
基于L1—L2混合噪声模型的图像超分辨率重建方法
2016-05-14 08:14李浚魁刘辉
价值工程 2016年6期
李浚魁 刘辉


摘要:文章提出了一种基于L1-L2混合噪声模型(HNM)方法用于图像、视频的超分辨重建,该方法有效利用L1范数在突变区域较好保持图像边缘信息的特点,同时兼顾了L2范数对图像平坦区域的噪声抑制特性。针对求解过程中噪声分布的改变,L1、L2范数的选择问题,提出一种自适应隶属度(AMD)方法,该方法不仅能达到理想的实验效果,而且大大地减少了迭代次数与运算时间。
Abstract: L1-L2 hybrid noise model (HNM) method is proposed in this paper for image/video super-resolution. This method has the advantages of both L1 norm minimization (i.e. edge preservation) and L2 norm minimization (i.e. smoothing characterization). In view of noise distribution changing and selecting L1 norm minimization or L2 norm minimization, the paper propose an efficient adaptive membership degree (AMD) method, which get the ideal result but the proposed AMD method can reduce the number of iterations and save much computational cost.
关键词:混合噪声模型;超分辨率;L1范数;L2范数;自适应隶属度
Key words: hybrid noise model;super-resolution;L1 norm;L2 norm;adaptive membership degree
中图分类号:TP751 文献标识码:A 文章编号:1006-4311(2016)06-0192-03
0 引言
超分辨率重建技术,利用拍摄目标的先验信息、单幅图像的信息以及多幅图像间的补充信息,以时间带宽换取空间分辨率,提取出低分辨率图像中的高频信息,使重建结果更接近于理想未退化的图像,广泛地应用于图像视频处理领域,如遥感图像,医学图像,视频监控和高清电视等。但由于其利用空域先验信息的能力的局限性,当前的研究多集中在空域。空域法主要有迭代反投影(Iterative back projection, IBP)[1]、凸集投影(Projection on to convex sets, POCS)[2]、最大后验概率估计(Maximum a posteriori,MAP)[3]以及最大似然估计(Maximum likelihood,ML)。其中,迭代反投影运算量小,收敛速度较快,但是难以利用先验约束信息,超分辨率结果不唯一。凸集投影和最大后验概率估计是目前研究最多的方法,其成像模型可以方便地利用先验信息,但是运算量大,收敛速度慢。最大似然估计可以看作最大后验概率估计在等概率先验模型下的特例[4]。
