
基于数据挖掘的财险客户风险贡献评级管理
2016-05-30 00:06闫春孙海棠
技术与创新管理 2016年5期
闫春 孙海棠

摘 要:良好的客户细分管理能够帮助财险公司更好地管理运营成本与收益,更好地实现公司风险控制和利润最大化的要求。文中采用相关分析进行相关数据的处理,运用KMeans聚类分析、决策树C 5.0算法和改进的Apriori算法3种数据挖掘技术对财险客户从风险和贡献2个角度进行了数据挖掘分类分析,得到具备风险、贡献指向性的双维度客户细分特征变量,并根据这些特征变量,建立了客户风险-贡献分类矩阵,对不同类别的客户提出了不同的客户管理对策建议。
关键词:客户细分;决策树;关联规则;风险-贡献分类矩阵
中图分类号:F 840.65 文献标识码:A 文章编号:1672-7312(2016)05-0538-06
0 引 言
随着我国信息化进程的加快以及保险业的迅速发展,有效运用数据挖掘技术在激烈的市场竞争中赢得先机是大多数财险公司面临的巨大课题。在一些实施 CRM(客户关系管理)的企业,通过客户细分环节能够对客户进行精确的识别与分类,客户满意度和忠诚度均有明显提高。因此,各大财险公司也越来越注重客户细分环节的应用与管理,希望通过对各客户群采取针对性的商业策略,减少客户流失倾向,增强客户吸引和保留能力,实现企业利润最大化。
从大量的数据中提取有用信息的数据挖掘技术为客户细分管理的研究提供了更为有效的工具。国外学者在这一领域的研究较早。ShuHsien Liao(2009)等学者基于Apriori算法和聚类算法实现保户分类,通过对客户需求链的分析,给出了保险企业在新产品开发和客户营销方面的建议[1]。RoungShiunn Wu(2010)与YouShyang Chen(2011)运用KMeans聚类分析实现了客户细分[2-3]。Shui Hua Han等(2012)将决策树模型应用到高价值客户识别中,建立了简单实用的客户评价体系[4]。Ahmed Ghoniemd等(2015)应用非线性模型研究交叉销售问题中互补零售类别的分类和定价决策的联合优化,并对客户实现分类分级管理[5]。
国内在数据挖掘与客户细分的研究中虽起步较晚,但也有许多优秀的成果。樊志刚等(2014)指出商业银行面对未来竞争的三大有效措施——“大风控,大数据,大平台”[6]。陈希等(2010)通过交叉频数分析保单中风险较大的因素,在保户分类过程中应用了决策树、支持向量机、逻辑斯蒂回归和贝叶斯网络4种数据挖掘算法[7]。王新军,胡曼(2012)介绍了聚类分析在寿险中的应用[8]。刘晓葳(2013)采用CHAID模型、罗吉斯回归、CART模型,以及Apriori算法等方法,获得具备风险及贡献指向性的客户特征变量,构建客户风险-贡献特征矩阵,提出了相应的保险公司客户管理策略[9]。程瑞芬(2013)则从客户的年缴保费额度和年收入这2个维度建立了客户细分矩阵[10]。
经典的分类算法有聚类分析、CART算法、Logistic回归、决策树分析、支持向量机等。从研究结果来看,大多数学者只引用其中一种分类算法,少有用多种算法进行验证的。在分类维度方面,多是单维,即多从风险或贡献其中一个方面进行细分研究。文中从客户为公司带来的风险(理赔次数)及作出的贡献(年缴保费)2个方面来實现客户的细分管理,采用KMeans聚类算法对数据进行预处理,相关分析剔除无关变量,运用决策树C 5.0算法进行客户细分研究,引入布尔矩阵改进Apiori算法进行不同算法间的交叉验证,最终得到客户风险-贡献分类矩阵。
