
卫生经济学评价中基于贝叶斯NMB模型的样本量估计方法及SAS实现
2016-10-26 05:21南方医科大学生物统计学系510515
中国卫生统计 2016年4期
南方医科大学生物统计学系(510515)
张娟娟 黄 云 陈平雁△
·应用研究·
卫生经济学评价中基于贝叶斯NMB模型的样本量估计方法及SAS实现
南方医科大学生物统计学系(510515)
张娟娟黄云陈平雁△
【提要】目的通过SAS编程实现Bayesian方法在卫生经济学评价中的样本量估计,弥补该领域样本量计算在操作上的不足。方法概括性地介绍Bayesian方法的理论背景,以及分析阶段和设计阶段的先验信息对样本量估计的重要性,给出样本量估算的不等式。编写SAS宏程序,利用迭代算法估算出不同参数组合下的样本量。结果通过举例展示了三种情形下的样本量估计结果,包括:分析阶段较弱、设计阶段较强的先验信息,分析阶段较弱、设计阶段适当的先验信息,以及分析阶段、设计阶段相同的先验信息。效果与成本的相关系数(含方向)、效应量、意愿支付界值与所需样本量呈负相关。此外,先验信息越强,所需样本量越小。结论本文的SAS程序可以实现不同效应量、相关系数、意愿支付界值等参数组合下的Bayesian样本量估计结果,还包括了经典的频率方法。
成本效果样本量Bayesian方法SAS编程词首字母大写
传统的卫生经济学评价往往只作为临床试验的次要评价指标,原因是新药注册时不要求提供卫生经济学数据[1]。随着临床试验的卫生经济学评价迅速发展,澳大利亚和加拿大提出新药在批准报销之前必须提供成本效果数据[2-3],ISPOR(international society for pharmacoeconomics and outcomes research)也给出了临床试验的卫生经济学评价专业指导意见[4-5],从而使得卫生经济学评价在新药审批及医疗费用报销中日益受到重视。临床试验的经济学评价首先需要考虑样本量问题。近二十年有关卫生经济学评价的样本量估计方法被陆续提出,包括模拟方法[6],基于成本数据的分布提出的参数和非参数方法[7],基于Fieller准则的置信区间法[8],机会成本法[9]等基于经典频率理论的方法,也有相应的Bayesian方法[1,10]。虽然样本量估计的方法学逐步发展,但目前尚缺乏相应的专用统计软件或便利程序,从而阻碍了卫生经济学评价领域中样本量估计的普遍应用,尤其是计算过程较为复杂的Bayesian方法的应用。
本文将首先介绍Bayesian方法的理论背景,然后通过SAS 9.4编程实现不同参数设置下的样本量估计,并分析各参数与样本量及检验效能之间的相互影响,以期为该方法的应用提供便利工具和参考意见。
方法介绍
1.卫生经济学评价的贝叶斯NMB模型
卫生经济学评价中,常用的成本效果评价指标为净效益(net monetary benefit,NMB),即
NMB=K△e-△c=K(μ1-μ2)-(γ1-γ2)
(1)
NMB是新方法与标准方法在货币尺度上的相对净效益,是关于K的函数。式中,K表示意愿支付的界值(willing to pay,WTP),△e代表两种方法效果的均数差,即μ1-μ2,μ1和μ2分别表示两种方法的平均效果;△c代表两种方法成本的均数差,即γ1-γ2,γ1和γ2分别表示两种方法的平均成本。当NMB=0时,表示新方法相对于标准方法没有多余的效益;当NMB>0时,表示新方法相对于标准方法是具有成本效果的。与普通的Bayesian方法(只考虑单一的先验信息)不同,这里在分析阶段和设计阶段分别考虑了不同的先验信息。
(1)分析阶段
在分析阶段,如果获得数据的后验概率至少为ω使得NMB>0,那么我们可以认为研究结果是阳性的,即新方法是具有成本效果的。ω的含义和传统假设检验中的1-α非常类似,在Bayesian分析中,当先验概率很弱时,其结果和传统频率理论得到的结果是相等的,此时ω=1-α。频率方法中降低水平可以使结论更严格,同样地,Bayesian方法中也可通过提高ω的值使得结论更加严格。
(2)设计阶段
