
一种缓存数据流信息的处理器前端设计
2016-07-19 01:54刘炳涛叶笑春范东睿张志敏
计算机研究与发展 2016年6期
关键词:数据流
刘炳涛 王 达 叶笑春 张 浩 范东睿 张志敏
1(中国科学院计算技术研究所 北京 100190)2 (中国科学院大学 北京 100049) (liubingtao@ict.ac.cn)
一种缓存数据流信息的处理器前端设计
刘炳涛1,2王达1叶笑春1张浩1范东睿1张志敏1
1(中国科学院计算技术研究所北京100190)2(中国科学院大学北京100049) (liubingtao@ict.ac.cn)
摘要为了能够同时发掘程序的线程级并行性和指令级并行性,动态多核技术通过将数个小核重构为一个较强的虚拟核来适应程序多样的需求.通常这种虚拟核性能弱于占有等量芯片资源的原生核,一个重要的原因就是取指、译码和重命名等流水线的前端各阶段具有串行处理的特征较难经重构后协同工作.为解决此问题,提出了新的前端结构——数据流缓存,并给出与之配合的向量重命名机制.数据流缓存利用程序的数据流局部性,存储并重用指令基本块内的数据依赖等信息.处理器核利用数据流缓存能更好地发掘程序的指令级并行性并降低分支预测错误的惩罚,而动态多核技术中的虚拟核通过使用数据流缓存旁路传统的流水线前端各阶段,其前端难协同工作的问题得以解决.对SPEC CPU2006中程序的实验证明了数据流缓存能够以有限代价覆盖大部分程序超过90%的动态指令,然后分析了添加数据流缓存对流水线性能的影响.实验证明,在前端宽度为4条指令、指令窗口容量为512的配置下,采用数据流缓存的虚拟核性能平均提升9.4%,某些程序性能提升高达28%.
关键词处理器微结构;指令缓存;数据流;指令重命名;数据流局部性
因为结构复杂度增长和功耗墙[1]等问题,单核处理器频率和性能的增长在21世纪初遇到瓶颈.处理器结构设计师们转而通过增加片上集成的处理器核数来维持处理器符合摩尔定律的性能增长[2].如今多核处理器已经逐渐占据了桌面和移动处理市场.
片上多核处理器(chip multi-processor, CMP)通过发掘程序的线程级并行性(thread-level parall-elism, TLP)来提供更高的处理能力.但利用程序的TLP有其局限性:1)历史遗留的大量串行程序并没有合理的并行化方案;2)通用处理领域大部分的计算并没有足够的TLP可供发掘;3)Hill与Marty[3]指出,根据阿姆达法则,随着程序中并行部分的加速,串行部分渐渐成为继续降低程序运行时间的瓶颈.这些都表明处理器的单线程处理能力仍然非常重要.
芯片资源总量固定的情况下,核数增加会提升处理器发掘TLP的能力,同时单核分得资源减少,降低处理器发掘指令级并行性(instruction-level parallelism, ILP)的能力.为了在多核设计中兼顾发掘程序的TLP与ILP,学术界提出了动态多核(dynamic multi-core, DMC)技术[3].DMC处理器可以动态地将数个较弱的原生核(native core, N-Core)合并为一个较强的虚拟核(virtual core, V-Core),增加处理器发掘ILP的能力.DMC技术按应用的需求重构多核的组织形式,打破了处理器发掘ILP与发掘TLP之间不可调和的边界.采用DMC技术的处理器,其适应性和通用性强于固定搭配处理器核的其他类型的多核处理器.
用多个小的N-Core通过DMC技术动态重构出的V-Core,其性能通常要弱于用等量芯片资源直接实现的一个大的N-Core.一个重要的原因在于V-Core取得指令的能力弱于其执行指令的能力.首先,取指、译码和重命名等流水线前端各阶段具有串行处理的特点,较难协同工作来成倍增加指令的供给带宽.而流水线后端的发射、执行、写回等阶段因具有并行处理的特点,相对较易经重构后协同工作增加指令处理能力.其次,传统的流水线从存储器中取得的有效指令数目与执行单元处理的有效指令数目相等,前后端耦合工作.流水线的以上2个特点,决定了DMC处理器中不同粒度的V-Core与N-Core不能全部做到流水线前后端匹配,并导致了DMC处理器不能在各种动态组织形式下都达到极优性能.
为了解决DMC处理器中存在的上述问题,我们提出了一种新的处理器前端设计,称作数据流缓存(dataflow cache, DF-Cache),并给出了与之配合的向量重命名(vector renaming, VR)机制.DF-Cache利用数据流局部性(dataflow locality),其操作的基本单元是经译码和重命名处理后的指令基本块,包含了数据依赖等信息.当指令基本块在DF-Cache中命中时,经向量重命名后,流水线可以立即将其指令交付发射队列,旁路了流水线前端各阶段.DF-Cache的作用体现在如下2点:1)DF-Cache提升了流水线的指令供给带宽并降低了指令供给延迟,进而提升了处理器发掘程序ILP的能力,同时降低分支预测错误带来的惩罚;2)DMC处理器中的V-Core利用DF-Cache旁路流水线前端各阶段,并不需要取指、译码和重命名等流水线阶段经合并后协同工作.当DF-Cache对动态指令的覆盖率很高时,处理器执行的大部分指令并非直接取自前端,流水线前端的处理能力不再限制流水线后端对指令的执行,前后端不匹配的问题得以解决.
对SPEC CPU2006中程序的实验证明了DF-Cache能够以有限代价覆盖大部分程序超过90%的动态指令;另外,我们分析了添加DF-Cache对流水线性能的影响.实验证明,在前端宽度为4、指令窗口大小为512的配置下,采用DF-Cache的V-Core程序执行性能平均提升9.4%,某些程序执行性能提升高达28%.
1相关工作
DF-Cache通过发掘数据流局部性来提升流水线前端指令供给能力,进而解决DMC处理器中V-Core前后端能力失配的问题.相关工作分为如下2节.
1.1流水线前端的指令供给与数据流局部性
为了使处理器的指令窗口有足够负载,很多研究着眼于提高流水线前端的指令供给能力.这些研究通常采用的方法是通过使用各种缓存结构来旁路相应流水线阶段的操作,从而达到降低延迟、提高带宽的目的.
传统的指令缓存(instruction cache, ICache)利用计算的时间局部性,实现了容量大、延迟低的指令存储结构,从而降低取指延迟[4].DF-Cache也是一种指令的缓存,降低指令进入发射队列之前的总的前端延迟.与ICache的不同有2点:1)DF-Cache缓存的是动态指令的数据流图,可以直接供后端使用,而ICache缓存的是统一编址内存空间内的静态指令;2)DF-Cache的操作单元是以分支等控制指令分割的指令基本块,而ICache操作单元是以地址索引的数条指令组成的缓存行.
Loop Cache[5]利用回跳分支指令发现计算中的循环,然后对循环指令进行缓存降低取指延迟.Loop Cache在Intel的Nehalem架构处理器中已有应用[6],Nehalem中的loop stream detector存储译码后的28条微指令,可以旁路译码等流水线阶段.相较Loop Cache,DF-Cache系统发掘了动态指令流中的数据流局部性,不局限于特殊指令或单个循环,可以加速多个或多重的循环代码的取指.
Trace Cache[7]比Loop Cache更进一步.它缓存译码后的指令,用首指令地址与后续数个分支的结果进行索引.如果与多个分支预测的结果匹配,Trace Cache可以在1个周期内跨越多个分支提供指令,大大提升前端带宽.Trace Cache已在商业处理器中得到应用,Intel的Sandy-Bridge架构处理器中的decoded uop cache即是一种Trace Cache,可以覆盖80%的处理器动态指令[8].DF-Cache相比较Trace Cache有2点改进:1)DF-Cache相比较Trace Cache多缓存了基本块内的指令依赖信息,所以流水线利用DF-Cache能够旁路了重命名阶段前半部分消除名相关的工作;2)DF-Cache 的操作单元是指令基本块,相比较Trace Cache,在存储空间使用效率[9]和与分支预测相关的操作上更具优势.实验证明,DF-Cache以更小的硬件代价实现了更高的指令覆盖率.
Swanson等人[10]提出了数据流局部性的概念,将其解释为程序中动态数据依赖的可预测性.为了发掘这种局部性,WaveScalar提出了新的指令集和微结构.DF-Cache则仅在微结构上做改进,不需要修改指令集,而对数据流局部性的发掘更有针对性.
Oberoi与Sohi[11]提出并行化流水线前端的方案.其中称为Fragment Buffers的结构可以缓存取得的指令并重用.根据测试程序的不同,可以使用16个这种缓冲区覆盖程序20%~70%的指令.这种缓冲区的管理方式与DF-Cache类似,不过缓存的内容却不同,Fragment Buffers并没有为了发掘数据流局部性做针对性的设计.
总而言之,提高指令供给能力的研究通常是通过有选择的缓存前端流水线各阶段的结果来加速后续的重复操作,指令覆盖率是衡量其效果的重要指标.首先,DF-Cache的设计符合该逻辑;其次,DF-Cache针对发掘数据流局部性而设计,与以往研究不同.结构上体现于2点:1)DF-Cache缓存并重用了重命名阶段的数据依赖信息,据我们所知,这是之前研究所没有的;2)缓存的粒度为指令基本块,提高前端能力的同时可以高效地利用片上资源,与预测执行等技术更直接衔接.
1.2动态多核技术
在多核处理器善于发掘TLP的基础上,DMC技术合并N-Core构建较强的V-Core来适应程序对ILP发掘的需求.
Core Fusion[12]可以将宽度为2的N-Core“融合(FUSE)”为宽度为4或8的V-Core,它提出了详细的重构方案.前端的Fetch和Decode阶段通过同步措施协同工作,然而Rename阶段却没有融合.当处理器数个N-Core按照V-Core的模式工作时,N-Core自身的重命名部件被旁路,而由单独的SMU负责V-Core的重命名和指令分发工作.当融合出的V-Core的宽度大于8时,SMU便难以实现.Fetch与Decode的同步开销增长亦不容忽略.Core Fusion融合得出的V-Core前端不具可扩展性,导致Core Fusion的能融合的N-Core数目和获得的V-Core的宽度受到限制,V-Core的性能也要弱于占用等量芯片资源的N-Core.
CLP(composable lightweight processor)[13]通过特殊的广播与收集措施完成V-Core中指令的取指与提交.因为没有核间共享的结构,其可扩展性要强于Core Fusion.但是CLP依赖非传统ISA的EDGE指令集来实现分布式的指令处理结构,需要编译器的支持,其适应性不如DF-Cache.
WiDGET[14]区别线程管理和计算资源分配,将计算资源从流水线中解耦合出来形成资源池,按应用需求分配计算资源给硬件线程形成V-Core.该DMC技术只重构计算资源,流水线的串行部分在形成V-Core时没有任何改变,其目的在于实现与功耗成比例的计算,其V-Core不具有可扩展性,流水线的宽度没有改变,所以无法动态调整芯片发掘TLP和发掘ILP的能力.
Dynamic Core Morphing[15]通过动态组合2个非对称核后端的计算资源,使其适应应用的需求,达到更好的功耗计算比.该DMC技术重构的多种V-Core不能都达到前后端匹配,影响处理器总体能达到的性能.
从以上研究可以看出,目前已有的DMC技术并没有提出合理的流水线前端的重构方案.Core-Fusion的前端融合缺乏可扩展性,CLP为了构建V-Core借助于非传统ISA,WiDGET和MorphCore等则不考虑对流水线前端做动态改变.DF-Cache加入流水线后可以部分替代传统的流水线前端,通过发掘数据流局部性为流水线后端提供指令,从而解决DMC中各种V-Core前端能力不足的问题.
2数据流缓存的原理与扩展的流水线结构
以存储程序为特征的冯-诺依曼体系结构将程序指令存放在统一编址的存储空间内,我们称之为静态指令.程序要被处理器执行,首先需要从内存中将静态指令取出,然后经过译码和重命名变为适合执行单元使用的微指令的形式,我们称之为动态指令.提高静态指令到动态指令的转换效率和提高动态指令的执行效率是冯氏结构的2个基本问题.DF-Cache尝试解决上述第1个问题.我们分别从计算模型和处理器微结构2个角度阐述DF-Cache的原理及优势.
1) 从计算的角度看.DF-Cache充分利用计算的数据流局部性,提高了处理器前端指令供给能力.
静态指令与动态指令的数量有量级上的差距,从侧面说明动态指令流有很好的时间局部性.利用这种局部性,从内存到发射队列间的整个指令转换过程有可以优化的环节.比如ICache,它通过缓存并重用从内存中取得的指令,使得处理器执行的动态指令数量远大于从内存中取得的静态指令数量.DF-Cache更进一步将缓存从取指阶段推进到重命名阶段之后,即指令转换的最后一个环节.而DF-Cache利用的数据流局部性,则是计算的时间局部性在传统的ISA格局下一种特殊的表现形式.
比较程序存储的静态指令代码和执行的动态指令流,我们可以发现,以分支等控制指令为边界划分的指令基本块在内容上是一一对应的.单个静态的指令基本块通常对应1个或数个动态的指令基本块实例,而这些实例内的指令依赖等信息完全相同.所以动态指令流中地址连续的指令之间的重命名结果可以缓存并重用,这就是数据流局部性的具体体现.着眼于此,我们的缓存结构将由控制指令分割的指令基本块作为操作单元.DF-Cache缓存指令基本块内的各种信息,包括译码后的微指令和微指令间依赖等.指令转换工作剩余部分则还有分支等控制指令的预测和验证,以及基本块间的操作数依赖表示.这2点是指令转换过程中没有可重复性的部分.当指令基本块在DF-Cache中命中时,通过复用存储的基本块内数据流信息,传统处理器前端的取指、译码和重命名的解决名相关部分等都被旁路,降低了前端的延迟,提高指令供给带宽.
2) 从微结构的角度看.DF-Cache加入流水线后,解耦合了流水线的前端和后端.这解决了DMC技术中前端难以重构和前后端能力失配的问题.
DMC技术[12]中多个N-Core的前端很难通过合并达到更高的指令供给能力.流水线的后端天然有并行处理的特点,发射队列与执行单元的动态组合问题可类比于传统单核处理器中分簇(clustered)后端的设计问题.然而流水线的前端负责指令转换,串行处理的特点导致其很难协同工作.尤其是重命名阶段,针对指令的重命名多采用级联比较器和多路器的设计[16],串联多个重命名部件导致一个超长的重命名延迟是无法接受的.所以像Core Fusion中的SMU[12]部件,重构的V-Core常另外设计结构替代单核内的重命名部件.即便如此,因为指令重命名串行处理每条指令的特点,目前已知的前端设计方法不具有可扩展性,很难匹配V-Core的流水线后端增长的带宽需求.
DF-Cache作为一种存储主体基于RAM的结构,通过整合多个核的DF-Cache可以实现更高的动态指令覆盖率,提供更高的读写带宽,具有可扩展性.利用DF-Cache进行指令转换的带宽和延迟由向量化重命名决定,它与基本块的数量相关,而不与指令数量直接相关.另一方面,DF-Cache位于流水线前端与后端的结合处,DF-Cache命中时取指、译码和重命名阶段被旁路,这些流水线阶段的能力并不直接决定流水线转化指令的能力.如果对动态指令流有很高的覆盖率,DF-Cache可以满足后端对指令供给的需求.这样前后端的处理能力不匹配对V-Core的整体效率没有影响.另外,不同于执行单元数量和流水线宽度的设计考量,DF-Cache不存在过度设计,它所要考虑的是对动态指令的覆盖率,与程序的ILP大小、流水线的执行能力强弱不直接相关.

