
改进的克隆选择算法求解高维背包问题*
2016-12-19 01:12钱淑渠武慧虹
计算机与生活 2016年12期
钱淑渠,武慧虹
1.南京航空航天大学 自动化学院,南京 210016
2.安顺学院 数理学院,贵州 安顺 561000
改进的克隆选择算法求解高维背包问题*
钱淑渠1,2+,武慧虹2
1.南京航空航天大学 自动化学院,南京 210016
2.安顺学院 数理学院,贵州 安顺 561000
QIAN Shuqu,WU Huihong.Improved clonal selection algorithm for solving high-dimensional knapsack problem. Journal of Frontiers of Computer Science and Technology,2016,10(12):1711-1719.
高维背包问题;克隆选择算法(CSA);受体编辑机制;修补策略
1 引言
背包问题(knapsack problem,KP)属一类NP难组合优化问题,具有较高的理论和实际应用价值[1],其可描述为许多实际问题,如货物装载、投资组合、资源分配等。近来,基于群智能的算法求解KP受到众多学者的关注[2],相继出现了差分算法[3]、粒子群算法[4]、蚁群算法[5]和量子进化算法[6]。这些算法在求解KP时已取得了较好的效果,但多数使用低维的KP作为测试实例,研究求解高维的KP算法更具有实际价值[1]。众所周知,作为一类新兴的智能算法,克隆选择算法(clonal selection algorithm,CSA)已在连续函数优化领域得到了广泛的应用[7],其独特的抗体学习抗原机制使得该算法能快速寻优,并且抗体多样性功能使得进化群能保持较好的解多样性,但其对KP的研究成果较少。主要原因是CSA多数用于求解无约束连续函数问题,没有特定的约束处理策略,故其直接解决约束问题时仅靠简单的亲和突变算子开采可行域,而且当求解高维KP时,在进化过程中所获可行抗体的比率非常低(相对于搜索群),开采能力弱,甚至不能获得可行的抗体,导致算法易于陷入局部搜索。因此,克服CSA易于陷入局部搜索的不足,发挥其抗体多样性功能,设计适合求解高维KP的改进CSA具有一定的研究价值。
为此,本文以CSA为基本框架,充分挖掘免疫系统的内部机理,提炼出一种受体编辑机制(receptor editing,RE),以该机制代替CSA中的0/1二进制变异,并设计一种二次修补策略(repair),提出了基于RE和修补的改进克隆选择算法(clonal selection algorithm with receptor editing and repair,CSA-ER)。其中RE机制增大抗体的突变程度,提高算法的开采能力,而修补策略增加种群中抗体的可行比率,加快算法收敛速度。数值实验将CSA-ER与CSA的一系列变体(CSA-M,基于0/1二进制突变的CSA;CSA-E,CSA中二进制突变由本文提出的RE机制替换后的CSA;CSA-MR,采用二进制突变并增加二次修补策略的CSA)应用于100和200维KP进行了仿真分析,比较了CSA-ER与其他两类算法的性能。比较结果充分表明了本文提出的RE机制和二次修补策略能有效地提高CSA求解高维KP的能力。
2 背包问题
背包问题(KP)的数学模型可描述为:

式中,pi和wi分别表示第i物品的利润和重量;n为物品数;xi取1表示第i物品被装入背包,否则表示不被装入;C称为背包的最大容量,本文取。求解KP的目标是确定最佳组合x,使总利润 f(x)尽可能的大。
3 改进的克隆选择算法
基本CSA[7]的步骤可简述为:
输入:种群规模N;最大迭代数G;免疫选择率α;突变率pm;募集率μ。
步骤1初始种群:随机产生规模为N的初始种群A。设置初始代数t=0。
步骤2停止准则:判断t<G?若是,执行步骤3;否则,输出结果。
步骤3抗体评价:计算A中各抗体亲和力aff(x),并按亲和力由大到小排序。
步骤4免疫克隆:选取A中亲和力较大的┌αN ┐个抗体构成群体B,对B中的抗体按亲和力比例克隆,获克隆群C。每个抗体x∈B的克隆数目为:

克隆群C的规模为N。∑aff(B)表示群体B中所有抗体亲和力的和。
步骤5亲和突变:对C执行亲和突变,获群体D。
步骤6免疫选择:从D中选择亲和力较大的N个抗体构成群体E。
改进的CSA主要围绕抗体评价、约束处理和免疫系统抗体多样性机理而相应地提出改进的亲和力设计方法、二次修补的约束处理策略和受体编辑机制。具体设计如下。
3.1 亲和力设计
KP为一类约束优化问题,常用罚函数法[8]设计抗体的亲和力,以降低非可行抗体进化机会:

这里,κ称为罚因子,一般需根据经验选择一个较为合适的数值;g(x)为约束。该方法不适合CSA,因为若选定的κ较大,将会使得非可行抗体的亲和力aff(x)<0(根据式(2))。此时,若当前群中非可行抗体又占主导地位,则会出现∑aff(B)<0。此情况下,在免疫克隆阶段,非可行抗体的克隆比例aff(x)∑aff(B)>0,而可行抗体的克隆比例却 aff(x)∑aff(B)<0(因为可行抗体必有aff(x)>0),这必将误导算法的搜索行为。
为了克服上述问题,本文亲和力设计为:

此设计足以保证非可行抗体的亲和力aff(x)∈(0,1),并且违背度越大,其亲和力aff(x)越小。
3.2 约束处理机制
在优化领域,约束的处理策略主要是罚函数法。对于KP模型,直接使用罚函数法很难获得高质量的解。为此,学者们提出了很多价值密度修补策略[9-12]。本文在这些策略的基础上,提出一种二次修补策略,对克隆突变的抗体进行修复,具体过程如下:
对抗体x=(x1,x2,…,xn)∈{0,1}n。若x为非可行抗体,执行步骤1~步骤7;否则,执行步骤4~步骤7。
步骤1确定抗体x中编码为1的序数集Ι={i|xi= 1,i=1,2,…,n}。假设集合I的势 |I|=u,计算序数集I中元素对应物品的价值密度:

步骤2序数集I中的元素按价值密度ρi由小到大排列,获得新的序数集,其中 ρi≤ρijk(1≤j<k≤u)。

步骤4计算背包的剩余容量ΔW=g(x)。
步骤5确定经修复的抗体x中编码为0的序数集O={i|xi=0,i=1,2,…,n},假定所获O的势|O|=η,计算序数集O中元素对应物品的价值密度:

步骤6对序数集O中的元素按价值密度σi由大到小排列,得到新的序数集。
评注 步骤1~步骤3是对非可行抗体进行修补,使其为可行抗体;步骤4~步骤7对可行抗体或修复后的抗体采用二次再装策略,使背包尽可能最大限度地载满,以加速算法的收敛速度。
3.3 受体编辑机制
研究表明免疫系统的B细胞成熟过程不仅经历克隆选择和亲和突变过程,而且B细胞偶尔会发生RE过程[13-15]。RE过程即通过V(D)J区基因段重组[16]删去亲和力较低的受体基因段,并从基因库中产生新的抗体受体。RE机制能极大地提高算法的全局搜索能力[17]。受该机制启发,本文提出受体编辑操作,主要包括基因库产生和编辑过程。
3.3.1 基因库产生
基因库即是由若干个基因片段组成的基因段池,每个基因段具有一定的长度。对于免疫系统,其基因库数量和库内基因段的长度一般为固定值,而且这些基因段是由染色体分解而成。本文为了提高算法适应不同维问题,基因库的数量和基因段的长度根据被优化问题的维数n确定,具体为:
步骤1给定基准基因段长度σ。
步骤2确定基因库数量m和各库的基因段长度l。如果mod(n,σ)=0,则m=n σ,此时每个库内的基因段长度l=σ;若mod(n,σ)≠0,则,此时前面m-1个基因库内的基因段长度l=σ,而最后基因库内的基因段长度l=n-(m-1)σ。其中mod(n,σ)表示σ除n的余数。
步骤3根据获得的l随机产生各基因库的基因段。
评注 该设计确保不同基因库内的基因段长度之和恰为染色体的长度,体现基因段来自染色体自身的生物机理;另外,在基准基因段长度给定下,不同维问题基因库的数目不同,维数越高其基因库数目相对多,基因段的多样性高,以提高算法适应问题的能力。
3.3.2 受体编辑
受体编辑(RE)即从基因库中选定一个基因段替换被编辑的抗体相应长度的基因段而获得新的抗体[7,17]。如图1所示。
需要说明的是在算法实现中不分基因库的类别,而且基因库的类型不只是图1中的3种类型,而是假设有多个基因库(参见基因库产生部分)。

