
一种交互式事件常识知识的获取方法
2016-05-04 01:15曹聪曹存根臧良军王石
中文信息学报 2016年3期
曹聪,曹存根,臧良军,王石
(1. 中国科学院 计算技术研究所 智能信息处理重点实验室,北京 100190;2. 中国科学院大学,北京 100049;3. 中国科学院 信息工程研究所,北京 100093)
一种交互式事件常识知识的获取方法
曹聪1,2,3,曹存根1,臧良军3,王石1
(1. 中国科学院 计算技术研究所 智能信息处理重点实验室,北京 100190;2. 中国科学院大学,北京 100049;3. 中国科学院 信息工程研究所,北京 100093)
赋予机器常识知识是使机器具有真正智能的必备条件之一,而获得这些常识一直是人工智能研究的一个重要课题。该文提出了一种通过交互的方式来引导知识贡献者给出关于事件的常识知识的方法。方法获取过程是一个机器与贡献者的交互过程: 机器动态地生成问题,对知识贡献者进行提问;知识贡献者通过回答问题给出常识知识。交互过程通过包含提示信息的提问问题对知识贡献者进行提示,运用七种类型问题层层递进地引导知识贡献者思考,以此唤醒他们大脑中的常识知识;通过动态变化的问题改善知识贡献者贡献常识知识过程的趣味性。同时,该文还引入可接受性和有效性两个定量标准评价提问问题,用于进一步改善交互过程。实验结果表明,知识贡献者运用此方法给出的知识量增加了451.61%,同时知识的正确率也达到了92.5%。
常识知识获取;事件常识;交互过程
1 引言
自从McCarthy[1]开展了第一个常识知识项目,常识知识问题已经成为人工智能界核心的研究课题,其中常识知识获取是常识知识问题的基础。
由于常识知识具有隐含性和多样性[2-3],从文本中自动抽取常识知识变得非常困难,因此,常识知识获取最可靠的方法是人工获取。人工参与的常识知识获取面临的一个困难是知识贡献者在给出常识知识的过程中非常枯燥无趣,造成知识贡献者流失。同时又由于常识知识的基础性[2]导致很多人会忽略常识知识,这样就会导致知识贡献者思考给出常识知识过程非常费力并且经过长时间思考还是想不出常识知识。以往的方法要么忽视存在的问题,要么用金钱来刺激知识贡献者,不能很好地解决上述两个问题。
本文介绍一种基于交互式提问引导知识贡献者的方法。机器通过提问的方式与知识贡献者进行交互,引导知识贡献者给出一类重要的常识知识——事件的常识性前提知识和后果知识。
交互过程借助于一个交互脚本,根据知识贡献者对当前问题的反馈来影响下一个问题的生成。知识贡献者看到动态变化的问题,会感觉常识知识输入的过程不再枯燥乏味。
提问问题基于问题模板自动生成。生成的问题包含提示信息,对知识贡献者起到刺激和提示的作用。提问问题会让知识贡献者得到一个明确具体的目标,以此来减轻知识贡献者的负担,进而有效地唤醒大脑中的常识知识。同时对于生成的问题我们会给出定量的衡量标准并将此用于改善提问交互的过程。
2 相关工作