Fig. 2 The logic function and organization of UB.图2 UB的逻辑功能与结构
添加DF-Cache后的流水线结构如图1所示.虚线上方为DF-Cache对一个传统流水线的扩展.DF-Cache命中的指令基本块,不经过取指和译码阶段,而后端的执行和提交阶段为2条流水线所共用.
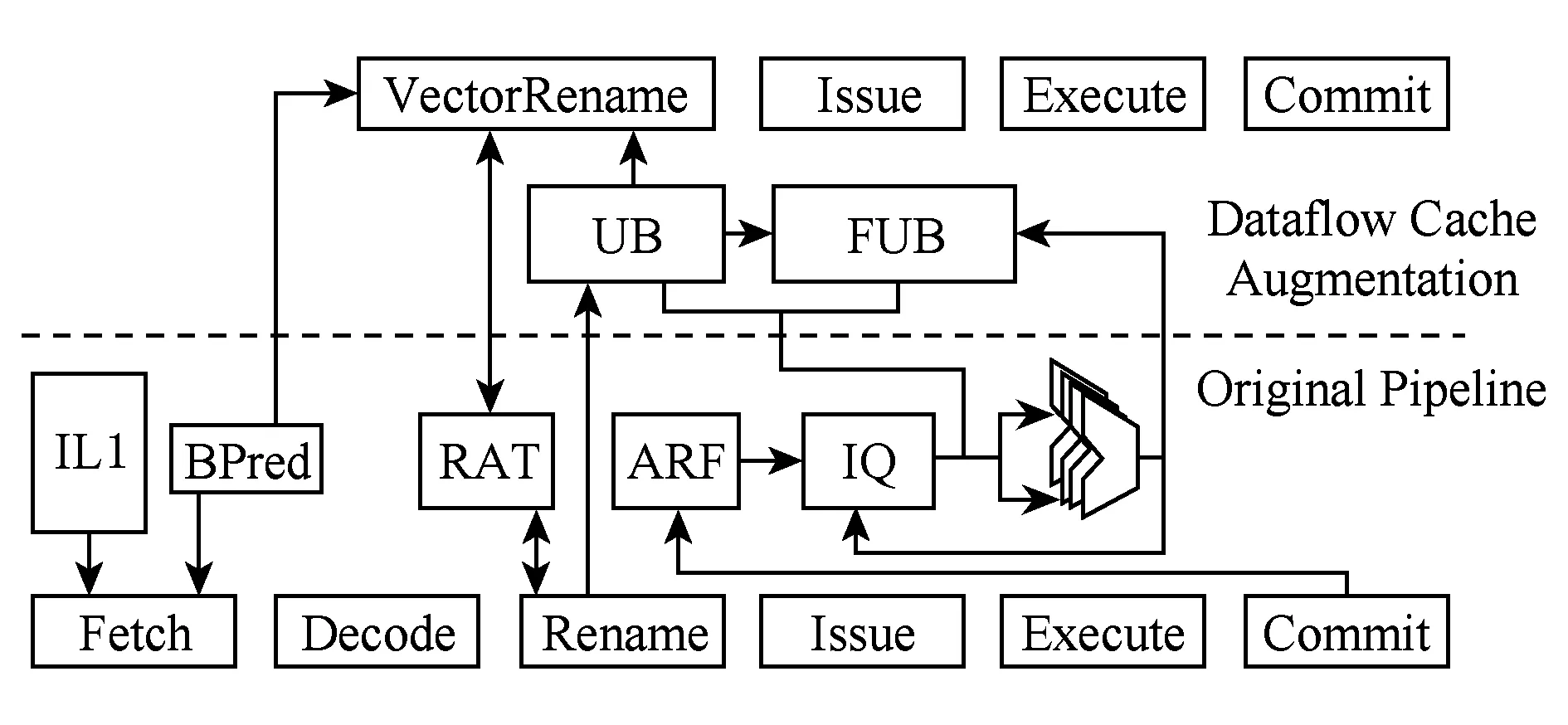
Fig. 1 Pipeline augmented with DF-Cache.图1 DF-Cache扩展的流水线
从图1可以看出,如果DF-Cache覆盖了动态指令流,那么计算就在DF-Cache和执行单元之间构成了封闭循环,指令快速地填充到发射队列,后端执行单元被最大限度地使用.
基本指令块被缓存的信息集合称为config.指令转换时如果命中这个config,后端分配物理寄存器和发射队列空间给基本块的实例,我们称其为属于该config的1个帧(frame).config对应静态的指令基本块,而frame对应动态的指令基本块.config存放微指令的编码以及基本块内指令间的相对数据依赖等信息,frame存放指令的操作数等信息.
DF-Cache含有2个组件:微指令缓冲区(uop buffer, UB)和帧更新缓冲区(frame update buffer, FUB),分别存放config和frame,如图1所示.
DF-Cache的功能主要有3个:1)UB命中时,它替代取指和译码阶段以及重命名阶段的部分功能,完成指令的获取;2)与发射队列(issue queue, IQ)并列的FUB,与指针追踪部件配合,完成指令的唤醒和选择;3)指令从UB到FUB的填充,由VR部件负责.本节分别介绍这3个功能的实现.
2.1微指令缓冲区UB
UB存储译码后的指令基本块,逻辑功能如图2所示,物理实现示意如图3所示.

