
一种基于视觉特征的Deep Web信息抽取方法
2016-07-02 01:44陈军华廉德胜
计算机与数字工程 2016年6期
孙 璐 陈军华 廉德胜
(上海师范大学 上海 200234)
一种基于视觉特征的Deep Web信息抽取方法
孙璐陈军华廉德胜
(上海师范大学上海200234)
摘要随着Web数据库的不断增长,大量网络信息通过普通搜索引擎难以满足用户的需求,需要用户提交表单查询并从后台数据库中返回结果页面才能获取到想要的信息,称为Deep Web。因此如何有效地抽取这些实体信息成为一个值得研究的问题。论文通过分析Deep Web结果页面的特点,结合人的视觉特征,提出了一种基于视觉特征的Deep Web信息抽取方法。该方法充分利用了人的视觉特征,在解析器将Web文档解析成语法树之前,将Web页面一些与主题无关的信息(例如导航栏、广告)等去除,并对优化后的DOM树利用VIPS算法对其进行语义分块,分块后根据位置特征首先寻找到基准视觉块,以该基准视觉块作为中心位置逆序和顺序遍历DOM树寻找所有相似的视觉块并对其进行抽取。从实验效果来看,该方法从提取信息速度和提取信息的准确率和完整率方面与传统方法相比都有一定的提高。
关键词Deep Web; 视觉特征; DOM树; 语义分块; 信息抽取
Class NumberJ653
1引言
信息抽取可以理解为从一段待处理文本中抽取指定的一类信息,并将其以结构化的形式表示(如XML等)供用户查询和使用的过程。针对Web信息抽取工作目前国内外已展开了大量的研究,并且取得了一定的成果。其中按照抽取技术的不同可以分为基于自然语言处理方式的实体抽取;基于包装器归纳法的信息抽取;基于模板的信息抽取;基于视觉特征的信息抽取和基于DOM树的实体抽取技术。其中基于视觉特征的信息抽取和基于DOM树的信息抽取是目前应用比较广泛的方法。
