
基于深度神经网络的语音识别研究
2016-09-20 07:22黄威石佳影四川大学软件学院成都610065
现代计算机 2016年7期
黄威,石佳影(四川大学软件学院,成都610065)
基于深度神经网络的语音识别研究
黄威,石佳影
(四川大学软件学院,成都610065)
0 引言
现在普通话与汉语方言的语音识别,大部分仍使用隐马尔可夫模型(Hidden Markov model,HMM)作为语音识别系统的基本模型来建模语音信号的时序性。但如果考虑了普通话及汉语方言的上下文发音的特点后,其模型参数无法得到充分的训练,语音识别率会受到较大影响[1]。而本文提到的深度神经网络,是一种含有多个隐含层的前向神经网络即深度神经网络(Deep nerual network,DNN),每一层都单独训练(包括最后一层的分类器),使得我们可以在有限的训练数据下可以使模型参数得到更加充分的训练。
尽管DNN在英文的语音识别任务上的优势得到了相关的证明,但是DNN在普通话尤其是汉语方言连续语音识别中的应用尚未深入研究。本文运用DNN模型的思想,研究将深度神经网络应用到普通话与四川话方言语音识别的声学建模当中,成功搭建了普通话与四川话方言的DNN模型语音识别系统,整理了训练和测试相应数据,设计并实现了模型需要使用到的一些脚本,如训练脚本、解码脚本等;以三音素HMM为基本模型,通过对普通话与四川话方言DNN模型训练和测试,以及一系列模型优化措施,得到最终DNN训练模型。本研究针对不同语料库进行相应的模型测试,并对结果进行对比及分析。
1 深度神经网络模型(DNN)
深度神经网络是一个多隐含层感知器,对于相邻的两层节之点间采用全连通,整个网络采用无监督学习的预训练方来生成初始权重,最后一个隐含层和输出层之间使用Softmax方法[1],再通过BP算法来调整整个网络的参数。其结构如图1所示:

图1 深度神经网络
深度神经网络属于深度学习模型中的一种,而深度学习模型的优点主要体现在:①着重强调了模型的深度结构;②突出了大数据对于完善复杂模型的重要性。当训练数据具备足够的多样性和复杂性,深度模型能真正展现对海量数据强大的建模能力;③强调了特征学习的思想。数据在原始特征空间的表示,经过网络的多次非线性映射变换到新的特征空间,最终使得分类或预测变得更简单[2]。
而将DNN深度神经网络应用于语音识别,其具体做法构建基于DNN-HMM混合的声学模型中。其中DNN的作用在于替换原先的GMM模型,估算HMM状态的后验概率。对于给定时刻t的特征观察矢量Ovt,在DNN中釆用Softmax函数计算HMM状态出现的概率,状态为:

其中,avt(s)为输出层状态s的激活概率(输出值):
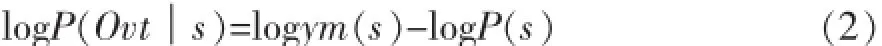
式(2)中,P(s)表示训练数据中状态s出现的先验概率。
网络釆用BP算法,通过最优化给定的目标函数来完成训练。
对于深度神经网络,通常以交叉熵作为目标函数,优化过程通过随机梯度下降算法实现。具体而言,对于如语音识别这种多状态分类问题,以对数概率的负值作为目标函数,如式(3)所示:

式(3)中,sut是1时刻的状态。FCE状态标签与预测状态分布y(s)之间的交叉熵。目标函数与输出层节点s输入avt(s)之间的梯度记为:
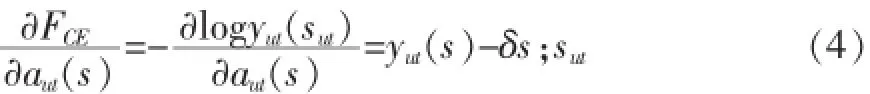
式(4)δs;sut是克罗内克函数,满足:

由式(5),根据BP反向传播算法,调节网络参数。
结合了深度神经网络的DNN-HMM声学模型,相比于单单基于三音素的隐马尔可夫模型构造的声学模型而言,其优势在于:①使用DNN估计HMM的状态的后验概率分布不需要对语音数据分布进行假设;②DNN的输入特征可以是多种特征的融合,包括离散或者连续的;③DNN可以利用相邻的语音帧所包含的结构信息。在文献[3]中的研究表明,DNN的性能提升主要是归功于第3点。
2 Kaldi语音识别系统开发平台
Kaldi语音识别系统开发平台是由Daniel Povey[4]等人开发的语音识别系统,主要由C++语言实现,可以在Linux、Unix、Windows环境下编译。Kaldi的官方网站是http://kaldi.sourceforge.net。
Kaldi主要依赖外部的两个开源库,OpenFst和BLAS/LAPACK。模块的两部分通过Decodable接口连接。Kaldi将各个模型的训练集成在脚本当中,通过脚本来构造语音识别系统,其系统框架图如图2所示。

图2 Kaldi语音识别系统开发平台
安装好Kaldi之后,cd/home/kaldi/kaldi-trunk;ls显示该目录的文件内容见表一,其中比较重要的文件夹是“src”、“tools”。
“tools”文件夹是Kaldi所依赖的一些外部库函数,有openfst和ATLAS。openfst是一个构建,组合,优化和搜索加权有限状态器的库,加权有限状态转换器是自动机,其每个转换都应包含输入标签,输出标签和加权,有限状受体通常是一组字符串;有限状态转换器是用来表示对字符串之间的转换关系;权重用来表示特定过渡的成本。
“src”文件夹中的“configure”脚本负责设置Kaldi使用的库,它在“src”目录下创建“kaldi.mk”文件,通过此文件将合适的参数传递给编译器。Kaldi.mk的内容设计到Kaldi所调用到外部数据库安装路径。

表1 Kaldi文件夹

表2 egs文件夹
3 普通话及四川话方言DNN-HMM模型语音识别系统
3.1实验数据语料库
实验普通话语料库采用的是北京交通大学的泛在网络与数字媒体实验室的语音库。语音库包含23000句左右的训练数据和500句测试数据。语音库大约有40小时左右,每句话时长为5~10秒,发音内容覆盖所有常用汉语音节。
实验四川话方言语料库是由1500条四川方言语音(涵盖四川方言中成渝片及灌赤片)构成。其中80%数据来源为四川地区本土风情影视作品,20%数据来源为10个说话人(男性:5人,女性:5人)。需要注意的是四川方言声母比普通话要少,还有韵母化现象,只有舌尖前音,没有舌尖后音,普通话与四川方言在发音方式上还是存在较大的区别,所以在识别单元设置中采用不同的方法。