Fig. 3 Implementation of UB.图3 UB的逻辑物理实现
UB由主微指令缓冲区(main-UB)和宏微指令缓冲区(mega-UB)组成.main-UB存储微指令相关的信息,比如微指令编码、微指令间寄存器依赖等,如图2(c)所示;main-UB由RAM实现,mega-UB存储基本块的宏信息,比如首指令的PC值(idxPC)、最后的控制指令的PC值(brPC)等,如图2(d)所示;mega-UB是基于CAM结构的全相连Cache,用idxPC做索引标签(tag),UB的各字段组成及大小评估如图3所示.
读取缓存的微指令是UB在流水线中的关键路径操作,主要有2步:1)通过idxPC检索mega-UB,获得微指令在main-UB中的存储地址(mainUBPtr);2)在main-UB中取出微指令.main-UB对指令基本块分行存储,各行之间通过指针组成链表.只有首行的微指令读取需要检索mega-UB,后续的微指令通过追踪指针(NextRowPtr)访问main-UB即可获得.
图2(a)展示了地址从0x10c50到0x10c60的指令基本块.首指令地址0x10c50作为该指令基本块的索引,通过检索mega-UB的idxPC字段确认DF-Cache是否命中,并获得基本块在main-UB中的首行存储地址,进而在main-UB中读取微指令.同时,0x10c60作为brPC从mega-UB中读出,分支预测器(BPred)使用brPC做分支预测,获得下一个基本指令块的idxPC,继续检索mega-UB,循环往复.
DF-Cache的取指方式与ICache相比,有3个特点值得注意:
1) 基于传统的取指逻辑,BPred必须在ICache取到控制指令后才可以利用其PC值作出分支预测.而mega-UB与BPred的互动不需要访问main-UB.这缩短了分支预测之间的间隔,理论上每个周期都可以从新的指令基本块开始取指,多个指令基本块的微指令读取周期可以重叠(overlap).
2) 获得同样多的指令,mega-UB的访问次数不会多于ICache.因为mega-UB只有遇到控制指令时才进行检索,而ICache在这种情况下也必须进行tag比较.同时ICache在遇到Cache行分界时都要进行检索,其访问次数应大于mega-UB.
3) mega-UB与BPred以及后续提到的向量重命名逻辑三者配合,可以比较自然地实现基于检查点(checkpoint)的预测执行.每次mega-UB的检索,都是进行了一次分支预测,产生了一个新的frame到FUB中,同时进行一次向量重命名.此时建立checkpoint,存储当前节点的结构寄存器映射以及一个最新的frame相关信息.将来控制指令执行后,如果发现分支预测错误可以进行回卷.首先丢掉(flush)后续预测执行的frame;错误的分支预测指令所在的frame因为没有提交(commit),其所在的config引用计数(refCNT)就不为0,从而config也不会被替换掉,利用checkpoint中的信息做现场恢复,利用正确执行方向的idxPC检索mega-UB恢复执行.
图2(b)展示了我们如何利用依赖指针(depen-dence pointer)[17-18]表示指令的操作数依赖.依赖指针是前向的(forward)数据流依赖表示,例如指令B依赖指令A,那么在指令A的操作数寄存器旁并列存放着指向指令B的源操作数物理寄存器的指针,当指令A的操作数更新后,指令追踪部件负责将操作数传递给指令B.指令依赖指针与RAM的实现相结合用来实现可扩展的发射队列.指令基本块作为整体,对结构寄存器文件的读写集合存储在结构寄存器读写向量内,用来做向量重命名.
图2(c)展示了基本块内的微指令和依赖信息在main-UB中的存储情况.FUB分为3个块(bank),依次存储微指令的2个源操作数和1个目的操作数,bank由bid索引.指令间的相对依赖由uopid和bid组成的依赖指针链表示.arch项记录了这个操作数是来自或写入哪个结构寄存器.
图2(d)列举了mega-UB的字段.idxPC用来做缓存的检索,判断缓存是否命中;brPC提供给分支预测器使用;LRUPtrs为记录基本块访问的时间先后顺序的双向链表指针,用来维护LRU(least recently used)信息;mainUBPtr是基本块在main-UB的首行地址;uopCNT记录了基本块内的微指令数目,这个字段用来在FUB中分配连续的空间;refCNT记录属于此config的frame实例数量;rdVec和wrVec这2个字段用来做向量重命名.
DF-Cache未命中时,由ICache负责取指,同时DF-Cache采集指令基本块的信息,并逐步完成基本块内的指令依赖表示.整个基本块取指译码完成后,尝试在DF-Cache中存储该指令基本块.
DF-Cache满时,包括2种情况:mega-UB溢出和main-UB溢出.DF-Cache使用LRU策略进行替换,在mega-UB中LRUPtrs组成的双向链表尾逐个向前清理,直到mega-UB中有空闲条目,main-UB中有足够空行.
DF-Cache中条目的构建与替换不是流水线的关键路径操作,限于篇幅限制不再继续展开.
对动态指令的覆盖率决定了DF-Cache的实际应用效果.着眼于应用的数据流局部性特征,我们对不同设计参数配置的UB进行实验,考察DF-Cache的指令覆盖率.同时,DF-Cache的面积、功耗与延迟作为约束,也决定了其是否有实现的价值.详细分析见3.1节的实验部分.
2.2向量重命名VR
传统的重命名部件的操作对象是单条指令.1)为每条指令分配存储操作数的物理寄存器和发射队列空间;2)解决名相关依赖,比对指令的操作数编码和寄存器重命名表(register aliasing table, RAT),获得每个操作数依赖的物理寄存器编号或者从寄存器文件中读出操作数的值,并更新RAT;3)将指令和操作数等写入发射队列.
向量重命名与传统重命名结果相同,但过程不同.我们将指令的寄存器依赖分为2类:位于基本块内的和位于基本块间的依赖.1)DF-Cache存储了基本块内的依赖,只要将config中存储的依赖关系加上frame在FUB中的偏移,即可得到绝对依赖关系;2)向量重命名部件对数个基本块的读写向量进行处理,分析基本块间的依赖得出操作数传递路径,并将其补充到发射队列里,完成基本块间的指令依赖表示.指令进入发射队列后,不再有块内和块间的区分,被独立地调度执行.
DF-Cache连续命中时,向量重命名部件可在2个流水的时钟周期内完成数个基本块的重命名和发射队列的填充操作.
周期1.VR完成基本块内的重命名,并为基本块间的重命名做准备.VR的操作对象是被分支预测选中且在DF-Cache中命中的数个指令基本块.首先,每个frame获得唯一的frameID并从main-UB向FUB中复制微指令,即在FUB中分配一块连续的物理寄存器和发射队列空间并对应uopid复制基本块内指令的相对依赖指针和立即数操作数.其次,main-UB中的结构寄存器读写字段也被读取,VR将表示块间依赖的读写向量和对应的物理寄存器的地址存储到向量重命名部件内,为第2周期的工作做准备.图4展示了第1周期操作的结果.
周期2.VR完成基本块间的重命名.利用读写向量和对应的物理寄存器地址,VR将块间寄存器依赖补充到指令窗口中,同时更新RAT.更新依赖时,结构寄存器的写向量的物理寄存器依赖指针地址作为更新地址,对应的读向量的物理寄存器地址作为更新值.我们以图4(a)的基本块为例子,假设分支预测器给出连续3个0x10c60的分支都是预测命中,那么我们要将该config的3个frame更新到指令窗口中.假设3个frame在VR的第1周期内分得的frameID分别是0x0a,0x0b,0x0c.第2周期的向量重命名过程和指令窗口更新结果如图5所示.
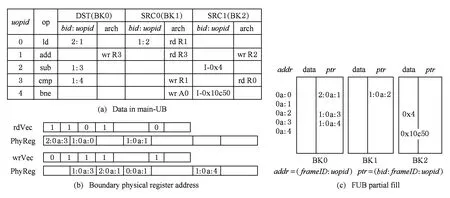
Fig. 4 First cycle of VR.图4 向量重命名第1周期

