
无线mesh网络中编码感知的跨层优化机制
2016-06-20 09:17王伟平王建新
系统工程与电子技术 2016年6期
杨 湘, 王伟平, 王建新
(1. 中南大学信息科学与工程学院, 湖南 长沙 410083;2. 武汉科技大学计算机科学与技术学院, 湖北 武汉 430081)
无线mesh网络中编码感知的跨层优化机制
杨湘1,2, 王伟平1, 王建新1
(1. 中南大学信息科学与工程学院, 湖南 长沙 410083;2. 武汉科技大学计算机科学与技术学院, 湖北 武汉 430081)
摘要:无线网络的广播和易于侦听的特点,使得网络编码技术能够很好地应用于无线网络中,以提高无线网络的吞吐量。通过理论分析和仿真实验发现,IEEE802.11标准的MAC层机制会使得成功竞争到信道的节点在短时间内在竞争信道方面更具优势,这会导致编码节点在短期内获得的属于不同编码流的数据包数目不均衡,从而丧失很多的编码机会。提出了一种跨层协作的优化机制,在编码节点根据编码流的队列占用情况计算编码流的优先级别,并将其发送给相应上游节点以调节MAC层参数,进而平衡编码节点中参与编码的不同流的队列占用率,增加编码机会。仿真实验结果表明,这种编码感知的跨层优化机制,能够很好地协调参与编码的流的速率,提高了整个网络的吞吐量。
关键词:无线mesh网络; MAC协议; 网络编码; 跨层优化
0引言
无线网络天生具有的广播和易于侦听的特性,使得网络编码技术能够很好地应用于无线网络环境,提高了网络的吞吐能力。流间编码的研究主要针对网络局部范围的编码和解码,文献[1]中首次提出了结合流间编码的转发机制COPE,其基本思想是编码节点通过对编码条件的判定,将属于不同单播流的数据包进行编码操作,然后再进行广播发送;而参与编码的单播流的下游节点通过对邻居节点的侦听,保证对接收到的编码包以一个足够大的概率进行解码,得到原始数据包。通过这样的方式,在一次传输时间内,发送了多个数据包,从而减少了传输次数,提高了网络的整体吞吐量。
COPE机制提出之后,人们针对流间编码机制进行了大量的研究。一部分研究工作集中在编码方案的设计和性能分析上,而另一部分研究工作则集中在基于编码感知的路由协议方面。在针对编码方案设计的研究工作中,人们针对各种不同的网络场景提出了多种编码方案。其中文献[2]在2跳局部网络场景下考虑了2条流进行编码的情况,对COPE进行建模,并分析了其性能表现以及相对传统的单径路由的吞吐量增益;文献[3]则分析了在2跳局部网络场景多条流进行编码的情况下,不同的流数量对吞吐量的影响,并基于“编码对齐”提出了一种编码机制,有效地提高了网络的吞吐量;另外文献[4-6]则利用“干扰对齐”、“线性规划”和“整数规划”等技术讨论了编码方案的设计与实现;文献[7]则通过建立网络效用最大化方程,分析并设计了一种结合流间编码和流内编码的编码机制,在考虑链路丢包率和不需要邻居节点侦听队列信息的情况下,能很好地提高网络的吞吐量。目前研究的编码系统分为两种:确定编码系统和随机编码系统,确定编码系统中根据显式的通知报文来做出编码决策;而随机编码系统根据侦听链路的报文传输成功概率来做出编码决策,文献[8]推导出了确定编码系统下的吞吐量区间以及随机编码系统下的编码限制区域,并提出了一种简单高效的编码机制,能很好地提高吞吐量。在文献[9]中作者研究了在考虑一条多播流或多条单播流的不同场景下网络编码机制的收益区间。文献[10]研究了在IEEE802.11s机制下编码延时对无线mesh网络吞吐量的影响,并提出了一种自适应调整编码延时的机制,以提高网络编码的吞吐量增益。
此外,大量的研究工作都集中在基于编码感知的路由协议方面,这类研究工作的出发点在于利用流间网络编码提高吞吐量的特点,在寻找路由时将编码机会作为路由度量值的计算指标之一,更多地增加传输路径上的编码机会,提出了一系列的基于编码机会感知的路由协议[11-19]。DCAR[14]提出了一种分布式的基于编码机会感知的路由协议,在路径度量值的计算中考虑了链路的编码机会,使得具有更多编码机会的结点更容易被选为路由的中继节点,从而利用网络编码的优势提高网络的整体吞吐量;CORE[15]通过将逐跳机会转发和流间编码相结合,达到提高吞吐量的目的;PNCAR[18]在计算链路的度量值时考虑了数据流之间的编码关系,同时将实际网络映射为一个虚拟网络以解决了路由协议的等分性问题,能够在无线多跳的场景下提高网络的吞吐量。
