
一种基于压缩矩阵的多值属性关联规则改进算法
2015-10-25 03:46汪峰坤张婷婷
新乡学院学报 2015年12期
汪峰坤,张婷婷
(安徽机电职业技术学院信息工程系,安徽芜湖,241000)
一种基于压缩矩阵的多值属性关联规则改进算法
汪峰坤,张婷婷
(安徽机电职业技术学院信息工程系,安徽芜湖,241000)
针对经典的Apriori算法对多值属性数据进行关联规则挖掘时效率低下的问题,提出了改进算法。算法通过对属性值进行二进制编码、增加行和属性值计数器等方式,对数据进行了压缩,并针对压缩的存储矩阵使用了新的频繁集生成算法。实验结果表明,改进算法相比经典Apriori算法执行效率更高,所需资源更少。
数据挖掘;关联规则;频繁集;多值属性
关联规则挖掘是数据挖掘的重要研究方向。根据所挖掘数据集属性的特点,这些数据集可以分成标称属性、二元属性、序数属性及数值型属性几大类。对应二元属性数据集的关联规则称为布尔关联规则。标称和序数属性数据集对应的关联规则称为多值属性关联规则。
Apriori算法是由Agrawal等人于1993年提出的针对单维的布尔关联规则的数据挖掘的方法[1]。该算法通过迭代逐步发现数据中的频繁集,通过频繁集来表示数据之间的关联关系。
多值属性的关联规则最早由Srikant和Agrawal在1996年提出[2],其主要思想是通过一定的量化规则将连续数值型属性转换为离散型的单维二元属性后,再使用经典的Apriori算法进行挖掘。在多值属性挖掘的应用中,有些应用针对某个属性在一条记录中的取值是唯一的,例如:在某次常规体检中,某人的血压只能是高、中、低三种情况中的任意一种,而不会同时是两种或三种。
根据这些情况,本文提出了一种基于压缩矩阵方式的Apriori改进算法。此算法充分利用了多值属性在一条事务上的取值是唯一的特点,通过构造特殊的数据存储结构和优化的剪枝策略,提高算法执行的效率。
1 关联规则的基本概念
关联规则挖掘的定义如下:设I=(I1,I2,…,In)是项目的集合,数据集(记为D)是数据库事务集合,其中每一个事务T都是项的集合,且使T属于I。关联规则是形式为X=>Y的蕴含式(即如果X为真,则Y也为真),其中X和Y是项集,且X⊂I,Y⊂I,X∩Y=Ø。
项的集合称为项集,包含k个项的项集称为k项集。如果项集的出现频率大于或等于最小频度支持度与D中事务总数的乘积,则该项集满足最小频度支持度m。满足最小频度支持度的项集,称为频繁集。频繁k项集的集合记为项集Lk。
数据挖掘中的关联规则主要有两个步骤:1)找出所有频繁集;2)由频繁集产生强关联规则[3-4]。其中,1)是核心,决定挖掘关联规则的总体性能。因此,本文主要针对1)进行算法改进。
多值属性关联规则挖掘算法的主要性质[5-7]是:每条交易所包含的属性数目相同,即每个交易的长度相同,并且某一属性的不同的属性值不会出现在同一个频繁属性集中。
2 改进算法
2.1 数据结构
将属性值转换为等长二进制串,需构建属性值变换的哈希表H。哈希表中元素的键是连接属性名和属性值的字符串,元素的值是属性值的新编码。
定义矩阵S用来存储数据库中所有记录项。若挖掘数据库有M维,则S就有M列,其每行都表示数据库中的一条记录,每列表示记录中的一维数据。S中每个元素对应数据集中相应行和列的属性值。
定义行计数矩阵R,使S中的每行记录在R中都有一个相应的值,用来表示相同行在数据集中出现的次数。
定义列属性计数矩阵C。C的内容是S中列的属性的所有取值在数据集中出现的次数。
2.2 算法流程
(1)扫描事务数据集D,对属性值进行变换,生成表H,同时构建矩阵S。在扫描过程中对相同的事务进行计数,把矩阵中相同的数据行压缩成一行,并保证没有重复值的行。建立用于表示行个数的数组M,数组下标对应的是数据行的顺序,数组的值为数据行出现的次数。另外,建立列属性计数矩阵C。
(2)遍历属性计数矩阵C,如果C中的某个值,即属性取值在数据集中出现的次数不小于最小支持计数,则将此属性值加入1阶频繁集。
(3)检查矩阵S中每一列,如果某列的值都小于最小支持计数,则删除此列。
(4)连接n-1阶频繁项生成n阶频繁候选集。遍历矩阵S,将每个n-1阶频繁候选项都与S中每一对应列做“逻辑与”操作。如果结果为“0”,则支持度加上行计数矩阵R相应行的数目;如支持度大于最小频度支持度,则此频繁候选项是频繁项。
(5)遍历矩阵S,去除未包含m阶频繁项的行。
(6)重复步骤(3)和(5),直到某阶频繁项小于2或S行数小于最小支持计数时,算法终止,最终生成k阶频繁项。