3.2识别单元设置
在语音学和音韵学中,普通话及汉语各个方言跟英文等其他语言存在着较大的差异,我们需要根据普通话及汉语方言的发音特点来设计声学模型识别单元来使得实验结果有着更好的准确性。在音韵学中,音节是最自然的语音单位,而音素是最小的语音单位,在普通话中对应的是声母和韵母,另外,为了能更好地表示普通话的发音特点,普通话的识别单元中还添加包含了声调的信息[5]。而在四川话方言中,仅仅是用声韵母来构造对应的识别单元。其两者的识别单元设置如表3所示。
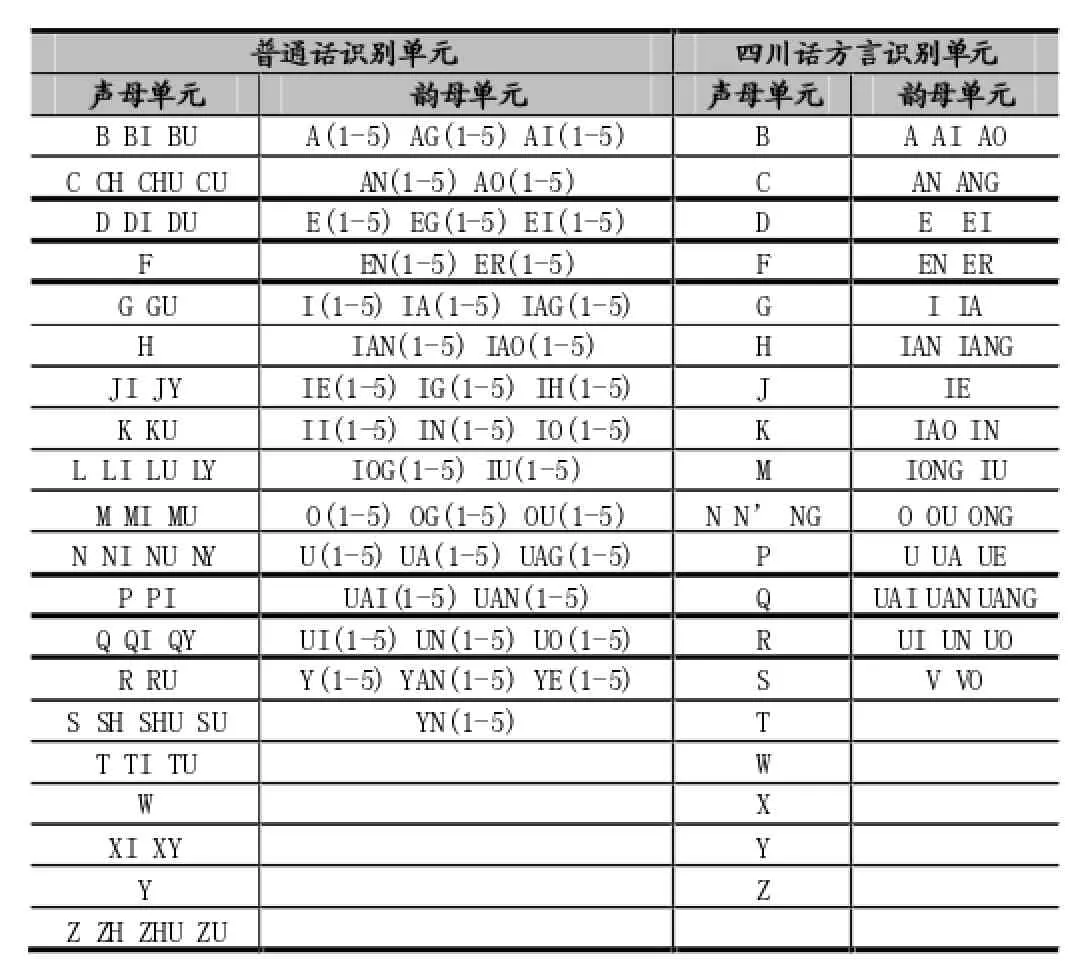
表3 普通话与四川话方言识别单元设置
注:表中比如A(1-5)代表韵母A的5个带音调单元A1,A2,A3,A4,A5,5为轻声调
3.3数据准备
在使用Kaldi进行语音识别训练之前,需要准备相应的训练数据与语言数据,本实验用到的普通话和四川话方言的语料库原始音频文件分别放在msr与scdsr对应的data文件夹中。
准备好原始音频数据之后,我们需要建立相对应的声学模型和语言模型,在data/train下手动创建text、utt2spk、wav.scp三个文件,其中text文本文件包含着每一位说话者的语音内容,wav.scp文件包含了提取原始wav格式音频文件的命令,utt2spk文件用来指明某一段发音是哪由一个说话人发出的。接着运行run.sh脚本自动生成剩余的训练数据文件,完成训练数据的准备。
接着在data/lang下运行run.sh脚本自动生成的相应的语言数据。其中,phones是一个文件夹,其目录下
本文的主要工作是在egs目录下新建的msr/s5和scdsr/s5中完成,其中主要的文件内容为:包含许多关于音素集的信息,分别以.csl、.int和.txt三种格式保存同一类信息;phones.txt和words.txt是两个符合OpenFst格式定义的符号表(symbol-table)文件,用于在音素符号的文本形式和数字形式之间的转换;文件L.fst与Ldisambig.fst是发音字典;文件oov.text里面只包含一个词sil,在训练过程中所有词汇表以外的词都会被映射为这个词;文件topo指明了实验中所用的隐马尔可夫模型拓扑结构信息。最后,运行prepare-lang.sh脚本自动生成剩余的语言数据文件,完成语言数据的准备,具体流程如图3所示。
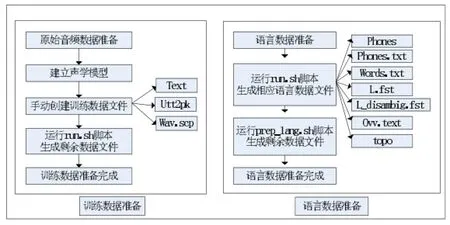
图3 数据准备
3.4模型训练
Kaldi调用shell和perl脚本来实现所有的模型训练和解码过程。Kaldi可以进行基础的隐马尔可夫模型训练,以及在隐马尔可夫模型为基础模型上进行深度神经网络的训练,还可以进行许多优化算法的训练。本文实验首先进行了基本的GMM-HMM模型训练,然后用经过线性区分分析后的训练结果作为DNN训练的基础,构造DNN-HMM模型,最后将两个模型分别对普通话与四川话方言语料库进行语音识别处理,对性能结果进行比较分析从而得出结论。其中具体涉及到的主要脚本如表4所示:
(1)GMM-HMM模型训练
