
一种多维网格编码译码器的高效FPGA设计*
2016-01-21 02:52那宝玉
通信技术 2015年7期
关键词:流水
兰 天,那宝玉,甘 明,张 剑
(1.中国电子科技集团公司第十研究所,四川 成都 610036;2.全军后勤信息中心,北京 100036)
一种多维网格编码译码器的高效FPGA设计*
兰天1,那宝玉2,甘明1,张剑1
(1.中国电子科技集团公司第十研究所,四川 成都 610036;2.全军后勤信息中心,北京 100036)
修回日期:2015-06-08Received date:2015-03-20;Revised date:2015-06-08
摘要:为在实时通信系统中有效利用多维网格编码调制(MDTCM)的短码特性,设计了一种适合FPGA实现的高效多维网格编码译码器。在该设计中,提出了一种易于硬件实现的改进归一化译码算法,采用四级流水线和乒乓环结构,并充分利用译码算法中的固有特性,有效降低了资源消耗和译码延迟。测试表明,该设计简单可靠,性能稳定,易于移植扩展,非常适合实时通信场合的应用,目前该译码器已成功应用于某实时通信系统中。
关键词:状态约束;网格编码调制;乒乓环;流水; FPGA
0引言
无线实时通信系统往往需要具备较强的误码纠错能力,同时又有很小的通信延迟要求。常用的一些信道码,如Turbo、LDPC等虽然可以很好满足纠误码性能的要求,但却由于编码模块较长,会导致高的译码延迟。多维网格编码可以满足这些要求。但由于多维网格编码在译码时采用了迭代BCJR算法,其中涉及大量的矩阵运算,乘加运算,因而设计实现时极可能导致高译码延迟,从而不能体现其短码结构在译码延时上带来的好处。
针对上述问题,本文提出了一种易于硬件实现的修正归一化算法,采用四级流水线,及乒乓环结构,利用算法特性,有效降低了资源消耗和译码延迟。
1多维网格编码简介
传统的网格编码调制[1](TCM)将信道编码与调制联合考虑,通过扩展调制信号集可以在不扩展带宽的情况下获得编码增益,但一般应用于带限系统, 在很多扩频系统中,编码与调制仍是单独考虑的。
多维网格编码[2-6]可以看作是TCM在功率受限系统中的扩展。它将扩频与编码调制有机的结合起来,可以很方便的同跳时,跳频,直扩系统配合使用。它不再着眼于带宽的不扩展,而是通过多维的星座点映射,以在网格图上获得更好的自由欧氏距离。
从网格图路径形式上讲,多维网格编码采用循环编码,可得到一种具有短码结构的网格编码,它满足状态约束,即对于输入的编码序列,保证在网格图上产生的状态转移序列具有循环码特性,且起始状态等于结束状态。这种状态转移的循环特性克服了传统TCM必须使用尾比特将网格状态归零,从而降低编码效率的缺点。由于不需要一个固定的起始或结束状态,这对于编译码将带来一个明显的好处,即对于一个固定的输入序列,通过在网格图上得到的闭合路径是唯一的,这为最终译码的良好性能提供了保证。

