
基于随机森林的网络攻击检测方法
2016-12-15 02:47王浩
软件 2016年11期
王 浩
(北方工业大学计算机学院,北京 100144)
基于随机森林的网络攻击检测方法
王 浩
(北方工业大学计算机学院,北京 100144)
网络攻击检测是网络领域的一个重要的应用,目前在这领域内的检测方法有很多,但是已有的检测机制存在着错误率高以及无法处理数据不平衡等问题。通过分析网络攻击数据,设计了基于随机森林的网络入侵检测算法,并把这个算法用于网络连接信息数据的检测和异常发现。通过对CUP99数据的测试集进行试验,基于随机森林的算法能够提高识别效率,有效的解决数据不平衡带来的问题,具有很好的分类效果。
攻击检测;数据不平衡;随机森林;CUP99
本文著录格式:王浩. 基于随机森林的网络攻击检测方法[J]. 软件,2016,37(11):60-63
0 引言
网络攻击检测是维持一个系统安全非常重要的一方面。网络攻击检测的目的就是要发现网络中的异常数据,维持系统的完整性,机密性和资源的可用性[1]。在信息化时代,攻击检测是对网络数据的分析来找出入侵的数据,也就是那些未经允许的连接访问,试图去破坏或者恶意使用信息资源的行为。
目前的入侵检测分为两类:误用检测和异常检测。误用检测是事先对已经获取的入侵数据进行分析,提取其中的攻击规则和模式,然后在检测的过程中将新的数据与已有的攻击规则和模式进行匹配,如果匹配,则说明发生了攻击行为。异常检测是检测数据与正常情况下数据的相似度,如果不符合以往正常情况下的数据行为,那么可以认为发生了攻击行为[2]。异常检测不仅能够发现已知的攻击行为,也能发现未知的攻击行为。
到目前未知,学术界出现了很多检测网络攻击的方法,有运用概率来计算的方法[3],基于数据挖掘方法[4],基于人工神经网络的方法[5],以模糊数学为理论的方法[6]等,但是通过单一的方法构建分类器,在准确率上存在缺陷,精度无法保证正常的使用,并且容易出现过拟合的问题。为了解决单一分类器存在的问题,许多学者提出了集成方法,通过组合多个分类器来提高检测的精度。目前使用最多的就是bagging和boosting的方法。Bagging采用自助采样(bootstrap)对训练集进行抽样,每个个体分类器所采用的训练样本都是从训练集中按等概率抽取的,因此Bagging的各子网能够很好的覆盖训练样本空间,从而有着良好的稳定性。Boosting方法中,基分类器串行工作,后续的单分类器着重对前面的错误分类样本进行处理,直到得到一个准确
率比较高的分类器组合,由于Boosting算法可能会将噪声样本或分类边界样本的权重过分累积,因此Boosting很不稳定。
随机森林算法(RFA)[7]由Leo Breiman第一次在2001年的文章中提出,它是Bagging的一个扩展的变体。随机森林以决策树为基学习器来构建Bagging集成,并且在决策树的训练过程中引入了随机属性的选择。由于出色的分类效果,随机森林已经在诸多领域得到了应用。本文在第二节中详细介绍了随机森林算法的具体过程。第三节针对cup99数据集多分类情况下的数据不平衡问题,将sampling的处理进行改进,并应用到随机森林算法得到检测网络入侵的模型并进行交叉验证。
1 随机森林算法
1.1 采样过程
随机森林中采用自助采样(bootstrap sampling)[8]的方法,给定包含m个样本的数据集D,随机从中选取一个样本,然后再将此样本放回,下次采样的时候可能再次取得此样本。这样有放回的取m次后,我们得到包含跟原样本数量一致的数据集,在此数据集中一些样本可能会重复出现,可以做一个估计,大约有的样本在所有的采样中都没有被采到,取极限可以得到,自助采样使得原始数据集中36.8%的数据没有出现在采样后的数据集,这样我们可以使用数量为m的采样数据集来进行训练,同时其中有大约1/3的数据来进行测试,通常称这种测试为“包外估计”(out-ofbag estimate)。
