
基于Epiphany 计算并行矩阵乘法的研究
2015-08-26 06:38曾弘扬
电子设计工程 2015年24期
曾弘扬
(北京工业大学 软件学院, 北京 100124)
对于工程科学中的许多计算问题中,数值计算问题都是最基本的内容。 矩阵乘法作为基本的线性代数运算,被广泛地应用于工程学领域[1]。 矩阵乘积在实际应用中是经常要用到的,例如,在解决有限元素的方法中,模型元素之间的关系被表示为状态矩阵元素。 对状态的改变,被表示成输入一个矩阵或向量,通过进行矩阵乘法来计算出新的状态。 所以如何高效的计算矩阵乘法是十分重要的。
1 矩阵乘法的串行实现
矩阵相乘串行实现的i-j-k 形式, 其中最内层运算是点积,数据用到A 的行和B 的列。
for(i=0;i<M;i++)
for(j=0;j<N;j++)
for(k=0;k<P;k++)
C[i][j]+=A[i][k]*B[K][j];
矩阵相乘的前提条件,前一个矩阵列数,须与后一个矩阵行数相等。 矩阵A 为M 行P 列,矩阵B 为P 行N 列,则矩阵乘法,继承前一个矩阵的行数M,和后一个矩阵的列数N,相乘矩阵中每一项,都要经过P 次加和乘。 算法分析:该算法需要进行n3个乘法运算和n3个加法运算, 顺序代码的时间复杂度为O(n3)。
2 串行计算大矩阵乘法的问题
2.1 串行计算不适应于大矩阵乘法
许多先进的计算机都配有高效的用于解矩阵乘法的的串行程序库,比如常用的SGEMM(单精度普通矩阵乘法)函数就是用于实现矩阵乘法运算一个常规形式的标准API,但它不适用于很大的矩阵。 因此,为了在并行计算环境下实现矩阵乘积,研究并行矩阵乘法是非常必要的[2]。
2.2 并行计算时数据在多核间的传输速率慢
在多核处理器上,当操作的矩阵足够大时,数据就必须从外部内存中取出,例如系统的DRAM。 而Epiphany 芯片的外部内存DRAM,通过eMesh 网络在STARTIX FPGA 上来连接。 这个扩展的eMesh 时钟频率是50 MHz,相较于芯片的时钟来说是很慢。 因此,数据在DRAM 的传输非常缓慢。 通过eMesh 连接的Epiphany 能够在每个时钟周期读写一个字节的数据。 在一个负载均衡的系统上,400 MHz 的Epiphany E16G3 芯片, 从芯片到DRAM 的理论写速率是400 MB/s,但实际测量到的写速率是82 MB/s[3]。
可见,为了生成优化的代码,应尽可能减少对速度相对缓慢的DRAM 的访问。因此,在设计算法时,我们必须试图尽可能多的去重复利用这些读取出来的数据。
3 矩阵向量乘法的并行计算
矩阵与向量相乘是线性方程组迭代求解的核心问题,其并行计算的效率直接影响迭代求解的整体效率。n 阶矩阵A,与n 维向量x=[x1x2… xn]T,并行计算A 与x 的乘积y=[y1y2…yn]T。