在设计阶段,我们需要每组有充足的样本量(n1和n2)使得阳性结果出现的概率至少为δ,即P(NMB>0)>δ。δ与频率理论中的检验效能相似,但又有所不同。频率理论中,我们假定一个真实的NMB,然后计算样本NMB大于等于假定值的概率即为检验效能。而Bayesian方法中,我们假定NMB的先验分布,然后计算先验分布下的平均检验效能即为。如果设计阶段NMB有很强的先验分布,那么NMB可以取一个特定值NMB0。另一方面,如果设计阶段的先验信息很弱,那么NMB将很可能为正向的极端值或负向的极端值,致使无法求得合适的样本量。因此,设计阶段NMB应有适当的先验分布。
该方法假设样本成本和效果数据服从联合正态分布,虽然个体观测值不服从正态分布,但是根据中心极限定理,当样本足够大时将会接近正态分布。同时,假设先验分布也服从正态分布。
2.模型求解
根据分析阶段的目的,获得阳性结果需要满足如下不等式:
(2)

(3)
(4)
其中,ρ1和ρ2分别表示每组效果与成本的相关系数,n1和n2分别表示两组的样本量,σ1与σ2表示两组效果的标准差,τ1与τ2表示两组成本的标准差。
在设计阶段,我们需要选择两组合适的样本量使得能够以δ的概率满足公式(2)。因此,综合考虑分析阶段和设计阶段的先验分布,公式(2)变为:
(5)

(6)
② 当分析阶段的先验信息很弱,设计阶段有适当的先验信息时;③ 普通的Bayesian试验设计方法,其中ma=md,Va=Vd。后面的实例分析将针对这三种类型逐一分析。
3.SAS程序
通过SAS的IML模块实现上文公式(5)的样本量估计,以下是SAS程序以及样本量估计时所需的参数解释。输入分析阶段和设计阶段的先验期望及方差、样本标准差、成本与效果的相关系数、组间样本量的比值、意愿支付界值、omega和delta即可得到最小组的样本量估计值。其中omega和delta为公式(5)中的ω和δ。
%letm_analysis={5,6000,6.5,7200};/*分析阶段的期望值,依次为第一组效果、第一组成本、第二组效果和第二组成本*/
%letm_design={5,6000,6.5,7200};/*设计阶段的期望值,向量元素含义同上*/
%letv_analysis=.;/*分析阶段的方差矩阵,如果分析其逆为0的情况则赋值为缺省值“.”,反之赋值为相应的方差矩阵即可*/
%letv_design={4 0 3 0,0 10000000 0 0,3 0 4 0,0 0 0 10000000};/*设计阶段的方差矩阵*/
%letsd={4.04,8700,4.04,8700};/*样本标准差,依次为第一组效果、第一组成本、第二组效果和第二组成本*/
%letp={0,0};/*依次为第一组和第二组中成本与效果的相关系数*/
%letr=1;/*第二组与第一组样本量的比值,如n1∶n2=1∶2,则r=2,此时得到的是较小组的样本量*/
%letk=10000;/*意愿支付界值*/
%letomega=0.975;/*取得阳性结果的后验概率,*/
%letdelta=0.7;
prociml;
va=&v_analysis;
ifva=.thenva_inv=0;
elseva_inv=inv(va);
a={-&k,1,&k,-1};
sigma1=&sd[1]##2;
sigma2=&sd[3]##2;
tau1=&sd[2]##2;
tau2=&sd[4]##2;
s=j(4,4,0);/*样本方差矩阵*/
s[1,1]=sigma1/i;
s[1,2]=&p[1]#&sd[1]#&sd[2]/i;
s[2,1]=&p[1]#&sd[1]#&sd[2]/i;
s[2,2]=tau1/i;
s[3,3]=sigma2/(&r#i);
s[3,4]=&p[2]#&sd[3]#&sd[4]/(&r#i);
s[4,3]=&p[2]#&sd[3]#&sd[4]/(&r#i);
s[4,4]=tau2/(&r#i);
vv=inv(va_inv+inv(s));/*后验方差矩阵*/
left=t(a)*vv*(va_inv*&m_analysis+inv(s)*&m_design);/*不等式左边*/
right1=abs(quantile(“normal”,1-&omega))#sqrt(t(a)*vv*a);/*不等式右边第一项*/
right2=abs(quantile(“normal”,1-&delta))#sqrt(t(a)*vv*inv(s)*(&v_design+s)*inv(s)*vv*a);
