
演化软件的特征定位方法*
2016-09-20 09:00韩俊明
计算机与生活 2016年9期
韩俊明,王 炜,2+,李 彤,2,何 云
1.云南大学 软件学院,昆明 6500912.云南省软件工程重点实验室,昆明 650091
演化软件的特征定位方法*
韩俊明1,王炜1,2+,李彤1,2,何云1
1.云南大学 软件学院,昆明 650091
2.云南省软件工程重点实验室,昆明 650091
确定演化活动潜在影响的过程称为特征定位。特征定位已经被公认为影响软件演化项目成败的一个关键因素,如何利用程序的领域知识促进特征定位的准确性已经成为当前研究的一个重要问题。该方法提取出软件源代码中的特征,并对提取后的特征进行主题分析,然后通过输入查询语句定位出被修改的源代码。利用现有的开源软件进行实验,并将实验结果与对应开源软件的Benchmark进行对比,结果表明所提出方法的精确度有所提高,可以进行软件特征的定位。实验结果中,平均查全率达到69.16%和100%,平均查准率达到1.28%和2.43%,平均调和平均数达到2.50%和4.72%,性能较对比方法有较大的提高。
软件演化;特征定位;主题模型;领域知识
1 引言
特征是指软件系统中被需求所定义和被使用的一个功能[1]。建立软件特征与源代码之间映射关系的过程称为特征定位[2]。特征定位是顺利实现软件演化意图的前提之一。对于文档缺失的中、大型软件采用人工的方式实现特征定位几乎是不可能的。文献[1]指出特征定位存在“两难”,即“高难度”和“高开销”。面向大型软件的可信演化活动常常由于无法迅速而准确地进行特征定位,导致演化效率低,甚至失败。文献[3-4]指出,在长生命周期软件系统中,50%~75%的系统成本和花费用于软件维护,其中一半以上的工作量用于特征定位。
1992年Wilde等人[5]提出的软件勘测(software reconnaissance)技术是最早的特征定位方法之一。此后,学者们基于覆盖执行[6]、基于依赖关系[7]和基于模型[8]分别提出了各自的动态特征定位方法[9]。动态定位方法能获得比较高的查全率,但是状态空间大,定位精度低,同时存在大量的噪声数据。
静态方法是对软件源代码的依赖关系和结构的静态分析,并建立特征和代码间的映射关系[2]。但该方法在使用过程中需要大量的人工搜索,同时具有较高的算法开销和人工开销。
动态和静态方法都存在一定的缺陷,因此本文提出了利用主题模型来分析软件源代码,并进行特征定位的方法。
主题模型,最初研究成果是作为对自然语言进行处理的工具。目前,国内的相关研究成果主要是把主题模型用于自然语言处理,很少有人将主题模型与软件源代码进行结合研究。文献[10]将主题模型用于处理软件源代码,主要是进行代码功能的分析,通过分析结果可以帮助开发人员理解软件功能和代码的实现。而文献[11]使用LDA(latent Dirichlet allocation)模型来进行中文软件文档和代码的相关性分析,根据分析结果将软件缺陷分配给相关人员去解决,并研究如何使用主题模型更好地提高软件及代码间语义相关性的提取效果。这些文献并没有将主题模型与软件演化或特征定位进行结合研究。
本文的创新点和贡献如下:
(1)对软件演化方面的研究不再局限于理论上的论证,而尝试使用实验的方式进行特征定位的研究。
(2)将处理自然语言的主题模型用于分析软件源代码,并将分析结果用于软件特征定位的研究工作。
(3)为了验证本文提出的方法,使用了真实的软件源代码进行实验,并与原有的特征定位方法进行对比,实验结果表明本文方法具有普适性和较高的精确性。
(4)除主题模型本身的代码外,文中所有实验,从源代码的特征提取、处理,到产生的实验结果,均是由程序执行,并已经形成一整套的特征定位工具。
本文结构安排如下:第2章介绍软件特征定位方法;第3章描述实验所采用的软件源代码;第4章对实验结果进行分析和讨论;第5章对实验进行总结,并探讨未来的研究方向。
2 软件特征定位方法
本文研究思路大致分为3个过程,如图1所示:主题语料[12]获取;主题建模;特征定位。3个过程具体步骤将在2.1~2.3节中介绍。

Fig.1 Feature location method图1 软件特征定位方法
2.1主题语料获取
本文方法原始实验数据为软件的源代码。源代码中包含了很多文件信息,例如图片、XML,甚至在代码文件内都有符号、关键字等,这些信息对描述软件功能的意义并不大,若直接采用源代码进行实验分析,就会存在大量无用的信息,实验结果的精确度将会受到很大的影响。考虑到源代码中很多都是信息量不大的代码功能语句、关键字等,就需要对源代码进行处理。根据文献[13]中提到的内容“……源代码中的变量名、函数名、类(对象)名、API函数、注释等关键词中蕴含了丰富的主题知识,可以通过其识别源代码与特征之间的映射关系。”因此本文认为,能反映一个代码模块或一个类功能的是该代码模块或者该类中变量名、方法名和注释,这就需要从源代码中提取出变量名、方法名和注释。
本文实验数据的处理主要有以下4个步骤:
(1)通过相关的网站下载同一个软件两个不同版本的源代码。
(2)提取出两个版本软件源代码中的特征(本文主要是提取变量名、方法名和注释),把提取后的特征以类为形成一个单独文件的基本单位,并以该类所在的包的名字加上其类名对该文件进行命名。
