
孪生支持向量机的特征选择研究
2016-06-17 02:58王方红黄文彪
浙江工业大学学报 2016年2期
王方红,黄文彪
(浙江工业大学 之江学院,浙江 杭州 310024)
孪生支持向量机的特征选择研究
王方红,黄文彪
(浙江工业大学 之江学院,浙江 杭州 310024)
摘要:针对机器学习中数据分类的特征选择问题,提出了孪生支持向量机( Twin support vector machine, TWSVM)的另一种方法:LFTWSVM.首先求解TWSVM优化问题后将得到两个权重向量,先将这两个权重向量进行归一化处理,再把处理后的两个权重向量取绝对值相加,得到一个总权重向量,最后将总权重向量进行特征选择.通过实验,将得到的数据结果和TWSVM特征选择方法进行比较,LFTWSVM特征选择方法具有一定的优势.
关键词:机器学习;特征选择;支持向量机;权重向量
支持向量机作为机器学习的一种算法,已得到广泛应用,如人体姿态识别[1]、ATM机异常行为识别[2]等,而支持向量机算法中的特征选择对于机器学习来说是非常重要的[3].在机器学习过程中,所用到的特征可以有几百,甚至几千,这对于算法中的运算量是十分庞大的.近几年的研究显示一些机器学习算法受不相关和冗余特征的负面影响,如利用那些对分类问题作用不大或者那些对该分类问题起到相反作用的特征不仅加大了运算的计算量,耗费运算时间,而且还降低了模型的准确率,使得学习的意义相对较小.所以,对某个学习算法通过训练样本进行预测未知样本之前,得先确定哪些特征需采用,而哪些特征需被删除,这就是特征选择的意义之所在[4-5].前几年,Jayadeva等提出了一种新的分类方法——孪生支持向量机(TWSVM)[6],此分类方法是寻求两个非平行的分类超平面,要求每个超平面离一类数据点尽可能的近,而距离另外一类数据点尽可能的远,此分类方法的运算量仅为传统的支持向量机的四分之一[7].在适合用TWSVM来进行分类的模型中,目前尚无有效的特征提取算法提出[8].在此利用TWSVM的方法结合标准支持向量机(Support vector machine,SVM)的特征选择思想,构造了基于TWSVM的特征选择方法LFTWSVM(Lable fold twin support vector machine,LFTWSVM),且给出了算法.此算法的主要思想是利用两个权重向量,这两个权重向量分别是正负两类训练集的指导,相对于SVM的特征选择方法中的单一权重向量多了一层考虑.
1SVM特征选择方法
在图1中,空心点和实心点分别代表两类样本,中间的H表示最优分类超平面,H1,H2分别表示平行于H的分类面,它们之间的距离就是分类间隔.所谓最优分类面即要求分类面不仅仅可以把两类正确分开,并且使分类间隔达到最大[9].

图1 线性可分两类点Fig.1 Linear separable two kinds of points
在线性可分情况下,构建最优超平面,使得平行于分类面H的H1和H2之间的分类间隔最大,就转化为下面的二次规划问题:
(1)
求解这个最优化问题得到了权重向量ω和常数b,构造决策函数为
f(x)=sgn((ω·x)+b)
(2)
在权重向量ω中,每个分量代表的是各自特征在决策函数中所起到的权重值,若ω中的某个分量|ωj|绝对值越大,则该第j个特征在决策函数中所起到的作用就越大,因此可以利用线性支持向量机中的权重向量进行特征选择,具体算法如下[10]:
步骤1输入数据X,Y,将X进行归一化处理.
步骤2将数据代入线性支持向量机最优化的求解过程,得到权重向量ω.
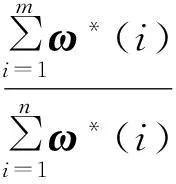
步骤4保留所记录的特征,删去没被累加的特征.
2TWSVM和 LFTWSVM特征选择方法
TWSVM的分类原理是寻找两条不平行的分类超平面,使得一条分类超平面与两类样本点的其中一类点最接近,同时与另一类点的距离尽可能的远[5],如图2所示.
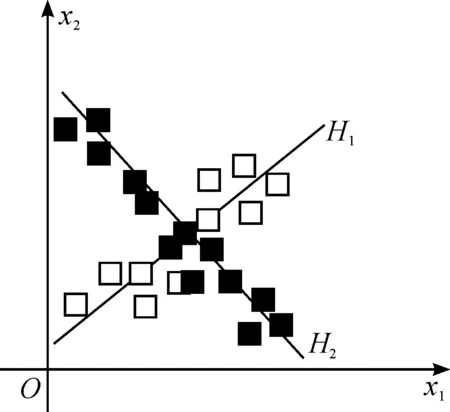
图2 线性不可分两类点Fig.2 Linear non separable two kinds of points
图2中的样本点有较多是交叉混淆在一起的,如果利用SVM来进行分类,必定有较多的样本点被错分,导致分类效果不佳.TWSVM与SVM主要区别是:TWSVM解决的是两个二次规划问题,然而SVM解决的是一个二次规划问题.