目前大部分的研究工作都是从路由层面出发,通过改变路由机制使得中间节点获得更多的编码机会,或者同时考虑了拥塞、负载均衡等问题,从而提高整体吞吐量。但是很少有人研究MAC层机制对局部网络编码机会的影响。文献[19]指出了现有的MAC层机制会影响编码流和非编码流之间的公平性,从而影响编码机会的产生,提出了一种虚拟队列的轮询机制,使得编码数据包能获得更多发送机会,从而能更充分发挥网络编码提高吞吐量的优势。但是文献[19]仅仅考虑了MAC层机制对编码流与非编码流之间公平性的影响,并没有注意到MAC层机制会影响不同编码流之间的公平性。我们观察到由于IEEE802.11MAC层的退避窗口调整机制,会导致可编码流短期内到达编码节点的数据包数目是不平衡的,从而导致很多编码机会的丧失。在本文的研究工作中,我们首先分析了IEEE802.11MAC层机制导致短时间内可编码流到达的不平衡性,并通过仿真实验验证了这种不平衡性的存在及对编码机会的影响。然后,我们基于跨层设计的方法,提出了一种无线mesh网络中编码感知的跨层优化机制CACLOM (coding-aware cross-layer optimization mechanism),能有效地增加编码节点的编码机会,提高网络的整体吞吐量。
1IEEE 802.11 MAC机制对编码机会的影响
流间编码示意图如图1所示,节点存在f1(n1->n3->n2)和f2(n4->n3->n5)两条流,数据包p1和p2分别属于流f1和f2,节点n3先后收到p1和p2,由于n5能够侦听到n1的数据包p1,而n2能够侦听到n4的数据包p2,n3就可以将数据包p1和p2编码成p1⊕p2数据包进行发送,而当节点n2和n5收到编码数据包p1⊕p2后就能够解码分别得到数据包p1和p2。
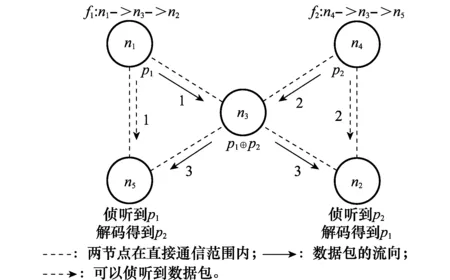
图1 流间编码示意图
在IEEE802.11MAC机制中,网络中的节点共同竞争信道资源,当一个节点竞争到信道并成功发送数据帧之后,它的竞争窗口被设置成最小值CWmin,而发送失败的节点会将它的竞争窗口增大一倍。这种机制会导致成功竞争到信道的节点比发送失败的节点在竞争信道方面具备更大的优势,进而抢占更多的发送机会,从而导致成功获得信道的流在短期内更易获得发送机会。在图1的场景中,节点n1和n4都要向节点n3发送数据包,若节点n1成功竞争到信道则会调低竞争窗口,若此时节点n4发送数据包失败则会增加自己的竞争窗口,那么节点n1在和节点n4竞争信道时短期会更具备优势。这样在节点n3中,短期内属于流f1的数据包会相对比较多,而属于流f2的数据包则会相对少甚至没有,这样会影响编码机会的产生。
为了观察不同链路丢包率对吞吐量以及编码机会的影响,利用图1的“X”型拓扑网络做了一个简单的实验。节点网络层采用AODV路由协议,链路层采用MAC802.11b协议;节点的通信距离为150m,侦听距离为330m,无线链路带宽为11Mbps。网络中节点n1到n2之间有一条UDP流f1,n4到n5之间有一条UDP流f2,速率均为1Mbps,每个数据包大小固定为512字节,按照网络拓扑结构和侦听关系,流f1和f2的数据包在节点n3处是可编码的。除了节点n1到节点n3链路之外的其他链路丢包率均为0,观察当n1到n3节点间链路的丢包率分别为0、5%、10%、15%、20%,其他链路丢包率为0的情况下,吞吐量等一些性能指标的变化。表1记录了仿真实验运行20s时间内的测试结果。其中总发送次数是指节点n3发送数据包的次数;缓冲区只存在单流的次数是指节点n3发送数据包时其队列中只存在编码流中的某一个单流出现的次数;编码次数是指节点n3发送编码数据包的次数;吞吐量是单位时间内数据流f1和f2被成功接收的数据量之和。Q1和Q2分别表示f1和f2两条流在编码节点n3缓存队列中数据包的个数,将队列中仅存在流f1的情况表示为Q1≠0|Q2=0,而将队列中仅存在流f2的情况表示为Q1=0|Q2≠0,显然这两种情况下n3是没有编码机会的。不采用编码机制是指n3直接转发;采用COPE机制即n3采用COPE机制对f1和f2的数据包进行编码发送。

表1 仿真实验结果
通过表1所示的仿真实验结果可以看出:
(1) 即使当n1到n3链路丢包率为0时,即所有竞争链路丢包率一致的情况下,节点n3缓冲队列中只存在单流的次数占了总发送次数的20%左右,即短期内f1和f2流的数据包到达节点n3是不均衡的,这也验证了MAC层竞争机制导致短期内流到达的不均衡性,从而影响编码机会的产生。
(2) 同时我们看到随着n1到n3链路的丢包率逐渐增大,流f1的丢包增多,即节点n3处接收的数据包总数减少,且大部分属于流f2。由于可编码包的比例(即编码次数和总发送次数之比)下降,从而使得吞吐量下降,编码增益下降。
2CACLOM机制的层级结构