并行矩阵向量乘法,对矩阵采用一维块状划分(带状划分),即把矩阵按整行(或整列)划分成组,将每组的数据指派给一个处理器存储。 划分的这些行列可以是连续的(连续带状划分),也可以是等距相间的(循环带状划分)。 这里,我们对矩阵A 进行按列连续划分, 将矩阵A 按行连续划分成p块,则每块所占行数为n/p 行(其中n 能被p 整除)。同时再将每个行块按列也相应地划分成p 个子块, 则第k 个行块Ak又可 进一步划 分为[Ak,0Ak,1… Ak,p-1]。 则Ak,j可以表 示如下:
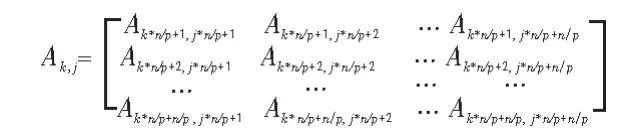
图1 矩阵的二维网格划分Fig. 1 The matrix of the two-dimensional grid
图1 中划分矩阵A 的下标k 是按行连续划分的下标,下标j 是与处理器个数相对应的列上划分, 它们都与处理器个数p 相关,因此范围都是[0,…,p-1]。
n 阶矩阵A 的子块分成了n/p 阶, 同理后面所要乘的向量x,与所得新向量y 的子块,也都要分成行为n/p 的子块,因此也都要按 行来进行 划分成:x=[x0x1…xp-1]T,y=[y0y1… yp-1]T,它们对应成的第k 块分别是:xk=[xk*n/p+1xk*n/p+2… xk*n/p+n/p]T,yk=[yk*n/p+1yk*n/p+2… yk*n/p+n/p]T。 划分到处理器上,在处理器k 上进行的第k 块乘积yk的计算公式为:

列下标j 按[0,1, …,p-1]移动时,下标(k+j) mod xk的模依次为[k,k+1,…,k-1],即先做本地处理器上的Ak,kxk,再做Ak,k+1xk+1,…,就这样不断地循环向下移动,直至做到Ak,k+1xk-1完成整个循环, 即按顺序逐次遍历完整个x 向量上的每一个子块为止。
矩阵A 的子块行坐标始终为k 不变,即按上式进行计算时,所用到的矩阵A 中的子块,就存储在当前运行的处理器上。而向量x 的子向量下标为(k+j) mod p,会随着j 的变化而变化, 即在计算的过程中需要用到整个x 向量上的所有子向量,因此可以通过在每次计算完成后,就将处理器中所存储的x 子向量,循环向上移动到上一列的处理器中。
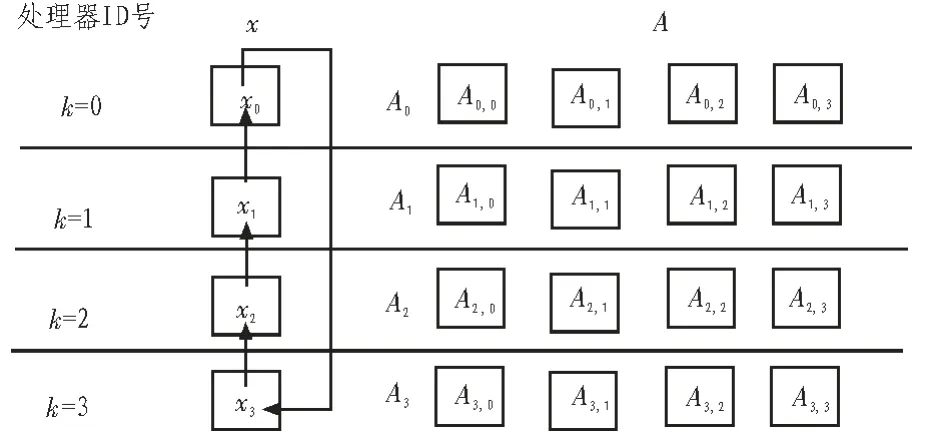
图2 并行计算矩阵向量乘积Fig. 2 Parallel computing matrix vector product
如图2 所示, 将各处理器中所存储的矩阵A 中的子块Ak,与处理器中存储的向量x 的当前子块xk相乘,进行p 次,每次x 向量中的子向量都向上循环移动一个位置, 对同一处理器中p 次的乘积进行累加求和, 即可得出矩阵向量的乘积向量y。
4 矩阵乘法的并行Cannon 算法实现
根据矩阵A 与矩阵B 在处理器中的不同存储方式可得到多种并行计算矩阵乘积的划分方法。 比如:行列划分算法,将矩阵A 按行连续划分成p 个一维块状子矩阵(行块),将矩阵B 按列连续划分成p 个一维块状子矩阵(列块)。 但无论是按行列、行行、列列,还是按列行来对矩阵进行划分,其本质都是基于矩阵的一维块状划分。而Cannon 算法是基于矩阵的二维块状划分的。 其特点是矩阵A 中的子块在指定行中循环移动,矩阵B 中的子块在指定列中循环移动,对每个处理器来说,计算量都是相同的,具有很好的负载均衡。 当p>=4 时,Cannon 算法具有优越性[4]。