index=left-right1-right2;/*不等式右边第二项*/
ifindex>=0thenstop;/*不等式成立则停止迭代*/
end;
printi;/*最小组所需的样本量*/
quit;
实例分析
利用上文的SAS程序分析常见的分析阶段和设计阶段三种不同的先验信息组合下样本量的估计。为了便于比较,本文引用与O′HaganA[1]相同的例子,Briggs和Tambour[11]也利用频率方法分析过这个例子。
1.分析阶段先验信息弱,设计阶段先验信息强
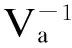
表中给出了不同效应量(1.5和0.8)、不同相关系数(0、0.5和-0.5)以及不同意愿支付界值(10000、20000和30000)下的样本量估计结果。可见效应量较大时需要的样本量相对较小,这与公式(5)一致。不等式左边为两个先验期望值的加权,效应量越大左边越大,不等式越容易成立。再者,效果与成本的相关系数也会对样本量的估计结果产生影响,从表中可以看出相关系数正向越大所需样本量越小,反之,负向越大所需样本量越大,这与ALMJ[6]在文中的结论一致。此外,随着意愿支付界值的升高,所需样本量越小。

表1 分析阶段先验信息弱,设计阶段先验信息强时样本量估计结果
2.分析阶段先验信息弱,设计阶段先验信息适当

样本量估计结果见表2。
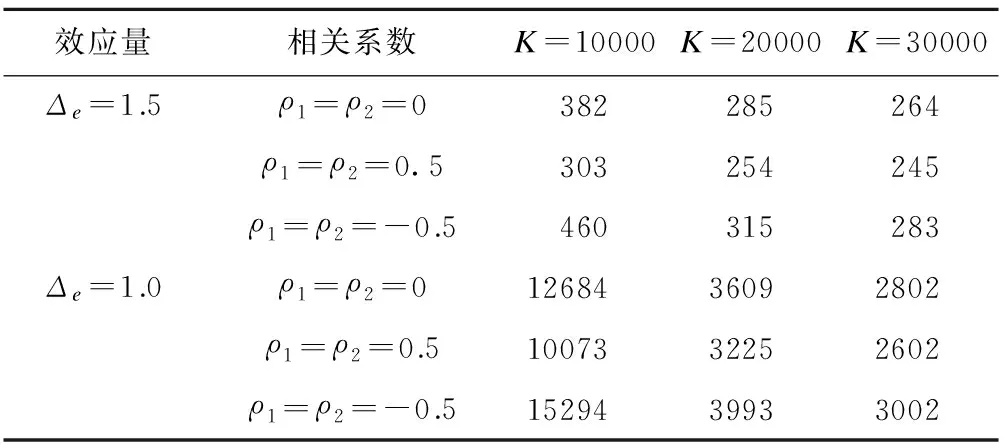
表2 分析阶段先验信息弱,设计阶段先验信息适当时样本量估计结果
与情形①不同的是效应量大小的设置。效应量为0.8时超出了迭代算法中设置的最大样本量(N=100000),现实情况下不具有操作性,故表2给出了效应量分别为1.5和1.0时的样本量估计结果。与表1的结果相比,相同参数条件下表2中所需的样本量相对较大,原因是情形①中设计阶段的先验信息非常强。先验信息越强,所需样本量相对越小。其他参数之间的规律与情形①保持一致。
3.分析阶段和设计阶段先验信息相等
本例中,我们假设分析阶段和设计阶段都有适当的先验信息,且相等。即,ma=md,Va=Vd取值情况与情形②相同。其中,考虑到效应量等于0.8时的不可操作性本例也给出了1.5和1.0两种情况下的结果。此时,样本量的估计结果见表3。
与表2的结果相比可以看出,相同参数条件下,分析阶段有适当的先验信息也可以减少所需要的样本量。其他参数之间的规律与情形①保持一致。

表3 分析阶段和设计阶段先验信息相等时样本量估计结果
讨 论
卫生经济学评价中样本量的估计方法包括频率方法和Bayesian方法,Bayesian方法的优势是可以看到分析阶段和设计阶段不同先验信息对样本量估计的重要性。而且,Bayesian方法还可以包含频率方法,并求得相等的样本量,这也体现了该方法的灵活性。近二十年成本效果分析的方法学日益发展,但是应用方面样本量的计算受到很大限制,很大程度上是由于没有专用的统计软件或便利的程序实现。为了弥补该领域发展的不足,本文基于O′Hagan A等人的文章[1]给出了Bayesian方法的SAS实现。用SAS编写成宏,只需要输入所需参数就可以得到样本量的估计结果。
本文只给出了平行设计中Bayesian方法的样本量估计,后续将考虑不同试验设计下的样本量估计方法,如配对设计、交叉设计等。
[1]O′Hagan A,Stevens JW.Bayesian assessment of sample size for clinical trials of cost-effectiveness.Medical Decision Making,2001,21(6):219-230.
[2]Australia Commonwealth Department of Human Services and Health.Guidelines for the Pharmaceutical Industry on Preparation of Submissions to the Pharmaceutical Benefits Advisory Committee:Including Major Submissions Involving Economic Analysis.Canberra:Australia Government Publishing Service,1995.
