
融合帕累托占优的用户协同过滤方法
2015-09-18 05:53刘艳范永全
现代计算机 2015年13期
刘艳,范永全
(西华大学计算机与软件工程学院,成都610065)
融合帕累托占优的用户协同过滤方法
刘艳,范永全
(西华大学计算机与软件工程学院,成都610065)
针对冷启动条件下传统基于用户的协同过滤方法不能获取充分代表目标用户的邻居用户,采用帕累托占优理论预过滤掉那些低相似度的用户。由邻近度、影响力、流行度结合的PIP相似度计算方法结合共同评分占比的影响因素改进相似度计算方法。实验采用Movielens100KB数据集,MAE作为评测指标,结果证明,融合帕累托占优和改进相似度的协同过滤算法MAE值对比只做过滤和只改进相似度有所改进。
协同过滤;帕累托占优;相似度计算;共同评分占比
教育部春晖计划(No.Z2011088)、四川省教育厅重点项目(11ZB002)、四川省高校重点实验室基金(No.SZJJ2012-027、No.SZJJ2014-033)、西华大学重点科研基金项目(No.Z1412620)
0 引言
在网络数据爆炸的时代,推荐技术让用户更快地找到想要的数据,让用户发现自己潜在的兴趣和需求,这对于电子商务和社会网络的应用都是至关重要的。在众多的推荐算法中,协同过滤推荐算法因其方法模型简单,数据依赖性低,数据采集方便,推荐效果较优成为主流的推荐算法。
协同过滤推荐的主要思想就是根据已有的一群用户的行为数据预测当前用户对没有见过的项目的喜好程度。协同过滤推荐可以分为基于内存的和基于模型的协同过滤推荐[1]。因为原始的评分数据保存在内存中,直接生成推荐结果,所以称为基于内存的推荐。而基于模型的推荐会先通过机器学习等方法学习用户行为数据建立用户的偏好模型,运行算法时再将模型调入内存。基于模型的推荐方法使用的模型有贝叶斯模型、聚类模型、矩阵因子分解模型等。
基于内存的协同过滤推荐算法又分为基于用户和基于项目的协同过滤。基于用户的协同过滤推荐思想是计算用户间的相似度,找到与目标用户相似度高的邻居用户,将邻居用户感兴趣的项目推荐给目标用户。基于项目的协同推荐思想是计算项目之间的相似度,推荐与目标用户感兴趣的项目相似度高的项目。
基于用户的协同过滤算法是一种早期的算法,最初介绍该算法是在GroupLens系统[2]用于推荐网络新闻。用户评分数据的稀疏性制约着推荐的质量,针对这一问题,文献[3]中定义了用户群体的概念并根据群体影响提出相应的两条准则,这样不仅考虑了用户个体之间的相似性,也考虑了用户所处群体之间的相似性。用户评分项目数极少的用户称为冷用户,也称为冷启动问题。计算相似度时,传统的相似度计算方法如皮尔逊相关系数、余弦、均方差不能获得足够的有效相似用户。文献[4]提出了一种启发式的相似度测量模型,模型由三个部分组成,有效解决冷启动问题。文献[5]提出在根据计算得出的相似度找K个近邻之前采用帕累托占优理论预先过滤一些具有较小代表性的用户,保留最有代表性的那些用户。
本文采用文献[5]提出的帕累托占优理论预过滤用户得到候选用户,然后采用文献[4]提出的启发式相似度测量模型加入共同评分占比的影响因素改进相似度测量方法,计算其他用户与目标用户的相似度,找到前K个相似度高的邻居用户。根据邻居用户做评分预测,计算MAE值。实验证明,本文的方法对比只改进相似度计算方法和只做预过滤处理的方法MAE值都有所提高,方法是可行的。
1 相关工作
帕累托占优理论是用于解决多目标最优化问题[6],从除开目标用户的所有其他用户中寻找能准确代表目标用户的用户作为候选邻居用户。若x'∈D,且在D中不存在比x'更优越的解x,则称x'为多目标最优问题的Pareto最优解,也称有效解。D就是除了目标用户以外的其他用户,x'就是与目标用户相关的邻居用户。一般来说,多目标优化问题不存在唯一的最优解,所有可能的解的集合都称为Pareto解集,也称非劣解集。
在推荐系统领域,用户对项目的兴趣度的测量包括准确度、新颖性、多样性,推荐系统推荐的项目通常都只选取一种测量条件,同时满足这三个条件可能会导致目标冲突的问题,文献[7]提出帕累托效率的概念用于解决这个冲突问题。根据用户回答系统提出的问题这样的简短对话所得出的答案做出推荐,称为对话推荐系统。文献[8]采用帕累托占优理论用于选择向用户提供的问题。对话推荐系统是基于内容的推荐算法的实例,在面向用户的电子商务中应用广泛。而在本文中我们将帕累托占优理论融合到协同过滤算法中。
我们定义m个用户对n个项目进行评分,用户集合为U,项目集合为I,评分值集合V,用户u的评分项目集合为Ru,项目i的评分项目集合为Ti。
U={u∈N|1≤u≤m}
I={i∈N|1≤i≤n}
V={v∈N│min≤v≤max}∪{∞}
其中max和min表示评分的最大值和最小值,∞表示没有评分。
Ru={i∈I,v∈V|ru,i=(i,v)}
Ti={u∈U,v∈V|ti,u=(u,v)}
常用的相似度计算方法有:皮尔逊相关系数(Pearson Correlation Coefficient)(1)、余弦(Cosine)(2)、均方差(Mean Squared Difference)(3)。
sim(x,y)PCC=