1 算法适用性分析与数据预处理
根据CRISPDM数据挖掘标准流程,建模步骤主要有商业理解、数据理解、数据准备、模型建立、模型评估、模型部署6个阶段。文中以帮助财险公司实现客户风险-贡献评级管理为商业目标,按照数据挖掘软件Clementine 12.0的需要进行数据准备,并基于算法实用性考量选取决策树C 5.0模型来提取客户风险-贡献特征变量,同时引入布尔型矩阵改进Apriori算法对分类结果进行交叉验证,最后建立风险-贡献分类矩阵,提出针对财险公司商业策略选择的相关建议。
1.1 算法适用性分析
KMeans算法首先通过迭代算法代计算“质心”,然后计算样本与质心的距离,再根据距离计算结果,把各样本指派到各个簇[11],文中运用KMeans算法分别实现了样本和指标聚类,以达到简化数据和验证决策树分类模型的目的。决策树算法利用归纳算法生成可读的规则和决策树,文中运用决策树C 5.0算法对事务数据库进行处理,生成客户分类规则和决策树模型。关联规则算法可以从大量没有规则的数据中寻找数据之间的关联性和其潜在的依存关系。文中引用改进型Apriori算法对决策树C 5.0算法产生的客户分类模型进行交叉验证。
Apriori算法原理简单明了,容易应用,但是其存在一个较大的缺点——时间消耗巨大。为更好地应用Apriori算法,文中引入布尔矩阵的改进模型进行关联规则的提取,以验证决策树模型结论的正确性。
引入布尔型矩阵的改进Apiori算法的基本思想表述如下:将事务数据库D(含有N个事务,M个项目)转化为一个仅用 0-1表示的M*N阶的布尔矩阵。矩阵中的每一行代表一个事务,每个事务都有唯一的标识TID.矩阵中的每一列代表一个项目。若事务i中含有项目j,则在矩阵中tij=1,否则tij=0.
扫描一次事务数据库D,即可将其表示成对应的布尔矩阵。此时,支持度的计算可以通过下面的公式进行[12-14]。
K-项集{Ii,Ij,…,Ik}的内积向量表示为Rij=Ri∧Rj∧…∧Rk,支持度为
Support(Iij…k)=(t1i∧t1j∧…t1k+t2i∧t2j∧…∧t2k+…tni∧tnj∧…tnk).
连接步的改进:若Ia和Ib不能连接,则Ia和Ib之后的所有k项集都不满足连接条件。故只要Ia和Ib不能连接,便不再需要判断Ia和Ib之后的所有k项集是否能连接,这样就可以减少循环的次数。剪枝步的改进:在通过k-1频繁项集 Lk-1生成k项候选项集Ck前,先对Lk-1中的各单个项目进行计数处理,记为|Lk-1(i)|,计算他们在Lk-1中出现的次数。若某项目的计数小于k-1,则删除含有该项目的项集,生成L′k-1,利用L′k-1自连接L′k-1∞L′k-1,生成Ck,从而减少由候选项级数量引起的不必要的连接和剪枝操作。
1.2 数据来源与预处理
算例分析使用了软件Clenmentine 12.0,数据来自4个地区,选取了与本次数据挖掘相关的字段组成数据集,这些字段包括客户号、住址、性别、出生日期、受教育程度、收入、职业、婚姻状态、是否负债、年缴保费、产品类型、有无理赔等。通过KMeans算法与相关分析算法剔除与“有无理赔”变量相关程度过低的变量,又因“理赔件次”变量与“有无理赔”同时提供客户理赔与否的信息,故可将其去除。对客户贡献特征变量做类似处理。为应用布尔矩阵改进Apriori算法,对数值型数据进行处理,使其转化为布尔型数据。