通过第1节的分析和实验数据,可以看到传统的IEEE802.11标准MAC层机制不能很好地适应网络编码的需要,其引起的可编码流到达的不平衡性会减少编码机会,从而不能充分发挥网络编码提高吞吐量的优势。为此设计了CACLOM机制,该机制能够根据编码节点中各参与编码流的队列占用对比情况,动态地调节各上游节点的MAC层竞争信道能力,使缓冲队列中各编码流的数据包更加均衡,获得更多的编码机会。
CACLOM机制中,采用了与COPE一样的数据包编码方式。所有节点保持侦听状态,将侦听到的数据包缓存在侦听队列中用于解码,每个节点定期广播自身侦听队列中的数据包,同时依据邻居节点侦听到的数据包来决定转发数据包是否能够编码,以确保该节点的下一跳节点在接收到编码数据包之后能解码。节点接收数据包时,若是编码数据包,则从侦听队列中找到解码所需的数据包用于解码还原原始数据包,然后递交给上层协议进行处理或放入转发队列等待调度。与其他基于网络编码的转发机制不同的是,在CACLOM机制中,对数据流赋予了不同的优先级,在MAC层依据数据流的优先级别进行区分处理:MAC层依据该优先级来确定发送数据帧的MAC层参数,使得优先级高的数据帧在竞争信道时具备更强的优势,以尽快获得发送机会。CACLOM机制的层级结构如图2所示,对原有协议栈的改动分为两个部分,分别为:流优先级的计算与调整和MAC层优先级的处理。
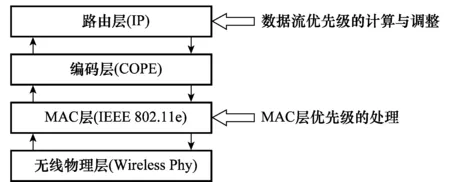
图2 CACLOM机制层级结构图
数据流优先级的计算与调整完成的功能是依据发送缓冲队列中各编码流数据包的数量,计算得到相对富余的流和相对短缺的流。所谓的富余流是将编码节点发送队列中所有能进行编码的数据包编码完之后,仍然有数据包需单独发送的流,与富余流构成编码关系的流即为短缺流。
根据各编码流在队列中数据包个数差值来计算这些编码流对应的优先级,然后通知上一跳节点,以降低富余流竞争信道的能力同时增强短缺流竞争信道的能力,从而使得到达编码节点的编码流的数据包数目趋向平衡,以获得更多的编码机会。关于流优先级的计算与调整的详细描述见第3节。
IP层将数据包递交给编码层时,会将该数据包所属流的优先级值写入此IP数据包头部的ToS字段。编码层按照文献[1]中的数据包编码机制对可编码数据包进行编码,当参与编码的原始数据包的优先级别不同的时候,编码包的优先级别取其中高的优先级别。
IP头部ToS字段可以在路由层提供区分服务,对优先级别不同的数据包,路由器会区分对待。本文提出的机制是在路由层没有启用优先级别的情况下使用,如果路由层已经使用了ToS字段,则应该以路由层的服务质量优先,即保持路由层优先级别高的数据占用较大的传输速率,在MAC层维持原来的竞争机制。
MAC层优先级的处理完成的功能是依据携带在IP头部ToS字段中的优先级,将数据帧送入不同的硬件接口队列。在CACLOM机制中,MAC层采用了IEEE802.11e协议,并对其参数设置进行了一些修改,采用了8个优先级的参数设置,具体每个优先级的参数设置如表2所示,其中AIFS为从检测到空闲到发送数据帧(进入Contention Window)的间隔时间;CWmin为竞争窗口最小值;CWmax为竞争窗口最大值。可以看出,0号优先级为IEEE802.11b的MAC层采用的参数设置。优先级越高,数据帧就越容易竞争到信道。

表2 修改的IEEE802.11e MAC层参数设置
3数据流优先级的计算与调整
数据流优先级的计算与调整是CACLOM机制的核心。本节中,我们将描述数据流优先级的计算与调整的具体方法。首先定义了节点的流表, 用于保存经过节点的活动流信息;然后引入编码图作为分析流之间编码关系的工具,给出了缓冲队列中富余流以及富余量的估算方法;在此基础之上,设计了数据流的优先级计算和调整方法。
3.1流表
CACLOM机制中,每个节点维护一张流表,用以记录每条经过本节点的“局部流”的信息。在每个节点的流表中,具有相同上一跳节点和下一跳节点的数据流聚合成同一局部数据流。在生成路由表的同时,就根据每条流的上一跳节点、目标节点地址、以及下一跳节点信息生成如表3所示的流表的每条记录前4项信息。周期性轮询整个转发队列,统计属于各个流的数据包个数,动态更新queue size表项的值。显然,对于中间节点进行网络编码而言,同一局部流的数据包在可编码性上是等价的。对应于每一条局部流,流表记录了<流序号,目的节点,上一跳节点,下一跳节点,数据包数目>五个表项。为了清楚说明流表的含义,我们举例说明。假设在图3(a)对应的网络中,存在7条流,分别为f1(v1->v2->v5->v8->v10)、f2(v1->v2->v5->v7->v9)、f3(v1->v2->v5->v12)、f4(v9->v6->v5->v3->v4)、f5(v6->v5->v8->v11)、f6(v8->v5->v2->v1)、f7(v1->v2->v5->v8->v11)。表3为图中节点v5的流表,以第一条记录对应的局部流为例,这条局部流相对于节点v5的上一跳节点为v2,下一跳节点为v8,是由f1和f7两条端到端数据流汇聚而成的,相应的,数据包数目为f1和f7在节点v5缓冲队列中的数据包个数总和。
