
基于HBase的海量文件的检索方案研究
2016-12-15 02:47陈栋波高跃明
软件 2016年11期
陈栋波,高跃明
(1. 北京邮电大学 网络与交换技术国家重点实验室,北京 100876;2. 上海欣方智能系统有限公司北京分公司,北京 100085)
基于HBase的海量文件的检索方案研究
陈栋波1,高跃明2
(1. 北京邮电大学 网络与交换技术国家重点实验室,北京 100876;2. 上海欣方智能系统有限公司北京分公司,北京 100085)
在互联网(尤其是移动互联网)、物联网、云计算、大数据等高速发展的大背景下,数据呈现爆炸式地增长。这类数据不规则的特性决定了其无法再按照传统基于属性列的方式进行检索,而是需要具备更加庞大的水平扩展性。使用NoSQL数据库HBase和搜索引擎ElasticSearch相结合,通过对检索方案进行设计,对关键字匹配、语意检索、逻辑关系等检索策略进行测试和分析,实现能够快速、准确的适用于海量数据的检索方案。
大数据;HBase;ElasticSearch;检索方案
本文著录格式:陈栋波,高跃. 基于HBase的海量文件的检索方案研究[J]. 软件,2016,37(11):88-92
0 引言
在互联网(尤其是移动互联网)、物联网、云计算、大数据等高速发展的大背景下,数据呈现爆炸式地增长。海量小文件的应用在生活中已越来越常见,不仅存储容量巨大,而且数据类型繁多、数据大小变化幅度大、流动快等显著特点,往往能够产生千万级、亿级甚至十亿、百亿级的海量文件。随着检索数据的增加,检索效率在减少。
传统的结构化关系型数据库管理中,数据的检索往往是基于列的条件检索。但是这类非结构化文档数据不规则的特性决定了其无法再按照传统基于属性列的方式进行检索,而是需要具备更加庞大的水平扩展性。NoSQL技术的出现,在一定程度上改变了这一状况,使数据不必一定满足关系型数据库管理系统的需要。而使用搜索引擎对大数据的搜索更是使检索更为方便。
基于以上的这种背景,对词组搜索、词组选择、提供结果的相关度等检索策略进行了研究,使用NoSQL数据库HBase和搜索引擎ElasticSearch相结合,设计和实现了适用于海量文件的检索方案:通过对检索策略进行设计,(包括确定检索的数据库、检索的用词,并明确检索词之间的逻辑关系和查找步骤的科学安排),对关键字匹配、语意检索、逻辑关系等检索策略进行测试和分析,实现能够快速、准确的海量数据的全文检索方案。
1 技术背景综述
HBase是hadoop系列的开源数据库。Hadoop为大数据处理而生,天生就是处理大数据的利器,但是其所擅长的是离线出来数据。而当需要动态实
时的从海量数据中获取信息时,就产生了HBase。HBase作为Google Bigtable的开源实现,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,与Hadoop的作业模式不同,HBase可用于存储和处理半结构化的数据,且能够将海量数据进行实时的处理,并动态的向用户提供数据的存储及读写服务。
但是随着使用的需求越来越多,应用场景日益复杂,用户对查询方式的的要求变得越来复杂。在HBase HBase的设计中只有每行数据的row key作为数据检索的唯一索引,这使得HBase在检索方面有很多的限制,这就要求在设计表结构的时候要根据表的使用场景做额外的考虑,经常会遇到不得不进行全表扫描的查询条件,这对于海量数据的表来说,完全是无法接受的灾难。单一的按row key检索数据的方式,无法再满足更多应用的需求。现有的传统的数据库产品都有索引以及全文检索的功能,而在HBase中至今没有完整的解决方案。
