
基于音节划分及短语表优化的英汉人名音译研究
2016-05-04 01:15王丹丹黄德根高扬
中文信息学报 2016年3期
王丹丹,黄德根,高扬
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
基于音节划分及短语表优化的英汉人名音译研究
王丹丹,黄德根,高扬
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
把英汉人名音译问题转换为以音节为基本单位的翻译问题,将连续的音节组合看作短语,引入一种基于短语的统计机器翻译方法,实现英汉人名的音译。首先,针对现有音节划分方法存在的问题,提出一种改进的音节划分方法;其次,该文提出去除低频词法及基于C-value方法对短语表进行优化,解决了训练语料偏小导致短语表中出现杂质信息的问题;之后,融入了汉语人名中首字(词)及尾字(词)的位置特征,改善了生成的音译候选中汉字选取的不合理性;最后,提出了两阶段音节划分方法,缓解了音节划分粒度过大导致的音译错误。与基准方法相比,其音译准确率ACC由63.78%提高到67.56%。
英汉人名音译;音节划分;短语表优化;C-value
1 引言
人名音译是指利用源语言及目标语言发音规则的异同将源语言人名翻译成目标语言,在机器翻译、跨语言信息检索等多语言处理任务中有重要作用。随着互联网络的迅猛发展,传统的基于词典的人名翻译方法已不能适应当前海量数据增长的需求,逐渐被基于数据驱动的人名音译方法取代。
根据处理单元的不同,人名音译方法一般分为基于发音、基于字形和基于发音字形混合的方法[1],文献[2]提出了基于发音的方法,利用源语言发音规则先将源语言人名转换为发音中间体,然后根据目标语言的发音规则,将中间体转换为目标语言;文献[3]提出了基于字形的方法,即直接由源语言不经过任何中间体转换为目标语言;文献[4]提出将音节及字形特征相融合的方法。相比于其他两类方法,基于字形的方法不需要经过中间体转换,会减少转换过程中的信息丢失,效果更优。
根据音节划分粒度的不同,分为以字母和以音节作为音译对齐基本单位的方法,文献[5]将英文的每个字母作为音译单元;文献[6]将英文进行音节划分,然后将每个音节作为音译单元;文献[7]提出基于多粒度的英汉人名音译方法,针对多个角度使用不同粒度的音节划分方法。实验结果表明,基于多粒度的音译效果要优于单一粒度的音译效果。
现有人名音译研究在音节划分和短语表优化方面还存在不足,主要如下: (1)音节划分规则不够完善,导致划分错误较多;(2)由于训练语料偏小,导致Moses系统生成的短语表中存在很多只出现一次,且翻译概率为1的低频短语,使短语表存在杂质;(3)音节划分粒度过大使音译时某些音节在短语表中找不到翻译,导致音译错误。
为此,针对英汉人名音译的特点及现有方法存在的问题,提出一种基于音节划分和短语表优化的人名音译方法。着重从下面几个方面进行改进: (1)在文献[8]的基础上对音节划分方法进行优化;(2)提出去除低频词法及基于C-value的短语表优化方法;(3)融入位置特征,仅考虑首词和尾词的位置特征;(4)提出两阶段音节划分方法。
2 基准系统
2.1 音节划分