Fig. 5 Second cycle of VR.图5 向量重命名第2周期
向量重命名要求获得每个frame的结构寄存器读写向量,并且有对应物理寄存器的地址.依赖的发现和表示过程举例说明.首先是R0结构寄存器,如图5(a)所示的虚竖线,从上到下依次为1 10 10 10 1.VR从读向量为1的位置入手,其获得的操作数来自离它最近的前面一个标记为1的位置*FUB采用单链的指针追踪实现唤醒和选择,使得发射队列可扩展.如果采用广播的形式完成唤醒,要考察标记为1的最近的写,通过减少参数传递的跳数,缩短指令唤醒的延迟..比如BB0的读向量的R0位置的1和对应的物理寄存器地址2:0a:3说明,BB0的第4条微指令的第2个源操作数来自RAT记录的R0.如果RAT中R0位置是有效的,那么将结构寄存器的值拷贝到FUB的BK2的0a:3地址的data字段;如果R0的位置是无效的,而是记录1个物理寄存器的地址,物理寄存器地址(2:0a:3)拷贝到R0所记录的物理寄存器的依赖指针里,延续依赖链.再比如BB1的读向量的R1位置的1和对应的物理寄存器地址1:0b:0说明,BB1的第1条微指令的第1个源操作数来自BB0的第4条微指令的第1个源操作数(1:0a:3),将(1:0b:0)写入到(1:0a:3)位置的物理寄存器的依赖指针内,延续依赖链.最后,见图5(a)中的RAT′,将每个最后写结构寄存器的物理寄存器的地址更新到RAT表中.更新后的FUB见图5(b).
VR大部分的逻辑操作可以向量化地并行进行.以图5(a)的向量重命名的位矩阵为例.VR可以分别操作各个结构寄存器对应的纵向位向量而互不影响,而针对单个横向的读位向量分别查询距离最近的1并负责更新FUB中的依赖,也可以并行进行.假设1个周期可以预测并写入到FUB中n个基本指令块,而结构寄存器有m个,那么需要(n+1)m个判断位是否为1并查询长度为(2n+1)的向量中最后的1的逻辑部件.硬件开销基本固定,与各基本块内的指令数和单周期内重命名的总指令数不直接相关.
2.3帧更新缓冲区FUB
FUB的设计类似于RUU[19],流水线并没有单独的物理寄存器文件,物理寄存器的地址与frame在FUB中的地址信息frameID相关联,FUB除了存储操作数的依赖信息并调度微指令外,还存储操作数.
与RUU不同的是,FUB由RAM而不是CAM组成,数块RAM加上指令追踪部件实现可扩展的发射队列.我们采用了类似ForwardFlow[18]中Dataflow Queue的设计.
在2.2节中已经提到了FUB的部分实现,FUB由main-FUB和mega-FUB组成.main-FUB作为指令窗口的组成部分*另一部分是标量重命名所使用的发射队列,如图1中IQ所示,同样采用类似DataflowQueue的设计.除了填充指令方式不同,IQ与FUB在指令唤醒和选择上是统一的.,与依赖追踪部件协同完成指令的唤醒(wakeup)和发射(issue).mega-FUB用frameID索引,记录属于frame整体的信息,比如frame属于哪个config以及该frame还有多少条uop没有发射等,这些信息用来协助管理UB和FUB.
依赖追踪部件沿依赖链逐个传递操作数,同时它负责唤醒指令并提供可以发射的指令给选择逻辑(select logic).在更新操作数后,追踪部件会将指令的2个源操作数读出,如果操作数都准备好,负责将这条指令交给选择逻辑等待发射,发射如果不能立刻完成,依赖追踪部件会阻塞在这条指令上,直到发射完成.在更新操作数后如果另外1个源操作数没准备好,依赖追踪部件会继续沿依赖链传递操作数.这种指令依赖追踪与RAM结合的设计保证发射窗口有可扩展性,实现较大的指令窗口同时对性能没有太大影响[17-18,20].
每个指令追踪部件皆负责一段RAM的更新,不属于其管理范围的操作数会传递给负责该操作数的指令追踪部件处理.每个指令追踪部件有辅助的FIFO缓存属于该部件但无法立刻追踪的操作数.RAM的分段越多,FUB的读写带宽越大.总的指令追踪部件数量与RAM的分段数相同,并且决定了FUB单周期内能提供给选择逻辑进行发射的微指令数.
3实验结果与分析
3.1数据流缓存的动态指令覆盖率与实现代价评估
DF-Cache能以有限的代价覆盖足够的动态指令才有应用价值.我们首先考察DF-Cache在不同设计参数下对指令的覆盖率,然后分析DF-Cache的访问延迟、面积和功耗,并与32KB的ICache进行比较.
我们使用SPEC CPU2006[21]中的部分程序作为测试程序集,使用ref等级的输入数据,如表1所示.我们用ESESC模拟器[22]运行测试程序集,每个程序我们运行20亿条动态指令,分析DF-Cache对动态指令流的覆盖率.

Table 1 Selected SPEC CPU2006 Benchmarks And Input
在使用CACTI对不同参数的DF-Cache设计的面积、功耗和延迟进行分析后,我们认为mega-UB容量为256个条目、main-UB容量为512个数据行的配置较为合理,并将其作为3.2节实验的DF-Cache配置.该配置下DF-Cache对测试程序的平均动态指令覆盖率大于90%,其功耗、面积和访问延迟都要优于32 KB的ICache.
3.1.1数据流缓存的动态指令覆盖率
DF-Cache采用LRU替换策略,指令基本块能否在DF-Cache中持续命中,取决于其数据流局部性.数据流局部性的衡量标准即1个静态指令基本块的相邻2个动态实例之间间隔的指令基本块种类数.举例说明,假设mega-UB的条目数为4,遇到某个config的第1个frame时,该config被放到队列头,如果该config的第2个frame到来前遇到的基本块不超过3种,那么该config没有被替换,第2个frame仍能够命中.程序中属于相同config的frame之间间隔的config种类少,表明该程序有好的数据流局部性,用较小的mega-UB容量即可覆盖较多的动态指令.mega-UB中条目越多则动态指令覆盖率越高.另外,mega-UB是基于CAM的全相连Cache,条目增多会增加功耗并增大访问延迟.
mega-UB中每个条目对应单个指令基本块,而main-UB中每个数据行存储8个译码后的微指令,main-UB中每个数据行只能属于单个指令基本块,所以main-UB的行数应该大于等于mega-UB的条目数.
参照图3,mega-UB与main-UB的宽度是确定的,分别为25 B与64 B.需要考量的是部件的高度,即mega-UB中的条目数与main-UB中的数据行数.mega-UB的实现分为4种:CAM128,CAM256,CAM512,CAM1024.CAM代表了其硬件结构,数字代表了其含有的条目数.main-UB的实现分为3种:RAM256,RAM512,RAM1024.两者叉积构成DF-Cache的各种配置,例如CAM128与RAM256的组合记为mega-UB128 main-UB256.图6展示了有代表性的DF-Cache配置对测试程序的覆盖率结果.