通常情况下,低分辨率图像需要预先进行运动估计,点扩散函数(PSF)估计以及亮度校正等[5-7]。在现实世界中,许多真实的图像、视频序列中,低分辨率图像、视频序列下观测模型中的噪声服从拉普拉斯分布(如椒盐噪声)[5,7],由于高斯噪声分布通常被看作是均值滤波器,它能够使图像具有更好的平滑效果,而拉普拉斯噪声分布通常被看作中值滤波器,它能够使图像保持良好的边缘效果[5]。
在本文中,我们提出了一种基于高斯分布和拉普拉斯分布的混合噪声模型。由于在超分辨率重建迭代过程中,噪声的分布会发改变,因此,我们提出了一种自适应隶属度(AMD)方法,该方法不仅能达到有效的实验效果,而且大大地减少了迭代次数与运算时间。
1 图像模型
1.1 观测模型
超分辨率重建图像序列的退化模型可用一个线性过程来描述,该观测模型可由下面的退化过程表示[7-8]:
yk=DkHkFkx+Nk,k=1,…,K (1)
其中,K是低分辨图像的个数,x是高分辨率图像,yk代表着第k幅低分辨率图像,Dk和Hk各代表下采样算子和模糊算子(系统的点扩散函数PSF),Fk表示第k幅低分辨图像的几何运动算子,NK表示第k幅图像的随机加性噪声。
1.2 运动模型
对于低分辨率图像的几何运动算子Fk的获取,本文采用平面投影运动模型(8DoF)[6]来获取,8DoF是从不同视角捕捉到的平面和近平面运动目标,乃至摄像机沿光轴旋转情况下进行运动建模的最佳方法。对于小范围、短时目标运动(如连续视频帧之间),8DoF变换能够在场景整体运动未知的情况下获得运动目标模型的足够的逼近精度。
1.3 模糊算子(PSF)
因此,从式(8)我们可得,如果比值v>0.7602,则噪声更倾向于高斯分布,反之,噪声更倾向服从拉普拉斯分布。
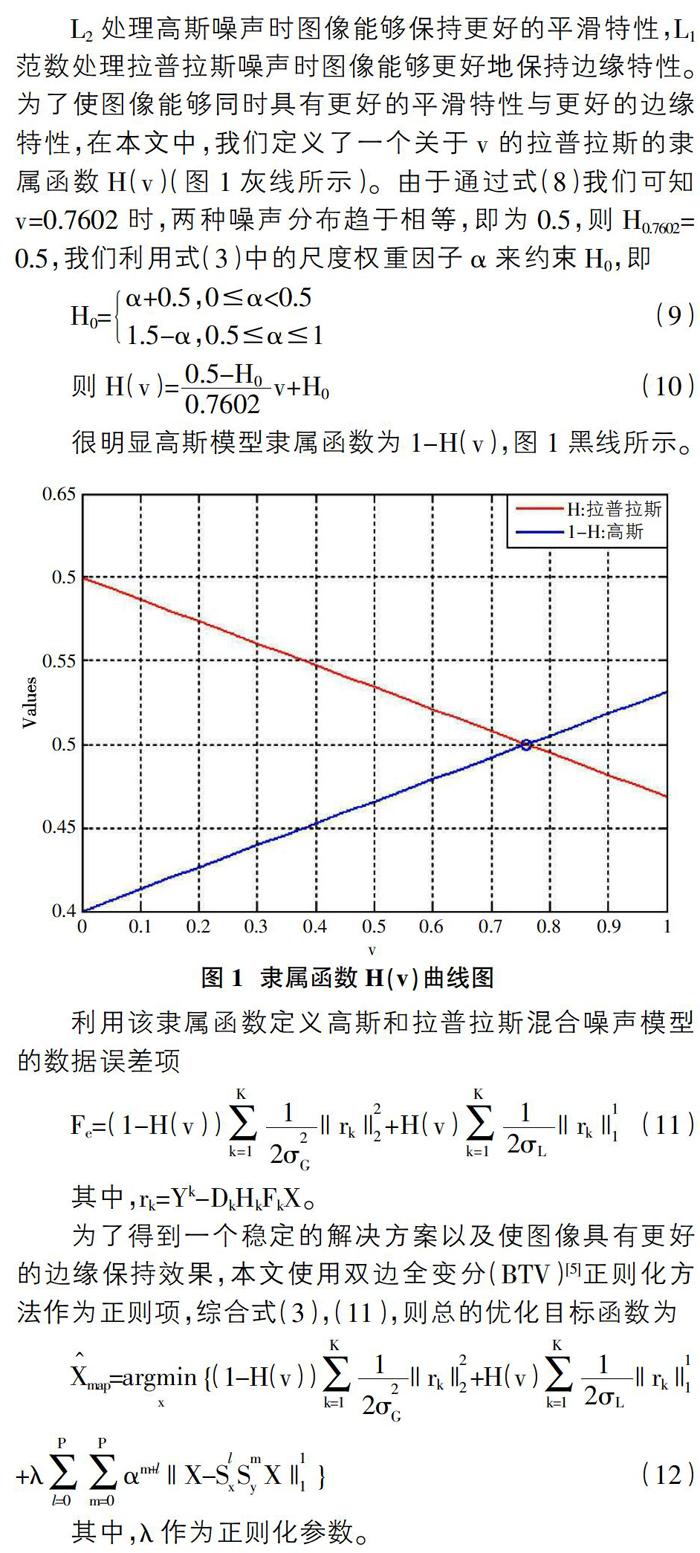
L2处理高斯噪声时图像能够保持更好的平滑特性,L1范数处理拉普拉斯噪声时图像能够更好地保持边缘特性。为了使图像能够同时具有更好的平滑特性与更好的边缘特性,在本文中,我们定义了一个关于v的拉普拉斯的隶属函数H(v)(图1灰线所示)。由于通过式(8)我们可知v=0.7602时,两种噪声分布趋于相等,即为0.5,则H0.7602=0.5,我们利用式(3)中的尺度权重因子α来约束H0,即
2.4 自适应隶属度方法(AMD)
我们使用SCG(scaled conjugate gradient)方法[8]来优化式(12)。随着迭代过程的进行,我们会发现式(12)中的数据误差项中的噪声分布会发生改变,因此在每次完成迭代过程后根据此时的数据误差项中的噪声分布更新H(v)的值,并且根据v的变化,我们提出了一种自适应隶属度方法(AMD),该方法的伪代码如表1所示。
3 实验与分析
本文分别将以L1范数和L2范数结合的BTV的超分辨率重建方法,记为L1BTV[5]和L2BTV[6],本文采用了实验图像为合成图像,分别加入了高斯噪声和椒盐噪声,并假设PSF和运动算子可知。为了验证本文提出的L1-L2混合噪声模型图像超分辨率方法(在下文中,称为HNM)的有效性,以及在保持图像平滑和保持图像边缘的优越性,本文将与L1BTV和L2BTV超分辨重建方法作实验对比。为了客观评估方法的性能,本文采用峰值信噪比(Peak signal to noise ratio,PSNR)和结构相似度(Structural similarity,SSIM )[6]超分辨重建图像客观质量的定量评价方法。