4.1 二维连续块状划分
Cannon 算法中并行计算矩阵的乘法,与并行计算矩阵向量的乘法原理类似。但不同于矩阵向量的乘法中,只让一边的矩阵的各子矩阵循环移动。Cannon 算法是通过矩阵A 中的各行块,与矩阵B 中的各列块同时进行循环移位,来完成对矩阵C 中子块的计算。
一个二维网络由p*p 个处理器组成,将矩阵A、B、C 各划分成p*p 块,按二维连续块状进行划分,如上面的矩阵A 图的形式。 则处理器Pi,j上面的子矩阵Ci,j的计算公式如下:
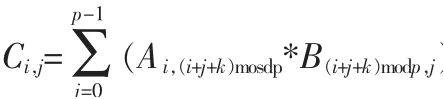
其中,i 是行下标,j 是列下标,范围都是[0,p-1]。 而k 是点积次数,即在m*l*n 中所乘的相同维度的l,因此k 的范围同其他维度一样也是[0,p-1]。
k 从0 变化到p-1 时,(i+j+k) mod p 也从0 取到p-1,k每增加1, 相应的行列坐标也循环递增1。 因此,i,(i+j+k)mod p 是i 行的所有块,(i+j+k) mod p,j 是j 列的所有块。 所以,式子中的Ci,j就是A 的i 行上与B 的j 列上对应的所有块乘积之和。
4.2 对 准
相乘的关键是相乘的两个元素下标要满足对准的要求。
在存储数据时, 处理器Pi,j上存储的数据应当是矩阵A的子块Ai,j,与矩阵B 的子块Bi,j。 而在计算开始时,从初始状态k=0 开 始,在处理器Pi,j上处 理 的 是Ai,(i+j)modp* B(i+j)modp,j的乘积。 可见,需要处理的两个子块均不在当前的处理器上。 因此,在计算k=0 状态之前,须要先进行对准操作,将处理器Pi,(i+j)modp上的子块Ai,(i+j)modp及处理器P(i+j)modp,j上的子块B(i+j)modp,j都先传递到Pi,j上后,才能开始计算。 即对p*p 二维网格上的每一个处理器Pi,j来说,都要进行的对准操作是,先将其上A的子块向左循环移动i 个位置,传递给位于i 行(i+j) mod p列上的处理器; 再将其上B 的子块向上循环移动j 个位置,传递给位于(i+j)mod p 行j 列上的处理器。
对准完成后,就可以从k=0 起始,从0 到p-1 按步进行计算了。
4.3 反对准
当计算p 次,即第p-1 次计算结束后,在Pi,j上参与计算的子块实际是Ai,(i+j+k)modp和B(i+j+k)modp,j。要想将之 前执行的 对准进行还原,需要进行反对准,使Pi,j上存储的操作子块恢复成Ai,j与Bi,j。 因此,要将多核 上的每一个处理 器Pi,j上存储 的A矩阵子块向右循环移动i 个位置,B 矩阵子块向下循环移动j个位置。
5 基于Epiphany 的矩阵乘法的Cannon 算法
为了实现一个任意大小矩阵乘法的高效的多核并行运算,需要使用单线程的C 代码来构建运算中的子块。其中,内存的分配被分为两个主要部分。 第一部分,是在芯片上每一个单核上的内存。 里面存放的是子块点积计算的结果。 第二部分,是芯片外的DRAM。 在这里,存放的是要操作的A、B、C矩阵。 以及,应用于系统层的主从设备间通信的Mailbox,和用于控制主从设备交互的结构体。
