
天然异龄林资产评估收益现值法中择伐周期的改进
2016-09-13 02:41林进添
西南林业大学学报 2016年1期
林进添
(1.福建江夏学院会计学院,福建 福州 350108;2.福建省社科研究基地财务与会计研究中心,福建 福州 350108)
天然异龄林资产评估收益现值法中择伐周期的改进
林进添1,2
(1.福建江夏学院会计学院,福建 福州 350108;2.福建省社科研究基地财务与会计研究中心,福建 福州 350108)
通过分析天然异龄林林分平均生长率可拓聚类预测的建模机制,构建出可拓聚类预测的物元模型,并利用该模型对林分平均生长率进行预测。结果表明:该方法预测精度较高,用于天然异龄林林分生长率的确定是可行的。天然异龄林资产评估的收益现值法应用中,运用该可拓聚类预测法的生长率结果来确定择伐周期指标,可进一步改进完善收益现值法。
天然异龄林;可拓聚类预测;林分生长率;择伐周期
择伐周期是天然异龄林资产评估收益现值法公式中的主要指标之一。择伐周期的长短受择伐强度和伐后林分平均生长率的影响,与择伐强度成正比,与林木生长速度成反比;择伐强度和生长率则由树种组成、经营水平和立地条件等因素所决定。在理论公式中,蓄积量法确定择伐周期时,林分平均生长率估测准确与否是关键。现行林业实践中,择伐周期仅仅只能通过利用调查的少数资料求出一个大致的平均生长率来测算。而在资产评估操作中,由于基础调查资料的缺乏,更多的是参考同龄林林分生长水平结合行业专家经验直接给定择伐周期,这就肯定存在着估值偏差。因此,如何求取客观准确的林分平均生长率以确定合理的择伐周期,是天然异龄林收益现值法评估质量好坏的关键之一,是最重要、也是较难解决的一个方面。
天然异龄林林分生长是一个多因素、多条件综合作用和互相影响的过程,其年生长量不可能是均匀的,即年生长率不可能保持不变。在天然异龄林资产评估中,以恒定的年均生长率来确定择伐周期指标,进而采用收益现值法来测算林分价值,这是不合乎生长实际的。建立林分生长率——蓄积量水平的传统数学模型,动态求取天然异龄林伐后各年林分生长率[1-2],具有一定的创新性;但由于模型拟合的样地数量少,使得模型预测精度受到限制。本研究引入可拓聚类分类预测法,该法所需建模样本少,且预测过程和技术能一定程度上体现林分恢复生长的随机性和模糊性,又能以较高精度预测林分平均生长率,对天然异龄林收益现值法评估中择伐周期指标的确定具有重要意义。
1 可拓聚类预测物元模型
可拓聚类预测是将可拓物元理论和聚类分析相结合,根据已知数据预测未知数据的一种方法。在考虑影响因素的基础上,通过对已知数据的提炼分类,构建已知物元模型的经典域和节域,根据关联函数确定待测物元对各经典域的隶属程度,以确定待测物元变化率的类别,从而得到预测结果[3]。可拓聚类预测物元模型的原理与方法是[4-6]:
设Ii(i=1,2,……,m)是可拓集P的m个分类别(子集),Ii⊂P(i=1,2,……,m)。对任何待测对象p∈P,用以下步骤判断p属于哪个类别,并计算p属于每一类别Ii的关联度。
1.1确定经典域和节域