图2(a) 是其中一幅Lena退化后的低分辨率图像加入方差σ2为0.08高斯噪声,图2(b)是HNM方法重建的结果,图2(c)是L1BTV方法重建的结果,图2(d)是L2BTV方法重建的结果。从表2中可以看出,此时的HNM重建的Lena的峰值信噪比(PSNR)为36.41,结构相似度索引(SSIM)为0.9855,而L1BTV,L2BTV重建Lena的峰值信噪比(PSNR)分别为34.35和32.79,结构相似度索引(SSIM)分别为0.9842和0.9836。另外,从图3可以看到随着尺度权重因子α的变化,HNM方法与L1BTV,L2BTV方法重建图像的结构相似度索引(SSIM)变化趋势图也说明了本文方法要比L1BTV,L2BTV方法重建效果较理想。
4 结论
文章提出一种基本L1-L2混合噪声模型对图像进行超分辨重建方法,该方法结合了高斯模型与拉普拉斯模型的优点,我们设计一种关于这高斯模型与拉普拉斯模型关系的隶属函数,根据该隶属函数,在迭代过程中,我们可以很好的选择噪声模型分布。由于迭代过程中,噪声分布会发生改变,我们提出了一种自适应隶属度(AMD)方法,该方法可以很有效地结束迭代。通过以上实验结果,文章方法与L1BTV、L2BTV方法相比较,在处理不同噪声的时候具有较高的峰值信噪比(PSNR)和结构相似度(SSIM),而且在平滑、边缘保持等细节区域具有更好的重建效果。具有更好优越性。
参考文献:
[1]Irani M, Peleg S. Improving resolution by image registration[J]. CVGIP: Graphical models and image processing, 1991, 53(3): 231-239.
[2]禹晶,苏开娜,肖创柏. 一种改善超分辨率图像重建中边缘质量的方法[J].自动化学报,2007,33(6):577-582.
[3]Lee E S, Kang M G. Regularized adaptive high-resolution image reconstruction considering inAMDurate subpixel registration[J]. Image Processing, IEEE Transactions on, 2003, 12(7): 826-837.
[4]安耀祖,陆耀,赵红.一种自适应正则化的图像超分辨率方法[J].自动化学报,2012,38(4):601-608.
[5]Farsiu S, Robinson M D, Elad M, et al. Fast and robust multiframe super resolution[J]. Image processing, IEEE Transactions on, 2004, 13(10): 1327-1344.
[6]Pickup L C. Machine learning in multi-frame image super-resolution[D]. Oxford University, 2007.
[7]Farsiu S, Robinson D, Elad M, et al. Robust shift and add approach to super-resolution[C] Optical Science and Technology, SPIE's 48th Annual Meeting. International Society for Optics and Photonics, 2003: 121-130.
[8]Nabney I. NETLAB: methods for pattern recognition[M]. Springer, 2002.