(3)考虑到版本间的有些更新删除了某些功能,为了提高结果的精确性,需要整合两个版本的特征。因此在处理特征上,本文采取了将低版本中有而高版本中没有的特征加入到高版本中。具体操作为:若低版本中有而高版本中没有的文件,则直接把该文件拷贝到高版本中;若某个文件在低版本和高版本中均存在,则以行为基础,找出低版本中有而高版本中没有的行,加入到高版本的该文件中。
(4)预处理[14],去除停词(类似“this”、“the”等)和词根还原(例如将“broken”还原为“break”)。这样可以减少文件的内容,提高了主题模型生成结果的精度。
表1为提取特征后部分文件名及其内容的示例。

Table 1 Sample of features in source code表1 源代码特征示例
2.2主题建模
主题模型是在自然语言处理和机器学习领域,用来从一系列文档中提取主题的一种概率统计模型。从更直观的角度来理解,就是一篇文章会有一个中心思想,从而会有一些与该中心思想相关的词汇频繁出现。主题模型就试图使用数学领域的框架来体现这种情况,主题模型会自动分析文档,统计文档内的词汇信息,根据统计结果来确定文档、主题和词三者之间的关系。本文使用主题模型对文档的生成过程进行模拟,再通过参数估计得到各个主题[15]。主题模型中,有一个重要的假设称为词袋假设,其具体内容是把文档信息视为词频向量,并且不考虑词与词之间的顺序。
LDA[16]是一种非监督机器学习方法。在LDA中,一个文档被看作是一系列不同主题的集合,采用忽略词间顺序的词袋方法把文档视为词频的向量,这样就把不能建模的文字信息转换成为可以建模的数字信息。LDA主题模型包含了3层结构,分别为文档、主题和词汇,并且以概率的形式给出了文档和主题、主题和词汇之间的关系。
主题模型技术最早是由Blei等人[16]在2003年所提出,主要应用于自然语言处理或者信息检索方面。主题模型是一种生成模型,描述了一种用以生成文档的概率过程[17]。LDA认为[16],文档是一系列的主题按照一定的概率生成的,而主题又是一组词按照一定的概率生成的,因此对于一个文档集D中的文档d,LDA假设了如下的生成过程[16]:

通过对从源代码中提取的特征采用主题模型进行建模后,可以得到主题和词之间的概率模型。表2为生成的概率模型示例。

Table 2 Sample of probabilistic model表2 概率模型示例
如表2所示,主题Topic1包含了两个单词document 和model,每个单词属于Topic1的概率分别为0.025 和0.013。
2.3特征定位
选取一条更新报告,并对该条报告做过滤处理,利用上一步生成的概率模型,计算更新报告和每一个主题的相似度。对计算出来的相似度排序,根据排序结果,选取相似度最高的一个或多个主题所包含的主题词,统计每一个特征文件中这些主题词出现的次数和该文档的总词数,使用“出现率”这一指标来对所有特征文件进行排序,通过排序结果,确定哪些文件被修改,进而进行特征定位。
定义1使用ONT(occurrence numbers of topicwords)表示在一个文档内主题词出现的次数,使用TWD(total words in a document)表示该文档的总词数,则出现率(occurrence rate,OR)可定义如下:

3 实验数据
数据是实验最重要的一个部分,因此源数据的获取情况直接关系到最终实验结果的好坏。本文方法中,实验数据是软件的源代码,为了保证实验结果的可靠性和客观性,同时也要提高实验结果的精确性,就需要获取到完整、有效的软件源代码。
对于需要获取的软件源代码,本文考虑以下3点:首先,得到的软件源代码必须是完整、有效且合法的,获取方法也必须是合法的。其次,该软件需要有比较长的演化历史,并且能够获取到两个甚至是多个版本的源代码。通过对比网上现有的开源软件,最后决定使用ArgoUML(http://argouml-downloads.tigris.org/)0.20和0.22版本(使用的ArgoUML由Java编写),并下载ArgoUML0.20-0.22版本Benchmark(http://www.cs.wm.edu/semeru/data/benchmarks/)用来验证实验结果。
在Benchmark中,有3个文件夹Queries、Traces和GoldSets。Queries中的内容是软件版本更新说明,LongDescription是详细描述,ShortDescription是概括性短语描述。Traces中为特征相关的执行迹,文件中记录了特征对应的测试用例在执行过程中搜集到的源代码调用信息。GoldSets记录了与特征实际相关的源代码,也就是在演化过程中哪些类被修改了。
4 实验测试与结果分析
4.1JGibbLDA
本文方法使用的是由Java语言编写的LDA主题模型建模程序JGibbLDA(http://jgibblad.sourceforge. net/)。按照JGibbLDA输入文件格式的要求(第一行为输入文档的个数,其余每行代表一个文档,行内容为文档中的单词,单词间以空格分隔)形成一个文件,如表3所示。经过观察发现,很多类的特征极少,若以一个类作为一个文档可能会导致输入的文档数目过多,因此以一个包作为一个文档进行整理。