(1)

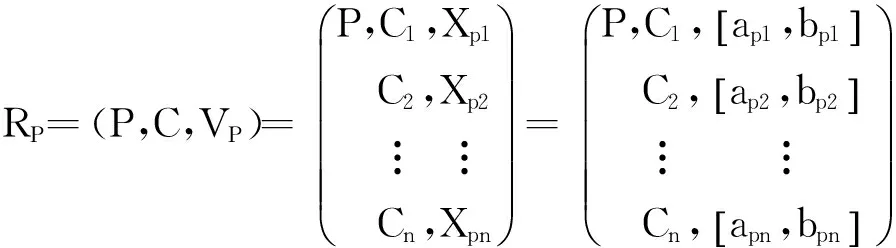
(2)
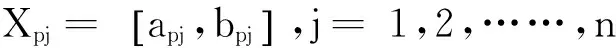
1.2确定待测样本物元
待测样本物元表示为Rx:
(3)
其中:x1,x2,……,xn分别为待测样本的n个特征的观测值。
1.3确定关联函数值
根据距的定义,确定关联函数值。待测样本各因子与各类的关联程度按下式计算:
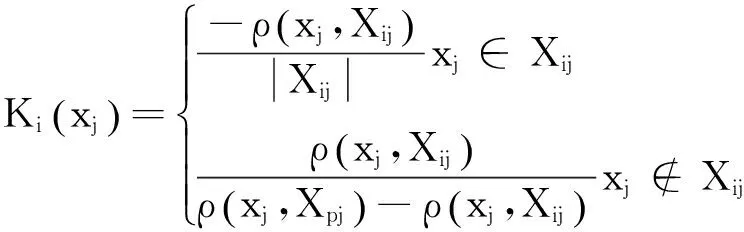
(4)
其中:
(5)
(6)
1.4确定权系数并计算待测样本与各类的隶属程度
权系数的确定方法可根据实际情况的需要采用专家评价法层、次分析法、比重权数法等。设ωij为第i类第j个特征的权重,则待测样本p对Ii类的隶属程度为:
(7)
1.5判定待测样本所属类别

2 可拓聚类预测模型要素与建模机制
可拓聚类预测模型结合可拓集合理论和聚类分析,利用关联函数建立起一套识别和评价方法来进行预测。根据事物关于特征的量值来判断事物隶属于某集合的程度与可拓集合的基本思想是一致的。可拓聚类预测模型已经用于多个领域的预测研究,表明该预测方法建模简单,所需样本数据量少,预测精度较高[7-11]。林分生长率的大小与许多因素有关,既有林分自身条件的影响,又有环境因素的影响,但最终都放映到生长量上。该量值与初始蓄积水平共同决定了林分生长率的大小。因此,只要能挖掘出林分生长率关于生长量和初始蓄积水平的内在联系机理,在确定天然异龄林择伐周期时,就可以依据择伐掉的蓄积量(即恢复至伐前蓄积水平的生长量)和伐后蓄积(即初始蓄积)来计算林分平均生长率。这样就避免了建立线性数学模型需要大量数据样本的弊端。
首先要对天然异龄林林分生长率的主要影响因素初始蓄积和生长量的调查数据进行样本提炼分类,将林分生长率与其2个主要影响因素的数据样本分成若干个典型类别;再构建相应的经典域和节域,构建起利用物元和节域物元来描述各类别初始蓄积和生长量的特征与林分生长率的变化模式,进而建立待估样本与各类别之间的关联度和各个影响因素的权系数;最后通过待估样本的择伐蓄积量和伐后蓄积量来判定林分平均生长率属于的类别,从而预测出平均林分生长率的变化范围得到预测结果。
3 林分年生长率的可拓聚类预测
3.1建模数据样本与预处理
收集到福建省最近连续2期的森林资源连续清查天然异龄林样地51块,均为阔叶林和阔叶混交林。计算2期间的总生长量和年均生长率,结果见表1。其中,1~45号样地作为可拓聚类预测建模的基础数据样本,46~51号样地作为模型的检验样本。

表1 林分平均生长率与评价特征指标值
3.2数据提炼与分类
根据表1里的建模数据样本可知道,年均生长率为0.40%~15.73%,为了能较为准确地预测林分平均生长率,不妨依据该年均生长率范围等距划分为5个等级(类别),每个等级的年均生长率范围分别为:
I1=[p1min,p1max]=[0.40,3.47]
I2=[p2min,p2max]=[3.48,6.53]