图1 几种扩频方式比较
如图1为多维网格编码与传统扩频方式之间的比较。从上到下,依次为非编码扩频方式,编码扩频方式,TCM级联扩频方式,多维网格编码方式。可以清晰的看到,将编码,调制与扩频整合到了一个步骤中考虑,这为多维网格编码带来更大的编码增益。
2多维网格编码的编译码算法
为方便后续讨论,作如下参数说明,定义(n,D),n为每个状态的输出分支数,即输入信号集的大小;D为网格深度,即从起始状态,到达所有可达状态的最小步数。由此可见对于(n,D),其网格图上一共有nD个状态。L为码长,N为信号维数。
2.1编码算法
编码步骤[1][2]主要为:根据n,D构造状态转移表,初态计算,状态转移计算,多维映射四步。
(1)首先根据S=nD构建构造一个状态转移表,由此表可以根据输入与当前状态得到下一状态。
(2)输入长度为k≥D+1的序列i1,i2,i3,…,ik,计算得到初状态β。
(3)根据1构造的状态转移表与2得到的初始状态β,由输入信号得到一个闭合网格状态转移序列。当编码模块长度L≥D+1时,编码序列所产生的闭合网格环路是唯一的。
(4)利用多维信号对状态转移进行符号映射。
一般的,映射信号的维数越高,所得的路径在网格图上的自由欧氏距离越大,性能也就越好,不过所需的带宽的也越宽,因此往往需要在带宽与性能之间折中。
2.2译码算法
译码时采用迭代循环移位BCJR算法[3]。
由于状态转移序列是一个闭合环路,可以证明将输入序列作k位移位后所对应的状态转移序列是移位前输入序列对应状态转移序列的k位移位。这个性质可以有效的保证多维网格编码以最大正确概率译码。
(2)初始化状态转移矩阵γi。
(3)前向状态度量α0初始化。
(4)更新α1,α2,…,αL,其中:
αt=αt-1γt-1
(1)
(2)
(5)后向状态度量βL初始化。
(6)更新β0,β1,…,βL-1,其中:
βt-1=γt-1βt
(3)
(4)
(7)迭代终止判决,满足判决条件则停止迭代,更新γi,得到硬判决结果,否则令:
α0=αL,βL=β0
(5)
然后回到3,继续迭代更新α,β。
(8)将得到的结果反向循环移位k,即得最终译码结果。
图2给出了N=12时,(4,2)码与(4,3)码编码长度为32比特的性能曲线。从图中可以看出,(4,3)码较(4,2)码有大致1db的增益,这是通过状态数的增加来获得的,即(4,3)码有64状态,而(4,2)码只有16状态。当然状态数越多编译码的复杂度也就越高。