首先,财险的种类有6种,似乎不便建立布尔型矩阵,但是通过对数据的分析发现,这6种财险种类中有3类的保费很低,分别为1,30,60元,另外3种较高,分别为480,580,680元。而本研究中恰用保费标示客户贡献,所以,可以用“0”表示前3种类型,后3种用“1”表示,这是因为贡献高的客户必是购买后3种财险类型的保户。
第二,总共有4个地区,通过前面的聚类分析和决策树分析结果来看,1,4地区可以看作一类,2,3地区看作另一类。由于1,4地区发生理赔的风险较大,2,3区较小,用“1”表示1,4地区,“0”表示2,3地区。
第三,年龄数据。由决策树分析结果:18~32岁、67岁以上风险较大,32~50岁,50~67岁风险较小。故将18~32岁、67岁以上2个区间的数据用“1”表示,32~50岁,50~67岁区间的数据用“0”表示。
将处理好的数据存储为SPSS数据文件。
2 客户风险-贡献评级管理算例分析
文中研究的主要目的是建立客户细分矩阵,为财险公司产品销售提供有益建议。运用相关分析剔除重复变量信息,采用决策树C 5.0算法和关联规则中的布尔型改进Apriori算法分别实现客户细分,提供不同分类方法的交叉验证。
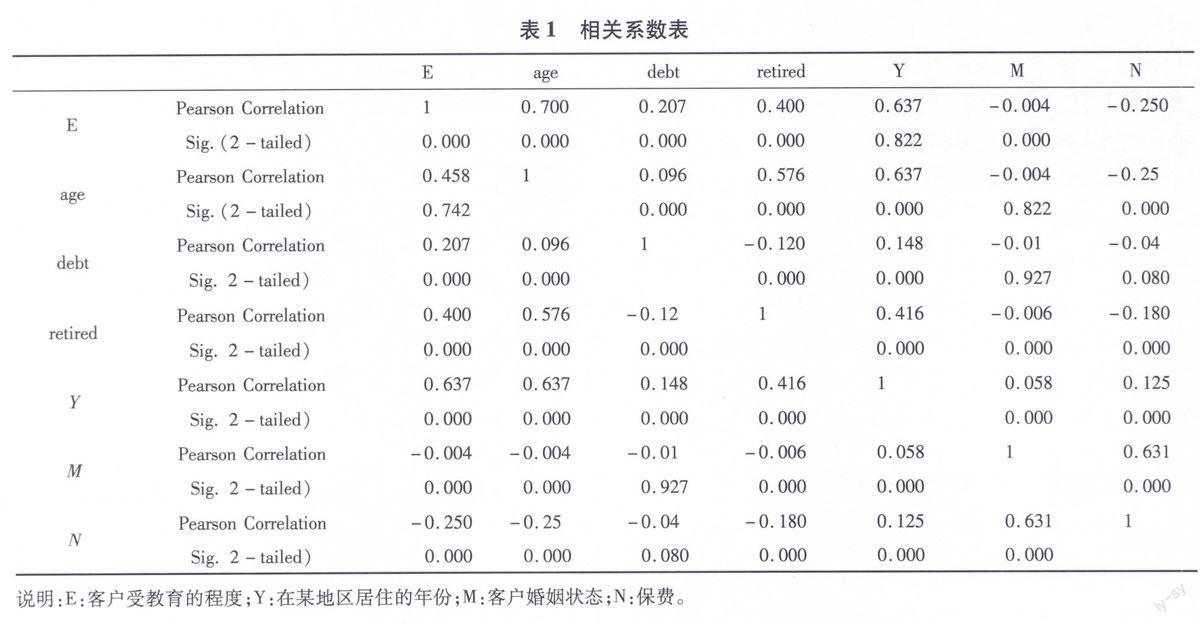
2.1 相关分析
为避免相关性较高的变量提供重复信息,通过对数据集中各个变量的相关分析,从相关性较高的变量中选取最具代表性的变量参与后续研究。表1只显示了一部分相关分析结果。
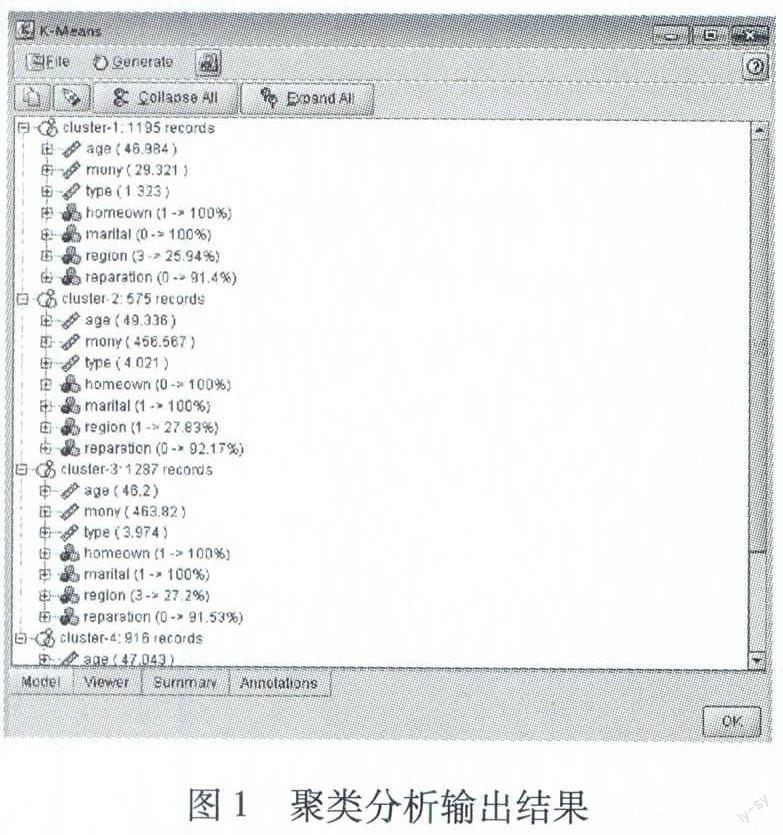
2.2 K-Means聚类分析
K-Means聚类的结果如图1所示。从聚类的结果来看,第一类发生理赔的概率是8.6%,第二类是7.83%,第三类8.5%,第四类是6.5%.因此,按照风险从大到小排序为:第一类,第三类,第二类,第四类。一二类的地区均为1,可见地区1发生理赔的风险较高。第二、三类的保费贡献是最高的,一、四类的保费贡献是较低的。
2.3 基于决策树C 5.0算法的客户风险-贡献评级管理
C 5.0模型根据能够带来最大信息增益的字段拆分样本,该模型对缺失值较为敏感,由于文中数据缺失值不是很多,直接将其剔除。选取前2 000个数据为训练集数据,后1 998个数据为测试数据,测试决策树预测模型的准确性。
将输出变量设置为“money”,测试客户贡献相关变量,实现基于客户贡献特征变量的客户分类。运行过程如图2,图3所示,图4显示了软件给出的分析结果。
从决策树C 5.0算法的输出结果可以看出,客户购买的产品类型对客户贡献变量的影响较大,但是由于产品类型与客户贡献的相关性较大,故而考虑按照地区分类:1,4地区为一类,2地区为一类,3地区为一类,与聚类分析分类结果相似。根据年龄划分,有4个年龄段,18~32岁,贡献最小,67岁以上的贡献最大,50~67岁相对低一些,32~50岁次之。
从分析结果可以看出,有92.54%的测试样本的预测值和实际值相符,7.46%的测试样本和实际值不符。平均正确性为0.901.始终正确的置信度为0.908,始终错误的置信度低于0.214.总体来说决策树模型预测正确率较高,可以采用。
将输出变量设置为“reparation”特征变量,实现基于风险的客户分类。结果分析与客户贡献的分析类似:1,4地區风险较大,其中1地区风险最大,2,3地区风险较小,其中3地区风险最小;年龄方面,18~32岁、67岁以上风险较大,32~50岁,50~67岁风险较小。
