
对商务统计教学内容改革的几点尝试
2016-06-25 05:49吴爱娟贾鲁军
中国市场 2016年14期
关键词:面积
吴爱娟,贾鲁军
(1.北京工商大学 嘉华学院,北京 101118;2.中国人民大学 信息学院,北京 100872)
对商务统计教学内容改革的几点尝试
吴爱娟1,贾鲁军2
(1.北京工商大学嘉华学院,北京101118;2.中国人民大学信息学院,北京100872)
[摘要]对于推断统计部分的学习,数学基础薄弱的商科学生往往感到困难,讲授《商务统计》的主要精力放在知识和应用的结合上,目的是更有效地阐述统计学特有的方法论和解释数据的能力。根据经管类学生的数理基础较薄弱的特点,我们重于统计学的通识教育,侧重讲思想、原则和基本计算,不追求严谨,内容上删繁求简。文章通过两个教学案例来阐述教学思想。
[关键词]推断统计;连续型随机变量;密度函数;面积;区间估计;抽样误差
[DOI]10.13939/j.cnki.zgsc.2016.14.142
1背景
现代商务统计是搜集、整理、分析现代商务活动信息资料的理论和方法。这些理论和方法主要包含在描述统计和推断统计中。
希望通过本课程的学习,使学生对统计学的学科体系有一个全面的认识,为学习后续课程作好铺垫;能明确理解统计这个认识工具的特点、作用;弄懂各种概念、范畴等基本知识;会分析社会经济现象和现代商业事务的一些具体事例;在今后的工作中,能将统计学的知识贯穿其中。
对于推断统计部分的学习,数学基础薄弱的商科学生往往感到困难,其原因大致有这么几点:概率统计知识基础不扎实或者没有先修概率统计课程;推断统计中的一些结论、公式的推导抽象;推断统计中的一些思想理解不透彻;推断统计结果不会解读。
讲授《商务统计》的主要精力放在知识和应用的结合上,目的是更有效地阐述统计学特有的方法论和解释数据的能力。根据经管类学生的数理基础较薄弱的特点,应重于统计学的通识教育,侧重讲思想、原则和基本计算,不追求严谨,内容上删繁求简。
2两点尝试
(1)对于财经类学生,若概率统计基础知识不扎实或者没有先修概率统计课程的话,在学习商务统计时,还是要加上概率论基础这一章节的。学生学习时感到困难的是连续型随机变量,以往的讲解内容是先介绍分布函数,然后结合积分给出密度函数及连续变量的概念,单单是积分、求导就把数理基础薄弱的学生吓到了。这部分内容如何讲解会浅显易懂呢?
对于离散型随机变量,文章介绍了利用概率函数(分布律)来求其取值的概率。区分离散型随机变量和连续型随机变量最根本的差异是如何计算其取值的概率,相应于离散型随机变量的概率函数,连续型随机变量也有概率函数,称之为概率密度函数,简称为密度函数,记作f(x),不同的是密度函数不直接提供概率,而是,连续型随机变量落在某个区间上的概率等于该区间上其密度曲线与x轴围成的图形面积。这句话用符号可作如下简洁叙述:
设连续型随机变量X的密度函数为f(x),y=f(x)与x=a, x=b, x轴围成的图形面积为S,如下图所示。

图1 P{a≤X≤b}=S
因此,当我们计算连续型随机变量取值的概率时,计算的是随机变量的取值落在某个区间上的概率。
我们知道,在一点处f(x)与x轴围成的图形面积为0,所以,对连续型随机变量取一值的概率为0。
下面将以均匀分布为例来阐述上述讨论的正确性。
设随机变量X表示飞机从北京到广州的飞行时间,X在180分钟与200分钟之间随机取值,因为X可能取值填满区间[180, 200],故X是一连续型随机变量。假设我们利用以往足够多真实的飞行数据推断出在180~200分钟的时间区间中,飞行时间落在任何一个间隔为1分钟的区间内的概率与落在其他任何一个间隔为1分钟的区间内的概率是相等的。在X落在间隔为1分钟的区间内是同等可能的条件下,X被称为是一个均匀概率分布。
对飞行时间这个随机变量X定义一个均匀分布的概率密度函数:
图2是f(x)的图像。
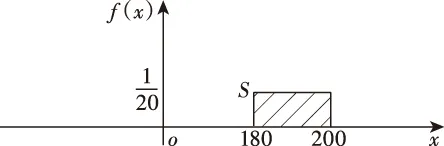
图2 f(x)的图像
前面讨论过,对一个连续型随机变量,只考虑其落在某个区间上的概率,故在本例中可问:飞行时间X落在180~190分钟之间的概率是多少?即P{180≤X≤190}=?
因为飞行时间必须落在180~200分钟,且在这区间上概率是均匀分布的,则易得P{180≤X≤190}=0.5。