I3=[p3min,p3max]=[6.54,9.60]
I4=[p4min,p4max]=[9.61,12.66]
I5=[p5min,p5max]=[12.67,15.73]
3.3确定经典域物元和节域物元
依据上述5个年均生长率等级类别将表1的建模数据样本归入各个类别中,具体分布情况见表2。

表2 建模数据样本的所属类别
因此,可以构造出5个经典域物元:
其中:C1和C2分别表示评价特征初始蓄积和生长量。
则节域物元为:
有待测物元,即检验样本物元为:
3.4确定每个特征的权系数[3]
确定权重的方法有很多种,但考虑到年均生长率是一个相对统计量,难以衡量初始蓄积量和生长量对它的贡献,因此采用比重权数法确定权系数。所谓比重权数,是根据某指标在所有被评价对象上的观测值比重差异来确定的一种数量权数,它用该指标的比重差异信息来衡量其重要性的大小。即对于每一个要进行判别的类来说,待测样本每个因子的权系数由其与相对应特征的经典域最大值的比值占这一类中各因子与其对应特征值经典域最大值的比值之和的比例确定,即:
(8)
式中:ωij为某待测样本在第i个分类中第j个评价特征的权系数;xj为某待测样本第j个评价特征指标值;bij为第i个分类中第j个评价特征的经典域最大值。
根据式(8)可求得6个待测物元在各个等级分类中每个评价特征的权系数,结果见表3。
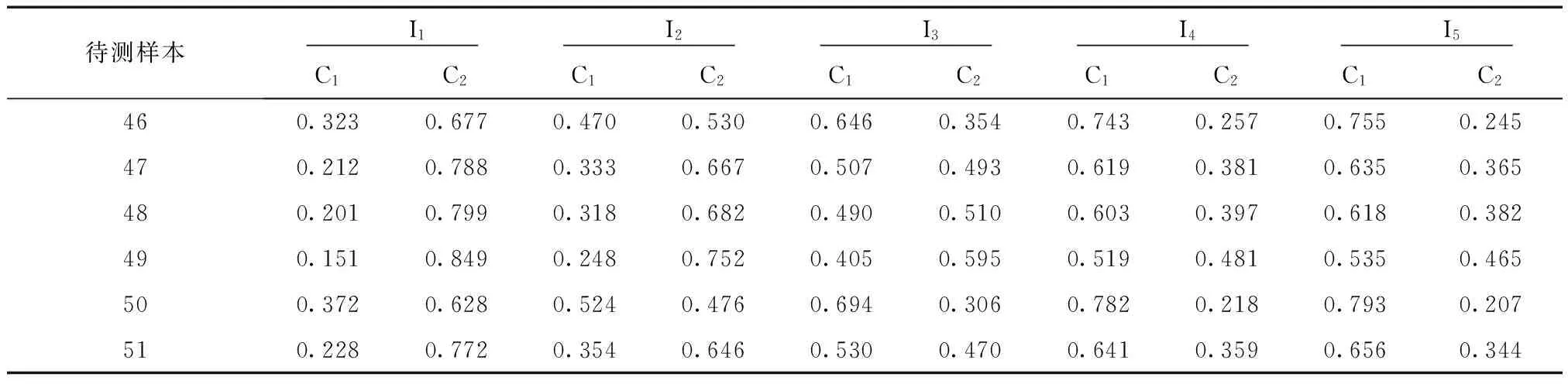
表3 待测物元评价特征的权系数
3.5计算待测样本的关联度和类别判定
根据公式(4)、(5)、(6)、(7)可以求得各待测物元关于各个分类等级的综合关联度,结果见表4。显然K2(R46)、K3(R47)、K3(R48)、K4(R49)、K2(R50)、K3(R51)分别为各待测样本在各个类别中的最大值(表中标“*”的数值)。因此,待测样本46和50的年均生长率属于I2类,即在区间[3.48,6.53]内;待测样本47、48和51的年均生长率属于I3类,即在区间[6.54,9.60]内;待测样本49的年均生长率属于I4类,即在区间[9.61,12.66]内。
表4待测物元关于各分类的综合关联度
Tab.4Comprehensive correlation degree of matter elements under each category
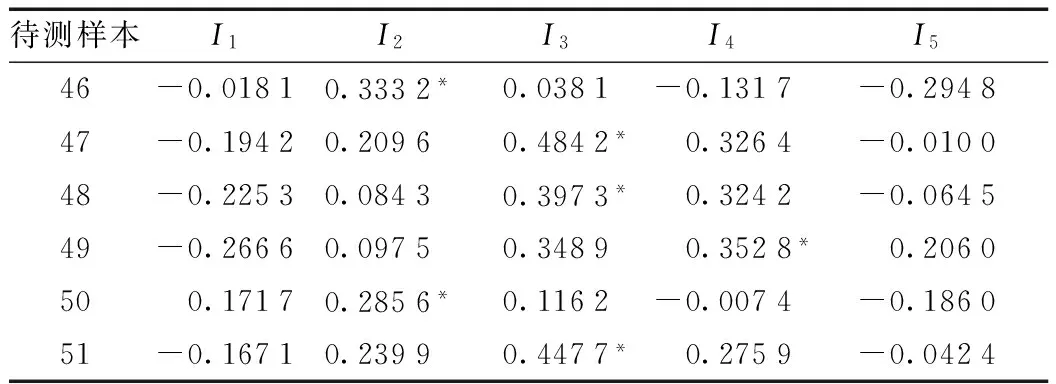
待测样本I1I2I3I4I546-0.01810.3332*0.0381-0.1317-0.294847-0.19420.20960.4842*0.3264-0.010048-0.22530.08430.3973*0.3242-0.064549-0.26660.09750.34890.3528*0.2060500.17170.2856*0.1162-0.0074-0.186051-0.16710.23990.4477*0.2759-0.0424
3.6年均生长率预测