Fig.1 Receptor editing process in immune system图1 免疫系统中受体编辑过程
RE步骤如下:
步骤1对于待编辑的抗体x,若rand≤Tr,则随机产生一个编辑起始点q,执行步骤2;否则,返回步骤1,对下一个抗体执行编辑操作。其中Tr称为编辑率,rand为[0,1]的随机数。
步骤2随机选定一个基因库并在其中随机产生一个长度为l的基因段y。
步骤3若q+l≤n,则y按图1方式替换;若q+l>n,此时替换完q点之后的所有基因,y仍有剩余,则y的剩余部分将依次替换x的起始位基因。此方法以保证被编辑后的抗体基因长度保持为n。
3.4 改进的算法
根据CSA基本框架,结合上述RE和修补机制,改进的CSA步骤描述如下。
输入:种群规模N;最大迭代数G;基准基因段长度σ;克隆选择率α;编辑率Tr。
步骤1初始种群:随机产生规模为N的初始种群A;根据变量维数n,按基因库产生方式确定基因库数量并产生各库的基因段。设置初始代数t=0。
步骤2停止准则:判断t<G?若是,执行步骤3;否则,输出结果。
步骤3抗体评价:依式(3)计算A中各抗体亲和力aff(x),并按亲和力由大到小排列各抗体。

步骤5受体编辑:对群C中每个抗体,执行RE操作,获群体D。
步骤6约束处理:群体D经由约束处理机制,获群体E。
步骤7免疫选择:群体E按亲和力由大到小排序,并选取亲和力较大的N个抗体构成群体P。置t←t+1,A←P,转入步骤2。
3.5 复杂度对比分析
对比CSA-ER与CSA-M可知,CSA-ER中RE代替了CSA-M的亲和突变,增加了约束处理策略,但减少了募集新成员算子。两算法不同部分的复杂度量化比较如下:对于CSA-ER,RE最坏时间复杂度为O(N);约束处理策略模块复杂度主要由步骤2和步骤6决定,其最坏时间复杂度均为O(Nnlgn)。故两模块最坏时间复杂度为O(N)+O(Nnlgn)=O(Nnlgn)。对于CSA-M,亲和突变的最坏时间复杂度为O(Nn)。因为O(Nnlgn)>O(Nn),所以CSA-ER的时间复杂度大于CSA-M。这里的N为免疫选择后的种群规模,n为抗体编码长度。
4 数值实验
为了分析CSA-ER的优化能力,采用CSA-ER求解两类高维KP(100维[9]和200维[12],为方便表述分别记为KP-100和KP-200),并将其与CSA的一系列变体以及两种其他类群智能算法(BDEPM[3]、MBPSO[4]进行比较,各算法的亲和力函数均采用本文设计的式(3):
(1)CSA-M:二进制0/1突变的CSA;
(2)CSA-E:RE策略替换CSA中的二进制突变;
(3)CSA-MR:采用二进制突变和二次修补策略的CSA;
(4)BDEPM:改进的无参数变异二进制差分进化算法[3];
(5)MBPSO:改进的二进制粒子群算法[4]。

各算法参数设置为:群体规模N=100,最大迭代数G=1 000;克隆选择率α=0.4;CSA中的突变率pm=1 n,募集率μ=0.1;CSA-ER的编辑率Tr=0.9,基因段基准长度σ=4;BDEPM中CR=0.9;MBPSO中c1=c2=2,r1、r2在[0,1]间均匀地随机产生。
评价准则为各算法对每测试问题独立执行30次,统计30次中各算法所获的最好值(最大目标值)、最差值(最小目标值)和平均值(30次所获最好目标值和的平均值),以及平均目标值搜索曲线和群体平均多样性搜索曲线。群体的多样性计算公式[18]为:
式中,HD(∙,∙)为两抗体间的海明距离;n为染色体长度;N为抗体数。群体平均多样性是30次执行所获的D(P)的平均值。
表1和表2分别为各算法对KP-100和KP-200在30次执行中所获的最好值、最差值、平均值及方差(粗体为6个算法中最好的)。由表1可知,CSA-ER所得各项统计值均比其他算法相应的统计值优越,其次为BDEPM,例如CSA-ER的平均目标值为5 341.167,BDEPM为5 335.833。比较CSA-M和CSA-E可知,除方差外,CSA-E所获统计值均优于CSA-M,这表明基于RE机制的CSA强于基于0/1二进制突变策略的CSA,其原因是RE机制增强了算法的开采和探索能力。比较CSA-MR和CSA-M,CSA-ER和CSA-E可知,CSA-MR优于CSA-M,CSA-ER优于CSA-E,这表明本文提出的约束处理策略能提高算法对KP的优化性能,原因是修补策略增强了可行抗体的数目,加快了算法的收敛性。对于KP-200(表2)同样有CSAER所获的各项统计值优于其他算法。对于被比较的其他类群智能算法BDEPM和MBPSO,由表1和表2可知,BDEPM求解KP的能力强于MBPSO,但均差于CSA-ER。特别对于KP-200,BDEPM和MBPSO甚至差于CSA-E和CSA-MR(观察表2可知)。由各表的方差统计值比较可知,CSA-ER所获的方差均小于其他算法所获的方差,这表明CSA-ER多次独立执行得到的结果稳定性较其他算法好。
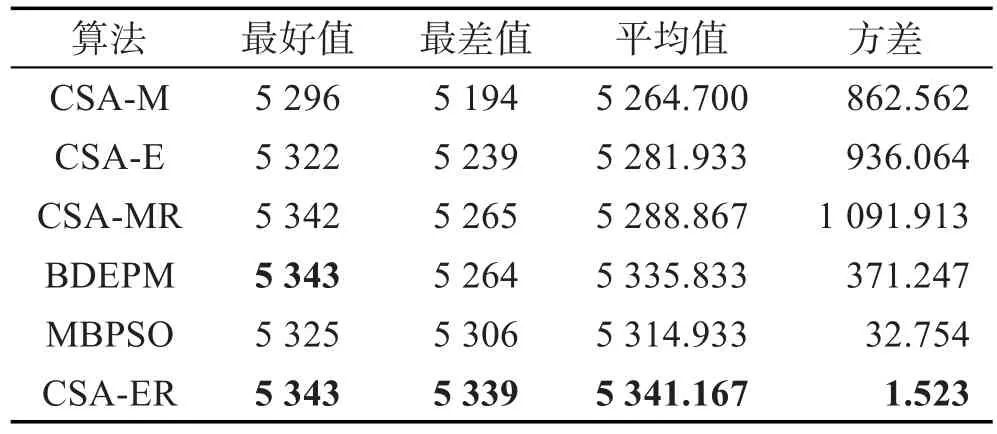
Table 1 Comparison of statistical values of each algorithm on KP-100表1 KP-100各算法统计值比较

