
第六讲均匀设计应用案例解读
2016-11-29 04:54徐静安彭东辉
上海化工 2016年10期
徐静安 彭东辉
技术讲坛
第六讲均匀设计应用案例解读
徐静安彭东辉
案例取自《正交与试验设计》2001版。在专业知识指导下,选定考察的变量因子及其范围,那么如何合理选择均匀设计表?如何安排变量水平?如何正确控制、记录实验条件?......如何进行中心化变换回归建模?如何追加、拓展实验?
自2013年以来,笔者有幸对吴向阳、彭东辉两位教授带教的在读研究生的研究课题以及该专业组从事的超导基带表面电化学精饰研究、甲醇汽油防腐蚀研究有过长期的接触,几乎每周都有讨论、沟通。彭东辉教授及其专业组成员积极学习、应用均匀设计等数理统计知识及数据处理技术,在研发工作中已经取得了初步成绩,涉及该案例的若干知识点,也得到了有效的应用。为此,我们合作进行本案例的解读。
案例:在某化工的合成工艺中,为了提高产量,试验者选了3个因素:原料配比(x1),某有机物的吡啶量(x2)和反应时间(x3),每个因素均选取了7个水平:
原料配比(%):1.0,1.4,1.8,2.2,2.6,3.0,3.4
吡啶量(mL):10,13,16,19,23,,25,28
反应时间(h):0.5,I.0,1.5,2.0,2.5,3.0,3.5
选用均匀设计U7(73)见表1,实验结果见表2。

表1 U7(73)
在作回归建模时,将自变量中心化。
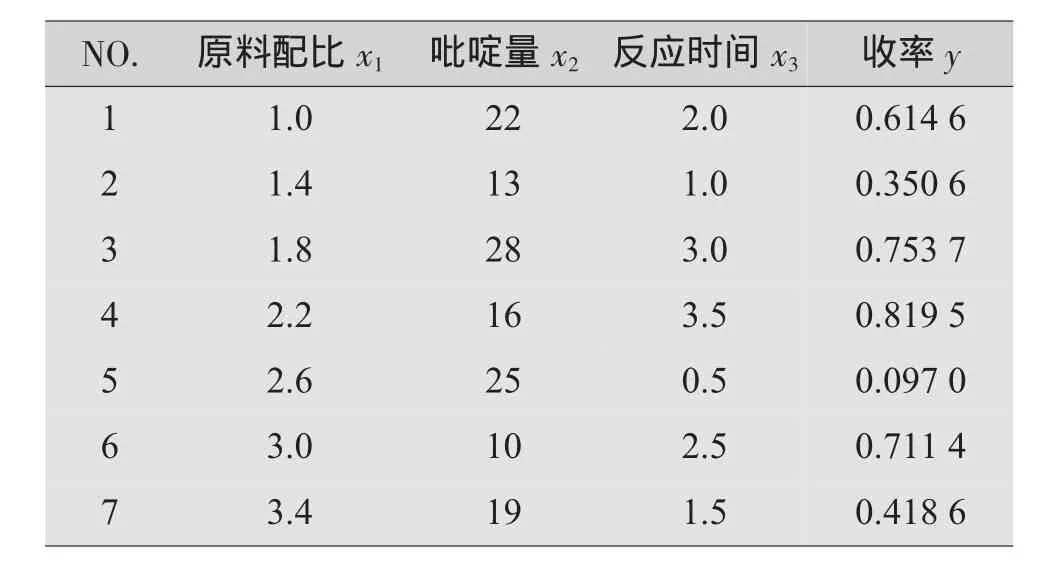
表2 化工试验方案和相应收率
考虑二次模型

运用筛选变量的回归技术,得

统计模型的方差分析见表3。