当前流行的常识知识获取方法可以分为两类: 一种是人工编撰常识知识,另一种是自动获取。较为著名的项目是Cyc[4]和OpenMind[5]。Cyc是知识工程师手工编辑常识知识。他们将属性、动作、时空、事件等常识手工编辑入库。但是Cyc雇佣的知识工程师要熟悉Cyc自己定义的一门语言,这会给常识知识输入过程增加负担。OpenMind为非专家的网络用户提供了常识知识输入平台。但是OpenMind缺乏有效的刺激方法,并且网络用户多是非职业人士,因此知识贡献者思考给出常识知识的过程负担较重。
为了减轻人工给出常识知识过程负担并增加趣味性,与知识贡献者交互获取常识知识的方法相继出现。LEARNER[6]基于已有关于实体的知识库,实现类比推理,得到一些候选的知识,然后通过人工机械式地判断,以此获取常识知识。此方法缺乏交互,知识工程师效率低下。Common Consensus[7]通过询问两个知识贡献者完成一个目标需要些什么,知识贡献者通过两人给出一致性的答案来获取高积分,高一致性带来高质量的常识知识。Open Mind Commons[8]利用知识库中已有的知识进行推理,然后产生问题让知识贡献者进行回答,以此来填补知识库中的空缺。如果知识贡献者拒绝某一条知识还可以修改知识。
游戏20Q[9]利用知识库自动地产生20个问题,这些问题由游戏参与者回答。根据参与者的回答,机器去猜测出游戏参与者脑海中想象的实体,进而从答案中抽取常识知识。Verbosity[10]需要两个知识贡献者参与,其中一个描述概念,另一个猜测概念是什么。对概念的描述就是常识知识的来源。实验结果表明Verbosity有一定的趣味性,获得知识的正确率为85%。Concept Game[11]是一个facebook游戏,它的输入是通过文本挖掘方法得到的候选断言,知识贡献者为了获得积分来验证随机呈现给他们的断言。
为了降低人工获取常识的高成本,自动获取的方法相继出现。Matusz等人[12]利用Cyc中已有的知识作为种子,通过构造查询项,从Google的返回结果中抽取、验证新知识。Shah等人[13]也是利用Cyc中已有知识作为种子,在Web网页中抽取关于命名实体的信息。ConceptMiner[14]以ConceptNet[15]作为背景知识库,以搜索引擎为工具,利用信息抽取技术发现web中存在的常识。自动化的方法不能解决常识知识隐含性的问题,因此它只能作为人工获取常识知识方法的一种补充。
多年来,国内一批学者在常识知识研究方面也做出许多工作。HowNet[16]是最大的中英双语常识知识库,Zhishi.me[17]、Tsinghua-ChineseKB[18]、CASIA-KB[19]是另外三个规模较大的中文常识知识库。计算所NKI[20]课题组利用自动化的方法获取概念属性类常识[21]、因果常识知识[22]、简单事件常识知识[23]等,同时还提出了一种从多个视角人工分析获取事件的前提和后果知识的方法[24]。
3 事件的常识性前提知识和后果知识
有很多科研工作者针对工作的需要提出自己的事件表示模型[25-27]。本文采用中国科学院计算技术研究所NKI课题组基于鲁川的26类句模[28]修改和扩充的事件体系[24]表示事件,这里事件定义为由特定参与者参与的,在满足一定条件下发生的,并能对参与者或其周围世界造成一定影响的行为。事件模型被表示成一个五元组<句意,角色,语言模式,词类,例句>。 我们这里希望给五元组补充事件发生前后需要满足的条件和产生的后果,这是一种重要的常识知识——事件的常识性前提和后果知识。