由于构成网页的HTML语言在很大程度上是用来显示数据而不是展示其内容结构的,所以从用户的视觉角度对Web页面进行分析有其一定的合理性。文献[10]提出了基于视觉特征的VIPS算法,该算法充分利用了Web页面的视觉特征,例如颜色、字体大小、图片等,把Web页面划分为许多视觉块,根据视觉块之间的相似度重构页面的内容结构,从而对信息进行抽取。但是该方法基于许多启发式的规则,有时会受人的视觉误导,把页面一些无用的信息当作视觉块处理,例如广告信息等。文献[6~8]提出了基于DOM树的实体抽取技术。在该方法中,首先利用解析器将Web文档解析成语法树,然后深度遍历整棵DOM树,利用DOM树节点之间的相似度确定正文区域,从而对文本信息进行有效抽取。但是该方法是把文本节点和标签节点放在一起对整个DOM文档进行遍历分析,加大了遍历DOM树的时间复杂度。本文通过观察大量Deep Web结果页面,首先运用启发式规则对原始页面进行去噪处理,使得去噪后解析DOM树的节点数大大减少,然后在DOM树结构基础之上,运用文献[10]提到的VIPS算法,把Web页面分割成许多大小不等的视觉语义块,利用页面中心位置的坐标确定出基准视觉块,然后根据Web页面正文信息的位置分布特征和正文视觉块之间的视觉相似性,以该视觉块作为中心位置,顺序和逆序递归遍历整棵DOM树,寻找出所有相似视觉块,即要提取的正文信息。实验表明该方法与传统的方法相比有一定的优势。
2基于基准视觉块的信息抽取算法
2.1Web页面去噪
一般的网页可以分为导航型网页和内容型网页两种,由于本文主要是针对特定领域的关键词搜索结果研究,所以不对导航型网页做研究。对于一个已抽取到的Deep Web结果页面,需要提取的数据区域往往集中于页面的某个区域,称之为正文区域。而普通的Deep Web页面往往包含标题、广告栏、导航链接等许多噪声信息,一些针对特定领域的数据查询(如图书查询),因为它们有规律地分布在页面的特定部分,使得这些无用的噪声信息占了整个页面的一定比重,这样不利于页面的信息抽取,所以对初始页面做去噪处理是非常有必要的。本文通过观察大量的网页后台HTML代码并结合文献[9]提到的网页信息去噪技术,得出如下一些启发式规则:
规则一:如果一个节点周围含有大量的链接节点,如〈link〉等,即链接节点数超过了该区域总数的一定比例,在这里取95%,那么倾向于把这片信息块看作噪声信息,反之则为正文信息;
规则二:如果一个节点的position属性为fixed,并且该节点下还包括img、object或iframe节点,那么把该节点作为噪声节点;
规则三:如果一个文本节点的文本字数低于版权信息节点所含文本的字数(这里把版权信息的字数作为一个阈值)那么倾向于把它看作噪声节点或无用节点。基于以上一些规则,可以初步对原始Web页面做一些优化处理。
本文采用HTMLPaster的词法分析器对页面的HTML代码进行分析,通过提交关键字查询获取Deep Web页面作为实验数据的来源。解析到原始页面的HTML代码后,利用上一节提到的启发式规则对页面的噪声进行过滤处理。可以看出,经过处理后DOM树的节点数大大减少了。
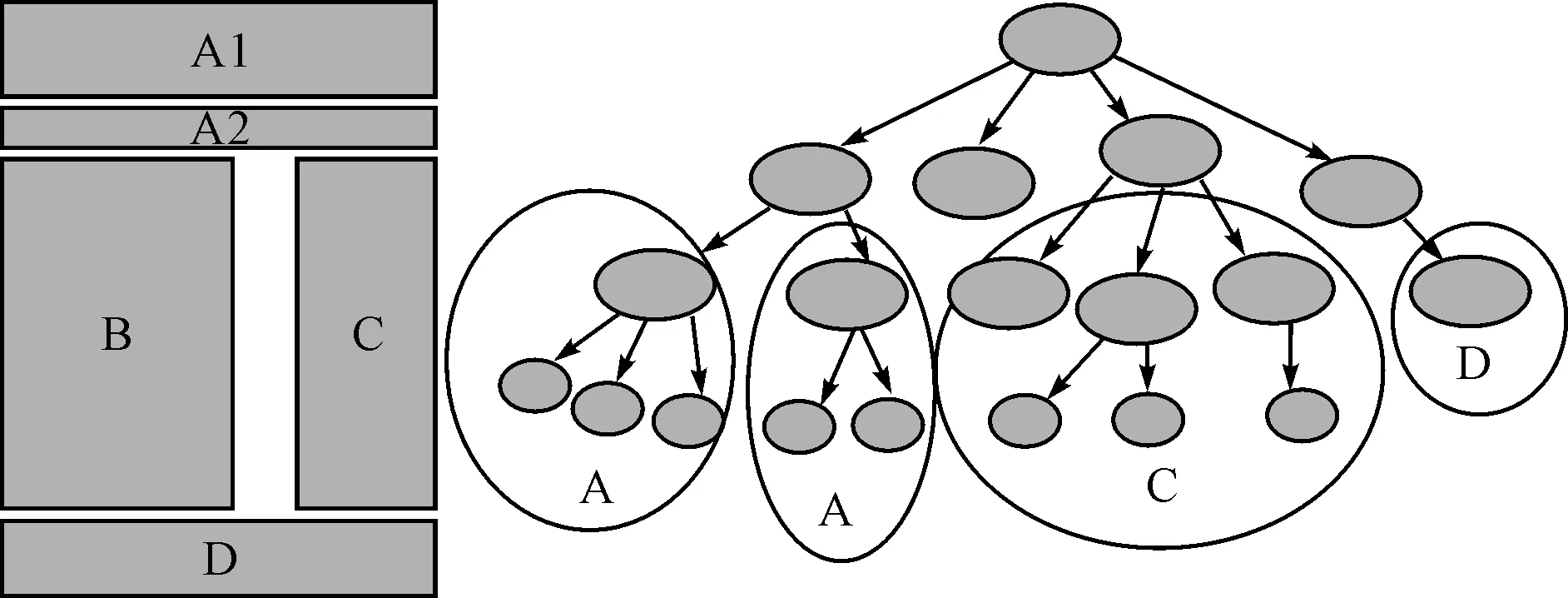
图1 页面结构和去噪节点对比图
2.2VIPS算法
VIPS算法主要是利用Web页面的视觉特征如背景颜色,字体的颜色和大小等把页面分成许多合适的视觉块,根据视觉块之间的逻辑间距重构语义DOM树,进而对页面信息抽取的过程。下面对该算法做一个简单介绍。在VIPS算法中,一个Web页面由Ω表示,Ω=(O,Φ,δ)。其中O={Ω1,Ω2,…,ΩN}是一系列有限的页面块的集合,Φ={Φ1,Φ2,…,ΦT}是一系列有限的分隔符的集合,δ=O×O→Φ∪{NULL},它表示O中每两个块之间的关系[10]。例如,假设Ωi和Ωj是O中的两个对象,δ(Ωi,Ωj)≠NULL表明Ωi和Ωj之间是有联系的,即它们有可能是DOM树中的两个相邻的节点。另外,在Ω中,每一个页面块都可以看作一个子页面,所以可以递归地对它作同样的处理,直到当前页面块不能再分割为止。
下面以当当网为例具体阐述整个分割过程。在当当网首页输入“计算机”,点查询,可以得到如图2结果页面。

图2 当当网页面