2.3 算法改进
相对于Apriori算法,本算法优化部分如下。
(1)经典的Apriori算法要多次扫描数据库,性能低下。本算法只需扫描并读取数据库中的记录一次,通过“属性转换为二进值和对相同行计数”等压缩方法,将用于挖掘的数据集转换为内存中的数据矩阵S,之后的所有扫描只针对数据矩阵S,从而有效地提高了运行效率,节约了存储空间。
(2)由n-1阶频繁项生成n阶频繁项时,使用优化的剪枝策略是:1)n-1阶频繁项自身进行组合得到n阶频繁项的候选集,判断组合的合法性;2)遍历S,增加一个变量用来保存已遍历的矩阵行数。如果n-1阶项频繁次数-行数<最小频度支持度,则停止对矩阵的扫描,这是因为矩阵中剩余行中频繁次数不可能大于最小频度支持度。
(3)在生成频繁项候选集时,经典的Apriori算法是通过字符串比较来判断矩阵的某一行是否包括频繁项候选项的。本算法则是构造二进制串,将候选项二进制串与矩阵S中每一行二进制串进行逻辑与运算,如果结果是0,则表示该行中包括候选项。
3 实例分析
3.1 改进算法示例
设某事务数据库D中有10个事务,每个事务固定有5个属性,如表1所示。其中属性TⅠD表示事务的唯一编号,其他4个属性每个属性都有若干取值。

表1 多值属性数据示例
假设最小频度支持度m=30%,即最小支持计数为N=m×|D|=30%×10=3。
扫描事务数据库D,对属性值进行变换生成H,H={“BMI.超重”:0000,“BMI.正常”:0001,“BMI.肥胖”:0010”“空腹血糖.受损”:0011,“空腹血糖.糖尿病”:0100,“空腹血糖.正常”:0101,“锻炼.不锻炼”:0110,“锻炼.经常”:0111,“锻炼.很少”:1000”“脂肪肝.否”:1001,“脂肪肝.是”:1010},同时构建表示矩阵S、R和C。第一遍扫描结束时,相应的数据结构内容为

根据最小支持计数N,得到1阶频繁集{0000,0001,0011,0111,0101,0111,1000,1001,1010}。

由1阶频繁集生成2阶频繁集时,通过连接操作生成的2阶频繁候选项较多,且每个候选项都要扫描S,效率很低。本算法在此处进行了优化,思路是:在对2阶频繁候选项出现次数进行统计时,增加一个计数器,记录S中2阶频繁候选项出现的总个数t,如果此总个数满足候选项分项支持度-t<N,则此候选项分项的其他连接就不用再扫描。使用此优化方法,扫描S的次数减少了,算法运行速度提高了。例如:对于0000项,其2阶频繁候选项组合有{0000,0011},{0000,0100},…,{0000,1010}8项。如果不进行优化,则要8次扫描S;而通过算法优化,只需扫描2次。第一次扫描,组合{0000,0011}出现次数为1次,组合{0000,0100}出现次数为3次。1阶频繁项“0000”共出现了5次,而其他包含“0000”的组合项最多只有5-1-3=1次,小于N,不包含“0000”项的2阶频繁候选项一定不会是2阶频繁集,关于“0000”项的2阶频繁集搜索结束。对于本例,2阶频繁集最终是{(0000,1001,4),(0000,0100,3),(0000,0111,3),(1001,0100,3),(1001,0001,3),(1001,0101,3),(1001,1000,4),(0001,1000,3)}。
根据2阶频繁集,扫描矩阵S,去除在2阶频繁集中不存在的属性,然后连接2阶频繁项得到3阶频繁候选项集,扫描矩阵S,最后得到3阶频繁集{(1001,0001,1000,3)}。
根据2.2中的步骤(6),由于3阶频繁项个数为1,小于2,满足算法终止条件,算法结束。
3.2 性能比较
改进算法与基本的多值Apriori算法的性能比较如下。
实验条件:双核笔记本计算机,主频2.1 GHz,内存4 GB,操作系统为Win7 64位;编程语言为C#;测试数据为某医院健康体检数据,共有9个属性,每个属性有3~5个属性值;最小频度支持度为10%;数据量从1 000条增加到100 000条。运行结果如图1所示。
由图1可见,由于在连接时和剪枝时进行了优化,随着数据量增大,效果愈加明显,改进算法的性能优于基本的Apriori算法。
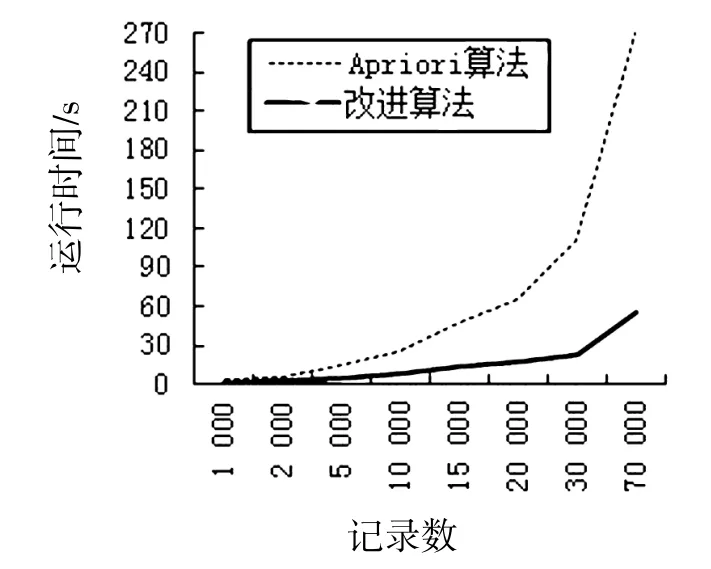
图1 运行时间和数据量关系
图2是在不同的最小频度支持度下,对50 000条记录进行处理后的Apriori算法和改进算法的性能比较。从图2可以看出,在最小频度支持度比较小时,改进算法的性能远远优于Apriori算法。