在JGibbLDA程序运行前,需要设定一些参数才能让程序运行,参数具体内容如表4所示。

Table 3 File format of input表3 输入文件格式

Table 4 Parameters in JGibbLDA表4JGibbLDA中的参数
在这些参数中,α和β属于超参数,目前暂时没有很好的方法对这两个参数的取值进行确定。根据文献[18]中的研究结果,α和β对应的值可以设置为50/k(k为输入文件内文档的数量)和0.1。
4.2实验结果文件内容
JGibbLDA实验后,会出现5类后缀名不同的文件,其后缀名和内容如表5所示。

Table 5 Filename extension and its content表5 文件后缀名及其内容
4.3形成实验结果
利用文件model-final.twords中的数据,形成最终的实验结果需要以下5步:
(1)从开源软件的Benchmark中选取一条更新报告,也做去除停词和词根还原的处理。
(2)假设参数ntopics和twords分别设置为N和T,生成N个T维的向量,并把这N个向量初始化为0。
(3)对这N个向量赋值,若主题m(0 (4)重复步骤(3)至这N个T维向量全部赋值完毕,然后针对第m个T维向量的值,与文件model-final. twords中第m个主题词对应的值,进行计算两个向量夹角余弦值操作,其中m=1,2,…,N。 (5)将计算出的余弦值降序排列,取前 j个主题的所有主题词,在源代码的特征文件中进行词频统计,并计算出现率。 4.4定义实验标准 为了验证本文方法的性能,需要使用某些度量标准来对结果进行度量和对比。本文采用在信息检索中常用的查全率(Recall)和查准率(Precision)作为衡量指标,并通过这两个指标来对输出结果进行评价[9],具体定义如下。 定义2Recall表示查全率,correct代表所需查找的目标文件,retrieved代表使用定位方法查找出来的文件,则查全率的定义为: 定义3Precision表示查准率,correct代表所需查找的目标文件,retrieved代表使用定位方法查找出来的文件,则查准率的定义为: 查全率和查准率之间具有互逆的关系。在极端情况下,一个将文档集合中所有文档返回为结果集合的系统有100%的查全率,但是查准率却很低(http: //baike.baidu.com/view/2126615.htm?fr=aladdin)。因此使用查全率和查准率的调和平均数F来评价方法的综合性能。 定义4使用F代表查全率和查准率的调和平均数,Recall代表查全率,Precision代表查准率,则调和平均数定义为[9]: 4.5实验结果 实验使用了ArgoUML的0.20-0.22版本源代码进行特征提取和处理,一共得到1 562个类和96个包,在用JGibbLDA处理时,alpha、beta、ntopics、niters、savestep和twords的值分别设置为0.528、0.1、30、1 000、100和50,选取夹角余弦值最高的5个主题的所有主题词进行词频统计。 表6列举了对ArgoUML做的实验的查询内容,查询内容来自Benchmark中的ShortDescription。 Table 6 Query contents ofArgoUML表6ArgoUML查询内容 文献[9]的推荐方法,取出现率最高的10%~15%的源代码计算查全率和查准率,并使用调和平均数来评价性能。而本文只取出现率最高的前5%进行计算。 表7为实验结果统计,从统计数据来看,10组实验结果,平均查全率为69.19%,平均查准率为1.28%,调和平均数的平均值为2.50%。 Table7 Query results ofArgoUML表7 ArgoUML查询结果 文献[12]是基于文本的特征定位技术,将其作为基线方法,在使用相同实验数据的前提下,与本文方法对表6中的特征数据进行对比。基线方法的10组实验,平均查全率为50.00%,平均查准率为1.02%,调和平均数的平均值为2.00%。基线方法与本文方法的查全率、查准率和调和平均数的具体数据对比分别如图2、图3和图4所示。 从图2、图3和图4中可以很明显地看出,本文方法与基线方法进行对比,10组实验中,3组高于基线方法,1组低于基线方法,其余6组与基线方法相同。可以观察到,在高于基线方法的3组实验(实验3、5、10),基线方法的查全率和查准率都是0,而本文方法却还可以查到,并且有比较理想的查全率和查准率。 Fig.2 Recall comparison图2 查全率对比 Fig.3 Precision comparison图3 查准率对比 在进行源代码特征提取时,有一类词在定位上起着关键作用,将其称为组合词,它是由两个或多个普通的单词组合起来形成的新单词,类似于“getsourcefileinfo”。这类词在人类的自然语言中是不会出现的,因此LDA在计算其属于某主题概率时,并不会对其做特殊的处理,以示与普通单词进行区分,而本文方法在提取特征时也没有对这些组合词进行分词处理。然而,组合词在软件的源代码中出现得很普遍,因为在编写程序时,会用到这些词汇表示一些重要或者复杂的信息,同时同一个组合词在整个源代码中出现的次数不会太多,所以利用组合词可以再次提高定位的精确度。 