为了获取知识,本工作呈现给知识贡献者的事件是五元组中事件的实例化例句,同时我们利用事件体系中的语言模式来识别实例化例句中的各种语义元素。实例化的例句呈献给知识贡献者有两个好处: 一是给获取到的常识知识提供上下文;另一个是实例化的例句不会抽象,这有利于知识贡献者思考常识知识,减轻知识贡献者负担。更长远的目标是通过对关于例句的常识性前提和后果知识抽象来获得关于事件的常识性前提和后果知识。
表1中给出了部分关于例句“爸爸迎娶了寡妇”的前提知识和后果知识。
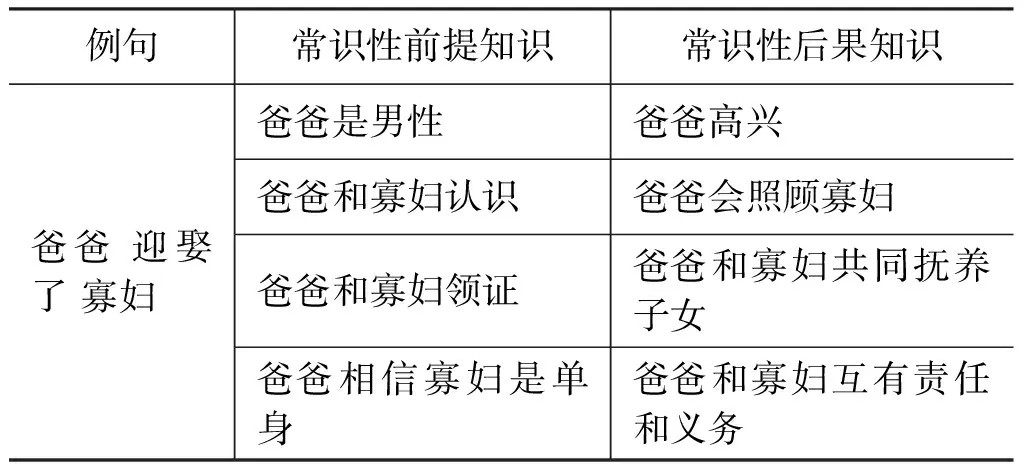
表1 “爸爸迎娶了寡妇”前提和后果知识示例
4 交互问题类型以及交互过程
与知识贡献者的交互过程是基于七种类型的问题驱动的,七种类型的问题从知识贡献者给出常识知识过程中总结得到。这七种类型的问题会根据当前的例句和知识贡献者的回答填充自己的缺失内容,同时还会根据知识贡献者的回答情况在不同类型间的问题之间进行变换。
4.1 交互问题类型
类型A 为了不影响知识贡献者的思考过程,解决提示信息会有偏向性引导的问题,我们只给出少量的提示信息,只提示让知识贡献者给出前提知识和后果知识。此类型问题模板如下:
<前提提问>∷=<例句>发生之前,应具备什么样的前提条件?
<后果提问>∷=<例句>发生之后,会产生什么样的结果?
其中,“<例句>”就是指知识贡献者看到的当前例句,例如“爸爸迎娶了寡妇”。在生成问题时就会用当前例句替换问题模板中的“<例句>”。
从问题类型A中的定义可以看到在问题中几乎没有任何提示信息。但是由于常识知识具有基础性,所以在没有任何提示信息的情况下知识贡献者要给出大量的常识知识是非常困难的。因此,我们需要在问题中加入提示性信息。
我们在彭会亮工作[23]的基础上总结了反映人们认知世界的生理、心理、社会、物理世界四个大类的常识知识角度[24],如图1所示。常识知识角度总体上分为四个大角度,每个大类角度下又分为若干个常识知识小角度。

图1 常识知识角度结构图
我们将常识知识角度作为提示性信息用来引导知识贡献者给出常识知识。对于知识贡献者,常识知识角度还是相对抽象一些,因此这里采用基于常识知识角度进行提问的方式来提示知识贡献者。由此我们定义问题类型B、C、D。
类型B 此类型的问题是当知识贡献者在想象不到常识知识后,将基于常识知识小角度(第三层的角度)生成的问题提供给他们,让知识贡献者有非常明确的目标,以此提示引导他们给出常识知识。此类型的问题是给每个常识知识角度整理属于自己的问题模板,结合当前的例句,动态地生成问题。下面给出“情绪”角度的问题模板:
<前提提问>∷=<例句>发生之前,<角色>的心情会怎么样?
<前提提问>∷=<例句>发生之前,和<角色>有关系的某个人的心情会怎么样?
<后果提问>∷=<例句>发生之后,<角色>的心情会怎么样?
<后果提问>∷=<例句>发生之后,和<角色>有关系的某个人的心情会怎么样?