y的极大值不难求得,当x1=3.4,x3=3.5时,y=91. 87%达到极大值。在x1=3.4,x2=19,x3=3.5追加了3次试验,相应的收率分别为91.05%,92.11%,91.53%,其均值91.56%与预报值相距很近,因此模型比较符合实际情形。
1 关于变量水平值的排列
变量水平值应该按单调增或单调减排列。该案例水平值采用单调增排列,如原料配比%,水平值1.0,1.4,1.8,......3.4。不能随意地1.0,1.8,1.4,...... 3.4,把1.8作为2水平放在1水平1.0和3水平1.4之间。这样安排将增加均匀设计表的不均匀性D值,影响模型的稳定性。
2 关于变量水平间的步长
变量水平间可以采用等步长,也可以采用不等步长。在专业知识及探索试验指导下,变化剧烈的区域步长小,平稳区域步长大,对建模更有利。

表3 化工试验的方差分析表(SAS输出)
3 关于水平值的设定和实际操作的偏差
均匀设计变量的每个水平只做一次实验,所以具体实验时要如实记录实验时的水平值。如表2第3号实验x3设计反应时间为3.0 h,由于种种原因它只要在前后步长的1/2范围内波动,就如实记录。即实际操作是3.1 h,记录并用于统计建模,反而能减少误差。这对反应温度、压力、微量滴加等难以控制的场合很有实际应用意义。
4 关于均匀设计表的选择
由于该案例应用在20世纪90年代,均匀设计法还处于不断完善阶段。按现在的观点,尽量选用带*号的均匀设计表。见表4~7。

表4 U7(74)
表5 U7(74)的使用表

因素数列号D 2 1 3 0 . 2 3 9 8 3 1 2 3 0 . 3 7 2 1 4 1 2 3 4 0 . 4 7 6 0
每张均匀设计表都配有相应的使用表。从表4的U7(74)安排考察3个因素。不均匀性D=0.372 1;表6的(74)考察3个因素。不均匀性D=0.213 2。我们应选用带*号、且D≤0.3的均匀设计表。