人名的音译可以看作是简化的、无调序的机器翻译。音译前需对语料进行分词预处理: 对于汉语语料,用空格将人名中的每个汉字隔开,将每个汉字看作句子中的一个词;对于英文语料,则根据发音规则对语料进行音节划分,将每个音节看作一个词。
文献[8]按照英文的发音规则,首先,对音节字母进行如下定义: (1)将a、e、i、o、u定义为元音,m、n为鼻音,其他字母为辅音;(2)若y跟着辅音出现,则y为元音,否则为辅音。其次,按照英文发音的规律,制定了适合英汉人名音译的音节划分处理规则,见表1,其中,“( )”表示将括号内的内容合并为一个音节。
2.2 基于短语的统计机器音译模型
将音译问题看作语言翻译问题,从而引入统计翻译模型。本文采用对数线性多特征融合的方法解决英汉人名音译问题,该音译模型的计算如式(1)所示。
(1)
其中,c表示汉语人名,e表示英文人名,λi表示第i个特征的权重,hi(e,c)表示英语及汉语间第i个特征,n表示特征的个数。

表1 音节划分规则
本文使用的特征包括:
(3) 汉语语言模型:lm(c)
(4) 汉语人名的长度
3 音节划分改进及短语表优化
由于现有Moses音译系统存在音节划分规则不完善,音节划分粒度大以及短语表中含有杂质信息等缺点。为此,本文针对现有Moses人名音译系统中的音节划分及短语表优化等问题进行改进,改进后的模型见图1。(1)改进“音节划分”模块,主要对音节划分规则进行修改,以解决现存音节划分规则不够充分导致的音节划分错误;(2)利用基于C-value的短语表优化方法,以解决训练语料偏少导致的短语表存在杂质信息的问题;(3)融入汉语人名中首字(词)和尾字(词)的位置特征,以解决生成的音译候选中汉字选取的不合理性;(4)在测试阶段提出两阶段音节划分方法,以解决音节划分粒度过大导致的在词典中找不到音节翻译的问题。
3.1 音节划分方法的改进
根据表1规则进行音节划分后的人名,经过GIZA++双向对齐后,会产生一些错误的对齐结果,继而影响音译效果,经统计分析,导致该错误的原因在于表1音节划分规则的不准确性及不充分性。其表现在: (1)对于连续的重复辅音,常发同一个音,不应划分开,如人名“zucca(朱卡)”中“cc”应合并发音;(2)某些连续的元音组合不只发一个音,划分开会使对齐效果更优,如人名“abbiati(阿比亚蒂)”中,“ia”发两个不同的音;(3)“gh”、“h”、“ng”等在不同的情况具有不同的发音规则,应进行特殊处理。上述问题(1)和(2)阐述了表1中的规则1和规则2存在的缺陷,为此对表1中的规则1和规则2进行修正;为解决问题(3),我们增加了四条规则,见表2中的规则8、规则9、规则10和规则11。其中,“()”表示将括号内的内容合并为一个音节。

图1 改进后的Moses音译流程图

规则序号英文人名的情况音节划分处理方式规则类型1连续的辅音除了重复的辅音合并外,其余均划分开修正2连续的元音除了eo,ia,io,iu,oi,ua,ui,uo等划分开,其余均合并,作为组合元音修正3辅音+元音(辅音+元音)不变4任何独立的元音或辅音作为独立的音节不变5元音+鼻音+元音元音+(鼻音+元音)元音+鼻音+辅音/无字符(元音+鼻音)+辅音/无字符不变6c/s/z/t/p/w+h(c/s/z/t/p/w+h)并定义为辅音不变7元音+r+元音元音+(r+元音)元音+r+辅音/无字符(元音+r)+辅音/无字符不变