在TWSVM中,首先假设全部属于+1类的样本点记为A∈Rm1×n,在这第i行表示的是一个样本点;类似地,B∈Rm2×n代表属于-1类的样本.然后对两类样本点进行拟合求出最优的分类超平面,因此要将样本点进行归类.
与SVM不同的是,TWSVM寻找一对不平行的分类超平面:
(3)
使得每条分类超平面与一类点距离较近,而与另一类样本点的距离较远,此处ω1∈Rn,ω2∈Rn,b1∈R以及b2∈R.这里经验风险计算式为
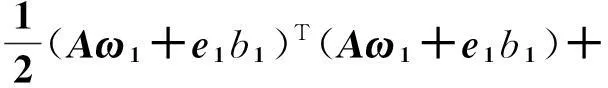
(4)

(5)
式中:c1>0,c2>0为参数;e1,e2为相应维数的全1向量.
因此,TWSVM求解的是一对最优化问题:
(6)
(7)
这个最优化问题求解得到的是两个分类超平面、两个权重向量ω1和ω2.该TWSVM的决策函数为
(8)
该式的意义为样本点距离哪个分类超平面距离较近则该样本点就归属于相应的类别.
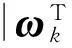
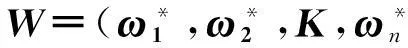
下面将LFTWSVM的特征选择方法的算法介绍如下:
步骤1输入数据X,Y,将X进行归一化处理并且将X分成正负两类A,B.
步骤2用十折交叉验证法求得TWSVM的最优参数,并用所得的最优参数进行TWSVM的训练,由此获得两个权重向量ω1和ω2.
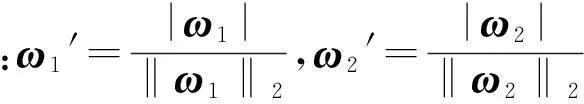
步骤4删除没有被累加的特征,保留被累加的特征.
3数据实验及结果分析
为了验证LFTWSVM的特征选择方法的可行性,采用了UCI[11]机器学习资源库的数据进行数据实验.此次实验在Pentium(R) Dual-Core 2.80 GHz处理器、2 GB内存以及Matlab7.0仿真软件的计算机上进行的.
该实验的主要过程是将同一个数据运用未经过特征选择的TWSVM方法以及笔者提出的LFTWSVM方法进行模型选参,十折交叉验证最优准确率,并将所得到的结果做两个方面的实验比较:使用的特征数量和最优准确度,如表1所示.
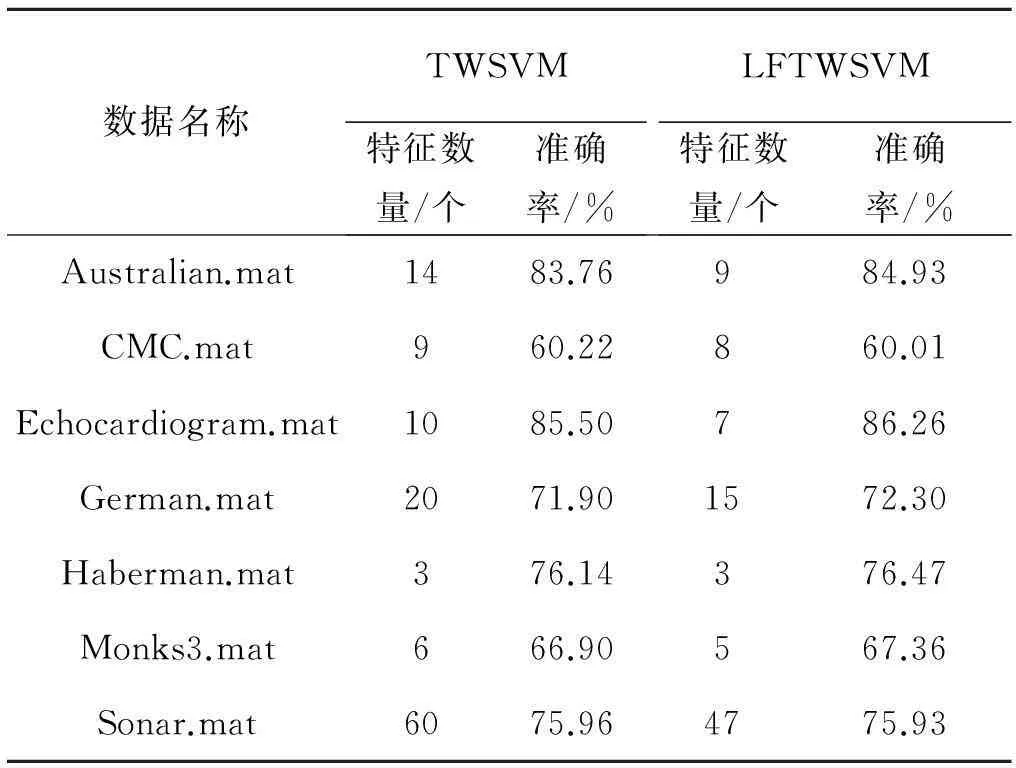
表1 两种方法数据实验结果
本次实验中阈值α取0.9.从表1中可以看到: LFTWSVM特征选择方法确实删去了冗余的特征,并且获得了更好的分类效果.例如:对于Australian这组数据,采用LFTWSVM特征选择的方法准确率为84.93%,所用到的特征数量只有9个,但是TWSVM特征选择方法利用了数据集的所有特征,却只有83.76%的准确率,LFTWSVM特征选择方法明显优于TWSVM的特征选择方法.