通过可拓聚类预测得到了各待测样本可能的年均生长率区间。但是评估操作确定择伐周期需要一个确定的年均生长率值而不是一个区间。因此,可以根据关联度的内涵意义,用以下公式对待测样本的年均生长率作出预测:
(9)
式中:px为待测样本的预测年均生长率值;Ki(Rx)为待测样本属于第i类的最大关联度值;pimin为第i类年均生长率的下限值;pimax为第i类年均生长率的上限值。
因此,可以预测出各待测样本年均生长率:
p46=0.3332×6.53+(1-0.3332)×3.48=4.50
p47=0.4842×9.60+(1-0.4842)×6.54=8.02
p48=0.3973×9.60+(1-0.3973)×6.54=7.76
p49=0.3528×12.66+(1-0.3528)×9.61=10.69
p50=0.2856×6.53+(1-0.2856)×3.48=4.35
p51=0.4477×9.60+(1-0.4477)×6.54=7.91
理论上如果类别分的越多,即把年均生长率各类别的区间划分的越窄,那么计算预测的年均生长率也就越精确。但是如果分类过多,会导致计算量非常庞大。因此,为了能提升预测精度,可以先适当划分为4~6个类别区间,待第1次可拓聚类预测结果判定出所属类别后,再以该类别所属的建模样本二次划分类别,进行二次可拓聚类预测。这样相当于先缩小到一定范围再行预测,既能避免大量计算工作又可以提升预测精度。
3.7预测结果检验
上述6个待测样本实际上是用来检验可拓聚类预测模型用的。把该6个样地的实际年均生长率与通过可拓聚类预测模型第1轮预测、2轮预测的年均生长率作卡方检验,见表5。

表5 可拓聚类预测结果的检验比较

第2轮预测中样地50的预测结果缺省,这是因为第2轮预测时建模样本量会少很多,致使样地50不在研究域内,其关于各类别的综合关联度均小于0。说明不是一定要进行多轮预测,只有数据样本量足够才有进行多轮预测的基础,否则不但不会提升预测精度,还使得计算工作量大大增加。鉴于上述检验效果,一般只需要进行一轮的可拓聚类预测就能满足精度要求,是否需要再行第2轮可拓聚类预测需根据建模数据样本的容量、样本数值区间和数据的平滑度以及第一轮类别划分的细致程度加以综合判定,最多只进行2轮可拓聚类预测即可。
4 择伐周期确定的改进
资产评估中可根据天然异龄林的蓄积水平和择伐强度,利用可拓聚类预测模型和方法逐年求得林分生长率,进而判断择伐周期。其原理如下:
假设待估林分单位面积蓄积量为M,择伐强度为S,那么择伐后林分单位面积蓄积量为M0=M(1-S),也就是初始蓄积量为M0;林分要恢复至伐前水平,则生长量为择伐掉的蓄积量,即MS。
利用上述可拓聚类预测技术模型,根据初始蓄积量为M0、生长量MS,即可得到该林分择伐后第1年的林分生长率,记为p1,则林分第1年末蓄积量为:M1=M0×(1+p1)。
林分进入第2年恢复生长期的期初,其初始蓄积量为第1年末蓄积量M1,要恢复至伐前水平则生长量为M-M1,通过可拓聚类预测可得第2年的林分生长率为p2,则林分第2年末蓄积量为:M2=M1×(1+p2)=M0×(1+p1)×(1+p2)。