其中,“<角色>”就是参与事件的事元,例如“施事”、“同事”等。问题模板实例化会用例句中的实例化事元替换“<角色>”。以“爸爸 迎娶了 寡妇”为例,上面问题模板中“<角色>”可以替换为“爸爸”或“寡妇”。篇幅的限制,后续问题介绍叶本文只给出后果知识的模板示例。
类型C 为了获取更多关于某一个常识知识小角度方面的常识知识,同时减少提示过程中的偏向性引导,这里不限制事元。以“情绪”角度为例给出问题模板:
<后果提问>∷=<例句>发生之后,还有其他角色心情会比较特殊吗,不是平静的心情?
C类型问题一般放在B类型问题之后,因为此类型问题相对B类型问题会抽象一些,先进行了B类型的问题提问后,有助于理解C类型问题,减轻知识贡献者的负担。
类型D 为了获取更多关于某一常识知识角度大类的常识知识,进一步减少提示过程中的偏向性引导,我们基于常识知识角度大类进行提问。以“心理”角度为例给出问题模板:
<后果提问>∷=<例句>发生之后,还有其他角色会有比较特殊的心理活动吗?可以从情绪、目标、态度、记忆等方面进行考虑。
D类型的问题要放在B、C类型问题之后,同样为了便于知识贡献者理解。
类型E 为了提高知识的准确性,需要反问知识贡献者。此类型问题是让知识贡献者反思给出的常识知识。
<后果提问>∷=<例句>发生之后,“<知识>”,是否加上一些条件后,会让“<知识>”发生或存在的可能性更大?如果想象到,请给出带有条件的后果。
其中,“<知识>”是知识贡献者已经给出的一条知识。“<知识>”可能是错误的也可能是不准确的,用E类型问题让知识贡献者进一步思考,进而获取更多、更准确的常识知识。例如“爸爸迎娶了寡妇之后,女方父母会高兴”。如果加上“女方父母赞成这门婚事”这个条件,此条知识会更准确。
类型F 为了利用已有知识获取更多的知识,根据当前知识的结果,问一下是否会有其他结果。此问题类型根据已有的知识,来产生一个问题。
<后果提问>∷=<例句>发生之后,一定会有“<知识>”的后果吗?是否可以在此后果的条件上增加或者更换一些内容,得到不同于“<知识结果>”的后果?如果想象到,请给出新的后果。
其中,“<知识结果>”是知识贡献者给出知识的结果部分。例如知识“如果父母不赞成这门婚事,父母会不高兴”,那么“父母会不高兴”就是“<知识结果>”的实例。
类型G 为了再次不限制知识贡献者的思路,解决引导偏向性问题,同时获取知识贡献者通过以上提示思考出新的常识知识。在经过所有提示方法后,再次在没有任何提示的情况下让知识贡献者给出前提知识和后果知识。
<后果提问>∷=经过以上的提示,<例句>发生之后,你能再给出一些其他的结果吗?请给出后果。
A、D、F、G这四种基本上没有偏向性引导的问题类型,不仅可以获取常识知识,而且还可以帮助我们获取更多地常识知识角度。因为这四种类型的问题最多只是含有少量的提示信息,特别是通过D、F、G这三种类型的问题获取到的常识知识,它们是通过前面B、C类型问题的提示引导,知识贡献者在思路打开之后通过自我想象给出的常识知识。知识贡献者在此种情况下有很大的可能给出其他不在常识知识角度规定类型下的常识知识,通过对这些新类型的知识进行总结,我们就可以得到新的常识知识角度。这样循环迭代下去,我们就能够有更多的提示信息,进而更多地减轻知识贡献者的负担,获取更多更丰富的常识知识。
4.2 交互过程
交互过程借用一个交互提问脚本,提问的整体过程分为三个阶段: 首先进行无偏向性A类型问题提问。如果知识贡献者给不出常识知识,再进行B、C、D类型问题的提问。B、C、D三种类型的问题按照其含有信息量由多到少进行提问,问题的偏向性也从大到小。这种由简单到困难的逐层深入的过程,也有助于引导知识贡献者进行深入思考,由此获取更好更多的常识知识。最后,在经过所有的提示后再进行G类型问题的提问。交互脚本如表2所示。
E类型的问题目标是为了提高知识的准确性,因此在交互过程中在知识贡献者给出一条常识知识后就会进行一次E类型问题的提问,让知识贡献者反思自己给出知识的准确程度。F类型的问题是为了通过已有知识获取更多的知识,我们将此种类型的问题随机的放在知识贡献者给出知识之后,在获取更多知识的同时也让提问过程具有变化性,改善提问过程的趣味性。
为了提高提问过程的变化性,我们在提问过程中都会采用一些随机性的选择,例如,随机选择常识知识角度(表2(5)),某一类型问题数目随机产生(表2(6)),随机进行F类型问题的提问等。

表2 交互过程脚本
5 交互问题质量的衡量
为进一步论证上一节的提问交互过程的合理性,我们需要引入必要的度量指标。
本文提出了两个指标。一是交互问题的可接受性,它用于衡量呈现给知识贡献者的问题是否符合自然语言语法和语义,如果一个问题不符合自然语言语法和语义,那么知识贡献者是看不懂问题的;另一个指标是有效性,它用于衡量问题能不能引导知识贡献者给出常识知识。如果用于提问的问题大部分都是不可接受或者无效的,整个交互过程中就会充斥着太多的冗余,这样就会让知识贡献者感到烦躁和无聊。
5.1 可接受性