将所选主题词中的组合词提取出来,在所有文件中统计这些组合词的出现次数,并将出现次数降序排列。假设组合词出现次数最少的目标文件排第N位,出现率最低的目标文件排第M位,则将前N个文件和前M个文件做交集处理,提取出它们的公共部分,这样就能很大程度上提高定位的精确度。 表8为加入组合词的结果统计,从统计数据来看,组合词确实极大程度提高了定位的精确度。最好的情况下,可以过滤掉222个无关文件,最差能过滤掉2个文件。 Table8 Statistical results ofArgoUML within compound words表8 考虑组合词的ArgoUML统计结果 表9为在考虑组合词后,ArgoUML实验结果。10组实验数据,平均查全率为100%,平均查准率为2.43%,调和平均数的平均值为4.72%,较没有考虑组合词时的实验和基线方法,都有了明显的提升。基线方法、本文方法和考虑了组合词的查全率、查准率和调和平均数的具体数据对比分别如图5、图6和图7所示。 Table 9 Experimental results ofArgoUML within compound words表9 考虑组合词的ArgoUML实验结果 从图5、图6和图7中可以很明显地看出,在考虑了组合词后,查全率、查准率和调和平均数都有了比较大的提高。在只取出现率最高的前5%源代码进行计算时,具体平均数据如表10所示。 Fig.5 Recall comparison within compound words图5 考虑组合词的查全率对比 Fig.6 Precision comparison within compound words图6 考虑组合词的查准率对比 Fig.7 F-measure comparison within compound words图7 考虑组合词的调和平均数对比 Table 10 Recall,precision and F-measure comparison表10 查全率、查准率和调和平均数对比 本文只取前5%的源代码进行比较,并利用组合词进一步提高了定位的精确度。通过表10可以看出,本文方法在平均查全率、平均查准率和调和平均数的平均值上,均明显高于基线方法。 软件演化是否与演化目的相符合,或者是否确实进行了演化,一直是软件演化领域一个重要的研究方向,过去对软件演化的研究大多都是在理论上的推演。为了能够在软件演化领域有所突破和创新,希望能够利用实验数据来进行软件演化的特征定位,因此本文提出了一种基于主题模型LDA的软件演化被修改代码定位方法,并开发出了一整套本文方法所使用的定位工具。通过对ArgoUML源代码进行分析和实验,证明了本文方法的高效性。 由于LDA本身是用于处理人类自然语言的工具,将其应用于处理软件代码势必会带来一些问题。通过研究发现,以下两点对本文实验结果存在着影响: (1)将一条更新报告作为查询语句进行定位,要想获得比较理想的实验结果,对该条更新报告的内容有比较高的要求。首先,这条信息要能很客观、直接地描述出修复了什么Bug或Defect;其次,描述所修复的最好是代码层面上的改动,若是软件的图标或其他非功能上的改动则本方法效果不佳;再次,描述修复的Bug或Defect,需要是实验使用的两个版本中在低版本发现而在高版本被修复的,例如某些Bug 或Defect是两个版本间的一些测试版发现或修复的,则实验结果不会很理想。 (2)使用JGibbLDA对语料进行处理时,需要输入一些参数,每一个参数的设置对实验结果都有着极大的影响。 LDA作为一种机器学习方法,研究之初就是为了将其应用于处理自然语言方面的问题,本文方法将其应用于软件演化领域本身是一次创新。对本文方法进行了实验,结果证明尝试是成功的,但是也存在着一些问题,这些问题将会成为以后的研究方向:首先,如何设置JGibbLDA的参数,特别对于两个超参数α和β,目前国内外还没有研究出一种带理论依据的方法提供指导,其值的设置都是凭借人工经验;其次,对原始语料既源代码的处理,是否还需要使用其他方法进行处理以提高结果的精确度;再次,需要通过一定的方法来确定一个词是否为组合词;同时,还将对本文开发的定位工具进行扩展以支持更多语言的源代码,并继续研究LDA是否还能应用于计算机其他研究领域。 References: [1]Poshyvanyk D,Guéhéneuc Y G,Marcus A,et al.Feature location using probabilistic ranking of methods based on execution scenarios and information retrieval[J].IEEE Transactions on Software Engineering,2007,33(6):420-432. [2]Dit B,Revelle M,Gethers M,et al.Feature location in source code:a taxonomy and survey[J].Journal of Software Evolution and Process,2013,25(1):53-95. [3]Li Tong.An approach to modelling software