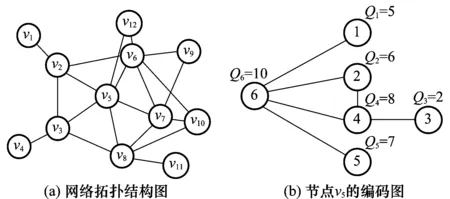
图3 网络拓扑结构图以及对应的编码图
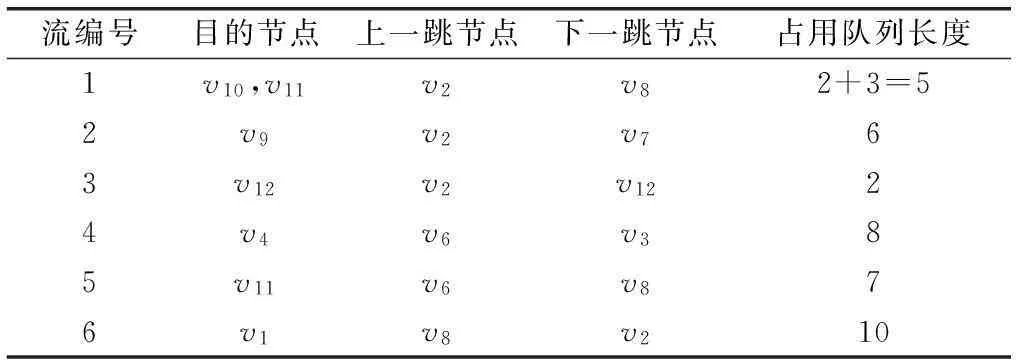
流编号目的节点上一跳节点下一跳节点占用队列长度1v10,v11v2v82+3=52v9v2v763v12v2v1224v4v6v385v11v6v876v1v8v210
3.2编码图(coding graph)
基于流表和局部流之间的编码关系,每个编码节点可以生成一张编码图。编码图为一无向图,反应了经过本节点的局部流之间的编码关系和局部流的流量大小。编码图的构建方法为:局部流fi对应编码图中的一个顶点i,顶点i对应的权值Qi表示局部流fi在节点缓存队列中的数据包的个数,如果两个局部流具有编码关系,则相应两个顶点间增加一条边,去除没有任何边的顶点(即不能与其他任何流进行编码的局部流)。
这里对局部流具有编码关系的判定是单纯依靠物理位置关系来确定的,即从物理位置关系而言,两个流的下一跳节点都能得到另一流的上一跳节点的发送数据包,当中间节点编码后,两个下一跳节点都能解码。其定义是:假设存在两个局部流f1和f2,若f1的下一跳节点即为f2的上一跳节点,或者是其邻居节点,反之f2的下一跳节点即为f1的上一跳节点,或者是其邻居节点,就称f1和f2具有编码关系。例如图3(a)中,经过节点v5的两个流f5(v6->v5->v8->v11)和f6(v8->v5->v2->v1),由于节点v2是节点v6的邻居,同时f5的下一跳v8即为f6的上一跳节点,因此我们称f5和f6具有编码关系。
同样,多个流之间具有编码关系是指这多个流中的每个流的下一跳节点从物理位置关系来说能监听到或者直接获得其他流上一跳节点发出的数据包,即中间节点将这多个流的数据包做异或编码后,这多个流的下一跳节点都能解码。图3(b)为图3(a)和表3对应的编码图。
3.3富余流估算方法
依据上述编码图,给出了估算富余流以及富余量的方法。我们首先通过几个常见的编码图结构简单说明一下如何利用编码图估算富余流及其富余量。
图4为几种常见的简单编码图结构。如图4(a)所示的编码图,表示局部流f1和f2具有编码关系,此时,流f1在该编码节点的队列中有10个数据包,而流f2在编码节点的队列中有4个数据包。显然此时流f1为富余流,富余的数据包个数为6。因此,这种情况下的估算方法很简单,权值大的顶点代表的局部流为富余流,富余量为权值之差6。
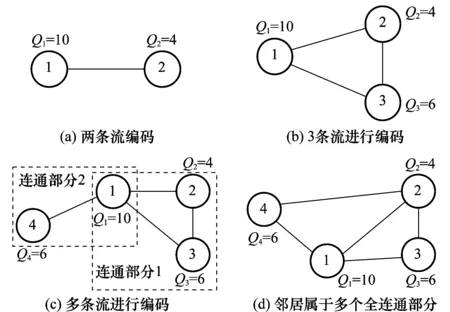
图4 几种常见的编码图结构
类似地,图4(b)中反映出流f1、f2和f3的数据包能一起编码的情况。这种情况下,3条流有一部分数据包可以3个编码在一起发送,在这个例子中,可以形成4个3编码的编码包,此后,流f1剩余6个数据包,流f2剩余2个数据包,这时,流f1和流f2的数据包可以进行一起编码,最后是流f1为富余流,富余的数据包个数为4。这种情况的估算方法是权值最大的顶点代表的流为富余流,富余量为最大权值减去次大的权值。以此类推,同样的估算方法可以适用于包含多个顶点的全连通编码图,即多个数据流可以编码在一起的情况。
图4(c)反映的情况稍微复杂一些,流f1不仅能和流f2和f3一起编码(连通部分1),而且能和流f4进行编码(连通部分2)。依据采用的COPE编码机制,总是取队首数据包与紧接其后的可编码数据包编码,并逐个判定是否可以多个编码在一起。因此f1的数据包是与f2和f3的编码在一起,还是与f4的数据包编码在一起,取决于数据包在缓冲队列中的位置。因此为了估算的合理性,首先分别计算两个全连通部分的可编码流量,连通部分1的可编码流量为6(即为该连通部分的次大顶点权值Q3=6),连通部分2的可编码流量也是6(Q4=6),我们将f1的流量按比例与可编码流的权值相消,即相当于将顶点1虚拟成两个不相连的顶点,将顶点1的权值按比例分配给这两个虚拟节点。在这个例子中,我们将权值均分。这时,图4(c)就变成了图5所示的分解图,然后再按照图4(a)和图4(b)的估算方法,可以得到富余流为f4和f3,富余量分别都是1。
图4(d)与图4(c)不同的是,除了权值最大的顶点1在多个连通部分外,该点的邻居顶点2也在多个连通部分。