4结论
利用求解SVM得到的权重向量进行特征选择的原理,将此方法运用到TWSVM的模型中.把求解TWSVM得到的两个权重向量进行归一化后取绝对值相加的方法进行合并,获取了另一个权重向量,接着提出了LFTWSVM特征选择算法,经过理论分析和实验数据的验证,我们可以看出LFTWSVM的特征选择方法不仅删除了冗余的特征,且获得了较好的准确率.
参考文献:
[1]郑莉莉,黄鲜萍,梁荣华.基于支持向量机的人体姿态识别[J].浙江工业大学学报,2012,40(6):670-675.
[2]陈敏智,汤一平.基于支持向量机的针对ATM机的异常行为识别[J].浙江工业大学学报,2010,38(5):546-551.
[3]邓乃扬,田英杰.数据挖掘中的新方法——支持向量机[M].北京:科学出版社,2004:348-350.
[4]张丽新,王家钦,赵雁南,等.机器学习中的特征选择[J].计算机科学,2004,31(11):180-184.
[5]TAN J Y, ZHANG Z Q, ZHEN L, et al. Adaptive feature selection via a new version of support vector machine[J]. Neural computing and applications,2013,23(3/4):937-945.
[6]SHAO Yanhai, DENG Naiyang, CHEN Weijie, et al. Improved generalized eigenvalue proximal support vector Machine[J]. IEEE signal processing letters,2013,20(3):213-216.
[7]SHAO Yanhai, WANG Zhen, CHEN Weijie, et al. A regularization for the projection twin support vector machine[J]. Knowledge-based systems,2013,37:203-210.
[8]SHAO Yanhai, ZHANG Chunhua, WANG Xiaobo, et al. Improvements on twin support vector machines[J]. IEEE transactions on neural networks,2011,22(6):962-968.
[9]杨志民,刘广利.不确定行支持向量机——算法及应用[M].北京:科学出版社,2012:56-60.
[10]CHEN Yiwei, LIN C H. Combine SVMs with various feature selection strategies[J]. Studies in fuzziness and soft computing,2006,207:315-324.
[11]ISABELLE G, JASON W, STEPHEN B, et al. Gene selection for cancer classification using support vector machines[J]. Machine learning,2002,46:389-422.
(责任编辑:陈石平)
Research on feature selection of twin support vector machine
WANG Fanghong, HUANG Wenbiao
(Zhijiang College, Zhejiang University of Technology, Hangzhou 310024, China)
Abstract:Aiming at the feature selection problem of data classification in machine learning a new method of twin support vector machine(TWSVM) is proposed: LFTWSVM Firstly, two weight vectors can be gotten after the SVM optimization problem is solved. Then, these two weight vectors will be normalized, and be summed together with their absolute values. A total weight vector can be gotten and features will be selected from the total weight vector. The experiments show that the feature selection method in LFTWSVM has rather advantages compared with the TWSVM.
Keywords:machine learning; feature selection; support vector machine; weight vector
收稿日期:2015-10-12
作者简介:王方红(1981—),女,浙江路桥人,助理实验师,研究方向为机器学习与数据挖掘,E-mail:390425074@qq.com.
中图分类号:O232
文献标志码:A
文章编号:1006-4303(2016)02-0146-04
猜你喜欢
福州大学学报(自然科学版)(2022年1期)2022-01-21
河南科学(2021年3期)2021-05-06
自动化学报(2017年5期)2017-05-14
电子制作(2017年23期)2017-02-02
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
价值工程(2016年29期)2016-11-14
科学与财富(2016年28期)2016-10-14