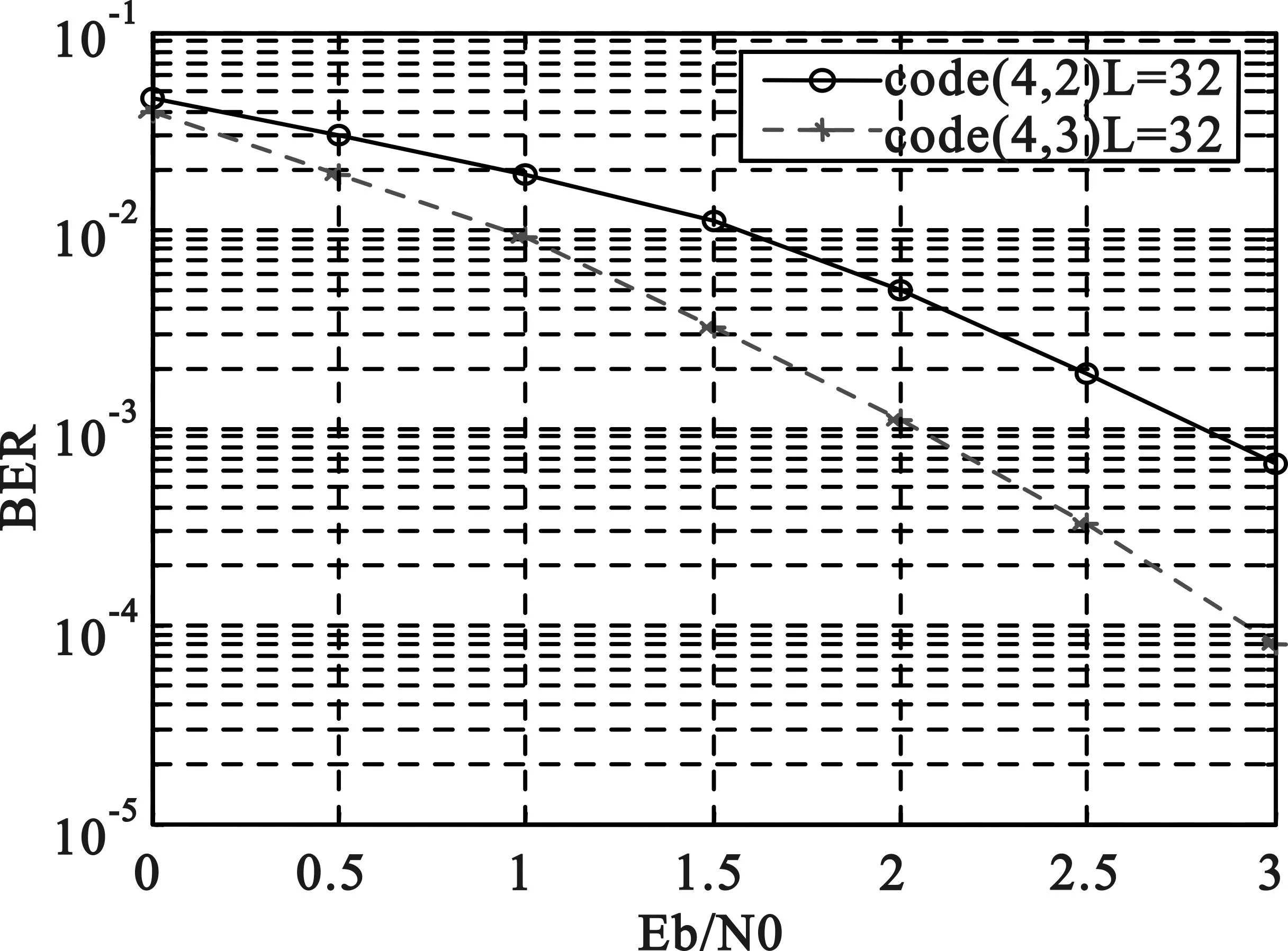
图2码长32的多维网格编码性能比较
3多维网格编码高速译码器设计
一般来讲,信道码的译码算法复杂度远远高于其编码算法复杂度,其译码延迟的大小往往决定了译码器能否用于实时通信系统中[7-9]。为充分发挥多维网格编码短码的优势,本节设计了一种高效多维网格编码译码器实现方案。
3.1归一化算法改进
在译码算法的第4,6两步,对αt,βt归一化时涉及到除法运算,这对于硬件实现比较困难。为此,作如下修正:
αt=αt/(max(αt)/Δ)
(6)
βt=βt/(max(βt)/Δ)
(7)
其中p为量化位宽,Δ=2p-1。
进一步的将归一化算法改写为:
(8)
(9)
仿真结果表明,经该算法改进后,采用9比特量化时,误码曲线与浮点时基本重合。
事实上,改进的归一化过程也是一个按比例缩放的过程,与原始的归一化算法一样,同样控制了归一化后的α,β元素值在0与1之间。因此不会对最终的译码判决有影响。
改进后,整个归一化过程可以通过简单的左移或右移来实现,避免了求和与除法运算,这将极大的消减硬件资源开销。
3.2状态转移矩阵γi简化
从前一节对译码算法的介绍可以看到,在迭代译码中所涉及的矩阵乘加运算与γi有关。反复的矩阵运算,除了乘加运算时间,还将带来大量的读写延迟。一个S×S的矩阵一次完整的读写周期为2S2,随S成平方增长。
事实上,由于γi表示的是状态转移概率矩阵。由BCJR算法可知大部分状态跳转是不允许的,即:
p(St=m|St-1=m′)=0
(10)
因此γi里的元素大部分是0,即γi是一个稀疏矩阵。由于可跳转状态是根据状态转移表所固定的,因此非零元素在γi中的位置也是固定的。所以只需要根据状态转移表,更新γi中的非零位置,这样可以大大减少迭代过程中的运算与读写时延。这样可使与γi有关的计算量减少至约为原来的(n·n)/(nD·nD)。
3.3四级流水结构
从以上译码算法介绍可知,一次完整的译码步骤较多,如果简单的按照算法顺序,逐步计算,即使考虑了γi的计算的简化,也势必造成高译码延迟,因此考虑使用流水结构。
根据译码算法特性,本文将译码过程分解为四个功能上相对独立的步骤:
(1)初始状态计算与序列移位。
(2)状态转移矩阵初始化。
(3)前向后向状态度量迭代更新。
(4)迭代中止,译码。
根据此四步,考虑采用四级流水结构,这样可以提高译码器的吞吐率,加快译码速度。同时,由于流水线的插入,关键路径得到了分割,电路可以工作在更高的时钟频率。四级流水结构如图3所示。

图3 四级流水结构
3.4乒乓环结构