为了简化估算,先将位于多个连通部分的邻居点2分解成多个虚拟点,分解的方法同样按比例划分,即分别计算所在的几个连通部分的不包含自身的次大顶点权值,按比例分解分配权值。接着按图4(c)的方法估算富裕流,得到如图6所示的分解图。观察此图6(b)可知,顶点4和顶点3对应的流为富余流,它们的富余量均为1。

图5 图4(c)对应的分解图

图6 图4(d)对应的分解图
CACLOM机制中,首先依据编码节点当时的缓存队列中数据流的编码关系生成编码图CG(V,E,W)。当一个节点的局部流较多时,可能会出现比较复杂的编码图。在这种更为一般的编码图中,富裕流估算的基本方法和步骤如下:
步骤 1在编码图中选择权值最大的顶点,由该顶点与其直接邻居点构成局部的编码图,在局部编码图中对权值相抵消;
步骤 2在权值抵消后,对编码图进行裁剪,具体的方法是去除权值为0的顶点及该顶点的所有的边,合并相应的虚拟节点,其权值为相应虚拟节点剩余权值之和;
步骤 3在裁剪后的残图中,递归执行步骤1和步骤2,直至残图中不存在边;
步骤 4输出残图中权值不为0的顶点和相应剩余权值,输出原图中这些点的邻居节点。这些权值不为0的顶点代表的流就是富余流,富余量即为该点相消后的剩余权值,其邻居点代表的流为短缺流。
步骤1中局部编码图权值相抵消的具体方法如下:
(1) 若某个点的局部编码图包含多个全连通部分。首先,若该点的某个邻居点属于多个全连通部分,则为该点生成多个虚拟节点,并将该邻居点权值分配给虚拟节点,用虚拟节点将多个全连通部分在该邻居点分离。若仅有该节点被包含在多个全联通部分,为该点生成相应的虚拟点,权值分配给虚拟节点,将局部编码图在该点出分拆成多个独立的全连通部分。
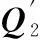
(2) 对于大于等于3个顶点的连通部分,即如图4(b)的情况,相抵消的具体方法是将权值最大的顶点的权值改为最大权值减去次大权值,其他点权值都改为0。
(3) 对于只有两个点的全连通部分,将原来权值大的顶点的权值改为权值之差,原来权值小的点赋值为0。
关于在编码图中查找富余流的算法描述如图7~图9所示。
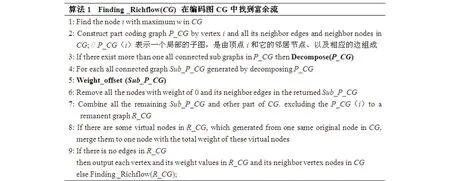
图7 Finding _Richflow(CG)查找富余流方法

图8 Weight_offset(G)权值抵消算法
3.4流优先级的计算与调整
CACLOM机制中,各流的优先级初始时刻均设置为0。当编码节点根据估算方法得到了剩余权值不为0的顶点和其权值后,将通知上一跳节点降低这些顶点对应的流的发送优先级,同时提升与其邻居节点对应的流的优先级别。为了尽量减少这种调节机制对整体信道竞争激烈程度的影响,我们在参数调节上尽量让富余流与其对应的短缺流的优先级调整量是平衡的,使得所有流竞争信道的能力维持在一定水平,保证CACLOM机制不会带来更多的MAC层冲突。
具体的优先级计算方法如下:
假设估算得到的剩余编码图中顶点k对应剩余权值为Qk(Qk>0),计算顶点k对应的局部编码流fk的优先级调整量公式为
(1)
式中,N为编码节点缓冲队列的最大长度;Δ为CACLOM机制中设定的优先级的个数,如表2所示,Δ=8。
同时计算在原始编码图中顶点k的邻居i所对应流fi的优先级调整量。由于可能存在多个邻居点,意味着多个流可以与流fk编码,这里的策略是同时提高这些流的优先级别,只是提高量作了平均。因此流fi的优先级调整量计算公式为
(2)
式中,m为顶点k的邻居节点的数目。

图9 Decompose(G)分解子图算法
当编码节点有数据包要发送时,将计算得到的流的优先级调整量信息携带在数据包中;邻居节点侦听到此数据包时,将对应本节点的流调整信息取出,并将相应的流优先级调整为Δ/2+η。

图10 编码图中查找富余流算法示例图
在CACLOM机制中,优先级信息的传输是采用携带的方式,在编码节点定期生成编码图计算出优先级调整量后,用一个发送数据包携带相应的调整信息。数据包格式如图11所示。CACLOM数据包格式与COPE数据包格式基本相同,只是在COPE数据包格式的基础上增加了“优先级调整信息”字段,其中PRI_REPORT_NUM为携带的优先级调整记录的条数,每条记录是针对某个上游节点的一条流的调整信息,对应一个
仍然是以图3和表3所示的网络为例,在第3.3节最后得到Q1=2.5、Q5=3.5,其他顶点的权值均为0,节点队列的最大长度N为10,设定的优先级的个数Δ=8。针对Q1=2.5,首先根据式(1)计算顶点1对应的流的优先级调整值h1=-|2.5×8/(10×2)|=-1,根据式(2)计算顶点1的邻居顶点6对应的流的优先级调整值h6=|2.5×8/(10×2)|=1。类似的计算顶点5及其邻居顶点6对应的流的优先级调整值分别为h5=-|3.5×8/(10×2)|=-1和h6=|3.5×8/(10×2)|=1,合并顶点6对应的流的优先级调整值h6=2。所以流f1和f5的优先级将被调整为4-1=3,而流f6的优先级将被调整为4+2=6。