表6 (74)
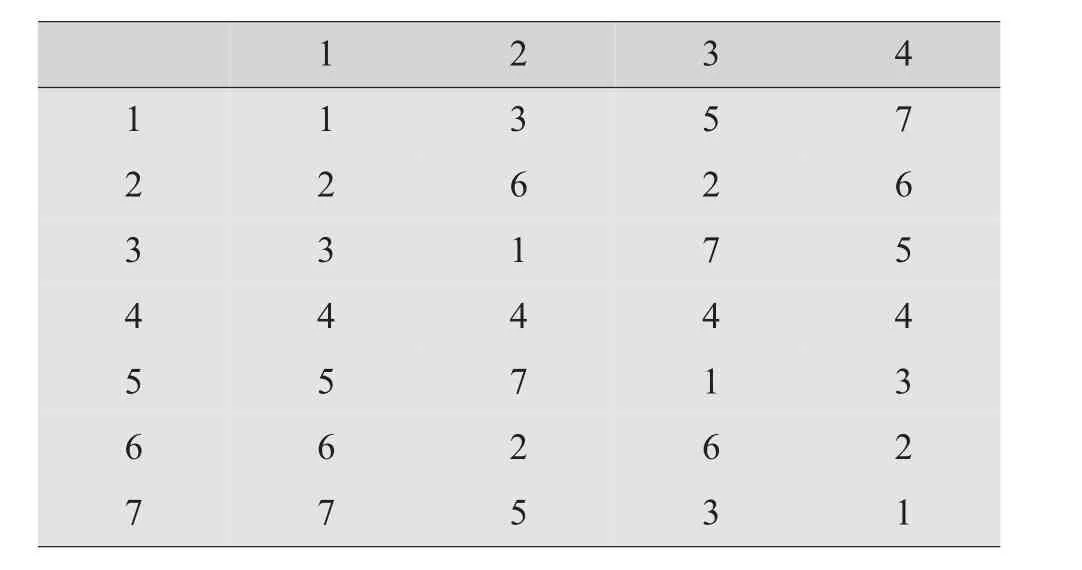
表6 (74)
1 2 3 4 1 1 3 5 7 2 2 6 2 6 3 3 1 7 5 4 4 4 4 4 5 5 7 1 3 6 6 2 6 2 7 7 5 3 1
表7 (74)的使用表
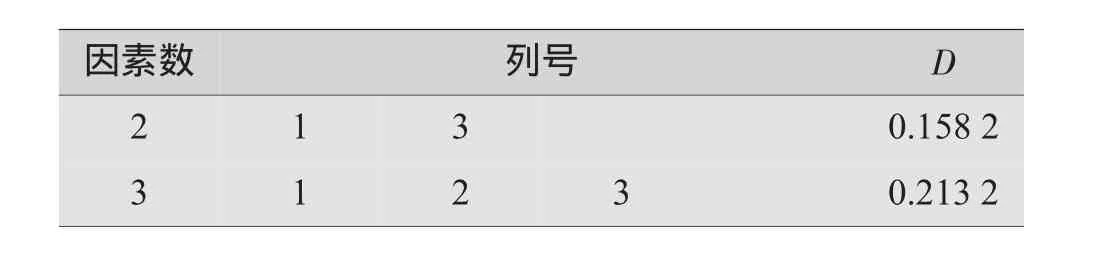
表7 (74)的使用表
因素数列号D 2 1 3 0 . 1 5 8 2 3 1 2 3 0 . 2 1 3 2
5 关于均匀设计表实验次数的选择
在试验设计时,需考察的变量因子相对刚性,而水平数通过改变间隔步长则相对弹性。由于受变量范围及仪表控制精度限制,各变量水平数不同的混合均匀设计,另行讨论。
本文案例是变量等水平的案例。因为均匀设计的变量水平数决定了实验次数,针对案例考察了3个变量可供选择的均匀设计方案,有(64)表、(74)表以及(85)表等,表8~9为(85)及其使用表。
笔者推广应用的体会:
(1)如果新的研究领域、新的实验平台、选试验次数大一些的均匀表,不致于某一次实验误差,对统计建模影响的太大;
(2)做过单因素考察的探索实验,可选用小一些的均匀表;
(3)本文案例考察变量数m=3,用二次多项式拟合建模:
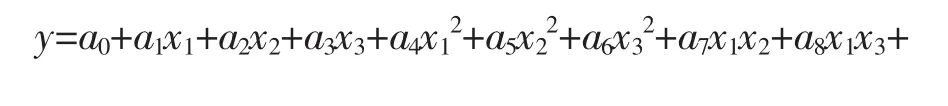
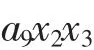
表8 (85)
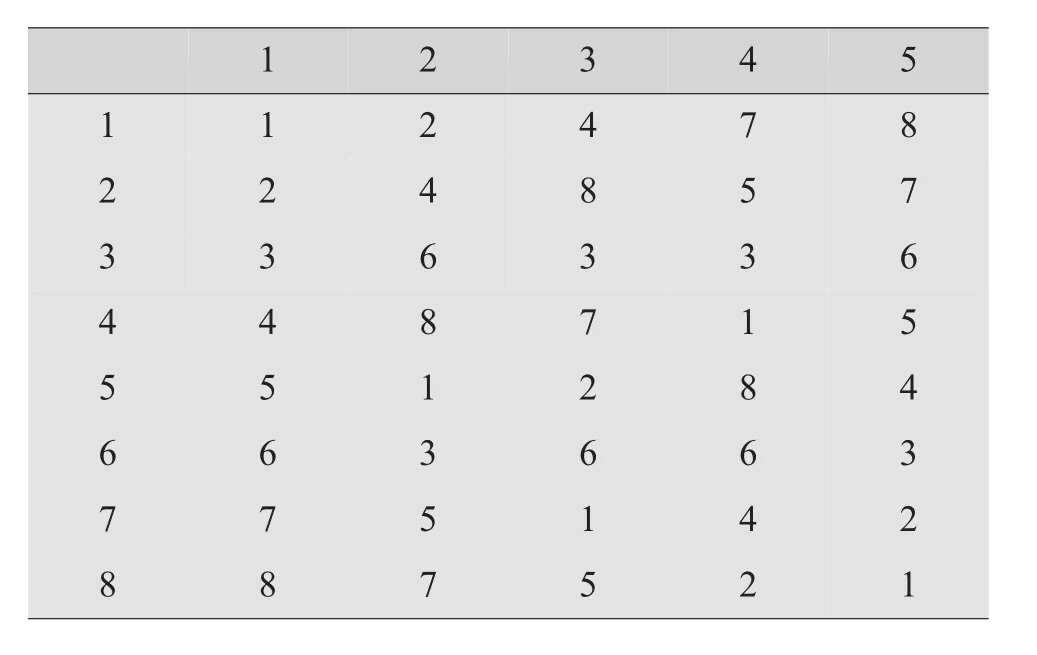
表8 (85)
1 2 3 4 5 1 1 2 4 7 8 2 2 4 8 5 7 3 3 6 3 3 6 4 4 8 7 1 5 5 5 1 2 8 4 6 6 3 6 6 3 7 7 5 1 4 2 8 8 7 5 2 1
