
科技文献中表格信息的存储及检索方法研究
2015-12-07 09:02崔文浩张伟张利国
图书馆学刊 2015年11期
崔文浩 张伟 张利国
(沈阳化工大学图书馆,辽宁沈阳110142)
科技文献中表格信息的存储及检索方法研究
崔文浩张伟张利国
(沈阳化工大学图书馆,辽宁沈阳110142)
当前文献数据库检索系统缺乏成熟的表格检索功能,针对这一现状提出一种多特征域检索、以子表形式精确返回单元格数据的表格检索方法。分析了科技文献表格的特征,从表格抽取、标准化处理、表格对象封装存储、检索及结果集排序算法等方面进行探讨。实验结果证明该方法复杂度不高,检索效果较好。
表格检索表格存储表格标准化科技文献
1 引言
科技文献经常使用表格来描述结构化信息。表格能够简洁、集中地展现科学内容的逻辑性和对比性,是实验数据、统计结果及事物分类的一种有效表示方法。数字图书馆的重要优势之一在于检索便捷,但至今尚未出现成熟的表格检索系统,为获取表格数据,只能先检索相关文献,再阅读全文查找表格信息,这种检索方式效率低且无法保证查全率。
近年国内外对表格检索的研究主要包括:应用机器学习、自然语言处理等方法实现表格自动抽取[1-3];将单元格内容散列存入数据库,利用数据挖掘技术获取表格信息[4];将向量空间模型引入表格检索体系,形成严谨的相关度计算算法[5]。现有研究虽取得一些进展,但离实际应用仍有差距。表格自动抽取的研究多针对HTML格式文档,其他格式则效果不够理想[3],基本表与复杂表存储形式的非统一性不利检索[4],特征词标引及相关度计算过程复杂,对于经常更新的文献集缺乏实时性[5]。笔者在现有研究的基础上,提出将表格进行标准化处理,使用矩阵结构将其封装为独立对象存储,并对科技文献表格进行统计分析,根据其特点提出简化的相关度排序算法,实现了表格多维检索、返回重构子表功能。该方法复杂度不高,却能实现对科技文献中表格内部属性的检索,对数字图书馆的建设具有实际意义。
2 科技文献表格主体与特征域的提取
2.1科技文献的表格抽取方法
表格通过布局、文字两个要素描述数据,对元数据的提取、表内数据存储与检索,都需要将表格布局一并考虑。目前科技期刊多要求论文使用三线表[6],但早期文献中的表格版式更为灵活,这为建立统一的表格抽取算法带来困难。Word、HTML及PDF是常用的数字文献格式。Word格式论文中的表格易于计算机程序读取,此格式中有些三线表是隐藏竖线的多单元格表,有些是用绘图工具绘制的横线与成列文字组合而成的表格,这两种形式都能够较为准确地由程序读取[7-8],存在的问题是图书馆在自建机构馆藏库时难以获得原版Word格式论文。英文数据库通常提供Full Text HTML格式的论文,由于HTML使用固定的标记来描述,其中的表格信息也能够较精确地识别,且相关研究资料丰富[9-10]。对于科技论文最常用的PDF格式,由于对其解析相对困难,因此目前的方法是使用第三方软件将其转换为前两种格式再进行表格抽取,OCR技术难以做到极其精确,转换后仍需手动校验[4]。
2.2表格特征域提取及功能分析
表格标题、表头、文献标题是表格3个重要的特征域。在科技文献中,表格标题一般位于主体前端,起到对表格内容的说明作用,其形式通常为“‘表N’+空格+标题”。表格的主体部分由属性单元格和值单元格组成。属性单元格的集合即表头,由行名及列名构成,对表格内容描述起到决定性作用。文献标题是对整篇文献内容最精练的概括,表格作为文献整体的一部分也在其涵盖的范围内,因此文档标题能够辅助判断表格与检索预期的符合度。相关研究显示,上述3个特征域的叠加基本可以描述表格的主题[5]。此外有些表格还含有注脚、参考文献,对表格中某些内容做进一步阐述或加以解释说明,但他们对描述表格主题内容所起的作用很小,且在大部分科技文献中都不出现,因此笔者将其忽略。表格抽取包含对特征域提取,科技文献表格标题比较规范,易于程序提取,在转换生成的Word文档中,表格标题是程序发现表格的重要依据。表头含在表格的主体中,笔者提取表格后对主体进行标准化处理,提取的表头信息是标准化后的内容。
3 科技文献中表格信息的独立存储