图11 CACLOM数据包格式图
4仿真实验
在本节中,将在简单的“X”型简单拓扑结构网络和随机部署节点的复杂拓扑结构网络中,测试CACLOM机制的性能表现。在下面的仿真实验中,如无特别说明,各参数设置如表4所示。

表4 仿真实验参数设置
4.1简单网络拓扑下仿真实验
为了验证CACLOM机制的有效性,模拟仿真了CACLOM机制,将其性能与COPE机制作了比较。我们首先在如图1所示的简单网络拓扑下进行仿真。网络中存在两条交汇于节点n3的UDP流,分别是n1到n2的流f1,n4到n5的流f2,速率均为1 Mbps。
在仿真中两者的网络层均采用按需路由机制AODV,不同的是COPE机制中MAC层采用IEEE802.11b,而CACLOM机制采用了结合流量估算和优先级调整的改进IEEE802.11e机制。测试中改变n1到n3节点间链路的丢包率,分别为0、5%、10%、15%、20%,将COPE协议与CACLOM机制相比较,观察在此过程中网络总吞吐量(所有流吞吐量的总和)、公平系数(两条参与编码流的吞吐量比值)、编码节点参与编码流的队列占用对比情况,具体如图12所示。
从图12(a)可以看出,CACLOM机制较单纯的COPE机制在吞吐能力上面提升了大概20%~80%,链路质量差异越大,吞吐量提升越明显。这是因为随着n1->n3链路丢包率的增加,使得编码节点n3成功接收到f1的数据包数目与f2的数据包数目的差异越来越大,造成编码机会的减少。而CACLOM机制在这种情况下,会适当提高f1的竞争信道能力,使得n3节点上流f1和f2的数据包数目趋向平衡,从而提高了网络编码的机会,从而使得吞吐量是能够得到提高的。
图12(b)给出了本次仿真实验中两种机制公平性的比较,其中公平系数的计算方法是两条流所获得的平均带宽的比值。
图12(c)给出了两种机制中流f1和f2的端到端延时的对比,其中流f2为富余流,流f1为与其对应的短缺流。可以看出,在部署了CACLOM机制之后,流f2的端到端延时基本没有发生变化,而流f1的延时则减小了很多。之所以能够不影响流f2的延时,是因为在编码转发的情况下,流f2数据包会与流f1数据包编码发送,从而不会对流f2数据包的转发造成影响。
表5给出的仿真实验中的编码次数和队列中数据包数目统计结果也验证了CACLOM机制可以调节参与编码的数据流到达速率,使得编码节点n3上的编码机会增多,从而提高了网络的吞吐量。
如表5所示,我们可以看到CACLOM在Q1=0|Q2≠0和Q1≠0|Q2=0出现的次数上都有非常明显的减少且更加趋近平衡,说明f1和f2两条流在队列占用率上面更加平衡,不能编码的情况减少;从编码次数的指标上来看,CACLOM机制增加了编码节点的编码次数,能更好地发挥网络编码的优势。
为了测试节点缓存大小N对网络性能的影响,在上述仿真实验场景中,固定n1到n3节点间链路的丢包率为10%,仅改变节点缓存大小N的值,观察其对网络编码次数以及总吞吐量的影响,具体如图13所示。
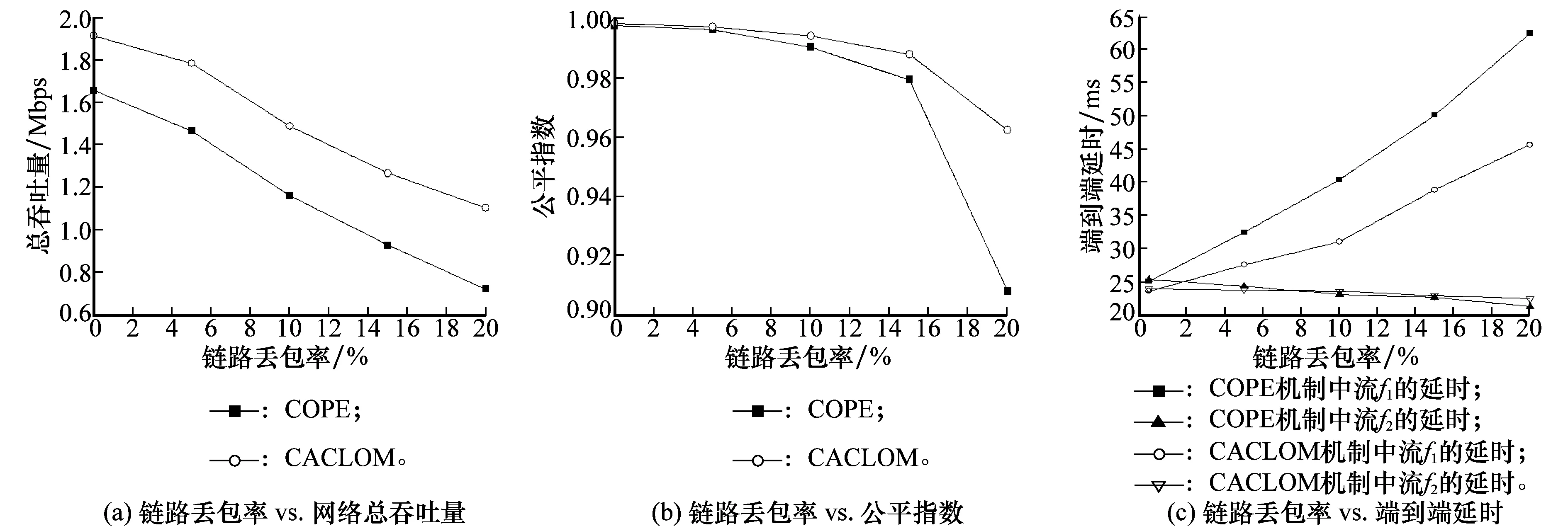
图12 总吞吐量、公平指数和端到端延时对比图

图13 不同节点缓存大小对性能的影响
通过图13可以看出,当节点缓存大小变化时,相对于COPE机制,CACLOM机制均能获得更多的编码机会,以及很好的吞吐量增益。在接下来的仿真实验中,节点缓存大小取NS2中的默认值50 packets。

表5 编码次数以及队列情况
在CACLOM机制中,对参与编码的数据流中速率较小的流赋予了较高的优先级,而速率较大的流赋予了较低的优先级。为了观察CACLOM机制对于速率不同的编码流的影响, 我们在上述实验中仅改变编码流的发送速率,同时固定所有链路的丢包率为0,观察在各种情况下两条流所获得的带宽对比情况。
仿真实验结果如表6所示,当网络比较空闲的时候(表6中的前两条记录对应的情况),CACLOM机制下流f1和f2所获得的带宽与其发送速率成比例。这是因为尽管提高了速率较低流的信道竞争能力,但是由于网络中有足够的带宽资源,使得被赋予较低优先级的数据流仍然能获得足够的带宽。同时,当网络较拥塞的时候(表6中的后两条记录对应的情况),流f1和f2所获得的带宽都高于COPE机制,但流f2获得了更好地带宽/速率比,这说明了CACLOM机制能提高流速较低的流抢占信道的能力,使得网络中产生了更多的编码机会,从而能够更好地发挥网络编码提高网络吞吐量的优势。