[3]Canadian Coordinating Office for Health Technology Assessment.Guidelines for Economic Evaluation of Pharmaceuticals:Canada(2nd ed).Ottawa:Canadian Coordinating Office for Health Technology Assessment,1997.
[4]Ramsey SD,Willke RJ,Briggs AH,et al.Good research practices for cost effectiveness analysis alongside clinical trials:the ISPOR RCT-CEA Task Force report.Value in Health,2005,8(5):521-33.
[5]Ramsey SD,Willke RJ,Glick H,et al.Cost-Effectiveness Analysis Alongside Clinical Trials II-An ISPOR Good Research Practices Task Force Report.Value in Health,2015,18(2):161-172.
[6]AL MJ,Van Hout BA.Michel BC,et al.Sample size calculation in economic evaluations,Health Economics,1998,7(4):327-335.
[7]Laska EM,Meisner M,Siegel C.Power and sample size in cost-effectiveness analysis,Medical Decision Making,1999,19(3):339-343.
[8]Willan AR,O′Brien BJ.Sample size and power issues in estimating incremental cost-effectiveness ratios from clinical trials data.Health Economics,1999,8(3):203-211.
[9]Gafni A,Walter SD,Birch S,et al.An opportunity cost approach to sample size calculation in cost-effectiveness analysis.Health Economics,2008,17(1):99-107.
[10]O′Hagan A,Stevens JW,Montmartin J.Bayesian cost-effectiveness analysis from clinical trial data.Statistics in Medicine,2001,20(5):733-753.
[11]Briggs A,Tambour M.The design and analysis of stochastic cost-effectiveness studies for the evaluation of health care interventions.Drug Information Journal,2001,35(4):1455-1468.
(责任编辑:邓妍)
陈平雁,Email:chenpy99@126.com
=10to100000;/*设定迭代过程的初始值和最大值*/
猜你喜欢
中国卫生统计(2022年2期)2022-05-28
内蒙古统计(2021年4期)2021-12-06
陕西理工大学学报(自然科学版)(2021年3期)2021-06-23
中州建设(2020年5期)2020-12-02
中华建设(2019年3期)2019-07-24
中国卫生统计(2019年3期)2019-07-10
中国卫生统计(2019年3期)2019-07-10
自动化学报(2017年5期)2017-05-14
探测与控制学报(2015年4期)2015-12-15
中国工程咨询(2014年1期)2014-02-16