表格信息提取后有两种数据处理模式,分别是动态生成临时文件模式与数据库持久化保存模式[2,4]。数字文献中的表格检索不同于对互联网页面中表格信息的挖掘,除部分OA资源外正规科技文献均由机构或出版集团掌握,数据增长速度有限且内容格式规范,将表格对象独立存储比动态挖掘效果好。笔者改进文献[4]提出的方法,将表格主体统一格式整体存储,从而减小存储算法的空间复杂度,易于后期检索、维护。
3.1表格按布局分型及标准表结构定义
科技文献表格按照属性单元格出现的位置可归为3种基本类型:
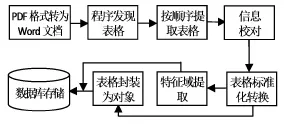
①行表头表格:总行数为p,前m行为属性单元格,其余为值单元格,其中1≤m ②列表头表格:总列数为q,前n列都为属性单元格,其余为值单元格,其中1≤n ③行列表头表格:对于p行q列的表格,前m行和前n列为属性单元格,表格中的所有其余单元格存放属性值,其中1≤m 上述3种基本类型表格的特征是值单元格位于行、列表头的下方、右侧,若属性与值间隔出现则视为复合表格。在不改变表格内容前提下,基本类型表格经过标准化转化后可用矩阵描述[6],笔者将这种在格式上与矩阵对应的表格称为标准格式表格,具体定义为: ①属性单元格仅出现在首行(m=1,n≠1)、首列(m≠1,n= 1)、首行列(m=1,n=1),属性值可以重复出现,但除首行第一个单元格外每个属性单元格不允许为空。 ②值单元格的行数为p-1,列数为q-1,若不为空则值与单元格必须呈一对一关系。 文献中有时还会出现描述性的无表头表格,但在科技类文献中极少见,且无表头表格对标准化存储并无影响,在此不作讨论。 3.2表格标准形式转换方法 公共属性、公共值的使用让表格版式更简洁,虽有利于读者阅读,但给计算机处理数据带来困难。为了使检索程序能够支持对表格内部属性的查询,需要预先对表头及值单元格做标准化转换,以对1 ①公共属性展开。某列属性若其覆盖的下一行属性单元格数大于1,则按其覆盖的列数生成新的属性单元格,并用相同属性值填充新生成的单元,使相邻两行的列数相等。 ②列属性合并。使用“-”将同列属性由上至下连接,使相邻行的列属性合并为一行。 ③重复①②直至列属性整体位于首行,若首行一个单元格为空则赋值为Null。 对列表头的转换与之类似,为公共属性按行展开,然后进行多列属性按行连接。对值单元格标准化转换只需展开而不需要连接。表2是对表1标准形式转换后的效果。 表1 Population Statistics 表2 标准形式的Population Statistics 3.3特征域信息及标准形式表格对象的存储 特征域信息可直接存储,表格主体需要做封装处理。标准化后的表格与矩阵Am×n对应,列表头为第1行的n个单元,行表头为第1列的m个单元,表格的数据部分由(m-1)×(n-1)个值单元格的组合,在高级程序语言中,此矩阵可用二维数组封装,并序列化处理为一个独立的字符串存入数据库。检索时将此字符串取出并重构为与A对应的二维数组,或根据需要提取A的某些行列重构为原表格的子集。以表2为例,数据库存储步骤如下: ①定义数据库表结构:a.表格标题表(表格ID,表格标题),存储表格标题特征域内容;b.表格-文档表(表格ID,文档ID,文档标题),存储文档标题特征域内容;c.表格属性表(表格ID,表格表头),表头为标准化处理后的内容;d.表格对象表(表格ID,标准形式表格对象),“标准形式表格对象”字段为变长字符串类型。 ②提取表头信息,分别加列、行前缀“col-”“row-”区别属性位置。即a12=col-Average-Height,a21=row-Males。此例中a11=Null。 ③属性单元a1j(j=2,3,4)与ai1(i=2,3)对应内容存入“表格属性表”。 ④表格标题特征域内容“Population Statistics”存入“表格标题表”。 ⑤通过以上步骤将表2特征域信息存储后,将表2整体赋值给二维数组,序列化处理后将生成的字符串存入表格对象表的“标准形式表格对象”字段。 