4.2复杂网络拓扑下仿真实验
为了测试更为一般的网络拓扑、多流并存情况下协议的特征,我们仿真了更为一般的网络拓扑场景,在1 000×1 000的区域内随机部署25个节点,然后每隔30 s加入一条UDP流,部署多条UDP流,流数为3~12条不等,速度为100 kbps,每条链路丢包率在0%~10%之间随机取值。

表6 编码流速率不同情况下带宽占用情况
由于一些相关研究已经在COPE机制上改进并提出了编码感知的路由协议,为了验证CACLOM机制与这些已经考虑了编码机会的路由机制结合之后的有效性,在测试中选择了文献[15]提出的编码感知路由协议PNCAR,并且在其上结合了MAC层优先级调整机制,对结合前后的性能进行了比较。(PNCAR是一个编码感知的路由协议,它在选择路由时考虑了编码机会的因素,同时解决了路由选择的等分性(isotonic)问题,性能上比单纯的COPE机制要好。)用PNCAR+CACLOM表示结合了MAC层优先级调整之后的机制。
仿真实验在10种不同的随机网络场景下进行,实验结果取10次实验的均值,同时我们给出了当流的数目为9时,10种随机网络场景下各“路由协议+编码机制”组合在总吞吐量和编码次数上的对比情况。测试的性能指标包括:
(1) 网络总吞吐量(所有流吞吐量的综合);
(2) 总编码次数(所有编码节点编码次数之和);
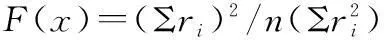
图14为不同网络负载情况下,网络总吞吐量和编码次数均值的变化情况,而图15为当网络中存在9个流时,各个不同网络场景下的吞吐量和编码次数。
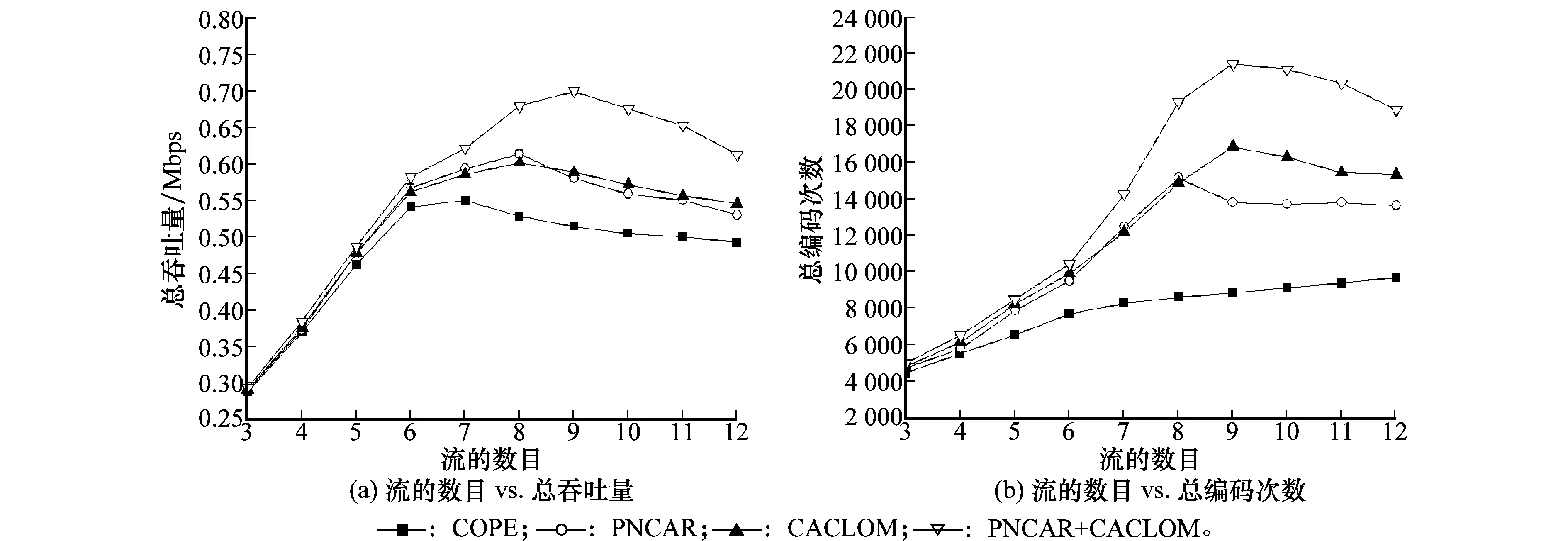
图14 平均吞吐量和编码次数的对比图
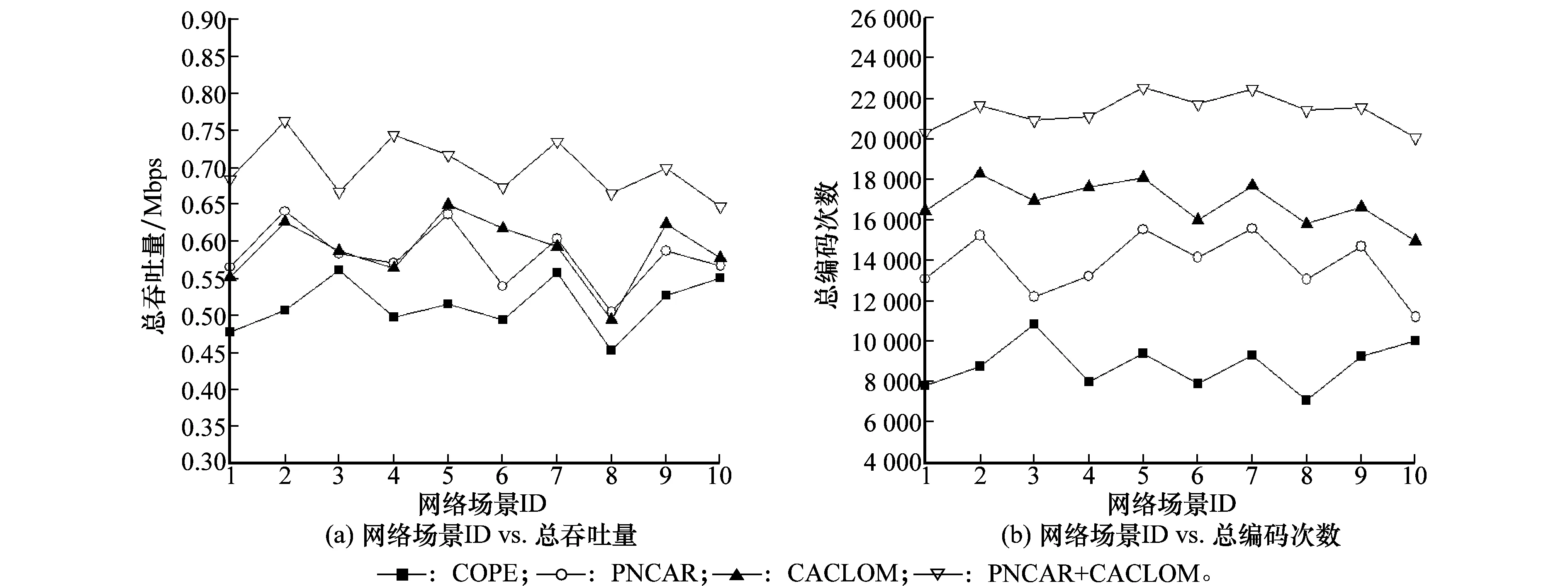
图15 流数目为9时不同网络场景的吞吐量和编码次数的对比图
观察图14和图15可得:
(1) 从图14可以看出,采用同样的路由协议,引入CACLOM机制之后(即COPE与CACLOM相比较,PNCAR与PNCAR+CACLOM相比较),在流的数目超过6以后,吞吐量和编码包数目都有很明显的提升。说明CACLOM机制能够有效地增加网络中的编码机会,更好地发挥网络编码提高吞吐量的优势。图15中给出了不同场景下的吞吐量和编码次数的比较,可以看出在测试的所有场景中,引入MAC层优先级别调整机制CACLOM后,网络中的编码次数和整体吞吐量都得到了有效的提高。
(2) PNCAR与CACLOM的结合较单纯采用一种机制进一步提高了吞吐量。这是因为PNCAR在选择路由时考虑链路的编码机会,能够将更多的网络流量聚合到具有编码机会的链路上来,使得网络拥有更多的编码节点。同时,CACLOM机制能够增加编码节点上的编码机会,也就是说,CACLOM机制能够进一步放大基于编码感知的路由协议相对于最短路径路由协议的优势。
图16为4种机制的公平性比较。由于PNCAR有流量汇聚的特点,流量汇聚之后会使得流之间竞争带宽资源的情况加剧,故采用了PNCAR的机制的公平性比采用COPE机制公平性要稍差一些。而CACLOM机制和PNCAR+CACLOM则有比较好的公平性表现。这是因为进行网络编码的节点在发送一个数据包时,如果队列中有符合编码条件的数据包,节点会将多个数据包编码进行发送,这种行为会改善网络流之间的公平性,并且编码次数越多,这种改善公平性的效果会越明显。这也从侧面说明了本文提出的CACLOM机制能够有效地增加编码机会,从而提升吞吐量。

图16 流的数目 vs. Jain公平指数
5结论
本文首先分析了IEEE802.11标准的MAC机制带来的短期竞争信道不公平的特点,并指出这会减少编码机会的产生,进而结合跨层优化的思想,提出了一种具有编码机会感知的跨层协作机制CACLOM。这种机制通过检查参与编码流在编码节点队列中的占用情况以通知相应上游结点调整MAC参数,从而调节参与编码流的速率,使得编码节点上不同编码流的数据包数目更加平衡,最终达到增加编码次数,提高网络整体吞吐量的目的。通过NS2上的仿真实验表明,CACLOM机制能够平衡编码流竞争信道的能力,有效地增加了编码机会,提高了网络的整体吞吐量。
参考文献:
[1] Katti S, Rahul H, Hu W, et al. XORs in the air: practical wireless network coding[J].IEEE/ACMTrans.onNetworking, 2008, 16(3): 497-510.