2.4 改进型Apriori算法交叉验证分析
用改进的Apriori算法进行客户风险交叉验证分析的结果见表2.
通过分析改进型Apriori算法的运行结果可以看出:地区为1,婚姻状况为1,保单类型为3的情况下,有无理赔的支持度为18.003%,置信度为93.002%,有较强的关联性,也就说明地区1,婚姻状况为1时,风险较大。其他6种关联规则可以类似分析。通过与决策树模型分析结果比较,两者较吻合,这就验证了决策树模型的准确性。
3 风险-贡献分类矩阵
公司战略制定过程中,最为简单直接的方法是波士顿矩阵分析,按照风险与贡献(高、低)组合,将客户群分为高风险高贡献、高风险低贡献、低风险高贡献、低风险低贡献4种类型,建立的风险-贡献特征矩阵如图5所示。
对公司来说,高风险低贡献客户是价值最低的客户,而低风险高贡献客户是公司应该努力长期维持的客户。高风险低贡献客户的特点是:年龄在18~32岁年龄段,地区类别为2,购买快递邮包险,一般为女性。低风险高贡献客户客户的特点是:32~50岁年龄段,婚姻状态为已婚,购买家财保障计划险和地震平安险。
4 财险公司商业策略选择建议
客户分类的目的之一就是针对不同的客户群体采用不同的商业策略,根据上面的客户风险-贡献矩阵可以实行以下的客户分类管理。
1)高风险低贡献客户商业策略。适当采取拒绝保险合约的风险规避策略,开展雇员培训,严格规范该类客户的申报审核程序,制定更加严格的保险赔付条例。
2)高风险高贡献客户商业策略。在防止客户流失的基础上以控制风险为主,采取较第一类客户较为缓性的风险规避制度。严格核实客户损失,严格规范保险赔付制度。
3)低风险低贡献商业策略。对该类客户应采取防止客户流失的策略,强化公司与客户的沟通,增强服务意识,积极创造条件推进该类客户向更高贡献级过渡。
4)低风险高贡献客户商业策略。该类客户是公司绝大部分利益的创造者,是公司管理的主要目标群,应及时开展客户信息回馈并适时推出新保险品种以满足客户的不同需求。
5 结 语
文中从风险和贡献2个维度建立了财险公司客户细分模型,在模型的建立过程中,综合应用了相关分析、聚类分析和决策树C 5.0算法,并引用改进的Apriori算法对模型结果进行了交叉验证。相关分析和聚类分析具有简单、实用的特点,能够对数据进行有效地分类处理,简化了建立决策树模型时参与建模的变量数量,为决策树模型的建立奠定了很好的基础。
决策树模型从风险和贡献2个角度对财险公司客户进行了分类,详细分析了各类客户的特点,对客户进行精准分类不仅能够帮助公司制定针对性的策略留住原有顾客,还能帮助公司制定更加精准的销售策略,发展更多优质客户。引入布尔型矩阵的Apriori改进算法,能够有效地提高算法的运行效率,大大节省存储空间和运行时间。通过运用此改进算法对决策树分类模型进行了交叉验证,验证结果表明,文中所建立的决策树模型可以有效进行财险公司的客户细分及分类评级管理。
参考文献:
[1] LIAO Shu-hsien,WU Chi-chuan.The relationship among knowledge management,organizational learning,and organizational performance[J].International Journal of Business and Management,2009,4(4):64-76.