5.1 程序在核间的存储
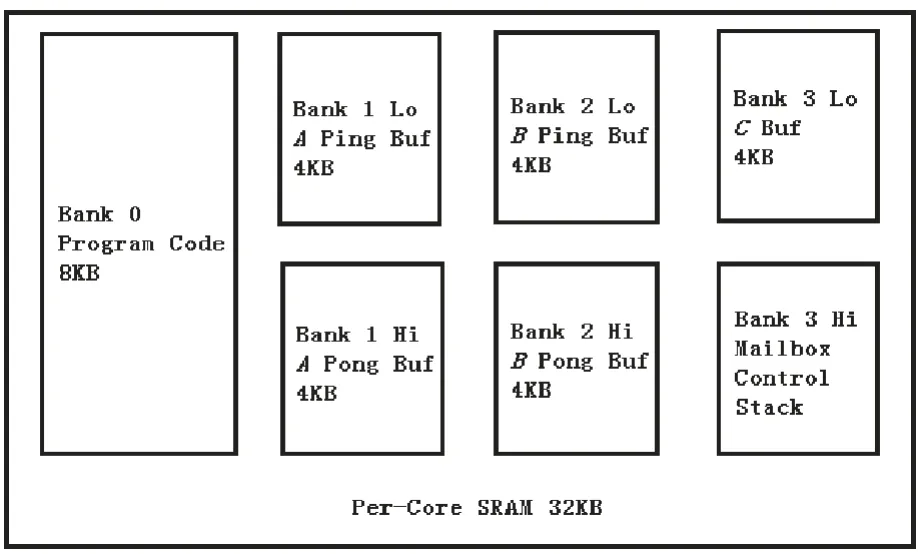
图3 单核中的内存分配Fig. 3 The mononuclear memory allocation
Epiphany 芯片的每个核都具有32 kb 的SRAM, 将其分配成4 个8 kb 的bank。每个核都可并发访问多个bank,且不会带来性能损失。 bank 0 用来存储程序代码。 bank 1 用来存放操作矩阵A 中子块的两个缓存。 同理,bank 2 用来存放操作矩阵B 中子块的两个缓存。 将bank 3 中的内存等分为两部分。 bank 3 中低位的部分,用于存放矩阵C 中子块的计算结果,因为计算结束后,也不需写回计算后的结果,因此不需要用两个缓存来存放矩阵C 中的子块。 将bank 3 中高位的部分, 用于存放对单核进行控制的结构体, 和核间交互的mailbox,以及运行bank 0 中代码时,程序所需要的栈。内存分块情形如图3 所示。
5.2 子块在多核间的传递
为了讨论方便,先给出一些记号的约定:
假设有p 个处理器,每个处理器上运行一个进程,则Pj表示第j 个处理器或进程,Pmyid表示当前运行程序的处理器或进程。 算法都是在Pmyid上运算的,处理器排序均以0 为起始,因此分成的块也从0 起始,矩阵的行列均从1 开始,如n阶矩阵A 为[a1,1… an,n]。
send 和recv 分别表示在Pmyid中的发送和接收操作。send(x,j)表示将运行当前进程的Pmyid处理器中的数据x 发送给Pj处理器。recv(x,j)表示将Pj处理器中的数据x 接收到运行当前进程的Pmyid处理器中。
因此在子块 移 动 的实现为顺序 为Send (Ai,j,Pi,(p+i-j)modp);Recv(Ai,j,P(i+j)modp);即 先 把 本 处 理 器 中 计 算 出 的 数 据 循 环 向前移动到第i 个位置处理器的内存PING 中, 再接收循环向后第i 个位置处理器的数据放到本地内存的PONG 中[5]。 在Epiphany 芯片中的实际操作如图4 所示。

图4 子块在多核间移动Fig. 4 Sub-block mobile between multicore
6 实验与结果分析
通过计算两个512*512 大小的矩阵乘积来测试该算法。分别使用在双核AMD 处理器的台式机, 和单核的Epiphany芯片上,使用串行算法;以及在16 核的Epiphany 芯片在上运行优化后的并行程序, 来计算相同的512*512 矩阵乘法,每组进行10 次实验得到数据如下:
通过表格中的数据可以发现:
与在标准台式电脑上得到的结果相比较,我们看到基于Epiphany 系统的巨大优势——在一个负载平衡的系统中和采用更低的时钟频率,运算速度却可以提高5 倍以上。

