
不确定数据的项集频繁概率近似算法
2016-04-14 05:31陈凤娟
许昌学院学报 2016年2期
陈凤娟
(辽宁对外经贸学院 基础课教研部,辽宁 大连 116052)
不确定数据的项集频繁概率近似算法
陈凤娟
(辽宁对外经贸学院 基础课教研部,辽宁 大连 116052)
研究在不确定事务数据库中挖掘概率频繁项集的问题,探讨使用近似算法在不确定数据中的挖掘概率频繁项集的方法.首先分析不确定数据库与可能世界语言,然后介绍频繁概率的概念,最后分析如何使用近似算法挖掘不确定数据库中的概率频繁项集. 从而降低运行时间,提高算法效率.
近似算法;不确定性;概率频繁项集
关联规则挖掘是数据挖掘重要的研究领域之一,它经常应用于购物篮数据库分析,从而发现顾客购买行为的规律.频繁模式挖掘是关联分析的第一步也是最重要的一步,在挖掘过程中,通常认为被挖掘的事务数据库是用一个二元矩阵M来表示的.其中,矩阵的每一行表示一个事务,而每一列表示事务中出现的一个项.矩阵中的一个元素Mij的值是1或0,分别表示项j在事务i中出现和不出现.在这种基本的事务数据模型中,一个项在一个事务中,要么出现,要么不出现,没有其他可能.相对于不确定数据集,这种数据库也称为确定数据库.在确定数据库中挖掘频繁模式的方法已经提出了很多,它们使用多种方法对事务数据库进行模式挖掘.
但是,在很多应用中,一个项在一个事务中不是出现或不出现,而是用一个存在概率来表示该项在该事务中出现的可能性大小.这是因为实验测量中搜集的数据容易受到噪声的干扰.例如,在用卫星对物体进行观察时,采集的卫星图像数据中,一个对象在其中出现的可能性用一个概率值来表示,因为它的出现与否是依靠人工解释或图像处理工具来分析得到的.这类数据被称为不确定数据.
从这类数据库中挖掘频繁项集比从确定数据库中挖掘更难,毕竟,计算一个项集的支持度必须考虑项集的存在概率.频繁概率是一种衡量不确定数据库中项集的支持度大小的概念,它全面考虑项集的支持度的概率分布,能表示该项集是频繁项集的概率.
本文主要研究在不确定事务数据库中挖掘概率频繁项集的问题,并探讨使用近似算法挖掘概率频繁项集.首先分析不确定数据库与可能世界语言,然后介绍频繁概率的概念,最后分析如何使用近似算法挖掘不确定数据库中的概率频繁项集.
从事务数据库中挖掘频繁项集是关联规则的最重要的步骤,大多数的频繁项集挖掘算法假设输入的数据不存在误差.然后,真实数据常常被噪声所影响,这种噪声在不确定数据库中用每个项的出现概率来表示.本文主要研究在不确定数据中用近似算法挖掘概率频繁项集的问题.
1 不确定数据库与可能世界
不确定数据库是指在事务数据库中,事务中每个项的出现与否由一个[0,1]之间的概率值来表示.当值为1时,表示该项出现在该事务中,当值为0时,表示该项不出现在该事务中,而值是区间的中间值时,表示该项在事务中出现的可能性大小.为了表示方式的简单,值为0的项在数据库中就不显示了[1].
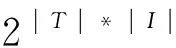

表1 确定数据库

表2 不确定数据库
定义1 设T是一组不同事务的集合,I是一组项的集合.一个不确定数据库D是一个从T×I到区间[0,1]的函数.不确定数据库D的一个可能世界W是T×I的一个子集.每个可能世界的概率PD(W)定义为
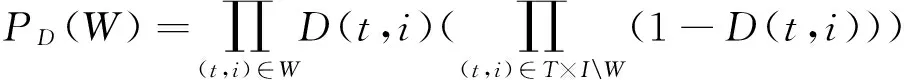
一个项集X在一个可能世界W中的支持度定义为W中包含X的事务的个数,因此,PD描述了不确定数据库的所有可能世界上的概率分布.一个项集在不确定数据库中的频繁度计算就是基于这种概率分布得到的.在所有的可能世界中,我们不知道哪个可能世界是真正发生的,因此,PD表明了某个可能世界真正发生的概率[3].
2 频繁概率的概念
在不确定事务数据库中,一个项集的支持度是不确定的,它是由一个离散概率分布函数来定义的.所以,每一个项有一个频繁概率,用来表示它是频繁项集的可能性大小.在不确定事务数据库中,一个项的支持度不应该仅用一个统计值来表示,而应该用离散概率分布来表示.
定义2 给定一个不确定事务数据库T和它的所有可能世界的集合,项集X的支持度的概率Pi(X)是指在所有可能世界中X的支持度等于i的可能世界的概率之和,即

定义3 一个项集X的概率支持度是指项集X所有的可能支持度值对应的支持度概率组成的概率分布.
这种概率分布也称为支持度概率分布,其和为1.
由于可能世界的个数是指数增长的,因此用定义1来计算支持度概率Pi(X)是不可行的,可以用下面的式子来计算[5].