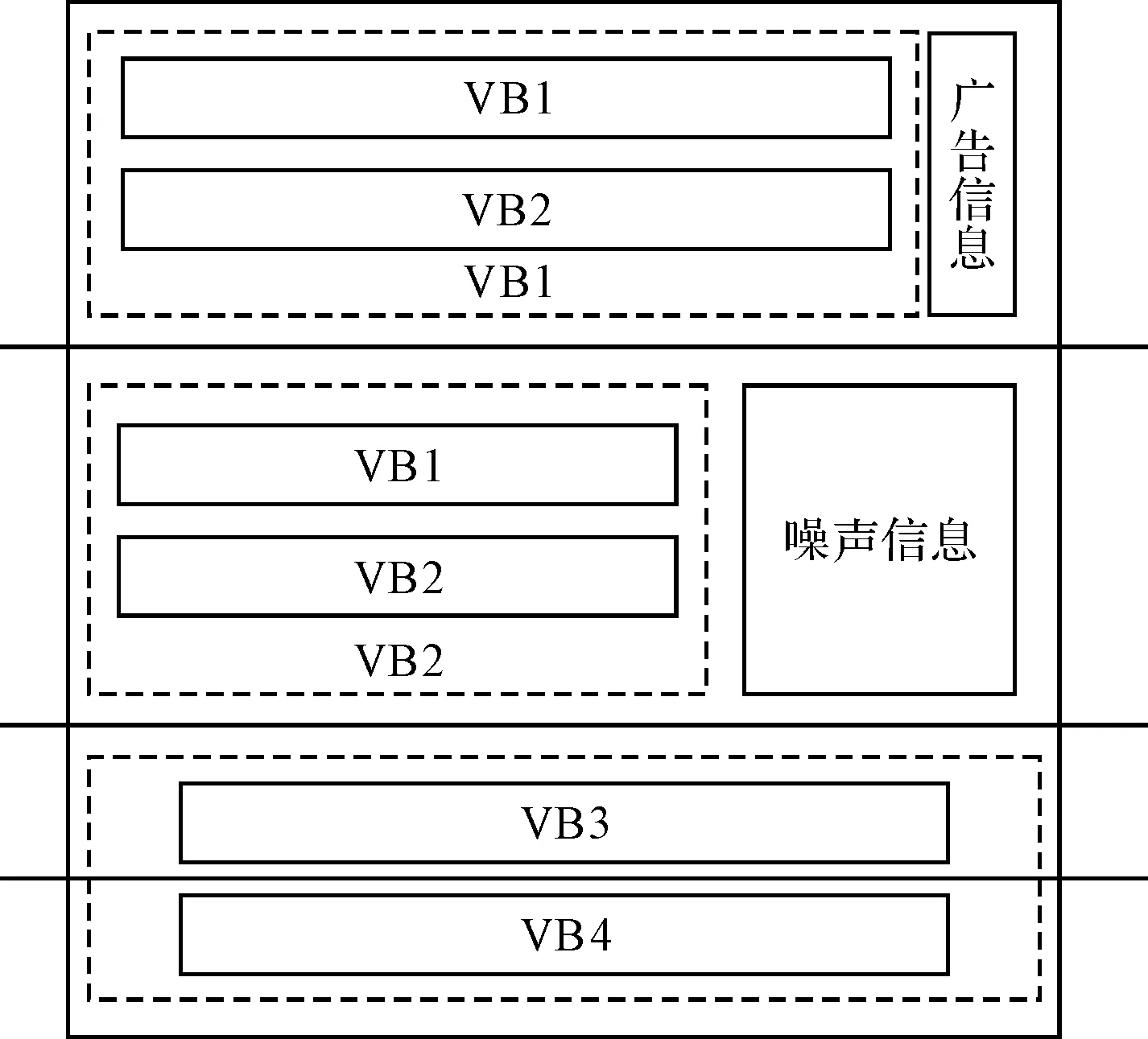
图3 当当网视觉分块图
根据VIPS算法,把该页面分割成如图3所示的视觉块,其中VB1中主要是查询信息和导航信息,还夹杂了一些广告信息,VB3和VB4是底下一些服务指南和版权信息,VB2是想要提取的正文信息。可以看到要提取的信息,即VB2主要集中在页面的某一特定部位,以VB2为例简单说明VIPS分块过程。VB2的DOM树结构如图4所示。
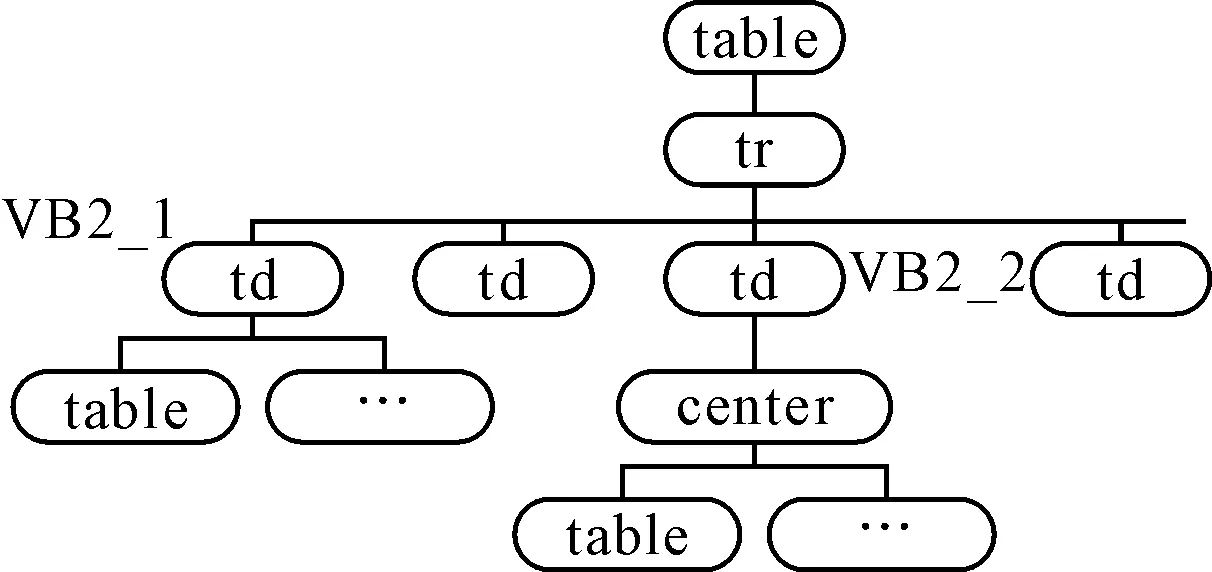
图4 VB2的DOM树结构
首先得到〈table〉标签,它有孩子节点〈tr〉,且孩子节点的背景颜色和它父亲节点的背景颜色不同,所以分隔这个节点,这样就得到两个节点块,然后分别对这两个节点块进一步分析。它有四个〈td〉节点,其中两个是无效节点,取出剩下的两个有效节点即VB2_1和VB2_2所在视觉块。分别对两个视觉块深度遍历,得到〈table〉子节点,它有可能是想要的文本信息,所以把它放到分块池中等待进一步被分析。等到所有的节点都被分析完放入池中后,再递归地对分块池中的节点块作同样的分析,直到得到合适的视觉信息块。至此,整个DOM树的分块过程完毕。
2.3页面信息提取算法
VIPS算法是对页面所有信息进行分块,而信息提取只需要提取与主题有关的正文信息,本文讨论的是针对特定领域的Deep Web结果页面信息,这些信息大都集中在Web页面的特定位置(一般在正中间)。并且这些信息块具有相似的层次结构,大小和颜色,所以可以根据页面视觉特征和DOM树的层次结构找出一个基准视觉块,并逆序和顺序遍历整棵DOM树,找出页面所有相似视觉块,若存在形似的视觉块,再递归地对相似视觉块做以上同样的操作。直到找到所有想要抽取的信息。抽取流程图如图5所示。
图5 信息抽取流程图
下面具体说明正文信息提取算法。以图6为例定义网页左上角顶点为坐标原点,网页中心坐标为(Center_X,Center_Y),定义每个视觉块的中心坐标为(Block_Xi,Block_Yi),其中i={1,2,3,…,n},n∈Z。页面信息提取过程可以描述如下:

步骤二:提取相似视觉块。通过观察可以发现,处于正文位置的视觉块具有相似的视觉特征,并且它们在DOM树中有相似的树层次结构和相同的父节点信息,所以可以以该基准视觉块即VB2_2_3所在树层次作为中心位置,遍历该视觉块所在层次的所有的兄弟节点,得到VB2_2_1和VB2_2_2并把它们和VB2_2_3作比较,它们具有相似的视觉大小和颜色,并处在相同层次的结构树中,所以把这三个视觉块其作为要提取的正文信息存储在目标池中。
步骤三:提取其他可能视觉块。尽管在Web页面中DOM结构树为基本的对象提供了一种层次结构,但是DOM结构树主要是用来显示而不是组织内容的,所以具有相似语义的视觉块可能存在不同的DOM树中,因此需要对DOM树进行进一步遍历以便找到所有可能的视觉块。这里采用文献[11]提到的逆序遍历方法。首先逆序遍历DOM树节点,找出目标池中所有视觉块VB2_2_1、VB2_2_2和VB2_2_3对应DOM树层次结构所在节点的公共父节点,即VB2_2,再逆序向上找出该公共父节点的根节点VB2,对此节点进行顺序遍历,得到VB2_1和VB2_3两个子节点,它们为VB2_2所在DOM树结构的所有兄弟节点。如果还有相似的正文目标视觉块存在,那么他们应该存在于VB2_1和VB2_3的子节点中,否则,说明不存在其他DOM树中包含相似的目标视觉块。在这里遍历到VB2_1_1、VB2_1_2、VB2_3_1和VB2_3_2四个孩子节点,把他们分别和基准视觉块VB2_2_3作比较,从图6中可以发现,这四个节点的大小和VB2_2_3相差较大,所以舍弃这些节点。
步骤四:根据步骤三的结果,如果提取到相似的视觉块信息,那么以提取到的视觉块作为新的基准视觉块递归作同样的操作,直到找到所有可能的视觉块。至此,正文信息视觉块提取结束。
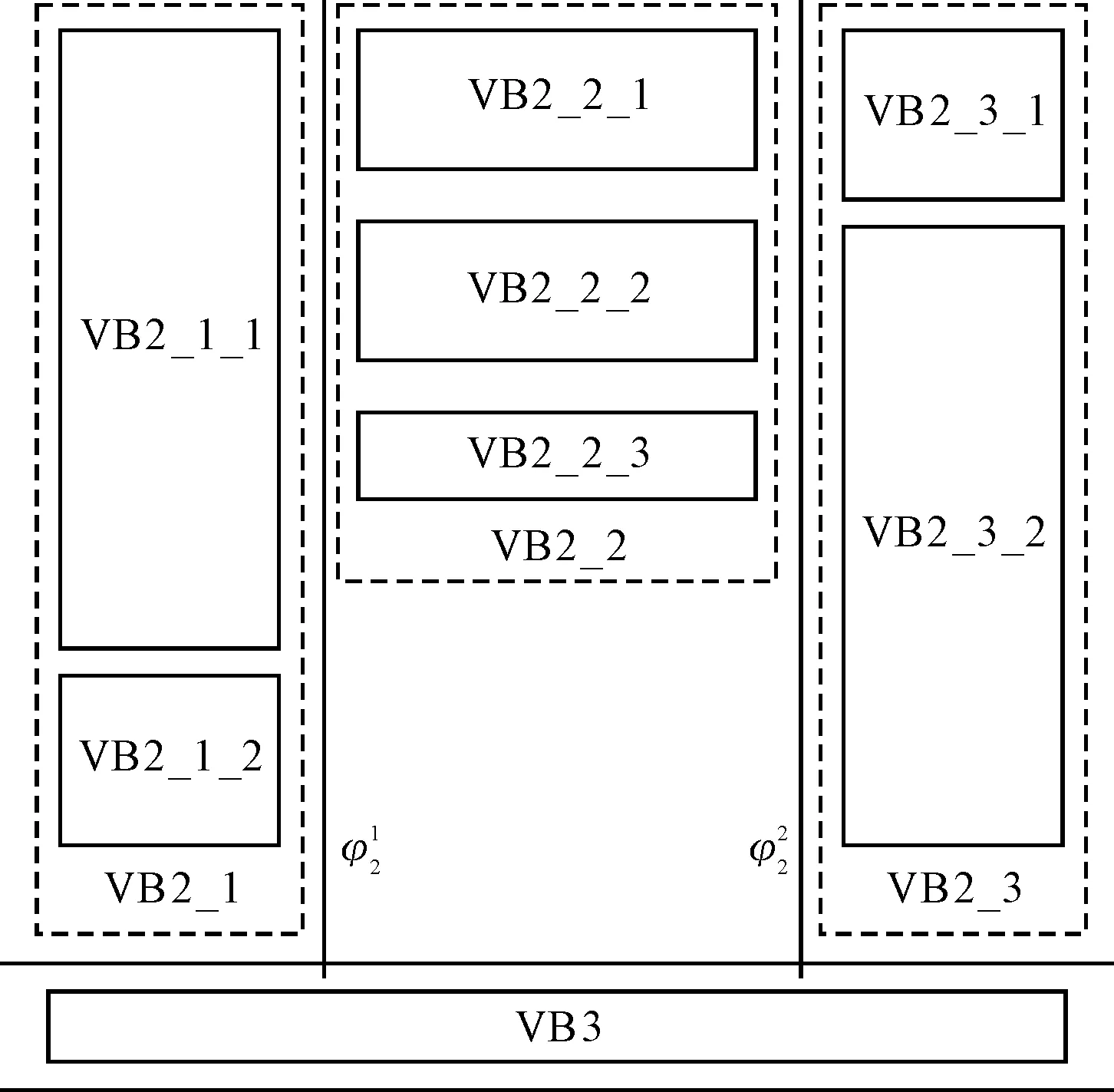
图6 页面视觉分块图