图2 运行时间和最小频度支持度关系
4 结束语
针对多维多值关联规则的Apriori算法执行效率较低和存储空间较大的缺点,提出了基于压缩矩阵和相应的频繁集的改进算法。实验结果表明,该改进算法减少了数据存储和搜索所需的空间,性能相对于经典Apriori算法有显著的提高。
[1]AGRAWALR,IMIELINSKIT,SWAMIA.Mining Association Rules Between Sets ofItems in Large Databases[J].ACM SIGMOD Record,1993,22(2):207-216.
[2]陈文.基于位矩阵的加权频繁k项集生成算法[J].计算机工程,2010(5):54-56.
[3]崔贯勋,李梁,王柯柯,等.基于改进Apriori算法的入侵检测系统研究[J].计算机工程与科学,2011(4):40-44.
[4]姜丽莉,孟凡荣,周勇,等.多值属性关联规则挖掘的QApriori算法[J].计算机工程,2011(9):81-83.
[5]付沙,周肮军.关联规则挖掘Apriori算法的研究与改进[J].微电子学与计算机,2013(9):110-114.
[6]张云涛,于治楼,张化祥.关联规则中频繁集高效挖掘的研究[J].计算机工程与应用,2011(3):139-141.
[7]李晓虹,尚晋.一种改进的新Apriori算法[J].计算机科学,2007(4):196-198.
【责任编辑 梅欣丽】
An Improved Algorithm of Quantitative Association Rules Based on Compressed Matrix
WANG Fengkun,ZHANG Tingting
(Information Engineering Department,Anhui Technical College of Mechanical and Electrical Engineering,Wuhu 241000,China)
Aiming at the problem of low efficiency of mining quantitative association rules with the classical apriori algorithm,an improved algorithm was proposed.The improved algorithm compressed data by using binary encoding of attribute values,adding rows and attribute value counters.A new algorithm for generating frequent itemsets was used for the compressed matrix.Experimental results showed that the improved algorithm was more efficient and less spaced than the classical apriori algorithm.
data mining;quantitative association rules;frequent itemsets
TP301.6
A
2095-7726(2015)12-0033-04
2015-09-01
安徽省高校省级自然科学研究重点项目(KJ2014A038)
汪峰坤(1978-),男,安徽霍邱人,讲师,硕士,研究方向:数据挖掘和大数据处理。
猜你喜欢
河南水利年鉴(2020年0期)2020-06-09
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
华中师范大学学报(自然科学版)(2017年6期)2017-12-26
妇女之友(2017年3期)2017-04-20
中国药物应用与监测(2015年5期)2015-12-11
中南民族大学学报(自然科学版)(2014年1期)2014-08-06
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
浙江师范大学学报(自然科学版)(2010年2期)2010-01-11
中学英语之友·上(2008年11期)2008-12-08