1.2 Bagging算法
Baggin[9]是一种并行式的集成算法。通过多次的采样过程,我们得到了T个含有m个样本的数据集,针对每一个数据集,训练出一个基学习器模型,通过投票的方式选出最佳的投票结果,这可以当做是最终预测的类别。每个基学习器都是弱学习算法,但是投票后的准确率将得到大幅度提高。如果出现投票一致的情况,最简单的方式是随机选取一个,也可以选用置信度来决定最终的结果。本文主要在数据的预处理阶段进行bagging,下一节可以看到在此阶段的优化过程。Bagging的算法描述如下:
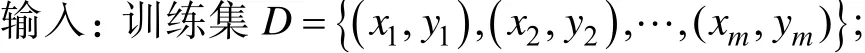

假定基学习器的算法复杂度为O(m),则bagging的算法复杂度为T(O(m))+O(s),其中O(s)为投票过程的复杂度,由于相比O(m)小很多故可以忽略,因此算法的复杂度维持在O(m)的水平上,是一个比较高效的算法。
通过自助采样,我们得到的训练集只有原数据集D的63.2%的样本,剩余的36.8%的数据集可以用作包外估计[10]。令Dt(x)为训练集,Hoob(x)为包外估计的预测,并且仅使用D-Dt(x)的数据来进行估计,则
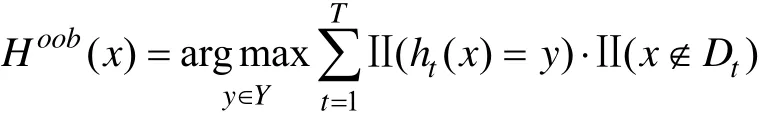
泛化误差为:

1.3 随机森林算法
随机森林[7]算法是以bagging算法为基础,加入了特征上的随机性。算法以决策树为基训练器,在决策树的训练过程中加入了特征上的随机选择。
首先,按照自助采样的方式取得与原数据集数量一致的m个样本作为训练集,假定当前一共有d个特征属性,对于每一个决策树,随机选取k<d个属性作为单个决策树的特征集合。对于每个基学习器,即单棵决策树,在k个属性中寻找能够在训练集中表现最优的属性进行分裂。参数k控制了特征的随机性,k=d时跟普通的决策树一样,k=1时是随机选取一个属性,建议选择k=log2d[7]。
新数据获取后,将数据带入训练好的森林模型中,预测基于每一棵决策树的预测结果,通常有多种方式可以进行投票。假定单棵树hi要对多类别进行预测,我们将hi在样本x的预测表示为一个N维向量其中代表h在c类别上的预测值,投票法的表示为ij
2 在网络攻击检测中应用随机森林算法
网络攻击检测的目的是识别网络中的异常流量,从而及时的发现攻击行为,针对流量的特征,分析出攻击的方式,进而采取对应的解决方案。目前大多数的异常流量检测是基于规则的识别技术,下面提出使用随机森林的方法来识别,这种方式和基于规则的方法相比,可以减少专家的参与,避免随着网络复杂度的升级而造成的规则的爆炸性增长。同基于聚类的方法相比,树类型的算法在性能上有着明显的优势,在不需要进行向量相似性对比的情况下就能检测出攻击类型。
2.1 数据采集与分析
数据来源于网络,需要网络设备在网络连接过程中采集网络数据包的特性,每个样本描述一个阶段内的数据包属性。包括协议类型,连接长度,源到目的的数据字节数,目的到源的数据字节数,错误段的数量,连接的状态等等。在这里我们选用KDD CUP99数据集作为训练数据集,该数据集取自真是的网络环境,是美国国防部为了进行入侵检测研究而收集的数据集,是学术界关于攻击检测用的最多的数据集。它包含了500多万的连接数据,训练集囊括了主流的23种攻击行为,除了一些基本的属性,例如持续时间、协议类型、传输的字节数等,还添加了2 s内时间窗的统计属性,统计和当前连接有相同目的主机的连接特征以及有相同服务的主机的连接特征.