续表
3.2 短语表的除杂优化
基于短语的统计机器翻译,使用GIZA++进行双向对齐,从对齐结果中抽取出双语短语并计算翻译概率,进而构造出短语表。由于训练语料偏小,导致Moses系统生成的短语表中存在很多只出现一次,且翻译概率为1的低频短语。仅根据短语出现一次就断定其翻译概率为1,这不符合现实世界的真实情况。本文考虑使用去除低频词法及基于C-value 的方法分别对短语表进行优化。
3.2.1 基于去除低频词的短语表优化
首先定义如下,#(en)表示英文短语en在短语表中出现的次数,#(en,ch)表示在短语表中英文短语en音译为汉语短语ch的次数,那么英文短语en音译为汉语短语ch的概率为p(ch|en)=#(en,ch)/#(en)。据统计,符合#(en)=1,#(en,ch)=1且所含音节个数大于2的短语占总短语表的81.7%。由于数据稀疏,这样在训练语料中只出现一次且翻译概率为1的低频短语与现实世界的真实情况不符。为了消除此类短语的影响,本文从原短语表中删除符合如下情况的短语再进行音译: #(en)=1,#(en,ch)=1且所含音节个数大于1的短语,之所以不删除长度为1的短语是因为其本身就是音译的基本单位。
3.2.2 基于C-value的短语表优化
我们引入C-value[9]来衡量短语的贡献程度,进而对短语表除杂优化。C-value的定义见式(2)。
(2)
其中,|a|表示短语a的长度,即短语a包含的英文音节个数,f(a)表示短语表中短语a出现的频次,Ta表示短语表中包含a的更长的短语,P(Ta)表示短语表中Ta的频次,∑b∈Taf(b)表示短语a在所有包含a的长短语里出现的频次。
由式(2)可见,C-value不仅考虑短语长度和出现频次,还考虑包含当前短语的更长短语的信息。C-value与短语的长度和短语出现的次数成正比。其主要思想为: 短语的长度越长、频次越高,其作为短语的贡献度越高;若一个短语经常在比他更长的短语中出现而很少单独出现,可能该短语出现频次很高,但作为短语的贡献度却较低。
基于C-value的短语表优化方法的步骤如下:
(1) 根据C-value的公式计算短语表中的每个短语的C-value;
(2) 按照C-value从小到大进行排序,并求出以每个C-value作为阈值时,大于等于当前阈值的短语占整个短语表的比例;
(3) 根据经验选取若干个具有代表性的C-value作为阈值,并删除原短语表中小于当前阈值的短语。
3.3 融入位置特征
同一音节可能存在不同的音译候选,此时,汉字的位置特征可以决定使用哪个汉字更合适。例如,英文人名“kilogore(基洛戈尔)”,音节划分后的结果为“ki/lo/go/re”,根据音译短语表可知,音节“re”的音译候选可能有“尔”,“雷”,“里”等,解码后的音译候选按照音译概率从大到小依次为“基洛戈雷”、“基洛戈尔”、“基洛戈里”等。但根据位置特征,“尔”一般不出现在词首,“雷”,“里”经常出现在词中或词首,将位置特征与原有特征相融合,重新调整音译候选的顺序,最终得到正确的最优候选“基洛戈尔”。