evolution processes[M].Berlin:Springer,2008. [4]Seacord R C,Plakosh D,Lewis G A.Modernizing legacy systems:software technologies,engineering processes,and business practices[M].Boston,USA:Addison-Wesley Longman Publishing Co,2003. [5]Wilde N,Gomez JA,Gust T,et al.Locating user functionality in old code[C]//Proceedings of the 1992 Conference on Software Maintenance,Orlando,USA,Nov 9-12,1992.Piscataway,USA:IEEE,1992:200-205. [6]Wong W E,Wei Tingting,Qi Yu,et al.A crosstab-based statistical method for effective fault localization[C]//Proceedings of the 2008 1st International Conference on Software Testing,Verification,and Validation,Lillehammer,Apr 9-11,2008.Piscataway,USA:IEEE,2008:42-51. [7]Baah G K,Podgurski A,Harrold M J.The probabilistic program dependence graph and its application to fault diagnosis[J].IEEE Transactions on Software Engineering,2010, 36(4):528-545. [8]Xu Baowen,Nie Changhai,Shi Liang,et al.A software failure debugging method based on combinatorial design approach for testing[J].Chinese Journal of Computers,2006, 29(1):132-138. [9]Ju Xiaolin,Jiang Shujuan,Zhang Yanmei,et al.Advanced in fault localization techniques[J].Journal of Frontiers of Computer Science and Technology,2012,6(6):481-494. [10]Li Meng,Zhao Junfeng,Xie Bing.Obtaining functional topics from source code based on topic modeling and static analysis[J].Scientia Sinica:Informationis,2014,44(1):54-69. [11]Xu Yebing,Liu Chao.Research on retrieval methods for traceability between Chinese documentation and source code based on LDA[J].Computer Engineering and Applications,2013,49(5):70-76. [12]Marcus A,Sergeyev A,Rajlich V,et al.An information retrieval approach to concept location in source code[C]//Proceedings of the 11th Working Conference on Reverse Engineering,Delft,Netherlands,Nov 8-12,2004.Piscataway,USA: IEEE,2004:214-223. [13]He Yun,Wang Wei,Li Tong,et al.Behaviour and topic oriented software feature location method[J].Journal of Frontiers of Computer Science and Technology,2014,8(12): 1452-1462. [14]Linares-Vásquez M,McMillan C,Poshyvanyk D,et al.On using machine learning to automatically classify software applications into domain categories[J].Empirical Software Engineering,2014,19(3):582-618. [15]Xu Ge,Wang