2.2 数据预处理
我们取用cup99的10%的数据集,为了适应随机森林算法,需要对数据集进行预处理。首先需要对字符属性进行转换,转换成数字格式。其次需要对回归属性值进行离散化,由于随机森林是基于树的算法,而ID3只支持离散型变量,C4.5和CART不适合23种类别的分类的问题,故需要手动进行离散化。
同时,我们观察数据可以发现,数据集存在着严重的不平衡问题,现在关于数据集的不平衡性的研究中,主要从数据集和算法两个方面进行解决。数据集的改进是对数据集的分布进行改变,然后对改进后的数据集进行模型拟合,sampling方法被证明是处理不平衡数据问题的一个有效的方法[11]。算法方面进行解决是对算法进行优化,增大劣势类别的权重。
从数据集的方面解决的方法为过采样和欠采样,针对稀有类别的样本进行重复的抽取,同时需要减少优势类别的数量,传统的方法采用随机向上向下采样法(Random Oversampling/Random Undersampling),Over sampling就是在原数据集D中劣势类别mini里面随机选取样本集合添加到数据集中,,其中n和m分别代表劣势类别和优势类别的种类。Undersampling就是选取优势类别maxj里随机选取的样本集合为剩下的即为新的数据集,但是单纯的重复劣势类别容易产生过拟合的问题[12],去除已有优势类别的数据也会丢失掉许多有用的信息。
因此采用改进的SMOTE(Synthetic Minority Oversampling Technique)。SMOTE本质上是一个优化过的oversampling算法[13]。原算法是对于每一个计算xi的K个近邻,然后随机选取其中的一个近邻xt合成新的数据其中σ是 [0,1]中的随机数。SMOTE是对简单的过采样算法的优化,避免了单纯的复制劣势类别,减小了过拟合。
SMOTE算法由于是对原数据集的操作,因此可能选定的近邻与当前点的类别存在不同。改进后的算法是只对劣势类别进行处理,选取k∈[1,n],其中n是劣势类别的数量,直接对于k个数据取平均,这样新得到的数据是对原数据的轻微扰动,并且能够保证新数据在原有的数据簇中,能够有效的减小过拟合的问题。
3 实验结果及分析
为了验证本文提出算法的普适性和有效性,选取KDD cup99数据集的10%作为训练集,correct文件作为验证集,并与经典的SVM等算法进行比较。随机森林工具包使用scikit-learn,本文实验环境为Intel(R) Pentium(R) CPU P6100 @ 2.00 GHZ,内存2 G,32位Win7操作系统,Ipython notebook编程。
3.2 实验结果及分析
随机森林,Wenka Lee的算法,BP神经网络,SVM算法在KDD CUP99数据集[14][15]中关于网络攻击识别的结果由表1可以看出。
3.1 实验设置

表1 几个算法的准确率比较
从表中我们可以看出,随机森林算法在准确度和检测全面性方面达到了一个比较平衡的状态,需要牺牲一部分的准确度来提高分类效果比较差的U2R类别。传统的几个算法,对于类别之间的不平衡是无法处理的,在U2R中的识别效率非常低。随机森林的算法相比其他算法在几个类别的识别中,虽然Prob,Dos,R2L三类的识别率不如SVM的准确率高,但是在U2R中准确率是明显提升的,这说明对于数据不平衡问题有了小程度的提升,而且,准确度的降低并不是特别的明显,可用度有一定程度的提升。
4 结束语
本文通过改进随机森林当中的bagging方法,改变原有数据集中数据的分布,并将其应用到CUP99数据集。基于这个算法,在数据集中试验表明,虽然改进后的算法在其他三个类别中的准确度降低,但是能一定程度的改善原来的数据不平衡性的问题。接下来的工作聚焦到1)算法的改进,对随机森林算法的防止过拟合部分进行研究,并通过交叉验证的方式优化参数。2)特征工程,对于无用的特征进行筛选,防止无用特征影响分类结果。
[1] Denning D E. An Intrusion-Detection Model[J]. IEEE Transactions on Software Engineering, 1987, 13(2)∶ 222-232.