关于HBase检索的方案,最常见的方案是基于Lucene或者Solr使用MapReduce去创建索引,再提供搜索,这样的方法是增量建立索引有困难,随着数据增大,每一次建立索引的时间会非常长,最后变成一个不可能完成的任务。另一方面,该方式基本就是为不同的数据编写不同的MapReduce任务,没有通用性。还有就是将管理全部放在客户端,比如Facebook的收件箱查询,分词的工作是由应用来完成,然后存储在HBase中,但是该类设计并没有通用性。还有一些尝试是基于HBase coprocessor的并使用Lucene为HBase增加全文检索功能。关于全文检索的讨论,基本上还是围绕着Lucence使用或者Solr来进行,但是一直以来全文检索也并未被社区重视,所以社区在这方面并没有什么动作,但是随着信息的增长,全文检索的需求还是很旺盛的。
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。ElasticSearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
综上所述,本方案中HBase的全文检索功能将基于ElasticSearch实现,提供简单灵活的索引定义方式。为了将索引建立方便地嵌入现有的HBase代码中,将充分利用HBase的coprocessor框架的特点,将相关代码填入到对应的钩子函数中,这样能够大大减少对于源代码的改动。
2 方案设计与实现
2.1 方案体系结构
方案的动态结构如图2-1所示,在使用检索功能前,应先使用数据库同步模块对数据库发出读取数据的请求,数据库返回数据库后再将其同步到ElasticSearch索引中。当检索请求发出时,前端交互模块将检索信息和筛选信息发送到检索处理模块,分词后,检索处理模块将推荐关键词经由前端交互模块返回给用户。检索处理模块自行再使用检索信息和筛选信息在ElasticSearch索引中进行检索,并将检索结果经由前端交互模块返回给用户。
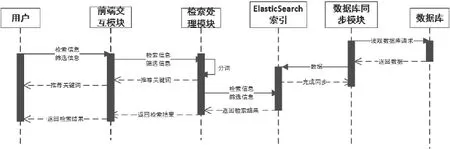
图2-1 检索系统的动态结构
在整体框架中在系统内部大致可以分为三个模块:信息输入模块、检索处理模块、数据库同步。在整体架构中信息输入模块主要起控制器层的接受使用者的消息请求的功能,检索处理模块主要起处理检索信息、实现检索功能、返回检索结果的功能,数据库同步模块主要起持久层作用,完成数据库同
步工作:
1)前端交互模块:
前端交互模块主要实现界面功能,包括以下功能:
· 提供信息输入的检索框以及筛选内容的tag;
· 将检索关键词及筛选tag传入检索处理模块进行处理;
· 在页面上返回检索处理模块的检索结果;
· 在页面上返回检索处理模块的分词结果作为检索的推荐关键词;
· 在页面上点击相应的检索结果能返回看到该结果的全文信息。
2)检索处理模块:
检索处理模块是体现检索子系统功能的主要模块,包括以下两个子模块:
· 分词子模块:
分词子模块接受前端交互模块输入的字符串,使用ElasticSearch的API连接ElasticSearch的中的MMSeg4j分词器和IKAnalyzer分词器进行分词处理,使得检索结果更准确,同时将分词结果传入检索子模块和前端交互模块。