可接受性是指系统自动生成的问题符合自然语言语法和语义的程度。这里我们让知识贡献者在看到问题后,对问题进行一个标注投票: 接受和不接受。如果知识贡献者看不懂提问问题就将此问题标记为不接受。利用知识贡献者标记的统计数据来衡量一个提问问题的可接受性。
这里我们可以利用知识贡献者标记的频率来作为问题可接受性的衡量标准,但是这种方法存在缺陷。因为如果一个问题被很多知识贡献者评价,另一个问题被很少的知识贡献者评价,那么前一问题的评价结果置信度更高。这里我们建立一个模型综合考虑频率和频度两个方面的因素。这个模型不仅和知识贡献者的投票比例成正比而且还考虑到这个比例的置信度。
模型中我们用sc(q)表示问题q被知识贡献者标记为接受的数目,nsc(q)表示问题q被知识贡献者标记为不接受的数目。m(q)表示知识贡献者对问题q的投票次数,即表示一个问题q被知识贡献者标记成接受和不接受的数目之和,即m(q)=sc(q)+nsc(q)。
定义1Pδ(q)表示知识贡献者投票问题接受的比率,如式(1)所示。
(1)
假设知识贡献者标记每个问题是独立的,我们可以把每一次标记当成一个伯努利实验。Pδ(q)表示知识贡献者能看懂问题的比率。
我们假设每个知识贡献者投票都是随机的。因此知识贡献者把问题分成接受和不接受的概率都是0.5。真实中的选择肯定不是0.5。如果我们不能拒绝假设,我们需要更多的信息(需要更多的人来评估当前问题)来判断当前问题能否让知识贡献者理解。
定义2ens(q)是效应值,表示问题被标记为不可接受的实际值和理想值之间的差距,即式(2)。
(2)
如果认为当前知识贡献者的选择是随机的,当前关于问题q的计数的概率可以用ps(q)来表示,如果ps(q)的值越低,当前计数的置信度越高。
定义3ps(q)表示二项分布假设检验的p-value,那么观察值和随机情况下相差ens(q)的概率为式(3)。
(3)
其中:
(5)
定义4ds(q)表示一个问题有意义能被知识贡献者看得懂的度量,也就是可接受性的度量如式(6)所示。
(6)
为了区分一个问题是否可接受,设定一个阈值α(α<0.5)。如果ds(q)<α,有1-α的置信度相信问题是不可接受的;如果ds(q)>1-α,有1-α的置信度相信问题是可接受的;如果有α 5.2 有效性 有效性是指系统自动生成的问题引导给出常识知识的效用程度。我们利用知识贡献者回答的次数和没有回答的次数来衡量问题的有效性。利用知识贡献者的回答与否这个数据建立模型来衡量问题是否能够有效获取常识知识。 同理我们应用上面的对问题可接受性进行度量的方法来衡量问题的有效性。 假设知识贡献者回答每个问题是独立的,我们可以把每一次回答当成一个伯努利实验。假设每个知识贡献者是否回答一个问题都是随机的。因此知识贡献者回答一个问题和不回答一个问题的概率都是0.5,真实中肯定不是0.5。同理,如果我们不能拒绝假设,我们需要更多的信息来判断当前这个问题是否是有效的。 参考可接受性的定义,最终我们会定义dv(q)。dv(q)表示一个问题的有效性的程度,这是一个定量度量。通过这个值可以判断一个问题是否有效,是否需要更多的信息来进一步判断。为了区分一个问题的有效性,同样需要设定一个阈值β(β<0.5)。 知识贡献者给出知识的过程中,利用可接受性和有效性来衡量一个提问问题,筛选出可接受性低的问题修改问题的生成方法,选择有效性低的提问将其去掉。当然还有一些问题需要进一步进行判断,我们会在知识贡献者的使用过程搜集更多的信息来进一步判断。迭代下去,高可接受性和有效性的提问问题会不断提高,提问交互过程会被不断改善。 为了评估我们的方法是否能够有效地刺激知识贡献者给出大脑中的常识知识,我们统计了通过各种类型提问问题获取常识知识的数目,如表4所示。A类型的问题不采用任何方法让知识贡献者去给出知识,B、C、D、E、F、G类型的问题都会给出不同程度的提示以及组合引导。将这两大类型的实验结果进行比较,结果表明本文方法能够引导获取更多的常识知识。 表4 未引导提示和有引导提示对比实验结果 表4中第一行和第二、三、四行分别列出了通过A类型问题和其他六种类型问题获得前提和后果知识的数目,可以看到通过A类型的问题得到62条知识,通过B、C、D、E、F、G类型的问题获得280条知识。我们可以看出知识的数目增加了451.61%。通过表中第四行中提示信息很少的问题类型D、F、G得到常识知识的数目可以看出,经过其他几种有提示信息类型问题的引导,知识贡献者能够进行思考,进而不用提示信息也能给出常识知识。通过上述结果可以看出交互式提问引导的方法能够获取更多的知识。 为了分析已获取到常识知识的正确率,我们从已获取的342条知识中随机选取40条知识,并召集五个具有较好常识知识背景的常识知识贡献者(不同前述的11个知识贡献者)对这40条知识进行判断分类。五个知识贡献者对这40条知识分别进行单独标记,将知识标记为“真”、“不知道”和“无意义”。如果五个人当中有三个人将一条知识赋予相同标记S,我们就认为当前知识的标记为S,如果关于一条知识没有一个标记得到投票次数超过3,我们就标记它为“无意义”。最终实验结果表明,最后标记为“真”的知识占总知识的数量的92.5%。 表5给出了其他方法和本方法获取知识正确率的结果比较。