在四级流水结构中,当第一级的计算结果送入第二级时,第一级已经处于空闲状态。但是由于第二级计算时需要用到第一级在存储器中的计算结果,因此这时第一级虽然空闲,但却只能空等,只有等到第二级计算结束将结果存放至第二级存储器时,第一级才能接收新的数据。对于后面三级同理。
因此,虽然插入了流水结构,但依然存在模块的空闲等待,这种等待将导致译码延迟的大大增加。
按照前述的流水结构划分,采用乒乓环的结构,可有效降低各级资源的空闲等待时间,如图4所示。
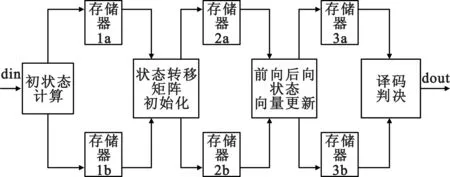
图4 四级乒乓环流水结构
从图4可以看出,各级之间使用了两个一样的存储器。第一级首先将计算结果存入1a存储器中。此时第二级开始从1a存储器中取数计算,同时第一级接收新的数据计算,将计算结果存入1b存储器中。
第二级在计算完1a中数据后,又马上开始从1b中取数计算。而第一级又开始接收新的数据,将计算结果存入1a中。如此交替循环,避免了各级的空闲等待,可大大减少了译码延迟。
4仿真及资源消耗
本节以编码长度为32,N=12的(4,2)码为例,给出了译码器设计结果。选用芯片为XILINX的V5SX50T芯片。

图5 原始算法仿真结果
图5为按照原始译码算法,一次顺序译码,只考虑归一化算法修正的仿真结果。译码延迟为38 603个操作时钟,最高时钟为114 M。

图6采用四级流水并简化算法后的仿真结果
图6是考虑归一化修正,采用四级流水乒乓环结构,同时优化γi的仿真结果。由于关键路径的缩短,最高时钟达到了224 M。译码延迟为7 858个操作时钟。
图7是采用XST综合得到的RTL级原理图。该图可以很清晰的反应出四级流水模块的互连结构。

图7 RTL级综合结果
表1是布局布线后的一些关键参数列表。可以看到该设计资源占有量很少,不到所选器件资源的10%。因此可以采用多路并行处理,进一步提高译码器的吞吐率,减小译码延迟。
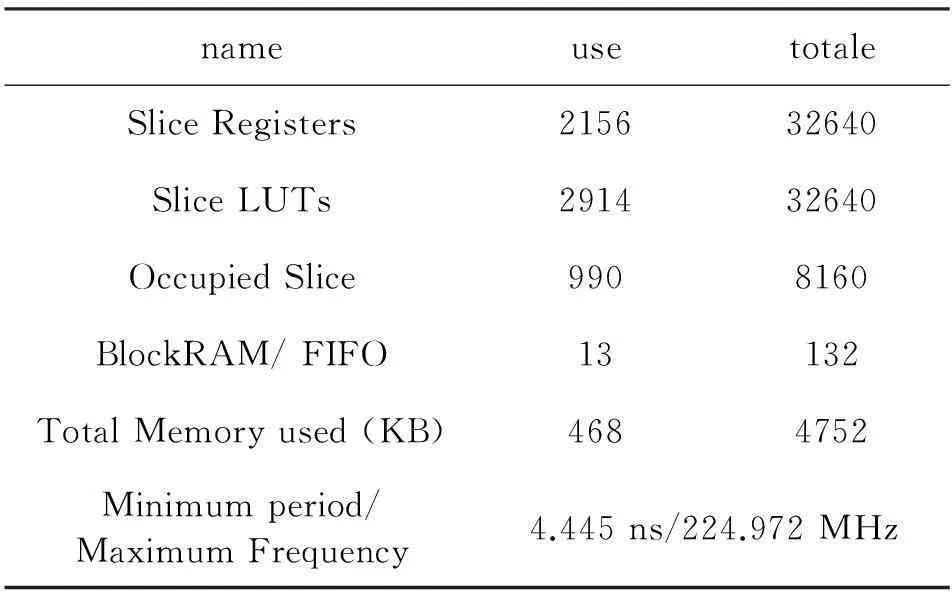
表1 FPGA实现后关键参数列表
5结束语
作为TCM与扩频系统的一种结合,多维网格编码可以同时获得编码与扩频增益,在实时通信中有良好的应用前景。基于多维网格编码译码算法的特点,本文提出了一种易于硬件实现的多维网格编码译码器。该译码器,在结构、存储空间和时序上得以较大的优化,极大降低了资源消耗与译码延迟。目前该该译码器已成功应用于某高速系统中,性能稳定,可靠。本设计具有较强的灵活性,能通过较小的修改而适应不同的多维网格编码,后续将用广阔的应用前景。
参考文献:
[1]Ungerboeck G. Channel Coding with Multilevel/Phase Signals[J]. IEEE TransInf. Theory, 1982, 55-67.