3.4表格信息检索算法 3.4.1表格检索相关度计算 相关度计算是结果集排序的重要依据,在全文搜索系统中,向量空间模型应用最广泛,文献[5]将向量空间模型引入表格检索的相关度计算中,此模型需要计算表格对象集内每个词的特征值,其值为单词级权值、表格级权值及特征域权值三者之积,再计算表格特征向量与查询特征向量夹角余弦值,此方法排序效果虽好,但计算量大且缺乏实时性。科技文献中的表格与纯文本区别较大,表格标题、属性所使用的词语简明、重复率低,因此单词级与表格级权值意义小,笔者仅取特征域权值,将该值与检索词出现在此特征域中的频率作为依据。 在文献检索中,出现在题名中的文献具有更高的相关度,同理在表格检索中,出现在不同特征域的文字对描述表格的主题具有不同的贡献。在实验部分对实际科技期刊中的文献表格观察,发现参考文献、注脚两个特征域出现的概率近似为零,因此对文献[5]所做研究取得的特征域权值稍作调整,设检索词依次出现在表格标题、表格列名、文档标题获得的权值为Qj,(j=1,2,3),则: 用户输入的先拆分为词项,设全部词项为termi,i=1,2,…k.设Fij为termi在第j个特征域中出现的频率,则表格相关度的值由如下公式计算: 3.4.2表格信息检算法的主要步骤 ①取得用户输入的并进行词项拆分,每个词项搜索“表格属性表”,若结果不为空,则生成结果集R1。结果集R1的每条记录包含表格ID、命中的表格属性值等。 ②查询“表格标题表”及“表格-文档表”,匹配表格标题及文档标题字段内容,若搜索结果不为空,则生成结果集R2,此结果集中的记录不包含表格属性值项。 ③按照公式(1)对结果集R1、R2进行相关度计算,合并排序生成结果集R3。 ④遍历结果集R3,对于表格属性值为空的记录,按照表格ID从“表格对象表”中提取出序列化字符串的表格对象,整体重构为表格。 ⑤对表格属性值不为空的记录提取行、列属性对应列。规则如下:对于与矩阵Am×n相对应的表格,p和q分别对应命中的行、列属性个数,则①若p≠0,q=0则返回子表格对应矩阵A′为p行×n列,即返回命中的p行;②若p=0,q≠0则返回子表格对应矩阵A′为m行×q列,即返回命中的q列;③若p≠0且q≠0则返回子表格对应矩阵A′为p行×q列。 ⑥结果集R3经过④⑤将重构后,按原排序生成文档返回。 以表1为例,当布尔查询为“Males”and“Weight”时,返回子表格的形式如表3;当布尔查询为“Population Statistics”and“Males”时,返回子表格的形式如表4。 表3 查询“Males”and“Weight” 表4 查询“Population Statistics”and“Males” 沈阳化工大学教师科研成果数据库是自建机构馆藏库,从中随机选取本校教师2014年在科技核心期刊上发表的100篇论文作为文献集样本,学科领域包括化工、材料、机械等。对样本进行统计分析,得此样本集中含有表格的论文共72篇,表格176个,从表5中的统计数据可知,科技类核心期刊中的表格多为三线表,且属于笔者定义的基本表类型的表格占绝对比重,复合表仅两个,笔者在不改变原意的前提下,手动改变布局转换为基本表格。 表5 表格统计信息 图1 表格提取、转换与存储流程 使用ASP.net及C#实现前述算法,构建表格检索平台。由于样本均为PDF格式文档,因此采用自动与手动结合的方式提取表格。首先调用Solid PDF Converter V7转换文档格式,实验发现转换工具处理三线表缺乏稳定性,如转成HTML格式,则三线表的边线常被忽略,表内文字虽能保持原来的对齐方式,但生成的源码缺乏必要的HTML标记,为自动提取带来不便;如转换为Word格式,则表格边线会被保留,但多以图形的方式存在,实验中将文献统一转换为Word格式。转换后读取生成的文档,查找“‘表N’+空格+标题”形式字符串提取表格信息,遇首次提取失败的情况则手动选择表格区域进行二次提取。使用3.3节方法存储176个标准化表格对象,与图像格式相比,字符串序列占用存储空间小,且得到更好的封装效果。与文献[4]的存储方法相比,表格存储在数据库中的格式更加统一,均能够以子表格返回。