OpenMind评估知识标准时给每条知识赋予一个1~5的分值,最后其获取知识的平均得分是3.26,这里我们可以理解其正确率为60%左右。Verbosity标记知识为正确或不正确,其标记为正确的知识所占比例为85%。learner2的衡量方法和本文方法相似,其知识的正确率为89.8%。虽然这几个方法正确率衡量方法不同,但是从上面的描述可知,本文方法的效果明显高于其他方法。 表5 知识正确率结果比较 由表5可以看到我们的方法获取知识的正确率最高,这是因为本方法的提示引导策略。本方法能给知识贡献者有效的刺激和提示,能够让知识贡献者得到明确目标并进行思考,进而给出正确的知识。综上可以看出我们的方法在获取高质量的常识知识上是非常有效的。 常识知识是机器走向智能必不可少的一部分。本文提出了一种基于交互式提问引导获取事件常识知识的方法。方法基于常识知识角度等提示信息,对知识贡献者输入常识知识的过程进行引导和提示。通过提示和引导,知识贡献者获得明确的目标后进行深入的思考,最终给出更多更准确的常识知识。实验表明,提示引导过程能带来451.61%的知识增加量,且知识的正确率达到了92.5%。 虽然实验结果表明本文的方法是有效的,但是还有一些地方需要改进。其中交互脚本要具有更多的变化性和灵活性,因此下一步工作可以多设计几种交互过程,提高交互过程的变化性。下一步工作还要将获取到的自然语言形式的常识知识转化成计算机可以理解的结构化的形式,同时将关于例句的常识知识抽象到事件上。 [1] McCarthy,John. Programs with common sense[C]//Proceedings of the Teddington Conference onthe Mechanization of Thought Processes. 1958. [2] Liang-Jun Zang,Cong Cao,Ya-Nan Cao,et al. A Survey of Commonsense Knowledge Acquisition[J]. Journal of Computer Science and Technology,2013,28(4): 689-719. [3] Lenhart Schubert. Can we derive general world knowledge from texts?[C]//Proceedings of the second international conference on Human Language Technology Research. San Francisco: Morgan Kaufmann Publishers Inc.2002: 94-97. [4] Douglas B Lenat. CYC: A large-scale investment in knowledge infrastructure[J]. Communications of the ACM,1995,38(11): 33-38. [5] Singh P. The public acquisition of commonsense knowledge[C]//Proceedings of AAAI Spring Symposium: Acquiring (and Using) Linguistic (and World) Knowledge for Information Access. 2002. [6] Chklovski T. Learner: a system for acquiring commonsense knowledge by analogy[C]// Proceedings of the 2nd international conference on Knowledge capture. New York: ACM,2003: 4-12. [7] Lieberman H,D Smith,A Teeters. Common Consensus: a web-based game for collecting commonsense goals[C]//Proceedings of ACM Workshop on Common Sense for Intelligent Interfaces. 2007. [8] Robert Speer. Open mind commons: An inquisitive approach to learning common sense[C]//Proceedings of Workshop on Common Sense and Intelligent User Interfaces. 