[2]WANG Qi, WEI Lei. Iterative Viterbi Algorithm for Concatenated Multidimensional TCM[J]. IEEE Transactions on Communication,2002(1): 12-15.
[3]Kamalakar Ganti, Jeffrey C Dill. Symbol Assignment for High-Rate Circular Trellis-based Turbo Codes[C]. IEEE WCNC,2008, 1056-1060.
[4]郭晶, 魏东兴. SOSTTC-OFDM系统设计与仿真[J]. 通信技术,2010,9(43):76-78.
GUO Jin, WEI Dong-xin. Application of Super-Orthogonal Space-Time Trellis Codes in MIMO-OFDM System[J]. Communications Technology,2010,09(43):76-78.
[5]王珏. 多维TCM及CPM编码调制技术研究[D].西安 西安电子科技大学,2012.
WANG Jue. Research on Multidimensional Trellis-Coded Modulation and Continuous-Phase Modulation Techniques[D]. Xi an: Xidian University, 2012.
[6]Priya K H, Tamilarasi M. A Trellis-Coded Modulation Scheme with 32-Dimensional Constant Envelope Q2PSK Constellation[C]. ICCSP, 2013(1): 821-825.
[7]雷赟. 网格编码调制技术的研究及其在VHF跳频通信系统中的应用[D].西安 西安电子科技大学,2012.
LEI Yun. Research on TCM and Its Application Within VHF Hop Communication System[D]. Xi an: Xidian University, 2012.
[8]唐星.带宽有效编码调制技术研究[D].武汉 华中科技大学,2012.
TANG Xing. Research on Bandwith Efficient Code-Modulation Technique[D]. WU Han: The Huazhong University of Science and Technology, 2012.
[9]CHEN Yi-hua, SU Mei-lin, NI Yi-fan. Implementation of Trellis Coded Modulation Encode on SDR Communication System[C]. ICEMI, 2013(2):687-691.

兰天(1982—),男,硕士,工程师,主要研究方向为编译码、高速数据链、抗干扰通信;
那宝玉(1979—),男,博士,工程师,主要研究方向为军队后勤信息化;
甘明(1978—),男,硕士,高级工程师,主要研究方向为高速数据链、高速编译码;
张剑(1975—),男,博士,高级工程师,主要研究方向为新型数据链、抗干扰通信。
An Efficient FPGA Design of MDTCM Decoder
LAN Tian1,NA Bao-yu2,GAN Ming1,ZHANG Jian1
(1.No.10 Institute of CETC, Chengdu Sichuan 610036, China;
2.Logistics Information Centre of PLA, Beijing 100036,China)
Abstract:Aiming at the effectively-used the short-code characteristics of MDTCM in real-time communication system, an efficient design of MDTCM decoder is proposed. Based on this, a modified normalization decoding algorithm suitable for hardware implementation is designed. With four-pipeline and ping-pang loop structure, and by taking full advantage of the intrinsic characteristics of decoding algorithm, the resource consumption and decoding delay are effectively reduced. Practical test show that this design, being simple, reliable and stable, and easy to transplant and extend, is suitable for real-time communication system, and now this decoder is successfully applied to certain real-time communication system.
Key words:state constraint;TCM;ping pang loop;pipeline;FPGA
作者简介:
中图分类号:TN850.3
文献标志码:A
文章编号:1002-0802(2015)07-0860-05
收稿日期:*2015-03-20;
doi:10.3969/j.issn.1002-0802.2015.07.022
猜你喜欢
云南画报(2021年8期)2021-12-02
文苑(2020年10期)2020-11-07
天津诗人(2017年2期)2017-11-29
视野(2015年6期)2015-10-13
六盘山(2015年3期)2015-06-29
海峡姐妹(2014年5期)2014-02-27