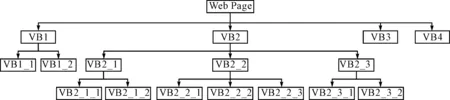
图7 页面视觉块对应的DOM结构图
3实验
本文实验分别实现传统的基于DOM树的网页信息抽取方法和本文提出的基于基准视觉块的逆序提取网页正文信息的抽取方法,并把这两种方法做比较,以体现本文提出的方法的优势。传统的基于DOM树的网页信息抽取方法主要是用一些开源工具如NekoHTML、Jtidy等把Web页面解析成一棵DOM树,然后深度遍历DOM树节点提取出页面正文信息。该方法实现简单,并具有一定代表性。本文通过对当当网、淘宝网等一些特定领域网站提交关键词查询获得大量的结果页面,把这些结果页面作为实验数据的来源。实验环境采用的是:主机ASUS,处理器Intel(R) Celeron(R) CPU 1.50GHz,内存4GB,硬盘250GB,操作系统为Window 7。

图8 两种算法使用的节点数比较
图8显示的是使用两种不同的算法提取正文信息需要解析的DOM树节点数,从图中可以看出,不管是提取哪一类的网页,经过去噪处理的基于基准视觉块的逆序提取方法都只需解析几乎只包含正文信息的DOM节点。
另外,为了进一步验证该算法的性能和可行性,本文进行了信息抽取的准确率实验。分别对每类网站抽取10个页面,人工提取出关键正文信息,并估算总共包含的正文信息个数,与本文提出的抽取出正文信息块方法抽取出的正文信息以及正文信息数量进行人工比对,结果如表1所示。

表1 Web页面信息抽取性能
其中完整率=(抽取到正文信息个数/总共包含的正文信息个数)×100%;准确率=(准确抽取到正文信息个数/抽取到正文信息个数)×100%。从实验结果可以看出,本文提出的基于基准视觉块的Web页面抽取方法可以较准确并完整地抽取到所需要的正文信息,证明了该方法的可行性。由于一些网站,例如搜狐,并不属于纯粹的针对特定领域的网页,所以该类网页中包含的干扰视觉信息块较多,并且正文信息与基准信息不具有相似的视觉特征和位置特征,所以有部分正文信息块会被遗漏,导致抽取的完整率和准确率会有所下降。