首先,对准备好的输入语音数据进行特征提取,作为要训练的声学模型的输入,调用trainmono.sh脚本训练HMM的单音素模型。训练完单音素模型之后,我们考虑在单音素左右音素的影响,即采用ABC这种形式来表示三音素模型,中间为当前状态,前后为上下文,调用traindeltas.sh脚本来训练基于三音素的隐马尔可夫模型,声学模型加入三音素后,使得模型可以更加细化,识别性能提升。
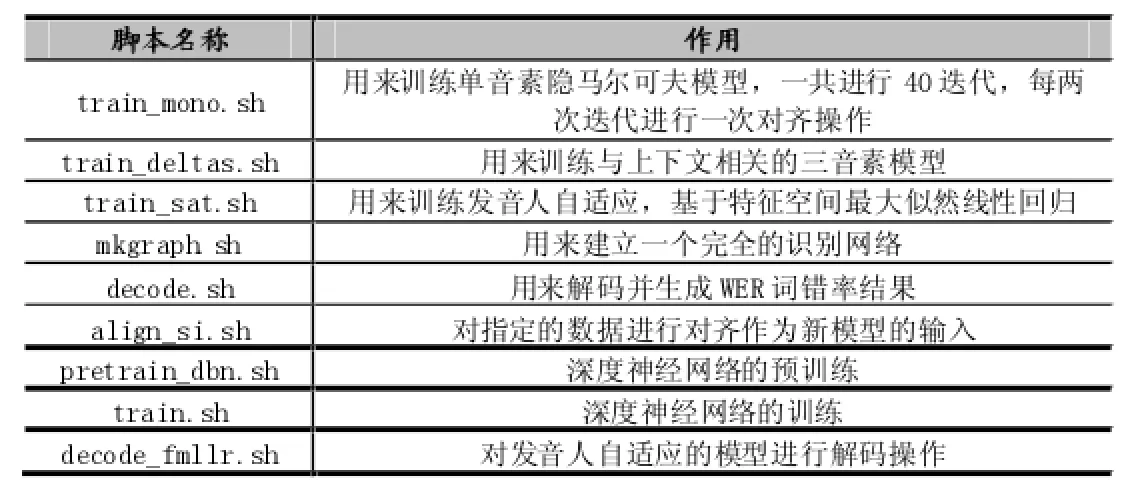
表4 训练脚本
三音素隐马尔可夫模型训练完成之后,接着对其进行优化,例如线性判别特征分析(LDA)和最大相似度线性特征转换(MLLT)。调用trainsat.sh脚本对三音素声学模型进行发音自适应归一化训练(SAT)。
实验中GMM-HMM训练过程如表5所示:
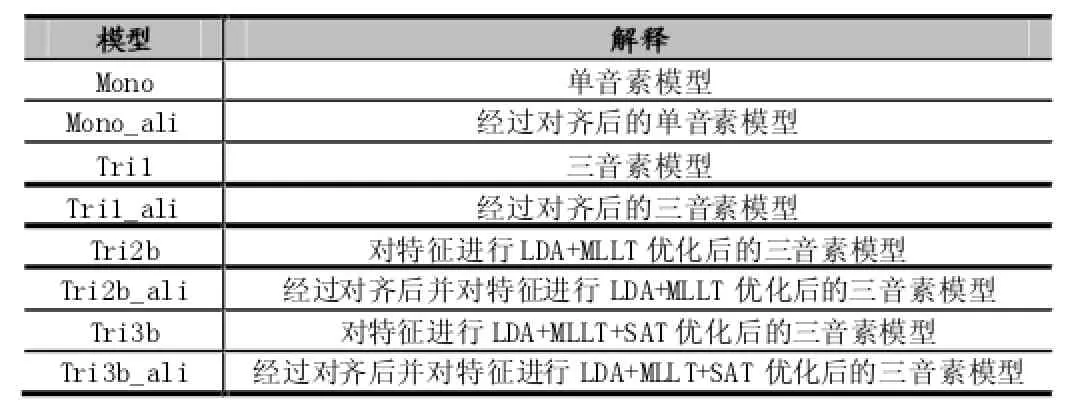
表5 基础模型训练过程
(2)DNN-HMM模型训练
实验中,使用强制对齐后并经过LDA+MLLT+SAT优化后的三音素隐马尔可夫模型作为DNN训练的基础模型。Kaldi中提供了两种深度神经网络训练方法,一种是Karel Vesely版本,另一种为Daniel Povey版本,本实验采用的是前者,其构造的深度神经网络共有6个隐藏层,1个输入层和1个输出层。6个隐藏层各为1024节点。然后我们需要选出普通话与四川话方言语料库中的各500句话作为测试集。
DNN模型训练主要分为三个阶段:
①基于基于RBMS(受限波尔滋蔓机),对每一层进行预训练;
②每一帧进行交叉熵训练;
③用格子框架通过sMBR准则 (状态的最小贝叶斯风险),对序列的区分性训练。
在预训练中,我们将句子级别和帧级别上分别置乱来模仿从训练数据分布里提取样本,每一个Minibatch更新一次。在交叉熵训练中,用BP算法对DNN进行训练,由DNN计算得到的预估概率分布之间的交叉熵作为目标函数,在通过Mini-batch随机梯度下降算法来将每一帧分成三音素状态来训练,默认的学习率为0.008,,Mini-batch的大小为256。模型学习率在最初的几次迭代中是保持不变的,当训练的准确率趋于稳定时(这意味着继续训练不会有性能的提升),我们将学习率减半,直到它再次停止提高。
每训练完一个模型之后都需要用mkgraph.sh脚本来建立模型相对应的识别网络,以方便以后对解码过程,调用decode.sh脚本进行解码之后,输出的结果为词错误率(WER),也就是我们需要对其进行分析的测试结果。
在scdsr/exp中包含了Mono,Monoali,Tri1,Tri1ali,Tri2b,Tri2bali,Tri3b,Tri3bali,dnn4pretraindbn等模型文件夹,其中各个模型目录下包含了该模型的详细信息,例如graph识别网络文件夹,log日志文件夹,decode解码部分文件夹等以及对应的final.mdl模型。
3.5实验结果及分析