Fig. 6 Instruction coverage by DF-Cache of different configurations.图6 不同配置DF-Cache的指令覆盖率
从图6可以看出,不同的程序表现出不同的特征.第1类程序包括gcc,namd,gobmk,h264ref等,这些应用的数据流局部性较差,对mega-UB的容量敏感.体现出这些应用的计算比较复杂,其控制流很可能与输入数据相关,通常其分支预测准确性也较低.第2类程序包括milc,libquantum,lbm,astar等,这些程序数据流局部性好、控制流简单,较小的mega-UB即可覆盖接近100%的动态指令.第3类程序包括其他的测试程序,当mega-UB的容量超过某值后,即可有较高动态指令覆盖率.从设计空间探索的角度看,我们所取的4个配置样本点无法完全满足第1类程序的数据流局部性要求,能满足第2类程序的数据流局部性要求,能覆盖到第3类程序的数据流局部性临界点.
观察经过几何平均的覆盖率,可以看到mega-UB256 main-UB512的DF-Cache配置对动态指令的覆盖率超过了90%.该数据已经超过了SandyBridge中decoded uop cache的80%的指令覆盖率.
3.1.2数据流缓存的实现代价分析
CACTI通过对存储器件进行建模可以分析其面积、功耗和访问延迟.我们首先分析DF-Cache的组件mega-UB和main-UB,然后计算得出不同配置的DF-Cache估计的实现代价.
mega-UB和main-UB的物理实现如图3所示,我们对RAM,CAM,ICache用CACTI5.3版本进行评估,配置间有差异的输入参数如表2所示,另外所有配置使用65nm工艺,有1个读写端口,bank数为1.

Table 2 CACTI Inputs
访问延迟、功耗与面积的评估结果分别如图7~9所示:
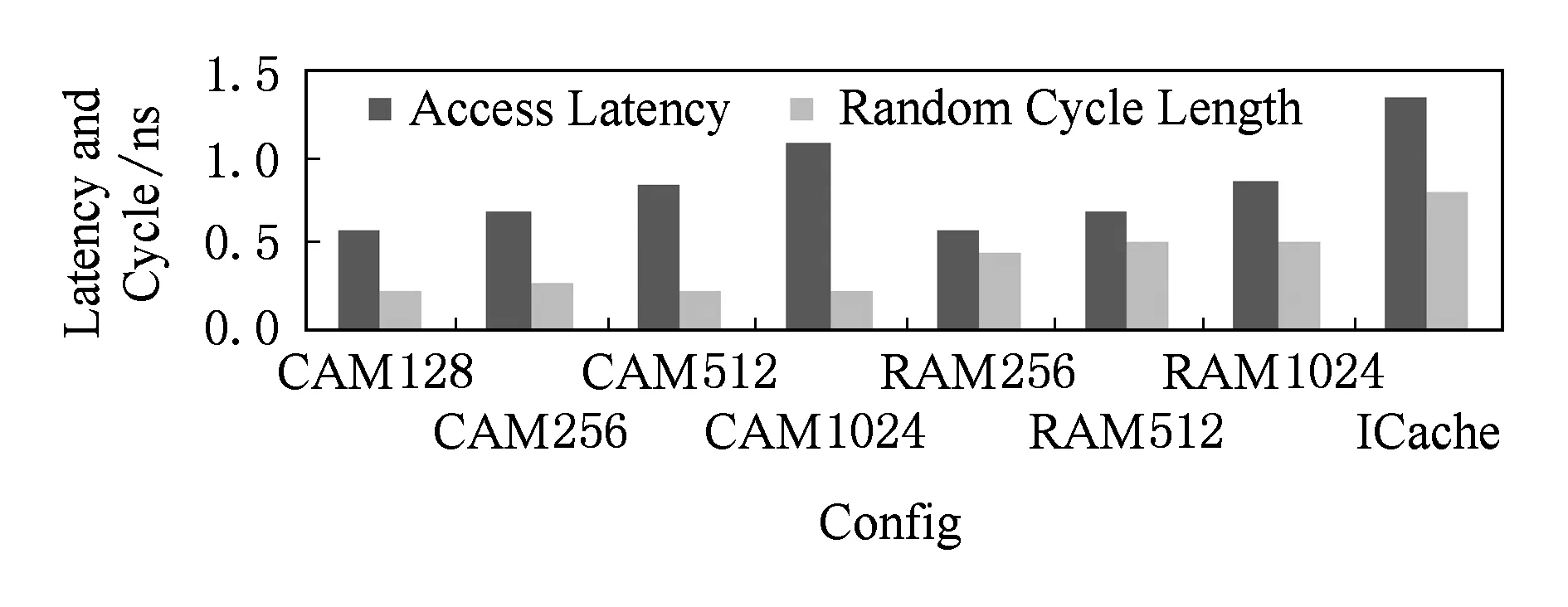
Fig. 7 Latency and cycle of CAM,RAM and ICache.图7 CAM,RAM,ICache的延迟与周期
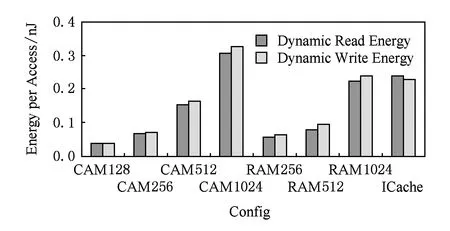
Fig. 8 Energy per access of CAM,RAM and ICache.图8 CAM,RAM,ICache的单次访问功耗
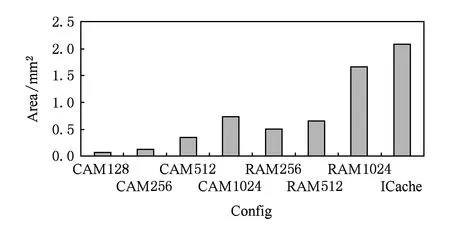
Fig. 9 Area of CAM,RAM and ICache.图9 CAM,RAM,ICache的面积
mega-UB使用CAM实现,其访问延迟、单次读写功耗和面积开销的变化曲线都比较陡峭,说明其可扩展性较差.但CAM256的各项数据仍在可接受的范围内.
main-UB使用RAM实现,它在功耗和面积方面都要大大优于同样容量的ICache,这是因为它使用从mega-UB中获得的RAM地址直接被访问,没有普通Cache的标签阵列(tag array).
从UB中取微指令分2种情况:如果是基本块的首行,首先访问mega-UB,然后从main-UB中取得微指令;否则,利用基本块每行末尾的指针取得后续行的微指令.前者的代价较大,我们称之为最差情况(worst case),而后者为最好情况(best case).
UB的各项指标计算如下:访问延迟为2个组件访问延迟的和(worst case)或main-UB的访问延迟(best case).周期等于mega-UB和main-UB周期较大者(访问mega-UB与访问main-UB流水实现).读写事件动态功耗为2个组件功耗的和(worst case)或main-UB的功耗(best case).面积开销为2个组件面积开销的和.UB各种配置的评估结果如图10~12所示.