· 检索子模块:
检索子模块中包括了逻辑检索子模块、关键词检索子模块和语义检索子模块,通过检索处理模块中的分词子模块传来的关键词和前端交互模块传来的筛选信息分别实现逻辑检索、关键词检索和语义检索的功能,使用ElasticSearch的API对数据库同步模块形成的ElasticSearch索引进行检索,对检索结果按照相关性进行排序,并返回到前端交互模块。
3)数据库同步模块:
由于数据存放在数据库HBase中,在使用ElasticSearch进行检索处理模块进行检索时,需要先对HBase中的数据进行同步。
· 对HBase中的数据进行同步。
· 在同步的过程中在ElasticSearch中建立索引,将HBase中的Rowkey保存为ElasticSearch中document的ID,将HBase中的column保存为ElasticSearch的field,将HBase中的表名保存为ElasticSearch中的type。
2.2 检索功能的实现
检索功能对关键词匹配和语义检索的具体实现如下图2-2所示:
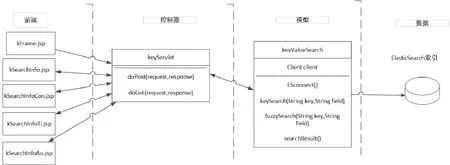
图2-2 关键词匹配和语义检索的具体实现
kFrame.jsp将检索关键词输入keyServlet中,而kSearchInfo.jsp、kSearchInfoCon.jsp、kSearchInfoTi. jsp、kSearchInfoAu.jsp的选择将筛选关键词输入keyServlet,控制器keyServlet调用keyValueSearch中的searchResult()来返回关键词检索和模糊检索后整合排序后的结果。search Result()需要实现检索子系统的检索策略:将检索结果按优先匹配完整关键词的结果,然后是分词后匹配到分词较多的检索结果,接着是分词后匹配到词语较少的检索结果和模糊匹配的结果,按相关度打分后的结果进行排序并去掉得分过低的结果。这一部分需要调用Elastic-Search的API getScore()完成。searchResult()调用keyValueSearch中的keySearch (String key, String Field)和fuzzySearch(String key, String field)来分别对ElasticSearch索引中的信息进行关键词检索和模糊检索。keyServlet将检索结果返回检索请求输入时对应的jsp中,每个结果分别对应一个链接显示,并显示前200字的预览。
2.3 数据结构
本方案数据包括HBase数据库表中的数据和ElasticSearch中索引中的数据,这些数据是用来检索的信息。
2.3.1 数据库表设计
HBase中的表Doc结构如表2-1所示。Doc表用来存储原始的文档信息,每行数据代表一个文档,每个文档在1 MB以下,整个表约有1200000条数据,整体大小约在1 TB左右,存储在数据库中。

表2-1 HBase的表Doc结构
在系统中,doc表的信息在数据库同步模块使用HBase API进行调用,将其写入到ElasticSearch索引中。
2.3.2 ElasticSearch索引设计
ElasticSearch索引HBase如表2-2所示。索引名为HBase,由数据库同步模块HBase数据库的Doc表写入,因此索引中每个文档也大多在1 MB以下,约有1200000个文档,整个索引大小约为1 MB,通过ElasticSearch自动分片分发到每个节点上存储。存储的信息为用来检索的文档。