采用上述步骤训练出来的GMM-HMM与DNNHMM模型,对普通话与四川话方言语料库分别进行语音识别性能测试,实验结果用词错率WER(Word Error Rate)作为指标来统计结果,词错率反映了语音识别性能的高低,词错率越低说明语音识别效果越好,模型越好。实验结果如表六和表7所示:

表6 普通话语料库实验结果

表7 四川话方言语料库实验结果
实验结果表明:
(1)在普通话语料库中,DNN-HMM的声学建模方法相比于传统GMM-HMM声学建模方法,前者的词错率比后者降低了11.12%,相对下降率为50.7%,甚至比优化后的GMM-HMM声学模型还要降低1.72%,相对下降率为13.72%,这说明在普通话语料库中,DNN模型比传统的基于三音素的隐马尔可夫模型性能更优,对语音数据有着更好的识别能力。
(2)在四川话方言语料库中,DNN-HMM的声学建模方法相比于传统GMM-HMM声学建模方法,前者的词错率比后者略有降低,只降低了0.77%,相对下降率仅为5.07%,其识别性能比经过优化后的GMM-HMM声学模型要差。
实验结果分析:
DNN-HMM在四川话方言语料库中语音识别性能不佳的原因可能有:
(1)相比于普通话语料库的23000条音频文件,四川话方言语料库总共1500条音频文件,整体语音数据量太少。而数据量对于DNN训练而言,有着较为重要的影响,从而导致了DNN模型最后的识别效果较差。
(2)相比于普通话语料库的标准音频文件(这里的“标准”是指在较好的录制条件下的录音),四川话方言语料库整体语音数据质量并不高,由于其大多数音频文件剪辑于影视作品,其背景噪音较为严重,对语音识别的训练造成了较为大的影响,也导致了DNN模型最后的识别结果不理想。
(3)相比于普通话的识别设置单元,四川话方言的识别设置单元并不完全涵盖四川话方言发音,仅仅只是包含了韵母与声母,没有像在普通话的识别设置单元中加入声调,导致最后的DNN模型识别结果较差。
4 结语
深度神经网络模型相对于传统的基于三音素的隐马科夫模型,对海量复杂数据有着较好的建模能力,在识别单元设置合理的情况下,能够对海量复杂的数据进行充分的训练,可以获得更好的语音识别效果。本文以Kaldi为识别平台,以隐马尔可夫模型为基本模型,进行模型优化训练,最后成功搭建了汉语及四川话方言的深度神经网络模型,并对相关的普通话及四川话方言语料库分别进行模型测试。本实验测试中,深度神经网络在不同语料库中的语音识别性能有所差异。对于普通话的语音识别,基于三音素的隐马尔可夫模型的WER为21.93%,优化后的三音素模型的WER为12.53%,最后得到的DNN模型的WER为10.81%。使用DNN模型后,相比基于三音素的隐马尔可夫模型,其词错率降低了11.12%,相对下降率为50.7%。而对四川话方言的语音识别,深度神经网络模型的语音识别效果近似于隐马尔可夫模型,鉴于本文的四川话方言语料库有限,数据质量不高,识别单元设置不合理,后续可以更正识别单元,添加大量的高质量数据,进行更好的深度神经网络的构造与训练。
[1]其米克·巴特西,黄浩,王羡慧.基于深度神经网络的维吾尔语语音识别[J].计算机工程与设计,2015(8):2239-2244.