Houfeng.The development of topic models in natural language processing[J].Chinese Journal of Computers,2014,34(8):1423-1436. [16]Blei D M,Ng A Y,Jordan M I.Latent Dirichlet allocation[J]. Journal of Machine Learning Research,2003,3:993-1022. [17]Steyvers M,Griffiths T.Probabilistic topic models[M]//Latent Semantic Analysis.New Jersey:Lawrence Erlbaum Associates,2007:424-440. [18]Griffiths T,Steyvers M.Finding scientific topics[J].Proceedings of the National Academy of Sciences of the United States ofAmerica,2004,101:5228-5235. 附中文参考文献: [8]徐宝文,聂长海,史亮,等.一种基于组合测试的软件故障调试方法[J].计算机学报,2006,29(1):132-138. [9]鞠小林,姜淑娟,张艳梅,等.软件故障定位技术进展[J].计算机科学与探索,2012,6(6):481-494. [10]李萌,赵俊峰,谢冰.基于主题建模和静态分析技术的软件代码功能性主题获取方法[J].中国科学:信息科学, 2014,44(1):54-69. [11]许冶冰,刘超.基于主题的文档与代码间关联关系的提取研究[J].计算机工程与应用,2013,49(5):70-76. [13]何云,王炜,李彤,等.面向行为主题的软件特征定位方法[J].计算机科学与探索,2014,8(12):1452-1462. [15]徐戈,王厚峰.自然语言处理中主题模型的发展[J].计算机学报,2014,34(8):1423-1436. HAN Junming was born in 1988.He is an M.S.candidate at Yunnan University.His research interests include software engineering,software evolution and data mining. 韩俊明(1988—),男,云南文山人,云南大学硕士研究生,主要研究领域为软件工程,软件演化,数据挖掘。 WANG Wei was born in 1979.He received the Ph.D.degree in system analysis and integration from Yunnan University in 2009.Now he is an associate professor at Yunnan University,and the member of CCF.His research interests include software engineering,software evolution and data mining. 王炜(1979—),男,云南昆明人,2009年于云南大学系统分析与集成专业获得博士学位,现为云南大学副教授,CCF会员,主要研究领域为软件工程,软件演化,数据挖掘。发表学术论文15篇,出版教材1部,主持省部级项目5项。 LI Tong was born in 1963.He received the Ph.D.degree in software engineering from De Montfort University in 2007.Now he is a professor and Ph.D.supervisor at Yunnan University,and the senior member of CCF.His research interests include software engineering and information security. 李彤(1963—),男,河北石家庄人,2007年于英国De Montfort大学软件工程专业获得博士学位,现为云南大学软件学院院长、教授、博士生导师,CCF高级会员,主要研究领域为软件工程,信息安全。发表学术论文100余篇、专著2部、教材5部,主持国家级项目5项、省部级项目14项、其他项目20余项。 HE Yun was born in 1989.He is an M.S.candidate at Yunnan University,and the student member of CCF.His research interests include software engineering,software evolution and data mining. 何云(1989—),男云南建水人,云南大学硕士研究生,CCF学生会员,主要研究领域为软件工程,软件演化,数据挖掘。 