表1 计算矩阵乘法耗时时间Tab. 1 Calculate matrix multiplication takes time
进一步研究, 在基于16 核的Epiphany 芯片在上运行的并行程序的各阶段的时间花费,测量时间如下:
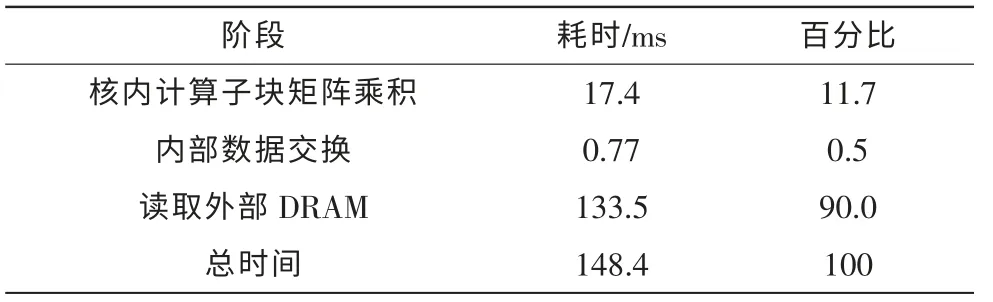
表2 并行算法各阶段的耗时Tab. 2 Every stage of the parallel algorithm’s time-consuming
通过表格中的数据可以发现:
1)总时间并不等于各项时间的和,在并行运算在多核上的性能会更低些。
2) 只有大约10%的时间是用来做真正的矩阵乘法运算的,其余时间都用来进行对DRAM 的读写。
7 结束语
本文在分析矩阵乘法的串行算法的基础上,找出了影响其计算效率的问题,给出了通过并行计算来实现可扩展的大矩阵乘法的Cannon 算法, 以此来提高大矩阵乘法的计算效率。Cannon 算法在多核并行计算矩阵乘法中具有广泛的应用性[6]。
[1] 李晓梅,吴建平. 数值并行算法与软件[M]. 北京:科学出版社,2007.
[2] 廖晓钟,赖汝. 科学与工程计算[M]. 北京:电子工业出版社,2003.
[3] Yaniv Sapir. Scalable Parallel Multiplication of Big Matrices[EB/OL].(2013-06)[2015-03].http://www.adapteva.com/wpcontent/uploads/2012/10/Scalable -Parallel -Multiplication -of-Big-Matrices.pdf.
[4] 姜弘道,张健飞. 工程科学中的高性能计算[D]. 北京:科学出版社,2013.
[5] Adapteva, Inc. Approaching Peak Theoretical Performance with Standard C [EB/OL].(2013-06)[2015-03].http://www.adapteva.com/white-papers/approaching-peak-theoreticalperformance-with-standard-c/.
[6] 李小洲, 李庆华. 矩阵相乘cannon并行算法在工作站机群上的实现[J]. 计算机工程,2002(6):102-130.
猜你喜欢
智能计算机与应用(2022年10期)2022-11-05
小学生学习指导(低年级)(2022年10期)2022-11-05
数学小灵通(1-2年级)(2021年10期)2021-11-05
小学生学习指导(中年级)(2021年3期)2021-04-06
现代计算机(2021年36期)2021-03-14
语数外学习·初中版(2020年11期)2020-09-10
学生导报·东方少年(2019年23期)2019-12-30
学生导报·东方少年(2019年22期)2019-12-19
小学生学习指导(低年级)(2019年9期)2019-09-25
计算机应用(2018年12期)2019-01-07