表9 (85)的使用表

表9 (85)的使用表
因素数列号D 2 1 3 0 . 1 4 4 5 3 1 3 4 0 . 2 0 0 0 4 1 2 3 5 0 . 2 7 0 9
回归方程可能形成9项变量,一般估计通过逐步回归有1/3~1/2显著变量项进入模型,即模型显著变量项可能占有自由度的3~5。大家知道,F检验误差自由度为1是不敏感的,希望误差自由度≥2~3。这样就要求选用的均匀设计表有5~8个自由度。而均匀设计表的自由度是f=实验次数N-1。所以要选用实验次数大一些的均匀表。综上分析,从应用角度建议选择均匀表实验次数N=2~2.5m。
6 关于随机化方法决定实验次序
由于化工实验可能存在时间周期长,随着时间延续,环境温度、湿度升高或降低;高压气体钢瓶使用中气体含H2O量增加;实验原料轻度氧化;配制溶液少量沉淀;陈化时间拉长;菌种有可能退化......。
均匀设计表中往往有第一列变量因子水平排列和序号是一致的,有的表还有最后一列的排列是完全相反的。如本文案例表2,按试验的自然序号进行实验,自然序号与x1水平序号相同,上述讨论的“随着时间延续,环境温度、湿度升高或降低;高压气体钢瓶使用中气体含H2O量增加;实验原料轻度氧化;配制溶液少量沉淀;陈化时间拉长;菌种有可能退化......”都会混杂到x1变量因子中去,因此使分析失真。
表10 (94)
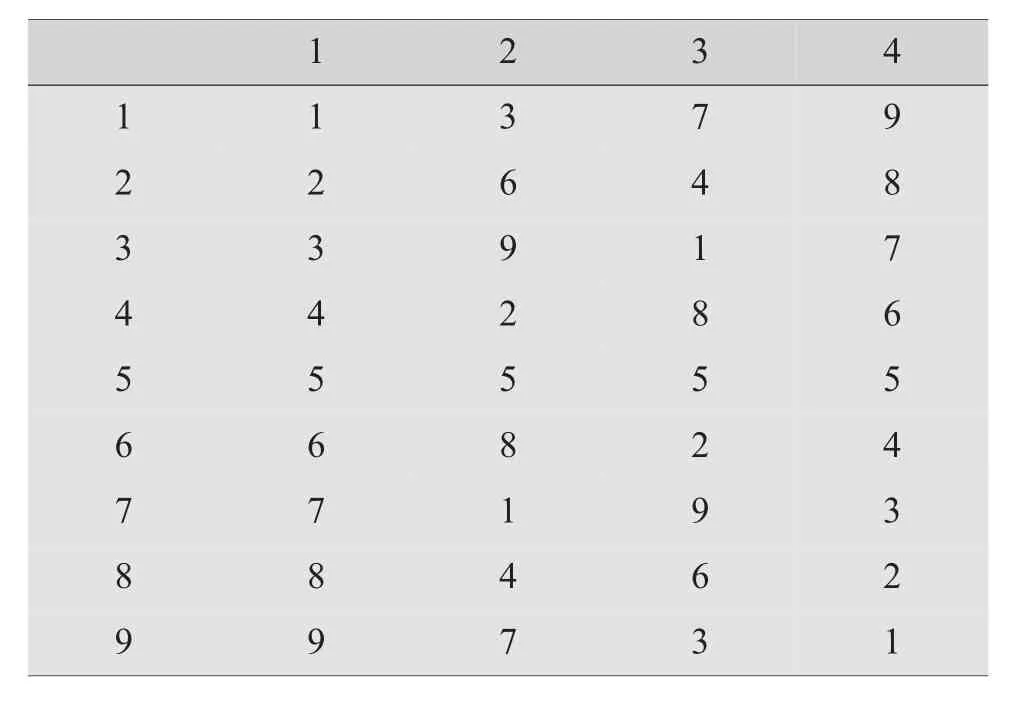
表10 (94)
1 2 3 4 1 1 3 7 9 2 2 6 4 8 3 3 9 1 7 4 4 2 8 6 5 5 5 5 5 6 6 8 2 4 7 7 1 9 3 8 8 4 6 2 9 9 7 3 1