由于同一英文人名生成的候选汉语人名的长度可能不同,若要考虑每个字的位置特征,则不同长度的候选汉语人名的位置特征不具有可比性,为此,本文仅考虑首字(词)及尾字(词)的位置特征。位置特征的计算方法: 首先将汉语语料中人名里的每个汉字用空格隔开;然后,利用BEO(B表示首位置,E表示尾位置,O表示其他位置)的方式分别标记每个字(词),统计每个字(词)分别出现在B、E、O的概率。实验表明,该方法要优于考虑人名中所有字的位置特征的方法。
3.4 解码时的两阶段音节划分方法
为了获得较好的对齐结果,在音节划分方法中引入了粒度较大的划分方法,如“元音+鼻音+辅音/无字符”情况,其将鼻音与前面的元音合并为一个音节,然而由于音节划分粒度过大,使得音译过程中在短语表内找不到音节的对应翻译。以英文人名“gwillim”为例,其音节划分结果为“g/wi/llim”,而由于音节“llim”在短语表中未找到对应翻译,导致音译错误。因此,提出了两阶段的音节划分方法。
如图2所示,第一阶段音节划分方法使用表2所示的优化后的音节划分规则,解码后,若存在未翻译的音节,则进入第二阶段音节划分,划分后再次解码。第二阶段音节划分的规则在表2规则的基础上进行如下变化:
(1) 若音节中含有y,且y的前一字符为辅音,则将y替换为i;
(2) 若最后一个字符为m或g,则将m或g与前面的音节分离;
(3) 若最后两个字符为ne,则将ne与前面的音节分离;
(4) 若r前面的音节长度大于2,则r与前面的音节划分开;
(5) 若gh后为辅音或者无字符时,则gh不发音;
(6) 若元音+h+辅音,则h不发音。
4 实验
4.1 实验数据及实验方法
英汉人名音译实验数据参照2012 Named Entities Workshop的英汉人名语料库[10]。其中,训练集含有37 753对英汉人名,调优集含有3 278对英汉人名。本文为了验证提出方法的有效稳定性,考虑使用交叉验证方法进行实验。从训练集中随机取出3 000对作为测试语料,剩下的34 753对作为训练语料,并使用此方法选取五组不同的训练及测试数据,调优集不变。
英汉人名音译的实验过程包括: 音译模型的训练、语言模型的建立、权重的调优及解码。在音译模型的训练阶段,利用GIZA++进行对齐生成短语表(参数设为grow-diag-and-fial)[11];在语言模型建立阶段,使用Srilm工具[12]计算汉语语料的N-gram语言模型(N取3);在调优阶段,使用MERT方法调整各特征权重达到最优;在解码阶段,由于人名音译可看作是无调序的机器翻译,为保证顺序解码,distortion设置为0,其他为默认设置。实验中,选取系统生成的前十个结果作为最优音译候选。
为评价音译结果的质量,采用如下四个指标进行评价[10]: 最优候选结果的准确率(ACC);最优候选结果与正确结果间的相似度(Mean F-score);正确结果在N个最优候选结果中靠顶部的程度(MRR);衡量正确候选结果中是否包含所有正确结果(MAPref)。
4.2 实验结果及分析
由于训练语料偏小导致短语表中存在杂质信息,使用基于去除低频词的方法对短语表进行优化,以“音节划分优化”为基准实验,表3为去除低频词前后的音译对比结果。
使用基于去除低频词的方法对短语表进行除杂,原短语表有八万多条短语,从短语表中将符合条件的短语删除,使短语表缩减到两万多条,即仅是原短语表的28.3%,如表3所示,其音译效果并未明显下降,说明短语表中确实存在杂质信息。

表3 基于去除低频词短语表除杂前后音译效果