Fig. 10 Latency and cycle of UB.图10 UB的延迟与周期
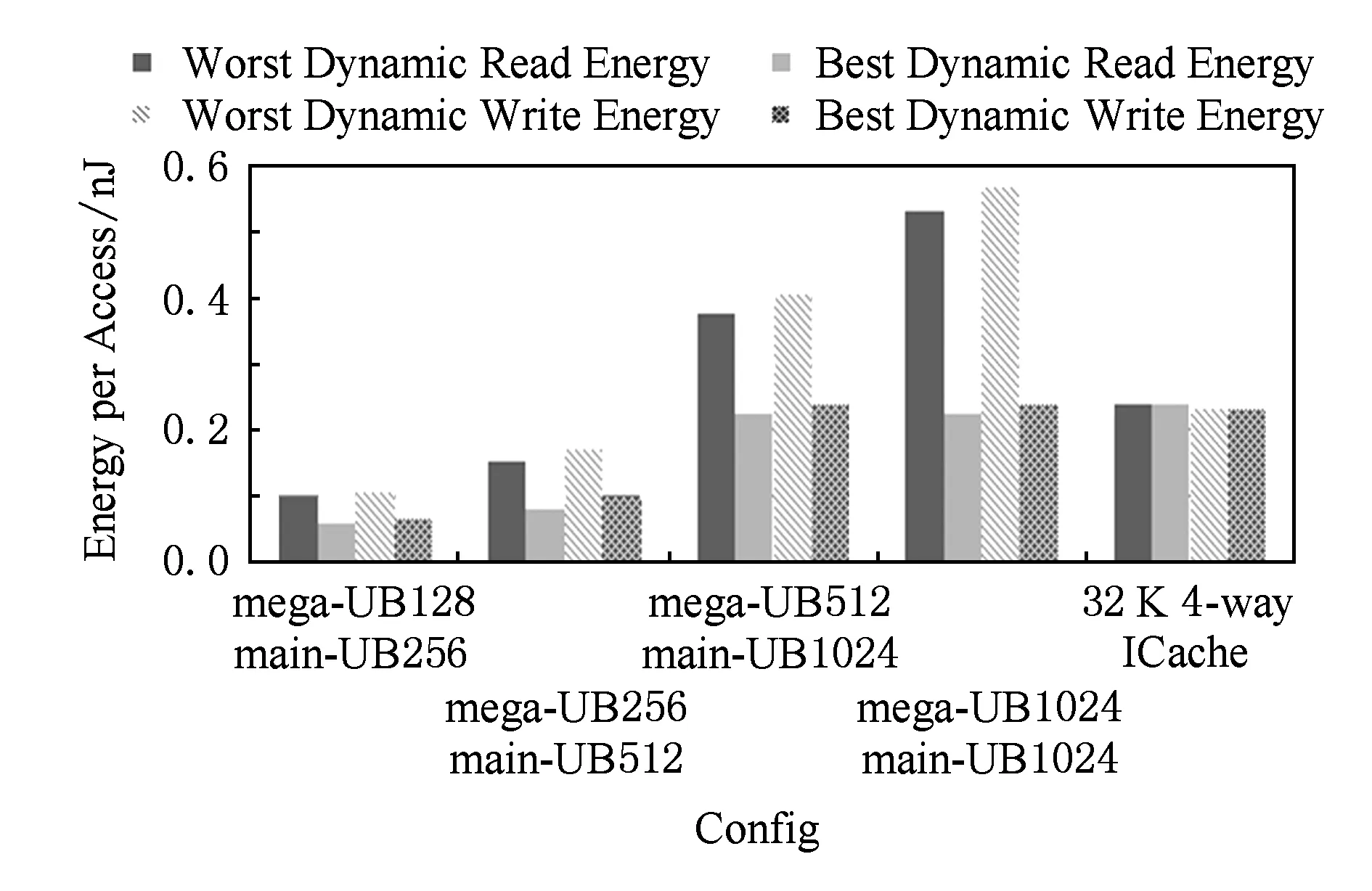
Fig. 11 Energy per access of UB.图11 UB的单次访问功耗
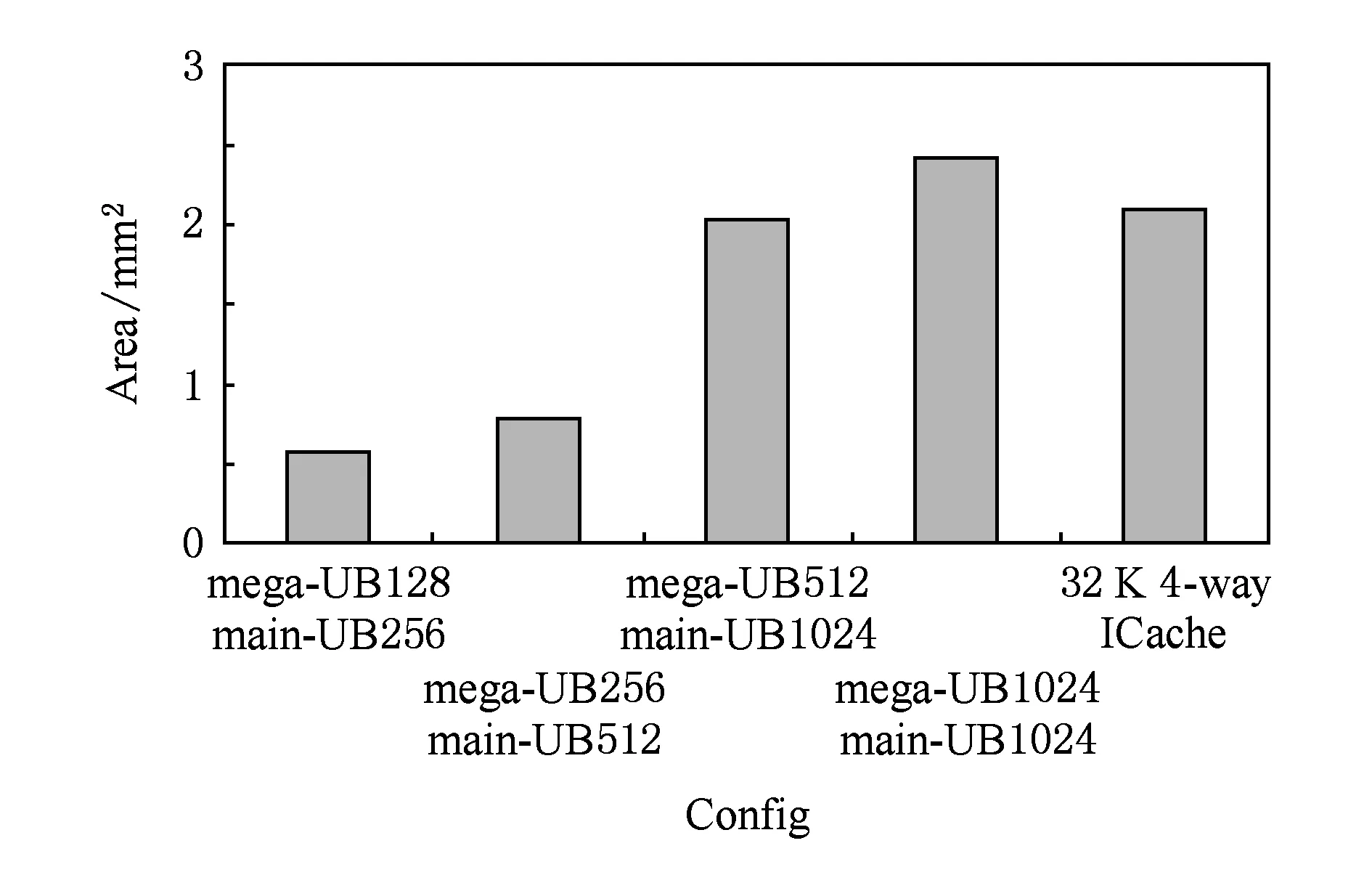
Fig. 12 Area of UB.图12 UB的面积
可以看出,mega-UB256 main-UB512的配置在访问延迟和单次读写功耗以及面积开销方面都要优于同样存储32KB指令数据的4-Way ICache.其功耗开销在最差情况也不大于ICache,而最优情况下只有ICache的一半.面积开销只有ICache的40%.
前面2.1节简单提到,mega-UB与main-UB是松散耦合的,与传统的ICache不同.从该点出发,DF-Cache可以在结构上进行优化进而提高性能.首先,mega-UB和main-UB可以通过地址缓存队列连接,mega-UB负责不断将预测获得的指令基本块首数据行地址放到队列中,而main-UB可以从队列中取得基本块首数据行地址,自由地完成后续的微指令取出操作.其次,main-UB基于RAM实现,其访问延迟和功耗低,可以倍频工作,或者多个读写端口同时访问多个基本块,提高指令供给的宽度.最后,对在存储空间内连续的数个基本块,可以在main-UB中链接起来,使得main-UB有连续跨基本块预取指的能力,而不完全依赖mega-UB.
通过以上分析可以看出,DF-Cache的结构和工作方式与传统的ICache相比,在性能、面积和功耗上都有优势.另外考虑到DF-Cache旁路了译码和重命名阶段,DF-Cache可以降低处理器的动态功耗.在ESESC中集成的mcpat工具里添加DF-Cache和向量重命名部件的延迟、面积和功耗模型,并在ESESC的时序模型中添加必要的性能计数器,即可以实时分析得到添加了DF-Cache的处理器运行特定测试程序时的动态功耗.本文重点在于DF-Cache加入流水线对功能和性能的影响,其具体的功耗优势不再继续展开.本节通过分析说明了,DF-Cache能以可接受的代价实现较高的动态指令覆盖率.
3.2加入数据流缓存对流水线的影响
DF-Cache加入流水线的作用可概括如下:首先它提升了指令供给带宽并降低了指令供给延迟;其次,DF-Cache解耦合了流水线的前后端,DF-Cache负责向后端供应指令,可以解决DMC处理器中V-Core流水线前端能力较弱的问题.本节,我们从上述2个方面分析DF-Cache对流水线的影响.
表3展示了ESESC模拟处理器核的基准配置的全部参数设置,我们记该配置为F4-B128.F4表示流水线宽度为每周期4条指令,B128表示指令窗口容量为128.

Table 3 Base Configuration F4-B128
表4列举了我们选择进行实验的10种处理器核配置.仅与基准配置不同的参数设置在表4中进行了列举,包括流水线宽度、指令窗口大小、功能部件配备和是否搭配有DF-Cache.