[2] 滕少华. 基于对象监控的分布式协同入侵检测[D]. 广东工业大学, 2008.
[3] Licks V, Jordan R. Geometric Attacks on Image Watermarking Systems[J]. Multimedia IEEE, 2005, 12(3)∶ 68-78.
[4] Kutter M, Bhattacharjee S K, Ebrahimi T. Towards second generation watermarking schemes[C]// International Conference on Image Processing, 1999. ICIP 99. Proceedings. 1999∶320-323 vol.1.
[5] Bas P, Chassery J M, Macq B. Geometrically invariant watermarking using feature points.[J]. IEEE Transactions on Image Processing A Publication of the IEEE Signal Processing Society, 2002, 11(9)∶ 1014-28.
[6] Tang C W, Hang H M. A Feature-Based Robust Digital Image Watermarking Scheme[J]. Signal Processing IEEE Transactions on, 2003, 51(4)∶ 950-959.
[7] Breiman L. Random Forests[J]. Machine Learning, 2001, 45(1)∶ 5-32.
[8] Efron B B, Tibshirani R J. An Introduction to the Bootstrap (ISBN 0412042312[J]. 2010.
[9] Breiman L. Bagging Predictors[J]. Machine Learning, 1996, 24(2)∶ 123-140.
[10] Wolpert D H, Macready W G. An Efficient Method To Estimate Bagging‘s Generalization Error[J]. Machine Learning, 1999, 35(1)∶41-55.
[11] Estabrooks A, Jo T, Japkowicz N. A Multiple Resampling Method for Learning from Imbalanced Data Sets[J]. Computational Intelligence, 2004, 20(1)∶ 18-36.
[12] Holte R, Acker L, Porter B. Concept Learning and the Problem of Small Disjuncts[M]. University of Texas at Austin, 1995.
[13] Chawla N V, Bowyer K W, Hall L O, et al. SMOTE∶synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2011, 16(1)∶ 321-357.
[14] Lee W, Stolfo S J, Mok K W. A data mining framework for building intrusion detection models[J]. Proceedings of the IEEE Symposium on Security & Privacy, 1999∶ 120-132.
[15] Mukkamala S, Sung A H, Abraham A. Intrusion Detection Using Ensemble of Soft Computing Paradigms[M]// Intelligent Systems Design and Applications. Springer Berlin Heidelberg, 2003∶ 239-248.
An Intrusion Detection Method Based on Random Forests Algorithm
WANG Hao
(College of Computer Sciences, North China University of Technology, Beijing, China, 100144)
Network intrusion detection is one of the important application in network area. At present, there are various detection approaches in this area. However, some problems are found in the existing algorithms, including high error rate and failure processing of data imbalance. After analyzing the network intrusion data, we design an intrusion detection algorithm based on random forests and apply it to detection of network connection information data and anomaly find. The experiment on CUP99 dataset proves that this algorithm improves identification efficiency, effectively solves the problem of data imbalance, and shows a better classification effect.
Intrusion detection; Class imbalance; Random forests; CUP99
TP393.08
A
10.3969/j.issn.1003-6970.2016.11.014
王浩(1992-),男,研究生,主要研究方向为计算机网络。
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
新校长(2016年8期)2016-01-10
郑州大学学报(医学版)(2015年1期)2015-02-27
商事法论集(2014年1期)2014-06-27
电测与仪表(2014年15期)2014-04-04