同理第U年初,其初始蓄积量为第U-1年末蓄积量MU-1,要恢复至伐前水平则生长量为M-MU-1,通过可拓聚类预测可得第U年的林分生长率为pU,则林分第U年末蓄积量为:MU=MU-1×(1+pU)=M0×(1+p1)×(1+p2)×……×(1+pU-1)×(1+pU)

如沿用上文样地数据资料及构建好的物元模型,表6即列示了利用可拓聚类动态预测不同蓄积量水平的待估林分小班在不同择伐强度下的择伐周期,并计算了动态生长率的均值。其中,240 ~ 260m3/hm2水平、35%择伐强度下的结果值缺省,是由于该蓄积量水平按35%强度择伐时的生长量指标超出了上文建模样本的量值范围,无法进行有效的动态预测。

表6 不同择伐强度下的平均动态生长率和择伐周期
在资产评估实务中,该择伐周期的推导全过程仍相对较为复杂,先是要利用样地数据资料构建物元模型,然后根据待估小班林分蓄积量水平和择伐强度指标,利用可拓聚类预测法逐年预测林分生长率,最终确定生长恢复周期即择伐周期。因此,为了方便日常评估操作,可利用计算机程序语言把择伐周期确定的全新思路编译出来,编制出类似于表6的天然异龄林二元择伐周期速查表。天然异龄林收益现值法评估需要确定待估案例的择伐周期时,就可以依据待估案例的单位面积蓄积量水平和择伐强度从该表中迅速查得择伐周期。如某待估小班蓄积量水平为190m3/hm2,择伐强度确定为35%,根据二元择伐周期速查表,该待估小班蓄积量水平介于180~200m3/hm2,在35%的择伐强度下,则择伐周期在12~13a,评估测算时基于谨慎原则可取择伐周期13a。这与传统实务中需要确定林分生长率再来估测择伐周期亦或直接给定择伐周期相比,更加准确和方便,因为待估对象的单位面积蓄积量水平和择伐强度是很好确定的。这就在一定程度上对天然异龄林资产评估收益现值法的应用进行了改进。
5 结 语
利用可拓聚类预测模型来预测林分年均生长率是可行的。可拓学的物元理论可以把多个变量因素综合起来作为一个物元进行分析,使结合多个变量因素进行预测成为可能。如果把不同条件下年均生长率的变化作为一个物元进行分析,就可以用聚类预测方法进行预测。可拓聚类动态预测法所需样地数量不多,只要建模数据样本有一定的跨度,数据分布均匀、连续性好,一般就能满足评估操作需要,既克服了传统数学线性建模对数据量要求苛刻的弊端,又考虑了林分生长过程中存在着的随机性和模糊性。
天然异龄林资产评估的收益现值法应用中,若基于可拓聚类预测动态生长率来确定择伐周期指标,更加符合林分生长实际,避免了计算林分平均生长率的困难,进一步改进完善了收益现值法。但可拓聚类动态预测方法无法形成一个成型的计算公式,它是一个集成的复合计算系统,为评估实务需要可以利用计算机语言编程集成;此外,考虑到林业调查数据的区域适用性,需要在一定区域范围内建立一套具有一定跨度、分布均匀的建模数据样本库。该建模数据样本最好能是各层次蓄积水平林分伐后恢复的长期监测数据。
[1]林进添,李冬梅,陈平留.利用生长率确定天然异龄林择伐周期的探讨[J].林业勘察设计,2009 (2):4-8.