表2-2 ElasticSearch中的索引HBase
索引文件使用默认的hybrid mmap/nio fs来进行存储。这种方式将映射的文件加载到虚拟地址空间。也就是在内存够时将索引存在内存里,当内存不够时使用虚拟地址映射到磁盘当中。并使用ElasticSearch的gateway功能的local gateway,也就是节点各自保存其状态,节点直接从本地存储来恢复节点状态和索引信息。
索引文件由检索处理模块使用ElasticSearch API进行访问,得出检索结果返回到前端交互模块。
2.3.3 检索处理模块数据结构
· 分词子模块的数据结构
keyServlet类

表2-3 keyServlet类的数据结构
analyze类
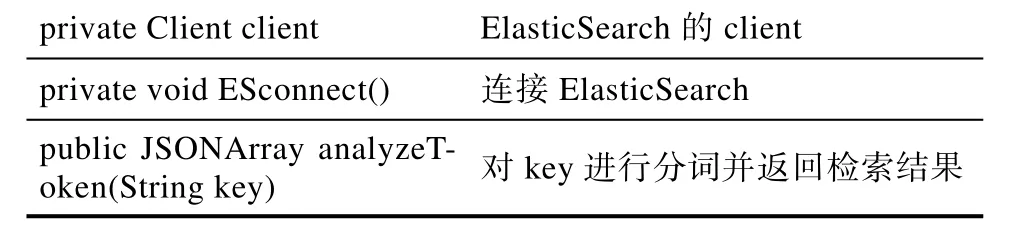
表2-4 analyze类的数据结构
2.2.4 检索子模块的数据结构keyValueSearch类
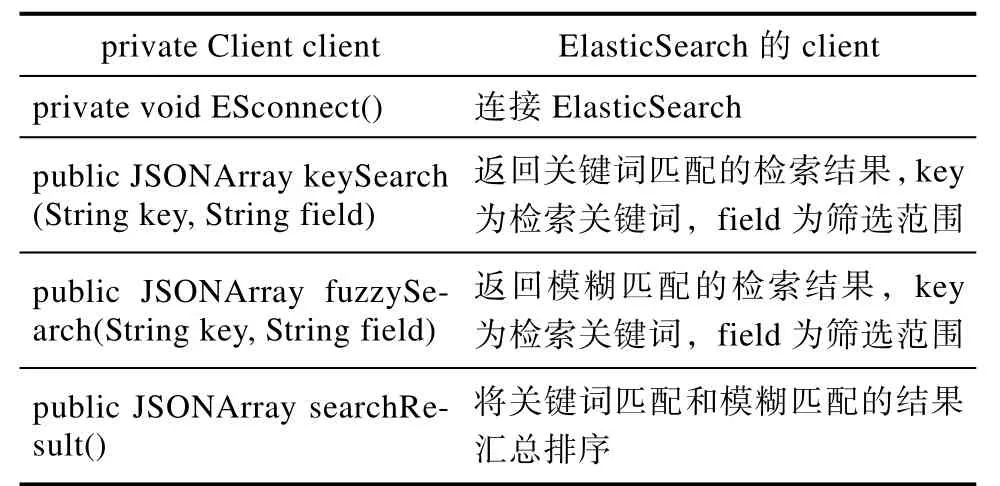
表2-5 keyValueSearch类的数据结构
logicSearch类

表2-6 logicSearch类的数据结构
3 方案测试验证
结合ElasticSearch和HBase集群系统,对检索方案的功能实现情况进行测试,如表3-1所示。

表3-1 测试硬件环境列表
在表3-2中同样列出了软件测试的软件环境:

表3-2 测试软件环境列表
如表3-3所示是测试检索20次的响应时间(设定最多返回250条结果)。
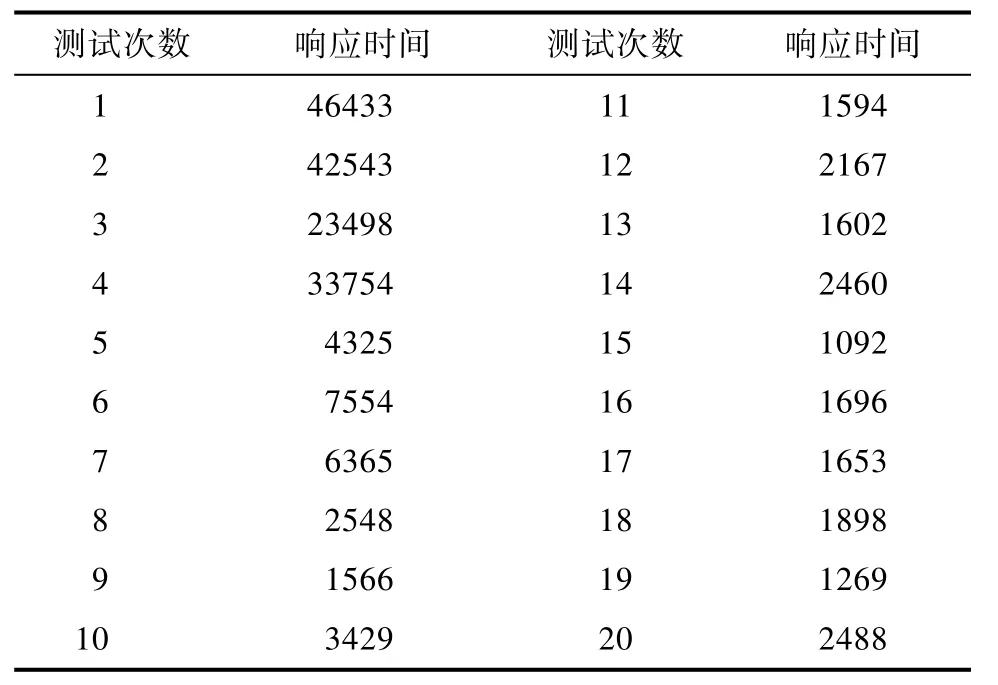
表3-3 响应时间测试时间(单位ms)
由表3-3可看出,前面几次响应时间比较长,最长达到了46433 ms,而到后面检索时间逐渐稳定,几乎都在3 s以内,查询相关资料后是ElasticSearch最开始使用时需要加载field data、倒排索引等数据结构,需要较长的时间,在加载完成之后检索时间就较为稳定了。
通过上述对于海量文件检索方案的测试可以发现,在性能测试方面,当采集量达到一定的量,本系统的检索的响应时间将维持在3 s以内,随着时间和检索次数的增加可能会继续减少,而且准确率较高,即在系统运行正常时具有极高的可靠性。从而,从上述测试结果中可以得出结论,本方案基本符合需求和预期目标。
4 总结与展望
通过对海量文件检索的现状和问题进行分析,基于ElasticSearch实现了HBase的检索功能,大大减少对于源代码的改动。进行了检索响应速度测试,得出较好的测试效果。在后续的开发中,将通过修改分词器来提高检索结果的准确率,进行深一步的研究和改进。
[1] 于天恩. Lucene搜索引擎开发权威经典[M]. 中国铁道出版社, 2008.
[2] 王宏霞, 艾树峰. 数字图书馆信息检索技术的研究[J]. 浙江传媒学院学报, 2007, 04: 69-71.
[3] 卓海艺. 基于HBase的海量数据实时查询系统设计与实现[D]. 北京邮电大学. 2013.
[4] 陈洪猛. 全文检索技术的研究与实现[D]. 北京工业大学, 2008.
[5] 杨小莉, 黄水清. 国内常见全文检索系统比较[J]. 图书与情报, 2006, 02: 94-96.