为验证笔者所提出的表格提取、存储及检索方法,在系统构建后,从样本中随机选取表格特征词作为关键词进行考察,3词为1组,共10组,通过人工比对作评价。得出查全率100%,查准率92%,子表格重构显示准确率达到90%。简化的相关度计算方法降低了检索算法时间复杂度,且检索结果按相关度排序准确性较好,误差在可接受范围内。 笔者分析了表格检索领域现有研究方法以及科技文献中表格对象的特征,指出现有方法应用于科技文献表格检索存在的问题,提出标准化转换、封装后存储及重构显示的方法,实验证明在科技文献表格检索中能够取得较好的效果。未来的研究重点将集中在以下两方面: ①本方法在表格提取环节需要调用第三方软件转换格式,这种转换是整篇文档转换,缺乏针对性且准确率不高。对于早期文献中某些结构较为特殊的表格,计算机程序识别及规范化处理均较为困难,因此自动化提取工作依然是未来研究的重点。 ②目前表格3个主要特征域在数据库中都是整体存储的,这样更易于程序实现,但影响了检索速度,拆分后的词项独立存储会带来更好的检索效率,这需要做进一步探索。 [1]P.Yu.Kudinov.Extracting statistics indicators from tables of basic structure[J].Pattern Recognition and Image Analysis,2011(4):630-636. [2]Xing Wei,Bruce Croft,Andrew McCallum.Table extraction for answer retrieval[J].In formation Retrieval.2006(9):589-611. [3]Ana Costa e Silva,Alípio M.Jorge and Luís Torgo.Design ofanend-to-endmethodtoextractinformationfromtables[J]. International Journal on Document Analysis and Recogni⁃tion,2006(2):144-171. [4]刘葳,孙一鸣.信息检索中关于表格信息挖掘技术研究[J].情报科学,2014(11):92-95. [5]王凯,王朝飞.一种基于向量空间模型的表格检索算法[J].现代图书情报技术,2010(9):41-45. [6]王耘,冯金东,刘飚.科技论文中表格数据处理的矩阵转置法[J].编辑学报,2014(3):246-247. [7]王立涛.使用VB编程读取WORD表格中数据一例[J].电脑知识与技术,2010(22):6255-6260. [8]孙明珠,盖强,吉红安.基于广源报表的Word表格数据自动获取方法[J].测控技术,2011(12):75-78. [9]赵洪,等,师庆辉.Web表格信息抽取研究综述[J].现代图书情报技术,2008(3):24-31. [10]车成逸,马宗民,焦晓龙.Web表格中本体实例自动获取方法[J].东北大学学报:自然科学版,2012(3):92-95. 崔文浩男,1981年生。硕士,工程师。研究方向:数字图书馆。 张伟男,1980年生。硕士,工程师。研究方向:网络安全。 张利国男,1976年生,馆员。研究方向:信息检索。 TP391 (2015-08-03;责编:王天泥。)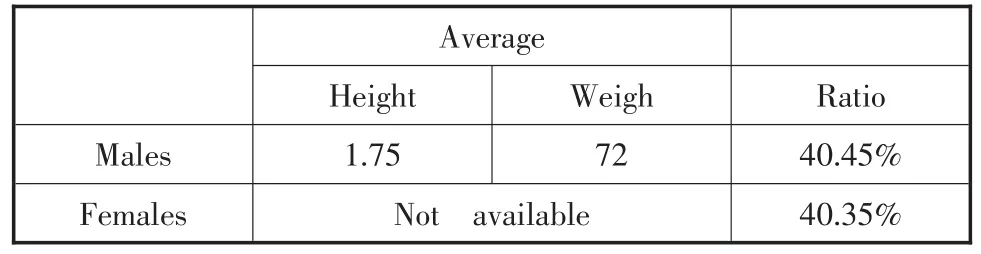

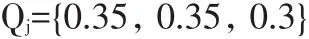



4 实验结果及分析

5 结语
猜你喜欢
客联(2022年3期)2022-05-31现代临床医学(2022年1期)2022-02-12中国新闻周刊(2021年26期)2021-07-27电脑爱好者(2021年12期)2021-06-22电脑爱好者(2021年8期)2021-04-21数学大王·趣味逻辑(2020年6期)2020-06-22数学大王·趣味逻辑(2020年5期)2020-06-19文化创新比较研究(2020年13期)2020-01-01高中时代(2017年7期)2018-02-24电脑爱好者(2017年7期)2017-05-06