表11 (94)的使用表

表11 (94)的使用表
因素数列号D 2 1 3 0 . 1 5 8 2 3 1 2 3 0 . 2 1 3 2
7 关于直观分析实验结果
本案例表2以第4号实验收率y=81.95%为最高。由于均匀设计在研究考察的多维空间范围内,代表性地均匀布点,一般会出现接近研究期望的“好点”。再通过回归分析处理数据,寻求优化点。如果没有出现接近研究期望的“好点”,就要从专业上重新审查所选变量因子及其范围的合理性。
8 关于回归分析
均匀设计的数据处理需要采用回归分析。回归分析时,为什么常常采用二次多项式拟合?如何采用逐步回归筛选变量?如何评价回归模型统计上的显著性?由于篇幅关系,在此不再展开,请阅读本刊2016年第5期刊登的第一讲——统计模型的假定和变量水平的设定;2016年第8期刊登的第四讲——回归分析中的变量筛选技术及统计检验。
9 关于自变量中心化处理
在二次多项式拟合时,一些著作均提出要对自变量进行中心化处理,但在同一本著作的其他案例中没有进行中心化处理,亦取得较好的统计建模效果。笔者从应用角度理解,在自变量数据中心化处理后有利于提高矩阵运算的计算精度,有利于提高统计模型的预报稳定性。针对本文案例,李志刚硕士研究生用DPS软件进行自变量非中心化、中心化处理的对照计算分析。
(1)非中心化计算
计算用数据,见表2。
结果见表12。
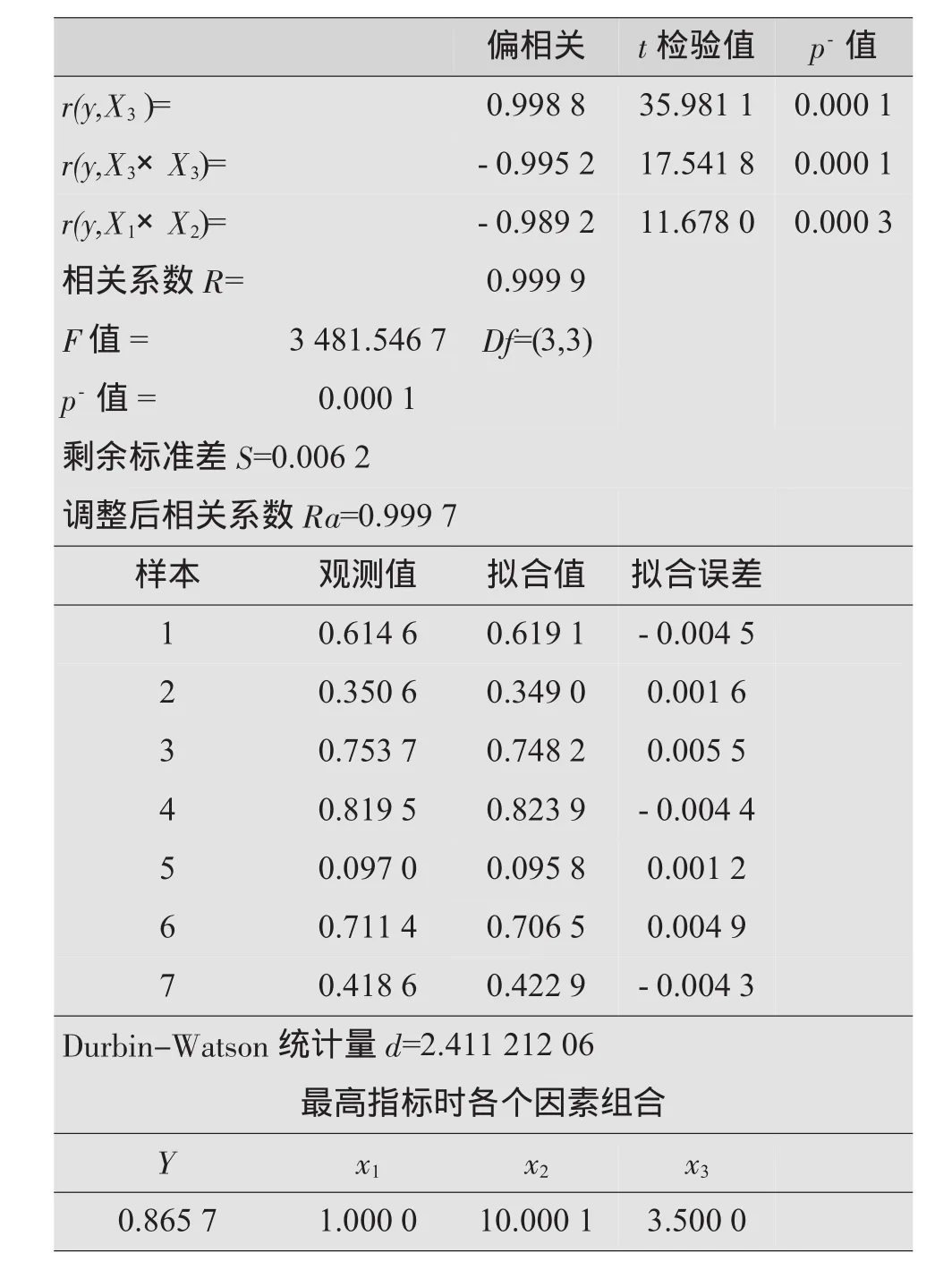
表12 非中心化计算结果

(2)中心化计算
计算用数据,见表13。
结果见表14。

上述非中心化,中心化计算结果表明,均通过回归分析各项统计检验,具有显著性意义。也就是说,对同一批研究数据,自变量的非中心化、中心化处理回归模型的拟合效果都不错,甚至非中心化的某些统计指标稍好些。上述中心化变换案例用SAS软件计算,本文用DPS软件计算,结果完全一致。