其中,Ix,y表示用户x与用户y共同评分的项目集合,|Ix,y|表示共同评分项的数目,rx,i和ry,i,表示用户x和用户y对项目i的评分,rx和ry表示用户x和用户y的平均评分。
2 融合帕累托占优和改进相似度的协同过滤
2.1选取候选邻居
定义Iu={i∈I,v∈V,v≠∞|ru,i=(i,v)}为目标用户u已评分项目集合。
定义d(rx,i,ry,i)为用户x和用户y对项目i的绝对差异。

当满足表达式(5)时,我们称用户x比用户y关于用户u占优,用户y被用户x关于用户u占优:

从概念上说,代表目标用户的被占优用户相比于占优用户没有展现更大的相似性,他们展现了较低的相似性。因此我们就将被占优用户舍弃。
我们定义目标用户u的候选邻居集合Cu,正式地,称为代表目标用户的非被占优(non-dominated)用户集。定义Du为被至少一个用户关于目标用户u占优的被占优用户集合。Cu满足表达式(6):
Cu∈U,u∉U,Cu=U-(Du∪{u}),∀y∈Du,∃x∈Cu|x> yu(6)
2.2计算相似度
文献[4]提出的新的相似度测量由邻近度(Proximi-ty)、影响力(Impact)、流行度(Popularity)三个部分组成。
用户x和用户y之间的相似度为sim(x,y)PIP,计算如表达式(7):
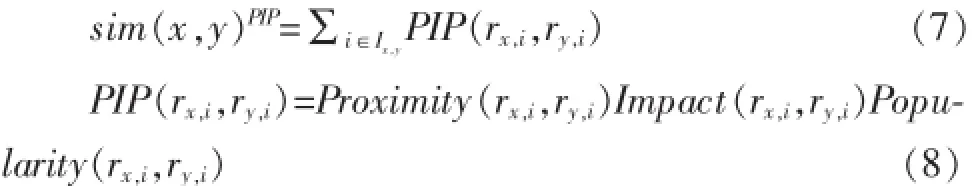
定义:

布尔值函数:

距离:
Distance(rx,i,ry,i)=

邻近度:
Proximity(rx,i,ry,i)=

影响力:

表示项目i对所有用户的平均评分
流行度:

共同评分项的占比是一个重要的因素,因此我们引入Jaccard系数,如表达式(16):

因此改进后的相似度计算方法如表达式(17):

2.3评分预测
从目标用户u的候选邻居集合Cu中选取k个近邻,得到K近邻集合Ku满足表达式(18),

令Gu,i={l∈Ku|rl,i≠∞}为Ku中对项目i进行了评分的用户集合。
预测目标用户u对项目i的评分如表达式(19):

3 实验结果
实验数据采用Movielens 100KB数据集,包含943名用户对1682部电影超过10万条评分。令Au={i∈I|ru,i≠∞∧pu,i≠∞}为用户u预测的项目的集合。
采用MAE作为准确性度量标准,则用户u的MAE计算公式如表达式(20):