一般地,若一个随机变量X有密度函数:
则称随机变量X服从[a, b]上的均匀分布。
注意到,在前面飞行时间例子中,P{180≤X≤200}=1,这就是说,密度曲线f(x)与x轴围成的图形面积为1,这一性质对所有连续概率分布都成立。显然,这和离散型概率分布的所有概率和为1是类似的。同样地,与离散型概率分布中每一取值的概率都非负相类似的有连续型概率分布的密度函数f(x)≥0, (x∈R)。
到此,对于连续型概率分布和离散型概率分布的两个主要差异已显现出来:
(1)对于连续型随机变量,我们不再讨论随机变量取特定值的概率,而是讨论其取值落在某区间上的概率。
(2)连续型随机变量X的取值落在x1与x2之间的概率等于其密度曲线f(x)在x1与x2之间与x轴围成的图形面积。因为单个点是区间长度为0的区间,所以一个连续型随机变量取一特定值的概率为0,这也意味着:
P{x1≤X≤x2}=P{x1≤X 接下来有关正态分布和指数分布,就可以继续利用面积或者查表来讨论其取值的统计规律性,从而避开了学生的难处:积分。 (3)对于总体分布中未知参数θ的区间估计的讲解,传统、严格的做法尽管严谨,但是对于概率统计知识薄弱的财经类学生来说有困难:一是一些抽象的抽样分布他们掌握不好更不会拿来用;二是不会解读其区间估计的结果。为此,我们课堂上做了如下尝试。 以正态总体(方差未知)均值的区间估计为例来介绍。 如何理解上面的48~88分这个置信区间呢?这个区间包含未知的总体均值的真值吗?对于一个特定的区间,这个问题是无法回答的,这是因为总体的参数值是固定的、未知的。我们能做的就是希望未知的总体参数均值落在此区间中。若再抽取另一个样本,那么它将会产生出一个多少不同的样本均值和不同的区间估计,即使有许多不同的置信区间,我们仍希望这些区间都包含参数真值。统计学家有某种程度的信心认为这个区间会包含真正的固定的参数值,所以取名为置信区间。比如这个信心程度(置信水平)为95%,即指这些区间中的95%个包含了总体均值的真值,而5%没有包含。也可以用其他数值作为置信水平,比如98%、99%等。 例如:某地区成年人睡眠时间服从正态分布,一项随机抽样调查得到16个成年人的睡眠时间数据(单位:小时)如下表所示: 16个成年人的睡眠时间数据 问:该地区成年人平均睡眠时间的置信水平为95%的置信区间,你怎么理解该区间? 解:设X=“某地区成年人睡眠时间”,则X~N(μ, σ2),σ2未知,对μ做置信水平为95%的置信区间。 可得到该地区成年人平均睡眠时间的置信水平为95%的置信区间(7.10,7.62)。 上述区间是在具体的一次抽样下得到的,若这样的抽样重复抽取100次,就得到100个具体的置信区间,则在这100个置信区间中有95个包含待估参数μ。 参考文献: [1]张俊妮.数据挖掘与应用[M].北京:北京大学出版社,2009. [2]王汉生.应用商务统计分析[M].北京:北京大学出版社,2008. [3]雷奥奇·卡塞拉,罗杰L.贝耶.统计推断[M].2版.北京:机械工业出版社,2002. [4]吴爱娟.商务统计学[M].北京:知识产权出版社,2015. [作者简介]吴爱娟(1979—),女,汉族,山东菏泽人,硕士,讲师。研究方向:概率统计。贾鲁军(1978—),男,汉族,山东菏泽人,博士,讲师。研究方向:基础数学(通讯作者)。

猜你喜欢
小学生学习指导(高年级)(2022年5期)2022-06-02
中学生数理化·七年级数学人教版(2022年4期)2022-04-26
数学小灵通·3-4年级(2021年5期)2022-01-01
今日农业(2021年4期)2021-11-27
小学生学习指导(高年级)(2021年6期)2021-06-19
小学生学习指导(高年级)(2021年3期)2021-04-06
中学生数理化·七年级数学人教版(2018年4期)2018-06-28
数学小灵通·3-4年级(2017年5期)2017-06-05
河南水利年鉴(2017年0期)2017-05-19
考试周刊(2016年65期)2016-09-22