表13 中心化计算用数据
非中心化计算和中心化计算的最大差异,一是统计模型的构成,非中心化计算进入模型的交互作用项为x1x2;中心化进入模型的交互作用项为x1x3。二是由此引起的最高指标时各个因素组合及y有明显不同,非中心化计算预报优化值y=86.57%,而中心化计算预报优化值y=91.95%。也就是两种计算拟合效果均有统计上显著意义的基础上,非中心化计算可能丢失预报更优的优化点信息,值得引起重视。
从回归分析计算角度,及本案例中心化计算优化点预报被验证实验验证说明,二次多项式回归的自变量中心化变换是科学、合理的。
10 关于回归模型的残差诊断
回归模型的残差分析现在受到了重视,限于本文篇幅,可查阅相关著作,如《六西格码管理统计指南——MINITAB使用指导》。
11 关于不显著变量的分析
原文案例采用自变量中心化变换进行二次多项式统计建模,模型中没有出现x2,即统计检验不显著。从专业角度,吡啶是许多有机物的优良溶剂,并能溶解许多无机盐类,是一些有机反应的常用溶剂。但其蒸汽与空气混合物的爆炸极限为1.8%~12.4%(体积)。x2统计检验不显著,没有进入y=F(x)的统计模型,并非y和x2无关,而是表示x2在实验范围内10~28mL内,对收率y的影响不显著,在实验范围内可随机取值。
12 关于验证实验
对于工程型研究,对选定的“好点”或推荐的优化点,进行验证实验这是很重要的研究环节。原文案例自变量中心化变换统计建模后,推荐预报的优化工艺组合,经过三次重复验证实验,平均值为91.56%。验证试验三次比较规范。
原文案例认为:“其均值91.56%与预报值相距很近,故模型比较符合实际情形”。那么预报值和验证值二者“相距很近”如何判断呢?