4结语
本文在基于DOM树结构的Web页面基础之上,利用人的视觉特征,首先根据一些启发式规则对原始页面去噪优化,然后利用VIPS算法把Web页面分成不同的视觉块,根据正文信息在页面的分布特征提取出基准视觉块,并根据基准视觉块的视觉特征逆序和顺序遍历整棵DOM树,递归提取出所有相似的视觉块。从实验结果来看,本文提出的方法在提取速度方面与传统方法相比有了一定的提高,并且有较高的准确率和完整率。但是本文的方法还有许多有待改进的地方。比如该方法比较适用于主题单一的网站,即整个网页只含单个文本区域的网站。如果页面结构较复杂,文本块较多,那么使用该方法有可能丢失一些有用的信息。另外,基准视觉块的大小也是一个关键,视觉块过大或过小都会影响实验的准确性和提取效率,下一步将对这方面做进一步研究,以达到更好的抽取效果。
参 考 文 献
[1] 吴茜,刘嘉勇.基于VIPS算法和模糊字典匹配的网页提取技术研究[J].技术研究,2014(10):49-53.
WU Qian, LIU Jiayong. Web Page extraction technology research Based on VIPS algorithm and fuzzy dictionary matching[J]. Netifo Security Technology Research,2014(1):49-53.
[2] 安增文,徐杰锋.基于视觉特征的网页正文提取方法研究[J].微型机与应用,2010(3):38-41.
AN Zengwen, XU Jiefeng. Web Page text extraction technology research Based on Visual feature[J]. Micro Computer and Application,2010(3):38-41.
[3] 郭迎春,刘一伟,陈召旭.Deep Web数据抽取的分析与研究[J].南开大学学报(自然科学版),2012,45(3):9-14.