[2]李冬梅.天然异龄林资产评估研究[D].福州:福建农林大学,2009:44-49.[3]黄大富,任竞争,江寒梅,等.用可拓聚类模型预测天然气的需求[J].计算机与应用化学,2011,28(5):617-619.
[4]沈家骅.集装箱生成量可拓聚类预测[J].上海海运学院学报,2002,23(2):63-65.
[5]沈航,邹平.可拓聚类预测方法预测卷烟销售量[J].昆明理工大学学报,2006,31(3):95-98.
[6]高洁.可拓聚类预测方法及其在邮电业务总量预测中的应用[J].系统工程,2000,18(3):73-77.
[7]蔡国梁,姜殿玉,李日华.可拓事件、可拓概率及其在预测学上的应用[J].江苏理工大学学报(自然科学版),1999,20(4):90-94.
[8]欧伟为.厦门港基于可拓聚类的集装箱生成量预测模型[J].中国水运,2009,9(11):47-48.
[9]刘耀彬,朱淑芬.基于可拓物元—马尔科夫模型的省域生态环境质量动态评价与预测:以江西省为例[J].中国农业生态学报,2009,17(2):364-368.
[10]董德毅,陈爱斌,杨勇.基于可拓学及模糊聚类分析的空气污染预测[J].信息技术,2009 (6):21-24.
[11]王维民.停车需求预测结果评价中的可拓层次分析[J].黑龙江交通科技,2010 (7):221-222,224.
(责任编辑张坤)
Methodology Development of Selective Cutting Cycle of IncomeApproachofNaturalUneven-AgedForestResourceEvaluation
Lin Jintian1,2
( 1.College of Accountancy,Fujian Jiangxia University,Fuzhou Fujian 350108,Chian;2.FujianCenterforFinanceandAccountingResearch,SocialScienceReseanhBaseofFujianProvince,FuzhouFujian350108,China)
Inthisthesis,mode-buildingmechanismofextensionclassifiedpredictionwasanalyzedfornaturaluneven-agedstands′averagegrowthrate,andtheelementmodeofextensionclassifiedpredictionwasbuilt.Meanwhile,theaveragegrowthrateswerepredictedwiththemodel.Theresultsshowedthatthemethodhadhighpredictionaccuracy,andwasfeasibletodeterminatenaturaluneven-agedstands′averagegrowthrate.Usingthestandgrowthratewithextensionclassifiedpredictiontodeterminetheselectivecuttingcycle,whichwasanindexofincomeapproachinthenaturaluneven-agedforestassetsevaluation,wastheimprovementofincomeapproach.
naturaluneven-agedforest;extensionclassifiedprediction;standgrowthrate;cuttinginterval

2015-04-30
福建省社会科学规划项目(2014C039)资助。
林进添(1986—),男,博士,讲师。研究方向:森林资源资产评估、森林资源审计与认证。Email:393668306@qq.com。
10.11929/j.issn.2095-1914.2016.01.015
S758
A
2095-1914(2016)01-0084-07
猜你喜欢
潍坊学院学报(2020年6期)2020-11-22
防护林科技(2020年9期)2020-11-09
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
中南林业调查规划(2018年3期)2018-11-24
中南林业调查规划(2017年3期)2017-12-29
绿色科技(2017年16期)2017-09-22
现代农业科技(2017年12期)2017-07-29
北方交通(2016年12期)2017-01-15
林业与生态(2016年2期)2016-02-27
中南林业调查规划(2015年3期)2015-12-20