[2] WU Roung-Shiunn,Po-Hsuan Chou S.Customer segmentation of multiple category data in ecommerce using a soft-clustering approach[J].Electronic Commerce Research and Applications,2010,10(3):331-341.
[3] CHEN You-Shyang,Ching-Hsue Cheng,Chien-Jung Lai,et al.Identifying patients in target customer segments using a two-stage clustering-classification approach:A hospital-based assessment[J].Computers in Biology and Medicine,2011,42(2):213-221.
[4] Shui Hua Han,Shui Xiu Lu,Stephen C H,et al.Segmentation of telecom customers based on customer value by decision tree model [J].Expert Systems with Applications,2012,39(4):3 964.
[5] Ahmed Ghoniem,Bacel Maddah.Integrated retail decisions with multiple selling periods and customer segments:Optimization and insights[J].Omega,2015,55:38-38.
[6] 樊志剛,黄 旭,谢尔曼.互联网时代商业银行的竞争战略[J].金融论坛,2014(10):3-10,20.
[7] 陈 希,李迪安,高 星,等.数据挖掘技术在保险客户理赔分析中的应用[J].统计与决策,2010(4):154-158.
[8] 王新军,胡 曼.寿险交叉销售的聚类技术实务分析[J].保险研究,2012(1):86-95.
[9] 刘晓葳.基于数据挖掘的保险客户风险—贡献评级管理[J].保险研究,2013(3):100-109.
[10]程瑞芬.基于数据挖掘的保险业客户识别与开发研究[D].郑州:河南工业大学,2013.
[11]蒋雪梅.基于改进人工蜂群算法的聚类研究[D].大连:大连海事大学,2014.
[12]王培吉,赵玉琳,吕剑峰.基于Apriori算法的关联规则数据挖掘研究[J].统计与决策,2011(23):19-21.
[13]罗 丹,李陶深.一种基于压缩矩阵的Apriori算法改进研究[J].计算机科学,2013(12):75-80.
[14]王达明.基于云计算与医疗大数据的Apriori算法的优化研究[D].北京:北京邮电大学,2015.
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
中国市场(2016年36期)2016-10-19
电脑知识与技术(2016年21期)2016-10-18
商(2016年27期)2016-10-17
大众理财顾问(2016年9期)2016-10-11
大众理财顾问(2016年8期)2016-09-28
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