[6] (波)库赛, (波)罗格辛斯基著, 蔡建斌译. Elasticsearch服务器开发: 第2版[M]. 人民邮电出版社. 2015.
[7] 张建中, 黄艳飞, 熊拥军. 基于ElasticSearch的数字图书馆检索系统[J]. 计算机与现代化, 2015, 06: 69-73.
[8] 陈俊杰, 黄国凡. 应用Elasticsearch重构图书馆站内搜索引擎[J]. 情报探索, 2014, 11: 114-119.
Research on the Retrieval Scheme of Massive Data Based on HBase
CHEN Dong-bo1, GAO Yue-ming2
(1. State Key Laboratory of Networking and Switching Technology, Beijing university of posts and telecommunications, Beijing 100876, China; 2. Shanghai CINTel Intelligent Telecom System Co., Ltd Beijing, Beijing 100085, China)
With the developing of Internet (especially mobile Internet), Internet of things, cloud computing and big data,the information on the internet showing the situation of the “explosive” growth. The irregular characteristics of data can not be searched through the traditional way of attribute based retrieval. This need to have a more extensive level of scalability. By combine NoSQL database HBase and search engine ElasticSearch, can quickly and accurately the massive data to achieve the retrieval subsystem.
Big data; Hbase; ElasticSearch; Retrieval scheme
TP391.1
A
10.3969/j.issn.1003-6970.2016.11.019
陈栋波(1991-),男,硕士研究生,主要研究方向:网络技术研究与应用。高跃明(1985-),男,上海欣方智能系统有限公司北京分公司(北京邮电大学产学研基地)数据业务部副经理,主要研究方向:电信增值业务及通信软件。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
校园英语·月末(2021年13期)2021-03-15
当代陕西(2019年14期)2019-08-26
现代计算机(2016年27期)2016-10-29
东莞理工学院学报(2014年3期)2014-07-12
测绘科学与工程(2014年2期)2014-02-27
外语学刊(2011年3期)2011-01-22
智能计算机与应用(2007年3期)2007-07-05