Table 4 Selected Configurations in Sample Space
F4-B128,F6-B256,F8-B512模拟的是有不同ILP发掘能力的N-Core,其前端指令供给能力与后端的执行能力匹配较好.F4-B256,F4-B512模拟的是通过DMC技术重构得来的V-Core,因为流水线前端各阶段的融合效果差,它们的指令供给能力要弱于指令执行能力.D4-B128,D4-B256,D4-B512,D6-B256,D8-B512这5个D系列配置,与F系列的配置一一对应,仅额外添加了DF-Cache.要考察前端结构对流水线的影响,我们需要控制非相关变量.因而忽略流水线后端V-Core融合导致的额外开销,操作数传递延迟设置为0.举例说明,F4-B256,D4-B256,F6-B256,D6-B256虽属不同结构,却拥有相同性能的后端.这使得模拟获得的实验数据能够体现出不同前端结构带来的影响,有可比较性.
与Core Fusion等DMC设计的实验类似,我们关注V-Core执行单线程程序发掘ILP的能力,暂时不考虑多道程序和多线程程序在DMC中的执行.我们使用ESESC的TASS采样模式运行了每个测试程序10亿条动态指令,TASS采样设置RWDT各阶段的比例为250:245:2:13.模拟的结果如图13所示.IPC数值已经归一化到F4-B128,方便比较.

Fig. 13 One billion uops simulation result.图13 10亿条动态指令模拟结果
简要分析没有DF-Cache的F系列配置的测试结果反映出的程序与处理器结构的特点.
首先,比较F4-B128,F6-B256,F8-B512这3个N-Core的数据,可以看到大部分的测试程序随着处理器核发掘ILP的能力上升而执行性能有所提升.bzip和libquantum提升较小,说明程序本身蕴含的ILP较有限或者长延时指令较多,对指令窗口大小不敏感.gcc,namd,soplex,povray,h264ref则含有较高的ILP.再对比图6我们可以看到,程序的数据流局部性与指令级并行性之间没有明显的相关关系,计算的这2个特性分别对应了微结构上流水线前端转化指令的能力和流水线后端执行指令的能力.流水线前后端相匹配,且满足程序的2个特性才可以有比较高的执行效率.
其次,分别比较F4-B256和F6-B256,以及F4-B512和F8-B512这2组V-Core对比N-Core的数据.例如gcc,milc,namd,povray等测试程序,可以明显看到DMC重构得到的V-Core因为其前端相对较弱,影响到了流水线对这些程序的执行效果.占用相同资源的N-Core性能强于重构得来的V-Core.
3.2.1数据流缓存对流水线性能影响
DF-Cache将前端的译码和重命名信息进行缓存,当指令基本块在其中命中时,通过向量重命名后,可以快速填充到后端发射队列中.所以DF-Cache可以提升前端带宽、降低前端延迟.但是,传统的处理器取指、译码和重命名等功能已经流水化实现,并且分支预测部件的正确率都很高,DF-Cache能发挥多少作用值得商榷,本节通过对比D系列N-Core相对F系列N-Core的测试数据来研究DF-Cache的加入对流水线性能的影响.
拥有不同ILP发掘能力的N-Core在有或无DF-Cache的情况下的执行性能对比如图14所示:

Fig. 14 The influence of DF-Cache on the pipeline of N-Core.图14 DF-Cache对N-Core流水线性能影响
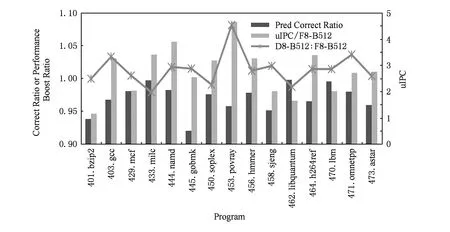
Fig. 15 Performance data of D8-B512 and F8-B512.图15 D8-B512与F8-B512的性能数据
1) DF-Cache提升了部分程序的性能,例如gcc,gobmk,povray,sjeng,h264ref,omnetpp.同时参照图6和图13可以得出,这些程序能够被DF-Cache加速存在3个因素:①程序本身要含有足够的ILP.DF-Cache提高指令供给,从而使得后端的计算能力得到更好的利用.而bzip2与libquantum因为程序自身或处理器后端能力原因导致ILP较低,所以DF-Cache对其提升有限.②这些程序的数据流局部性较差.与直觉相反,DF-Cache覆盖率较低的程序反而受到的DF-Cache加速效果更好,这是因为这些程序局部性较差,从而指令供给能力提升的空间也大.③程序的分支预测准确率也影响DF-Cache的效果.
2) mcf,milc,soplex,libquantum,astar的部分测试结果要比没有DF-Cache的情况更差.这主要有2个原因:①如上段所述,数据流局部性好的程序前端带宽提升的空间非常有限,前后端匹配的流水线已经能非常好地利用后端的计算资源,DF-Cache的加入能提供的正面效果较弱.②通过分析程序的执行过程,我们发现发射队列的快速填充导致了不在关键路径上的指令抢占了属于关键路径上的指令的执行时机,我们称这种降低程序执行效率的现象为关键路径遮挡.如果指令调度器实现了优先关键路径指令的调度算法,该问题即可解决.
图15重点展示了D8-B512和F8-B512的性能对比数据和F8-B512执行的ILP绝对数值以及分支预测准确率.可以看到DF-Cache对流水线的加速效果与程序的ILP呈较明显的正相关关系,而与程序的分支预测正确率呈较明显的反相关关系.举例说明,povray程序有高的ILP而分支预测准确率低,其受到DF-Cache加速效果最明显,达到8.1%;bzip2虽然有低的分支预测准确率,但其ILP有限,DF-Cache基本没有加速其执行;libquantum的分支预测准确率高但ILP低,DF-Cache的加入反而影响其执行,原因见上段的2点.所有程序中,soplex与astar属于偏离上述相关关系的测试程序,经过对它们执行过程的详细分析其性能表现与关键路径遮挡现象有关,指令调度策略属于流水线的后端执行能力研究的范围,与前端指令供给不相关,在此不再做展开.
总而言之,带有DF-Cache的处理器前端,能够更有效地发掘计算的数据流局部性、增强流水线的指令转化能力.1)它提升指令供给带宽,增强处理器发掘ILP的能力;2)它缩短指令供给延迟,降低了分支预测错误带来的惩罚.
3.2.2数据流缓存解耦合流水线前后端
由3.2节开始对F系列的V-Core和N-Core数据的对比可知,V-Core前端能力较弱影响其性能.这是目前大部分DMC技术需要解决的问题.
首先,我们对比D系列的V-Core与F系列的V-Core的性能数据,分析研究DF-Cache加入流水线后解耦合前后端的作用与效果.如图16所示,除了bzip2,libquantum等ILP较差的程序外,V-Core运行的所有程序在DF-Cache的帮助下,IPC都有很大提升.D4-B256相对于F4-B256性能平均提升了5.5%,D4-B512相对于F4-B512性能平均提升了9.4%,尤其是povray性能高达28%,这说明DF-Cache为后端提供了更多的动态指令,能够较大提升流水线性能.
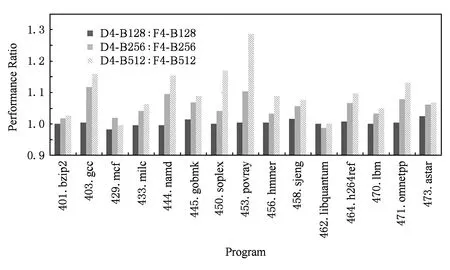
Fig. 16 The influence of DF-Cache on the pipeline of V-Core.图16 DF-Cache对V-Core流水线性能影响
然后,我们对比具有基本相同硬件开销的集成了DF-Cache的V-Core与没有集成DF-Cache的N-Core的数据.参照图13,可以看出D4-B256和F6-B256,以及D4-B512和F8-B512性能差距较小,平均性能差距小于5%.
而Core Fusion等DMC设计其合并后的V-Core性能要大大弱于同宽度的N-Core*例如Core Fusion的8发射V-Core在运行SPEC整型程序时性能只达到6发射N-Core的76%,当然Core Fusion全面建模了后端,我们对V-Core后端的估计相对乐观..这说明V-Core流水线后端的指令执行能力在DF-Cache的帮助下得到了充分利用.
通过上面2段对DF-Cache加入流水线后性能下限和上限的分析,我们可以看到V-Core不再受限于能力失配的前端,性能更接近其后端的指令执行能力.DMC技术在DF-Cache的帮助下有更高的实用价值.
4结束语
数据流缓存尝试发掘程序的数据流局部性.通过缓存并重用指令基本块内的数据流信息,数据流缓存可以旁路取指、译码和重命名等流水线前端阶段,解耦合流水线的指令供给和指令执行功能.
通过分析程序的数据流局部性,我们证明了数据流缓存能够以有限的代价覆盖90%以上的动态指令.在流水线宽度为4条指令、指令窗口大小为512条指令的虚拟核的配置下,采用数据流缓存提升了SPEC CPU2006平均9.4%的执行性能.
数据流缓存能够缩短指令供给延迟,提高指令供给带宽,降低分支预测错误带来的惩罚,通过解放后端来增强处理器核发掘ILP的能力.另外,数据流缓存替代流水线前端供给指令,解决动态多核技术中虚拟核的前端难以协作工作的问题,提升了动态多核技术中虚拟核的性能,增强动态多核技术的实用性.
参考文献
[1]Agarwal V, Hrishikesh M S, Keckler S W, et al. Clock rate versus IPC: The end of the road for conventional microarchitectures[C] //Proc of the 27th Int Symp on Computer Architecture. New York: ACM, 2000: 248-259
[2]Borkar S, Dubey P, Kahn K, et al. Platform 2015: Intel processor and platform evolution for the next decade[J/OL].[2015-03-04]. http://www.researchgate.net/publication/247190040
[3]Hill M D, Marty M R. Amdahl’s law in the multicore era[J]. Computer, 2008, 41(7): 33-38
[4]Hennessy J, Patterson D. Computer Architecture: A Quantitative Approach[M]. San Francisco, CA: Morgan Kaufmann, 2011
[5]Lee L H, Moyer B, Arends J. Instruction fetch energy reduction using loop caches for embedded applications with small tight loops[C] //Proc of the 1999 Int Symp on Low Power Electronics and Design. New York: ACM, 1999: 267-269
[6]Singhal R. Inside Intel next generation Nehalem microarchitecture[C/OL] //Proc of the 20th Symp of Hot Chips. [2015-03-04]. http://www.cs.uml.edu/~bill/cs515/Intel_Nehalem_Processor.pdf
[7]Rotenberg E, Bennett S, Smith J E. Trace cache: A low latency approach to high bandwidth instruction fetching[C] //Proc of the 29th Int Symp on Microarchitecture. Los Alamitos, CA: IEEE Computer Society, 1996: 24-35
[8]Lempel O. 2nd generation Intel core processor family: Intel core i7, i5 and i3[C/OL] //Proc of the 23rd Symp of Hot Chips. [2015-03-04]. http://www.hotchips.org/wp-content/uploads/hc_archives/hc23/HC23.19.9-Desktop-CPUs/HC23.19.911-Sandy-Bridge-Lempel-Intel-Rev 07.pdf
[9]Black B, Rychlik B, Shen J P. The block-based trace cache[C] //Proc of the 26th Int Symp on Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 1999: 196-207
[10]Swanson S, Schwerin A, Mercaldi M, et al. The WaveScalar architecture[J]. ACM Trans on Computer Systems, 2007, 25(2): article 4
[11]Oberoi P S, Sohi G S. Parallelism in the front-end[C] //Proc of the 30th Int Symp on Computer Architecture. New York: ACM, 2003: 230-240
[12]Ipek E, Kirman M, Kirman N, et al. Core fusion: Accommodating software diversity in chip multiprocessors[C] //Proc of the 34th Int Symp on Computer Architecture. New York: ACM, 2007: 186-197
[13]Kim C, Sethumadhavan S, Govindan M S, et al. Composable lightweight processors[C] //Proc of the 40th Int Symp on Microarchitecture. Los Alamitos, CA: IEEE Computer Society, 2007: 381-394
[14]Watanabe Y, Davis J D, Wood D A. WiDGET: Wisconsin decoupled grid execution tiles[C] //Proc of the 37th Int Symp on Computer Architecture. New York: ACM, 2010: 2-13
[15]Rodrigues R, Annamalai A, Koren I, et al. Performance per Watt benefits of dynamic core morphing in asymmetric multicores[C] //Proc of Int Conf on Parallel Architectures and Compilation Techniques. Los Alamitos, CA: IEEE Computer Society, 2011: 121-130
[16]Yeager K C. The MIPS R10000 superscalar microprocessor[J]. IEEE Micro, 1996, 16(2): 28-40
[17]Raasch S E, Binkert N L, Reinhardt S K. A scalable instruction queue design using dependence chains[C] //Proc of the 29th Int Symp on Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2002: 318-329
[18]Gibson D, Wood D. ForwardFlow: A scalable core for power-constrained CMPs[C] //Proc of the 37th Int Symp on Computer Architecture. New York: ACM, 2010: 14-25
[19]Sohi G S, Vajapeyam S. Instruction issue logic for high-performance, interruptible pipelined computers[C] //Proc of the 14th Int Symp on Computer Architecture. New York: ACM, 1987: 27-34
[20]Kim I, Lipasti M H. Half-price architecture[C] //Proc of the 30th Int Symp on Computer Architecture. New York: ACM, 2003: 28-38
[21]Henning J L. SPEC CPU2006 benchmark descriptions[J]. ACM SIGARCH Computer Architecture News, 2006, 34(4): 1-17
[22]Ardestani E K, Renau J. ESESC: A fast multicore simulator using time-based sampling[C] //Proc of the 19th IEEE Int Symp on High Performance Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2013: 448-459