Feature Location Method of Evolved Softwareƽ HAN Junming1,WANG Wei1,2+,LI Tong1,2,HE Yun1 HAN Junming,WANG Wei,LI Tong,et al.Feature location method of evolved software.Journal of Frontiers of Computer Science and Technology,2016,10(9):1201-1210. Feature location is the process that confirms the potential influence in software evolution.Feature location is a recognized critical factor that decides success or failure in evolution,and how to use domain knowledge to promote accuracy in feature location becomes an important problem in current research.This method extracts the features in the software source code,and analyzes the features by topic model,then inputs update report as a query to locate which source code has been changed.This paper makes experiments with open source software,then compares experimental results with the benchmark of the open source software,correlation results indicate that this method has higher accuracy and universality,and can verify software evolution.The average of recall can achieve 69.16%and 100%,the average of precision can achieve 1.28%and 2.43%,the average of harmonic mean can achieve 2.50%and 4.72%.The experimental results show that the performance is better than that of baseline. software evolution;feature location;topic model;domain knowledge 2015-07,Accepted 2015-09. *The National Natural Science Foundation of China under Grant Nos.61462092,61262024,61379032(国家自然科学基金);the Key Project of Natural Science Foundation of Yunnan Province under Grant No.2015FA014(云南省自然科学基金重点项目);the Natural Science Foundation of Yunnan Province under Grant No.2013FB008(云南省自然科学基金). CNKI网络优先出版:2015-09-28,http://www.cnki.net/kcms/detail/11.5602.TP.20150928.1033.002.html A TP311.5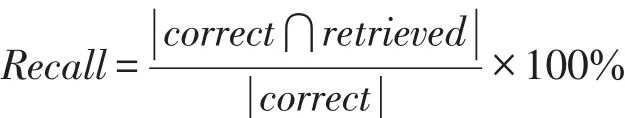
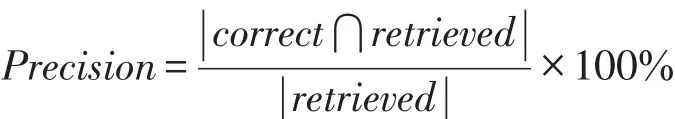











5 实验总结及未来研究方向




1.College of Software,Yunnan University,Kunming 650091,China
2.Key Laboratory for Software Engineering of Yunnan Province,Kunming 650091,China
+Corresponding author:E-mail:wangwei@ynu.edu.cn
猜你喜欢
现代信息科技(2021年21期)2021-05-07
现代电子技术(2018年20期)2018-10-24
现代电子技术(2018年16期)2018-08-21
现代情报(2018年11期)2018-01-07
现代电子技术(2017年23期)2017-12-20
计算机应用(2017年10期)2017-12-14
计算机应用(2016年10期)2017-05-12
世界汽车(2016年9期)2016-09-29
中国管理信息化(2009年10期)2009-06-19