2007. [9] Robert Speer,Catherine Havasi,Dustin Smith. An interface for targeted collection of common sense knowledge using a mixture model[C]//Proceedings of the 14th international conference on Intelligent user interfaces. ACM,2009: 137-146. [10] Von Ahn L,M Kedia,M Blum. Verbosity: a game for collecting common-sense facts[C]// Proceedings of the SIGCHI conference on Human Factors in computing systems. New York: ACM,2006: 75-78. [12] Cynthia Matuszek,Michael Witbrock,Robert C Kahlert,et al. Searching for common sense: populating CycTMfrom the web[C]//Proceedings of the National Conference on Artificial Intelligence. London: AAAI Press,2005: 1430-1435. [13] Purvesh Shah,David Schneider,Cynthia Matuszek,et al. Automated population of Cyc: extracting information about named-entities from the web[C]//Proceedings of the Nineteenth International FLAIRS Conference. Melbourne Beach,2006: 153-158. [14] Ian Scott Eslick.Searching for commonsense[D].Cambridge,MA: Massachusetts Institute of Technology,2006. [15] Liu H,P Singh. ConceptNet—a practical commonsense reasoning tool-kit[J]. BT technology journal,2004,22(4): 211-226. [16] L Dong Z,Dong Q. HowNet and the Computation of Meaning[M]. Singapore: World Scientific Publishing Company,2006. [17] Niu X,Sun X,Wang H,et al. Zhishi.me: Weaving Chinese linking open data[C]//Proceedings of Proceedings of the 10th international conference on The semantic web. Berlin,Heidelberg. 2011: 205-220. [18] Wang Z C,Wang Z G,Li J Z,et al. Knowledge extraction from Chinese wiki encyclopedias[J]. Journal of Zhejiang University—Science C,2012,13(4): 268-280. [19] Zeng Y. Extracting,linking and analyzing the Web of structured Chinese data[R]. Beijing: Institute of Automation,Chinese Academy of Sciences,2012. [20] CAO Cungen,FENG Qiangze,GAO Ying,et al. Progress in the development of national knowledge infrastructure[J]. Journal of Computer Science and Technology,2002,17(5): 523-534. [21] Ya-nan Cao,Cungen Cao,Liangjun Zang,et al. Acquiring commonsense knowledge about properties of concepts from text[C]//Proceedings of Fifth International Conference on Fuzzy Systems and Knowledge Discovery. IEEE,2008: 155-159. [22] 曹亚男. 面向web语料的因果知识获取研究[D]. 北京: 中国科学院计算技术研究所,2012. [23] 彭会良. 人物相关事件的常识知识获取方法研究[D]. 北京: 首都师范大学,2010. [24] 李闪闪,曹存根. 事件前提和后果常识知识分析方法研究[J]. 