Liu Bingtao, born in 1983. PhD candidate. Student member of China Computer Federation. His main research interests include processor microarchitecture, recon-figurable computing and heterogeneous computing.

Wang Da, born in 1981. PhD, associate professor. Member of China Computer Federation. Her main research interests include IC testing and analysis, micro architecture design, many-core processor, and VLSI design and testing.

Ye Xiaochun, born in 1981. PhD, associate professor. Member of China Computer Federation. His main research interests include high-performance computer archi-tecture, software simulation, algorithm paralleling and optimizing.

Zhang Hao, born in 1981. PhD, associate professor. Member of China Computer Federation. Associate chief architect of the Godson-T many core processor. His research interests include high throughput CPU microarchitectures and application analysis.

Fan Dongrui, born in 1979. PhD, professor and PhD supervisor. Member of China Computer Federation. His main research interests include many-core processor design, high throughput processor design and low power micro-architecture.

Zhang Zhimin, born in 1963. Professor and PhD supervisor. His main research interests include SoC design and computer architecture.
A Dataflow Cache Processor Frontend Design
Liu Bingtao1,2, Wang Da1, Ye Xiaochun1, Zhang Hao1, Fan Dongrui1, and Zhang Zhimin1
1(InstituteofComputingTechnology,ChineseAcademyofSciences,Beijing100190)2(UniversityofChineseAcademyofSciences,Beijing100049)
AbstractIn order to exploit both thread-level parallelism (TLP) and instruction-level parallelism (ILP) of programs, dynamic multi-core technique can reconfigure multiple small cores to a more powerful virtual core. Usually a virtual core is weaker than a native core with equivalent chip resource. One important reason is that the fetch, decode and rename frontend stages are hard to cooperate after reconfiguration because of their serialized processing nature. To solve this problem, we propose a new frontend design called the dataflow cache with a corresponding vector renaming (VR) mechanism. By caching and reusing the data dependencies and other information of the instruction basicblock, the dataflow cache exploits the dataflow locality of programs. Firstly, the processor core can exploit better instruction-level parallelism and lower branch misprediction penalty with dataflow cache; Secondly, the virtual core in dynamic multi-core can solve its frontend problem by using dataflow cache to bypass the traditional frontend stages. By experimenting on the SPEC CPU2006 programs, we prove that dataflow cache can cover 90% of the dynamic instructions with limited cost. Then, we analyze the performance effect of adding the dataflow cache to pipeline. At last, experiments show that with a frontend of 4-instruction wide and an instruction window of 512-entry, the performance of the virtual core with dataflow cache is improved up to 9.4% in average with a 28% maximum for some programs.
Key wordsprocessor microarchitecture; instruction cache (ICache); dataflow; instruction renaming; dataflow locality
收稿日期:2015-04-23;修回日期:2015-07-14
基金项目:国家“九七三”重点基础研究发展计划基金项目(2011CB302501);国家“八六三”高技术研究发展计划基金项目(2015AA011204,2012AA010901);“核高基”国家科技重大专项基金项目(2013ZX0102-8001-001-001);国家自然科学基金重点项目(61332009,61173007)
中图法分类号TP303
This work was supported by the National Basic Research Program of China (973 Program) (2011CB302501), the National High Technology Research and Development Program of China (863 Program) (2015AA011204,2012AA010901), the National Science and Technology Major Projects of Hegaoji (2013ZX0102-8001-001-001), and the Key Program of the National Natural Science Foundation of China (61332009,61173007).
猜你喜欢
商丘师范学院学报(2021年9期)2021-08-16
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
制造技术与机床(2018年10期)2018-10-13
中南大学学报(自然科学版)(2018年7期)2018-08-08
自动化学报(2018年6期)2018-07-23
计算机技术与发展(2018年1期)2018-01-23
铁道通信信号(2016年2期)2016-06-01
西北工业大学学报(2015年3期)2015-12-14
中国卫生(2014年7期)2014-11-10