使用基于C-value的方法对短语表优化,选取不同C-value作为阈值对短语表进行除杂,进行多组对比实验,结果如表4所示。当C-value阈值取0.9时,即当短语表缩减到原来的80.9%时,音译效果最优,与使用整个短语表的音译效果相当。由于短语表中存在大部分频次仅为1的短语,无法仅通过基于统计的方法有效优化短语表,今后考虑结合基于规则等方法对短语表进一步除杂优化。
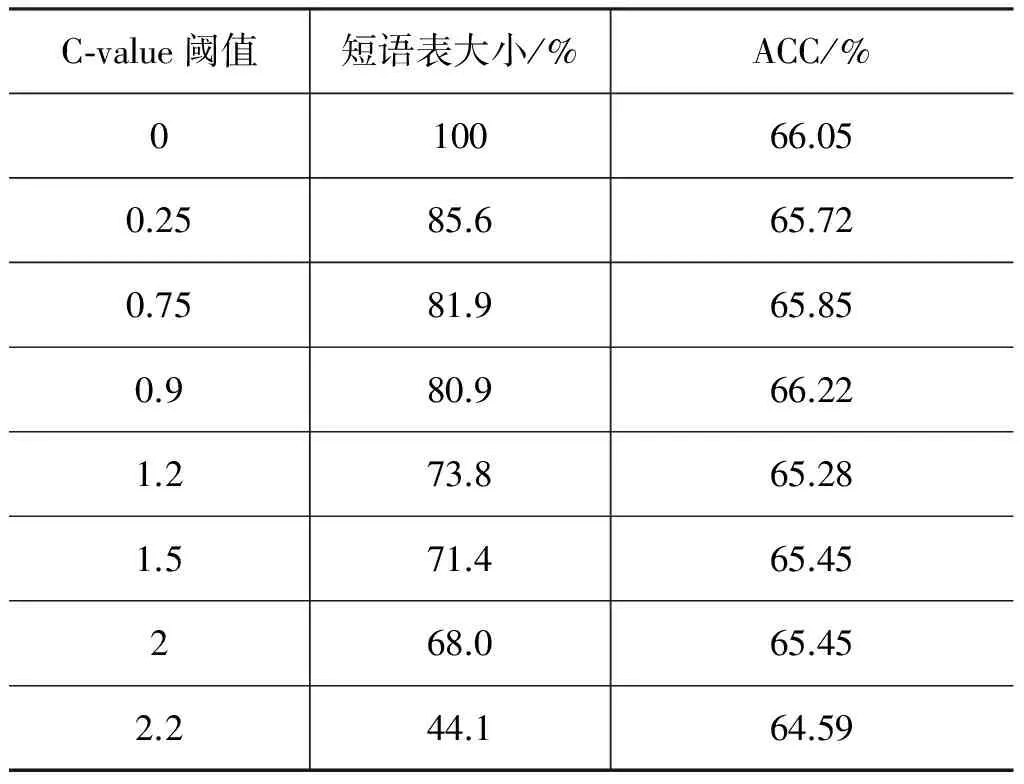
表4 不同C-value阈值下短语表大小及音译性能
在基准系统基础上,进行一些改进实验,实验对比结果如表5所示。为了说明方法的稳定有效性,以下实验结果均为使用交叉验证后,五组实验获得结果的平均值。其中,实验2针对基准系统中音节划分规则的不完善性,对其进行修正及扩充,其音译准确率ACC提高了2.52%;实验3则考虑到音译候选结果中汉字的选择与其在人名中出现的位置有密切关系,所以融入位置特征进行实验,其音译准确率ACC提高了3.19%;实验4为了解决由于音节划分粒度过大导致的某些音节在短语表中找不到翻译的问题,引入两阶段音节划分方法,最终音译准确率ACC提高了3.78%;实验5及实验6为文献[5]及文献[6]的实验结果,进一步说明了本文方法的有效性。

表5 基准系统与改进方法的实验对比

续表
5 结论及展望
针对当前人名音译研究中存在的问题进行改善,包括音节划分方法的改进、融入首尾位置特征以及提出两阶段音节划分方法等,改进后方法的准确率提高了3.78%。同时,提出了去除低频词法及基于C-value方法优化短语表,有效去除了杂质信息。
通过分析人名中音节的发音情况,某些音节具有不同的发音。例如,“r,d,t”等有时发音,有时却不发音;“gh”有时合并发音,有时分开发音,有时不发音,这些都没有明确的发音规则,无法通过统一的音节划分方法来确定。因此,在今后的工作中,可以考虑将不同音节划分方法获得的音译结果融合。此外,不同来源的人名发音规则不同,如“Smith”为英语来源的,应翻译为“史密斯”,而“Matsumoto”为日语来源的,则应翻译为“松本”更合适。今后可以考虑在音译之前先进行人名来源的识别,以进一步提高其音译效果。
[1] Karimi S,Scholer F,Turpin A. Machine transliteration survey[J]. ACM Computing Surveys (CSUR),2011,43(3): 17-46.
[2] Knight K,Graehl J. Machine transliteration[J]. Computational Linguistics,1998,24(4): 599-612.
[3] Haizhou L,Min Z,Jian S. A joint source-channel model for machine transliteration[C]//Proceedings of the 42nd Annual Meeting on association for Computational Linguistics. Association for Computational Linguistics,2004: 159-166.