计算机科学,2013,40(4): 185-192. [25] 王寅. 事件域认知模型及其解释力[J]. 现代外语,2005,28(1): 17-26. [26] 吴平博,陈群秀,马亮. 基于事件框架的事件相关文档的智能检索研究[J]. 中文信息学报,2003,17(6): 25-30. [27] 梁晗,陈群秀,吴平博. 基于事件框架的信息抽取系统[J]. 中文信息学报,2006,20(2): 40-46. [28] 鲁川,缑瑞隆,董丽萍. 现代汉语基本句模[J]. 世界汉语教学,2000,4: 11-24. An Interactive Method for Acquiring Event-Based Commonsense Knowledge CAO Cong1,2,3,CAO Cungen1,ZANG Liangjun3,WANG Shi1 (1. Key Laboratory of Intelligent Information Processing,Institute of Computing Technology,Chinese Academy of Sciences,Beijing 100190,China;2. University of Chinese Academy of Sciences,Beijing 100049,China;3. Institute of Information Engineering,Chinese Academy of Sciences,Beijing 100093,China) A large-scale commonsense knowledge is indispensible for intelligent machine,and commonsense knowledge acquisition has always been an important research area of artificial intelligence. This paper presents an interactive method to guide the contributors to give event-based commonsense knowledge. The process of knowledge acquisition is interactive: machine dynamically generates questions to a contributor,and the human presents commonsense knowledge by his answeres. In addition to the prompt information,seven types of questions are presented in a progressive order to guide the knowledge contributors to think,which also brings more interest to the contributing process. The results show that the interactive method increases the number of knowledge by 451.61% with accuracy of 92.5%. commonsense knowledge acquisition;event commonsense;interaction process 曹聪(1987—),博士,主要研究领域为知识获取,数据挖掘。E⁃mail:caocong@iie.ac.cn曹存根(1964—),研究员,主要研究领域为大规模知识获取与管理。E⁃mail:cgcao@ict.ac.cn臧良俊(1981—),博士,主要研究领域为知识的获取、表示与推理,机器学习。E⁃mail:zangliangjun@iie.ac.cn 2014-02-08 定稿日期: 2014-06-11 国家自然科学基金(30973713,61035004,61173063,61203284,91224006);国家社科基金重点资助项目(10AYY003);科技部项目(201303107)。 1003-0077(2016)03-0125-086 实验结果及分析


7 总结与展望

猜你喜欢
法律方法(2022年1期)2022-07-21
快乐语文(2021年31期)2022-01-18
今日农业(2020年15期)2020-12-15
现代商贸工业(2020年1期)2020-02-06
宁夏画报(2019年8期)2019-09-10
小火炬·阅读作文(2018年10期)2018-03-08
高中生学习·高一版(2017年11期)2018-01-15
青年文学家(2017年29期)2017-11-08
法制博览(2017年4期)2017-05-20
长江丛刊(2016年26期)2016-10-31