[2] Wang C C, Shroff N, Khreishah A. Cross-layer optimizations for intersession network coding on practical 2-hop relay networks[C]∥Proc.oftheIEEEAsilomarConferenceonSignals,SystemsandComputers, 2009: 771-775.
[3] Wang C C. On the capacity of wireless 1-hop intersession network coding—a broadcast packet erasure channel approach[J].IEEETrans.onInformationTheory, 2012, 58(2): 957-988.
[4] Ramakrishnan A, Das A, Maleki H, et al. Network coding for three unicast sessions: interference alignment approaches[C]∥Proc.ofthe48thIEEEAnnualAllertonConferenceonCommunication,Control,andComputing, 2010: 1054-1061.
[5] Eryilmaz A, Lun D S. Control for inter-session network coding[C]∥Proc.ofthe3rdIEEEWorkshoponNetworkCoding,Theory&Applications, 2007: 1-9.
[6] Traskov D, Ratnakar N, Lun D S, et al. Network coding for multiple unicasts: an approach based on linear optimization[C]∥Proc.oftheIEEEInternationalSymposiumonInformationTheory, 2006: 1758-1762.
[7] Seferoglu H, Markopoulou A, Ramakrishnan K K. I2NC: intra-and inter-session network coding for unicast flows in wireless networks[C]∥Proc.ofthe30thIEEEInternationalConferenceonComputerCommunications, 2011: 1035-1043.
[8] Paschos G S, Fragiadakis C, Georgiadis L. Wireless network coding with partial overhearing information[C]∥Proc.ofthe32ndIEEEInternationalConferenceonComputerCommunications, 2013: 2337-2345.
[9] Keshavarz-Haddad A, Riedi R H. Bounds on the benefit of network coding for wireless multicast and unicast[J].IEEETrans.onComputing, 2014, 13(1): 102-115.
[10] Carrillo E, Ramos V. On the impact of network coding delay for IEEE 802.11 s infrastructure wireless mesh networks[C]∥Proc.ofthe28thIEEEInternationalConferenceonAdvancedInformationNetworkingandApplications, 2014: 305-312.
[11] Wei X, Zhao L, Xi J, et al. Network coding-aware routing protocol for lossy wireless networks[C]∥Proc.ofthe5thIEEEInternationalConferenceonWirelessCommunicationsNetworkingandMobileComputing, 2009: 1-4.
[12] Fan K, Li L, Long D. Study of on-demand cope-aware routing protocol in wireless mesh networks[J].JournalonCommunications, 2009, 30(1):128-34.
[13] Wu Y, Das S M, Chandra R. Routing with a Markovian metric to promote local mixing[C]∥Proc.ofthe26thIEEEInternationalConferenceonComputerCommunications, 2007: 2381-2385.
[14] Le J, Lui J C S, Chiu D M. DCAR: distributed coding-aware routing in wireless networks[J].IEEETrans.onMobileComputing, 2010, 9(4): 596-608.
[15] Yan Y, Zhang B, Zheng J, et al. CORE: a coding-aware opportunistic routing mechanism for wireless mesh networks[J].IEEEWirelessCommunications, 2010, 17(3): 96-103.
[16] Zhang J, Zhang Q. Cooperative network coding-aware routing for multi-rate wireless networks[C]∥Proc.ofthe28thIEEEInternationalConferenceonComputerCommunications, 2009: 181-189.
[17] Jhang M F, Lin S W, Liao W. C2AR: coding and capacity aware routing for wireless ad hoc networks[C]∥Proc.oftheIEEEInternationalConferenceonCommunications, 2010: 1-5.
[18] Peng Y, Yang Y, Lu X, et al. Coding-aware routing for unicast sessions in multi-hop wireless networks[C]∥Proc.oftheIEEEGlobalTelecommunicationsConference, 2010: 1-5.
[19] Zhao F, Médard M. On analyzing and improving COPE performance[C]∥Proc.ofInformationTheoryandApplicationsWorkshop, 2010: 1-6.
[20] Jain R, Chiu D M, Hawe W R.Aquantitativemeasureoffairnessanddiscriminationforresourceallocationinsharedcomputersystem[M]. Eastern Research Laboratory: Digital Equipment Corporation, 1984: 5-10.
杨湘(1980-),男,博士研究生,主要研究方向为网络协议性能优化、网络编码。
E-mail:yangxiang1027@163.com
王伟平(1969-),女,教授,博士研究生导师,博士,主要研究方向为网络优化、网络编码、网络安全、匿名通信。
E-mail:wpwang@mail.csu.edu.cn
王建新(1969-),男,教授,博士研究生导师,博士,主要研究方向为参数计算理论、网络优化理论。
E-mail:jxwang@mail.csu.edu.cn
A coding-aware cross-layer optimization mechanism for wireless mesh network
YANG Xiang1,2, WANG Wei-ping1, WANG Jian-xin1
(1.SchoolofInformationScienceandEngineering,CentralSouthUniversity,Changsha410083,China;2.SchoolofComputerScienceandTechnology,WuhanUniversityofScienceandTechnology,Wuhan430081,China)
Abstract:Due to the inherent broadcast and overhearing capabilities of wireless network, the network coding technique is very suitable for the wireless mesh network. Through the theoretical analysis and simulation results, it is observed that the MAC mechanism of the IEEE802.11 standard may make the node more competitive after accessing the channel successfully, which unbalances the amount of packets of different coding flows in the buffer of the coding node in a short period, and finally, some coding opportunities are lost. A cross-layer optimization mechanism is proposed. In the mechanism, the priorities of coding flows are calculated by using the buffer occupancy information and are sent to the upstream node, and then the corresponding upstream node adjusts its MAC parameters, which yields more coding opportunities. Simulation results show that the proposed mechanism can adjust the rate of flows whose packets can be encoded together adaptively, and improve the total throughput of network.
Keywords:wireless mesh network; MAC protocol; network coding; cross-layer optimization
收稿日期:2015-02-05;修回日期:2015-05-09;网络优先出版日期:2015-12-29。
基金项目:国家自然科学基金(61173169)资助课题
中图分类号:TP 393
文献标志码:A
DOI:10.3969/j.issn.1001-506X.2016.06.29
作者简介:
网络优先出版地址:http://www.cnki.net/kcms/detail/11.2422.TN.20151229.1142.004.html