[4] Oh J H,Choi K S. An ensemble of transliteration models for information retrieval[J]. Information processing & management,2006,42(4): 980-1002.
[5] Jia Y,Zhu D,Yu S. A noisy channel model for grapheme-based machine transliteration[C]//Proceedings of the 2009 Named Entities Workshop: Shared Task on Transliteration. Association for Computational Linguistics,2009: 88-91.
[6] Zhang C,Li T,Zhao T. Syllable-based machine transliteration with extra phrase features[C]//Proceedings of the 4th Named Entity Workshop. Association for Computational Linguistics,2012: 52-56.
[7] 于恒,涂兆鹏,刘群,等. 基于多粒度的英汉人名音译[J]. 中文信息学报,2013,27(4): 16-21.
[8] Li L,Wang P,Huang D,et al. Mining English-Chinese Named Entity Pairs from Comparable Corpora[J]. ACM Transactions on Asian Language Information Processing (TALIP),2011,10(4): 19.
[9] Frantzi K,Ananiadou S,Mima H. Automatic recognition of multi-word terms: the C-value/NC-value method[J]. International Journal on Digital Libraries,2000,3(2): 115-130.
[10] Zhang M,Li H,Liu M,et al. Whitepaper of news 2012 shared task on machine transliteration[C]//Proceedings of the 4th Named Entity Workshop. Association for Computational Linguistics,2012: 1-9.
[11] Koehn P,Och F J,Marcu D. Statistical phrase-based translation[C]//Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology-Volume 1. Association for Computational Linguistics,2003: 48-54.
[12] Stolcke A. SRILM-an extensible language modeling toolkit[C]//Proceedings of the Interspeech. 2002.
[13] Koehn P,Hoang H,Birch A,et al. Moses: Open source toolkit for statistical machine translation[C]//Proceedings of the 45th Annual Meeting of the ACL on Interactive Poster and Demonstration Sessions. Association for Computational Linguistics,2007: 177-180.
English-Chinese Name Transliteration Basedon Optimization of Syllabification and Phrase Table
WANG Dandan,HUANG Degen,GAO Yang
(School of Computer Science and Technology,Dalian University of Technology,Dalian,Liaoning 116024,China)
The English-Chinese name transliteration can be described as syllable-based translation,which can be solved by current a phrase-based statistical machine translation model. After describing a detailed rule-based syllabification method,this paper presents a translation phrase table optimization by frequency thresh-hold and c-value. In addition,the method is also featured by integrating the local features of Chinese names,as well as a two-stage of syllabification strategy. The experimental results show that the performance of the English-Chinese name transliteration is improved from 63.78% to 67.56% in terms of ACC.
English-Chinese name transliteration; syllabification; phrase table optimization; C-value

王丹丹(1989—),硕士研究生,主要研究领域为自然语言处理与机器翻译。E⁃mail:15092170184@163.com黄德根(1965—),通信作者,博士,教授,博士生导师,主要研究领域为自然语言处理与机器翻译。E⁃mail:huangdg@dlut.edu.cn高杨(1988—),硕士,主要研究领域为自然语言处理。E⁃mail:389021064@qq.com
2014-07-22 定稿日期: 2015-01-21
国家自然科学基金(61173100,61173101,61272375);福建省自然科学基金(2014J01218)
1003-0077(2016)03-0096-07
TP391
A
猜你喜欢
考试与评价·八年级版(2021年4期)2021-08-14
考试与评价·七年级版(2021年1期)2021-08-14
汉字汉语研究(2020年3期)2020-12-14
考试与评价·八年级版(2020年3期)2020-11-02
考试与评价·八年级版(2020年6期)2020-11-02
考试与评价·七年级版(2020年1期)2020-10-23
英语世界(2018年5期)2018-11-28
西夏学(2017年1期)2017-10-24
老年世界(2017年2期)2017-03-16
北京大学学报(自然科学版)(2016年1期)2016-10-12