按数理统计要求,验证值在预报值±2.5S范围内,属于“相距很近”,正常。也有文章报道,按不同专业的要求,验证值和预报值相对偏差控制在约5%。
现在问题又转化到如果验证实验和预报值“相距甚远”,不符合“相距很近”又怎么办呢?重新安排实验,废掉已做的实验,工作量不小。考虑其他模型又缺乏“好点”方向。
相关资料未作展开讨论。按笔者推广应用中实践体会,模型具有学习、修正的潜力。具体操作方法是把验证实验作为NO.8组实验和案例(74)7组数据一起,进行回归建模,产生新的优化预报值,再进行验证。序贯进行,修正2~3次就能得到期望的结果,如果仍然“相距甚远”,则需要从专业上,实验平台、实验设计及数据处理上重新审查研究工作。
由于计算机和数据处理软件的普及,对于预报值和验证值“相距很近”,验证通过的案例,笔者建议把验证实验作为NO.8组实验,对原统计模型作进一步完善。DPS软件计算用数据见表15,结果见表16。

表15 DPS软件计算用数据
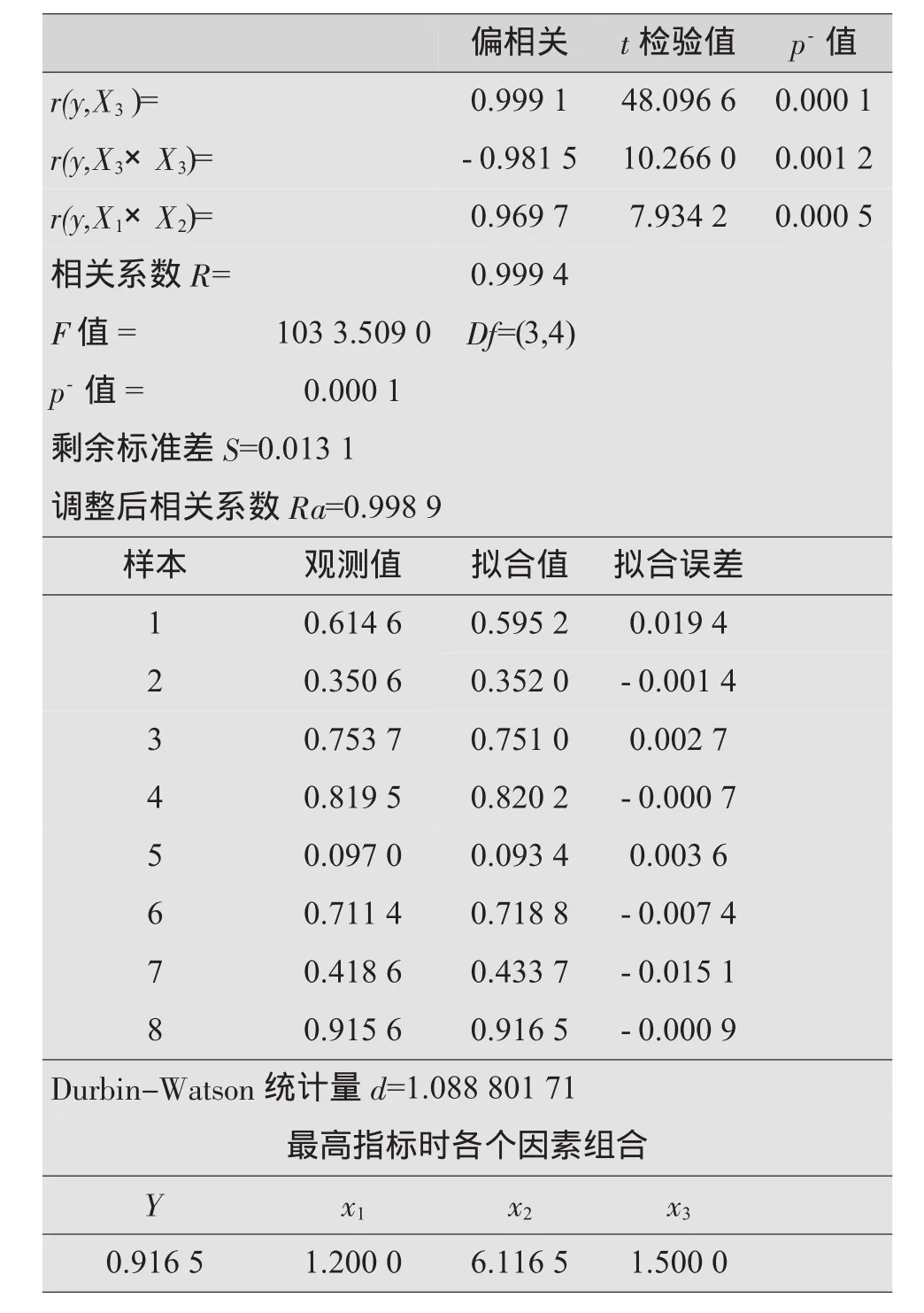
表16 DPS软件计算结果

计算结果表明,统计模型得到了完善,预报指标稳定。
13 关于追加实验
在一轮试验设计和数据处理后,有多种情况需要追加试验。本文仅结合案例解读进行追加实验的方案。
原文案例通过对统计建模判断x1、x3优化点已在实验范围界面,需界面拓展,追加实验,探索更优空间。其实对多因素统计模型预报最高指标时,已给出实验范围界面值,由此可作判断。