[2]Li J,Yu D,Huang J T,et al.Improving Wideband Speech Recognition Using Mixed-Bandwidth Training Data in CD-DNN-HMM[J]. IEEE Workshop on Spoken Language Technology,2012,8537(11):131-136.
[3]余凯,贾磊,陈雨强,等.深度学习的昨天、今天和明天[J].计算机研究与发展,2013,50(9):1799-1804.
[4]Pan J,Liu C,Wang Z,et al.Investigation of Deep Neural Networks(DNN)for Large Vocabulary Continuous Speech Recognition:Why DNN Surpasses GMMS in Acoustic Modeling[J].IEEE,2012,7196(8):301-305.
[5]Povey D,Burget L,Agarwal M,et al.The Subspace Gaussian Mixture Model—A Structured Model for Speech Recognition[J].Computer Speech&Language,2011,25(2):404–439.
[5]张德良.深度神经网络在中文语音识别系统中的实现[D].北京交通大学,2015.
Deep Neural Network;Speech Recognition;Hidden Markov Model
Research on Speech Recognition Based on Deep Neural Network
HUANG Wei,SHI Jia-yin
(College of Software Engineering,Sichuan University,Chengdu 610065)
1007-1423(2016)07-0020-06
10.3969/j.issn.1007-1423.2016.07.005
黄威(1995-),男,浙江温州人,本科,研究方向为机器智能
石佳影(1995-),女,河北唐山人,本科,研究方向为机器智能2016-01-15
2016-02-19
目前,普通话与汉语方言语音识别主要采用的是三音素的隐马尔可夫模型,其语音识别率并不是很高。以Kaldi为测试平台,通过训练得到一个含有6个隐层的深度神经网络模型,利用该模型对普通话与四川话方言分别进行语音识别。实验结果表明,深度神经网络在普通话语料库中的语音识别性能要优于三音素的隐马尔可夫模型,词错率降低11.2%。而在四川话方言语料库训练集上的识别率与三音素的隐马尔可夫模型相当。
深度神经网络;语音识别;隐马尔可夫
Currently mandarin and Chinese dialect speech recognition are mainly achieved by using the triphone hidden Markov model,however,the speech recognition rate is not very well.Based on a neural network containing six hidden layers which is trained by the Kaldi platform,and uses the model for the mandarin and Sichuan dialect recognition.The experimental results show that the speech recognition performance is improved in the DNN model compared to that using the HMM triphone model in the mandarin corpus,which reduces the word error rate by 11.2%.But the performance based on DNN model is similar to that using the HMM triphone model in Sichuan Dialect corpus.
猜你喜欢
外语学刊(2021年1期)2021-11-04
北京教育·普教版(2020年9期)2020-10-09
天津外国语大学学报(2020年1期)2020-03-25
校园英语·中旬(2019年11期)2019-11-26
广西教育·D版(2019年6期)2019-07-11
速读·中旬(2018年8期)2018-10-23
故事会(2009年12期)2018-09-03
中文信息(2016年8期)2016-11-22
外语教学理论与实践(2014年4期)2014-06-13
文学教育(2014年3期)2014-05-26