算法的MAE值计算如表达式(21):

实验结果如图1所示:

图1 不同方法在不同k值下的MAE值
从图中可以看出本文采用的预过滤处理结合改进的相似度计算方法的MAE值相比其他方法是最小的,改进的相似度的方法相比传统的PCC、MSD、COS方法都较小。传统的方法之间MAE值差别不大。随着邻居数k的变化,MAE值不断减小,但从120以后,变化趋于平缓,比较稳定了。因此本文的方法和传统的协同过滤方法相比较,推荐质量有所提高。
4 结语
传统的基于用户的协同过滤方法在选取目标用户的邻居用户时不够代表性,因此本文采用帕累托占优理论预先过滤掉那些低相似度的用户。由邻近度、影响力、流行度结合的PIP相似度计算方法结合共同评分占比的影响因素改进相似度计算方法。预过滤处理结合改进的相似度计算方法提高了推荐质量。采用预过滤处理,增加了运行时间,接下来将会对如何提高算法的运行时间进行研究。
[1]Su X,Khoshgoftaar TM.A Survey of Collaborative Filtering Techniques[J].Advances in Artificial Intelligence,2009,2009:4
[2]Resnick P,Iacovou N,Suchak M,et al.GroupLens:an Open Architecture for Collaborative Filtering of Netnews[C].Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work.ACM,1994:175~186
[3]林耀进,胡学钢,李慧宗.基于用户群体影响的协同过滤推荐算法.情报学报,2013,32(3):299~305
[4]Ahn H J.A New Similarity Measure for Collaborative Filtering to Alleviate the New U ser C old-S tarting P roblem[J].Information Sciences,2008,178(1):37~51
[5]Ortega F,Sánchez J,Bobadilla J,etal.Improving C ollaborative F iltering-B ased R ecommender S ystems R esults U sing Pareto D ominance[J].Information Sciences,2013,239(4):50~61
[6]Zitzler E,Laumanns M,Thiele L.SPEA2:Improving the Strength Pareto Evolutionary Algorithm[J].Tik Swiss Federal Institute of Technology,2001
[7]Ribeiro M T,Ziviani N,Moura E SD,et al.Multiobjective Pareto-Efficient Approaches for Recommender Systems[J].ACM Transactions on Intelligent Systems and Technology(TIST),2014,5(4):53
[8]TrabelsiW,Wilson N,Bridge DG,etal.Comparing Approaches to Preference Dominance for Conversational Recommenders[C],in: 22th IEEE International Conferences on Toolswith Artificial Intelligence(ICTAI’10),2010:113~120
Collaborative Filtering;Pareto Dominance;Similarity Measure;Proportion of Common Ratings
User-Based Collaborative Filtering Using Pareto Dom inance
LIU Yan,FAN Yong-quan
(School of Computer and Software Engineering,Xihua University,Chengdu 610065)
The traditional collaborative filteringmethods can not select the representative users as neighbors insufficiently of active user in the condition of cold starting.Uses Pareto dominance to perform a pre-filtering process eliminating low similarity with the active user.Improves sim ilarity measure by considering the influence of proportion of common ratings,combined with the PIP similarity measure which composed of proximity,impact,and popularity.Uses MovieLens-100K as the data sets,MAE asmetrics.The experimental results show that themethod combining with the pre-filtering processing and improved similarity measure is improved in the value of MAE compared to only using pre-filtering or improved similaritymeasure.
1007-1423(2015)16-0011-04
10.3969/j.issn.1007-1423.2015.16.003
刘艳(1990-),女,四川广安人,研究生研究生,研究方向为信息检索、推荐系统
收谢日期:2015-04-142015-06-03
猜你喜欢
中学生数理化·八年级物理人教版(2022年5期)2022-06-05
新班主任(2022年4期)2022-04-27
客联(2021年5期)2021-09-10
成都信息工程大学学报(2021年1期)2021-07-22
科学大众(2020年23期)2021-01-18
汽车观察(2019年2期)2019-03-15
中山大学法律评论(2018年2期)2018-03-30
天津经济(2016年10期)2016-12-29
中国卫生(2016年5期)2016-11-12
中国医学影像学杂志(2015年9期)2015-12-15