项集X的频繁概率P≥minsup(X)表示的是项集X是频繁的可能性大小,依据这一策略,一个项集的频繁度可以作为项集是否是候选项集的判断条件.因此,给定一个最小的频繁概率作为用户定义的参数,可以找出概率频繁项集.
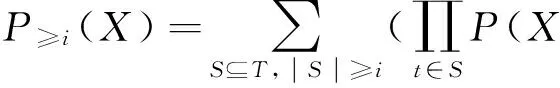
频繁概率可以通过计算所有满足最小支持度的可能世界中的概率之和得到.
定义5 一个项集X是概率频繁项集当且仅当该项集的频繁概率P≥minsup(X)大于等于用户给定的最小频繁概率阈值.
因此,挖掘不确定数据库中的概率频繁项集的问题就是指在不确定数据库中,根据用户给定的最小支持度和最小频繁概率阈值,找出所有频繁概率大于最小频繁概率阈值的项集.
3 挖掘概率频繁项集的近似算法
为了挖掘不确定数据库中的概率频繁项集,需要计算项集的频繁概率,可以采用动态规划的方法和分治的方法来计算频繁概率.
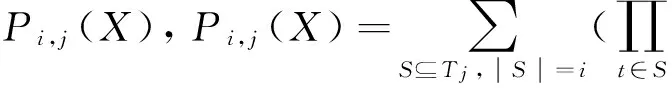
而P≥i,j(X)=P≥i-1,j-1(X)·P(X⊆tj)+P≥i,j-1(X)·(1-P(X⊆tj)).
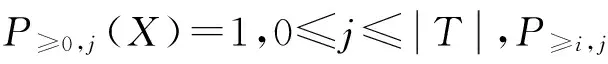
分治方法把不确定数据库分成两个子数据库,在子数据库上继续调用该方法,再次划分数据库,直到数据库中只有一条记录,然后计算频繁概率,再把两个数据库中的频繁概率进行合并,通过不断的合并,得到该项在整个数据库中的频繁概率.该方法可以在计算过程中使用快速傅里叶变换,提高该方法的效率[6].
虽然动态规划和分治算法给出了计算频繁概率的方法,但是在挖掘过程中,对于项集的频繁概率的计算量还是很大的,当数据库中记录量很大时,算法的效率不是很高.

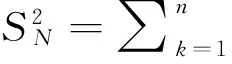
4 结语
概率频繁项集挖掘问题是在不确定事务数据库中发现某些项集可能是频繁的,并计算它们是频繁项集的可能性大小,找出大于用户给定最小频繁概率阈值的项集.用动态规划和分治方法计算频繁概率,从而找出概率频繁项集的方法在数据量大时效果不是很好,而近似算法不去计算具体的频繁概率,只关注频繁概率的近似值,从而减少了运算量,提高了算法的效率.
[1] 王意洁,李小勇,祁亚斐,等.不确定数据查询技术研究[J].计算机研究与发展,2012,49(7):1460-1466.
[2] Chui C, Kao B, Hung E. Mining frequent itemsets from uncertain data[C]. Berlin Heidelberg: Springer-verlag, 2007.
[3] Aggarwal C, Yu P. A survey of uncertain data algorithms and applications [J].IEEE Transactions on Knowledge and Data Engineering, 2009, 21(5): 609-623.
[4] 汪金苗,张龙波,邓齐志,等.不确定数据频繁项集挖掘方法综述[J].计算机工程与应用,2010,47(20):121-125.
[5] 周傲英,金澈清,王国仁,等.不确定性数据管理技术综述[J].计算机学报,2009,32(1):1-16.
[6] Wang L, Cheung D W, Cheng R, et al. Efficient mining of frequent itemsets on large uncertain databases[J].IEEE Transactions on Knowledge and Data Engineering, 2011,23(3):367-381.
[7] 王 爽,杨广明,朱志良.基于不确定数据的频繁项查询算法[J].东北大学学报:自然科学版,2011,32(3):344-347.
责任编辑:赵秋宇
Approximation Algorithm for Probability of Frequent Item-sets in Uncertain Database
CHEN Feng-juan
(InternationalBusinessandEconomics,LiaoningUniversity,Dalian116052,China)
In order to reduce the running time and improve efficiency of algorithm, studying items of mining approximation algorithm for probabilistic frequent item-sets in uncertain transaction databases, this paper acquired how to use approximation algorithm to mine probabilistic frequent item-sets in uncertain base. Starting with analyzing connections between uncertain databases and possible worlds, the paper introduces what frequent item-sets is. At last, a method of mining probabilistic frequent item-sets by approximation algorithm in uncertain databases is concluded.
approximation algorithm, uncertainty, probabilistic frequent item-sets
2015-10-17
陈凤娟(1979—),女,辽宁本溪人,副教授,硕士,研究方向:数据挖掘、无线传感器网络.
1671-9824(2016)02-0046-04
TP393
A
猜你喜欢
装备制造技术(2020年3期)2020-12-25
河南水利年鉴(2020年0期)2020-06-09
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
华中师范大学学报(自然科学版)(2017年6期)2017-12-26
科技视界(2016年19期)2017-05-18
中国工程咨询(2017年3期)2017-01-31
西华师范大学学报(自然科学版)(2015年3期)2015-02-27
中南民族大学学报(自然科学版)(2014年1期)2014-08-06
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