原文案例对x1、x3界面拓展,追加试验,建议选用U4(42)均匀表。一则在均匀设计不能推荐此类小表,不均匀性D值较大。最主要的问题是追加实验的数据不能和原设计U7(73)的数据一起统计建模,数据利用率不高。
笔者建议在原设计的基础上,引入序贯设计概念进行界面拓展,追加实验。结合本案例,设计操作如表17所示。即把x1、x3界面拓展的水平值填入原设计表NO.4、NO.7的空白处,仍保持试验设计的均匀性。作为追加的实验条件,所得结果为NO.8、NO. 9,可以和原U7(73)数据一起统计建模。
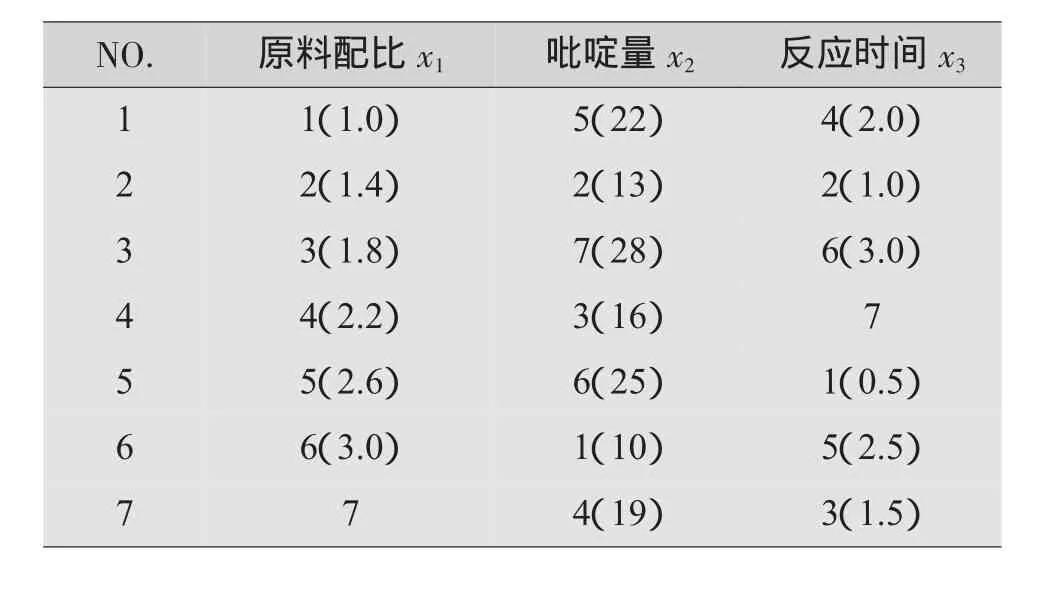
表17 设计操作数据
推广应用的实践证明,此拓展方法尽管专著中没有展开讨论,但实际应用效率很高,效果很好。
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
少先队活动(2021年2期)2021-03-29
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
中学生数理化(高中版.高二数学)(2019年6期)2019-06-24
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
中国公路(2017年7期)2017-07-24
中国卫生(2015年4期)2015-11-08
河北科技大学学报(2015年5期)2015-03-11
电测与仪表(2014年2期)2014-04-04