GUO Yingchun, LIU Yiwei, CHEN Zhaoxu. Analysis and Research on Deep Web Data Extraction[J]. Journal of Nankai University(Natural Science Edition),2012,45(3):9-14.
[4] Wachirawut Thamviset, Sartra Wongthanavasu. Information extraction for deep web using repetitive subject pattern, World Wide Web 2014 DOI 10.1007/s11280-013-0248-y.
[5] 顾韵华,高原,等.基于模板和领域本体的Deep Web信息抽取研究[J].计算机工程与设计,2014,35(1):327-332.
GU Yunhua, GAO Yuan, et al. Deep Web information extraction research Based on template and domain ontology[J]. Computer Engineering and Design,2014,35(1):327-332.
[6] 田建伟,李石君.基于层次树模型的Deep Web数据提取方法.计算机研究与发展 ISSN 1000-1239/CN 11-1777/TP,2011,48(1):94-102.
TIAN Jianwei, LI Shijun. Deep Web data extraction method based on hierarchical tree model[J]. Computer Research and Development ISSN 1000-1239/CN 11-1177/TP,2011,48(1):94-102.
[7] 李朝,彭宏,叶苏南,等.基于DOM树的可适应性Web信息抽取[J].计算机科学,2009,36(7):202-210.
LI Chao PENG Hong, YE Sunan, et al. Adaptive Web information extraction based on DOM Tree[J]. Computer Science,2009,36(7):202-210.
[8] 寇月,李冬.D-EEM:一种基于DOM树的Deep Web实体抽取机制[J].计算机研究与发展,2010,47(5):858-865.
KOU Yue, LI Dong. A Deep Web entity extraction mechanism based on DOM Tree[J]. Computer Research and Development,2010,47(5):858-865.
[9] 付涛.基于DOM和显示属性的网页信息除噪技术研究[J].商丘师范学院学报,2010,26(9):90-93.
FU Tao. Web Information noise cancellation technology research Based on DOM and Display attributes[J]. Journal of Shangqiu Normal College,2010,26(9):90-93.
[10] Deng Cai, Shipeng Yu. Extracting Content_Structure for Web Pages based on Visual Representation Microsoft Research Asia.
[11] 张瑞雪,宋明秋.逆序解析DOM树及网页正文信息提取[J].计算机科学,2011,38(4):213-215.
ZHANG Ruixue, SONG Mingqiu. Reverse parsing the DOM tree and informaiton extraction on the web page[J]. Computer Science,2011,38(4):213-215.
Deep Web Information Extraction Method Based on Visual Features
SUN LuCHEN JunhuaLIAN Desheng
(Shanghai Normal University, Shanghai200234)
AbstractWith the constantly development of Web database, a large number of information can not be got by ordinary search engine. The results which users want to get need them submit the form query so that the information can be got from the database behind called Deep Web. Thus how to effectively extract these information become a problem which worth of study. This paper propose an improved method by analyzing the characteristics of the results pages combining with human visual sense. This method makes full use of human visual characteristics, before the parser parsed the Web document into a syntax tree, and removed some information which has nothing to do with the theme such as navigation, advertising, etc. After that, division the DOM tree into semantic block using VIPS algorithm. Sw we can find the standard block according to the block’s position, then put the standard block as center block which used to find all similar visual blocks by reversing and suquential traversal the DOM tree. These result blocks are the information blocks which we want to extraction. According to the experimental results, this method has some improvement from the aspects of accuracy rate and complete rate to some extent compared with traditional method.
Key WordsDeep Web, visual characteristics, DOM tree, semantic block, information extraction
收稿日期:2015年12月5日,修回日期:2016年1月23日
作者简介:孙璐,女,硕士研究生,研究方向:数据库。陈军华,男,硕士,副教授,研究方向:数据库。廉德胜,男,硕士研究生,研究方向:人工智能。
中图分类号J653
DOI:10.3969/j.issn.1672-9722.2016.06.026