Table 2 Comparison of statistical values of each algorithm on KP-200表2 KP-200各算法统计值比较
图2和图3分别为各算法对KP-100独立执行30次所获的平均目标和群体平均多样性搜索曲线。由图2可知,在初始大约100代内,MBPSO和BDEPM的搜索速度快于CSA-ER,但随后CSA-ER的搜索速度超过所有其他算法,MBPSO陷入局部搜索,BDEPM一直向最优解搜索,并逐渐靠近CSA-ER。这表明BDEPM具有一定的发展潜力,但其收敛速度比较慢。比较CSA-E与CSA-M和CSA-MR可知,CSA-E起始收敛速度差于CSA-M和CSA-MR,但其一直向最优解搜索,而CSA-M和CSA-MR虽然起始收敛速度快,但随后陷入局部搜索。此也说明了RE机制能提高算法的开采能力,其不足是收敛速度稍慢。由CSA-ER、CSA-MR与CSA-E、CSA-M的比较可知,在最大代数内,CSA-ER、CSA-MR的收敛能力均优越于CSA-E、CSA-M,这说明约束处理策略加快了算法的收敛速度。由图3的比较可知,MBPSO在进化过程中保持较高的种群多样性,而其他算法均有较明显的下降,其中BDEPM在进化过程中一直下降,而其他算法初始阶段迅速下降,随后保持一定的水平。这是因为MBPSO中改进的粒子位置更新策略保持了种群的多样性,而BDEPM中的无参数变异策略加速种群向最优解位置移动,随算法的收敛,必将降低其种群的多样性。进一步比较CSA系列算法可知,CSA-ER优越于CAS-MR,CSA-E相似于CSAM,这说明RE机制提高了群体的多样性。

Fig.2 Comparison of average objective values with generations of each algorithm on KP-100图2 针对KP-100各算法的平均目标搜索曲线

Fig.3 Comparison of average diversity with generations of each algorithm on KP-100图3 针对KP-100各算法的平均多样性搜索曲线
图4和图5分别为各算法对KP-200独立执行30次所获的平均目标和群体平均多样性搜索曲线。观察图4可知,CSA-ER与CSA-MR的初始阶段具有相当的收敛速度,但最终CSA-ER获得更好的收敛效果,而MBPSO相对于其他算法有较差的收敛能力,BDEPM收敛能力与KP-100相似,一直向最优解搜索。对于多样性(图5)的比较可知,同图3类似,MBPSO和BDEPM保持较好的多样性(但BDEPM一直下降),CSA-ER仅优于CSA-MR,而劣于其他算法。这是因为CSA-ER保持较好的收敛能力,必以降低种群多样性为代价。

Fig.4 Comparison of average objective values with generations of each algorithm on KP-200图4 针对KP-200各算法的平均目标搜索曲线
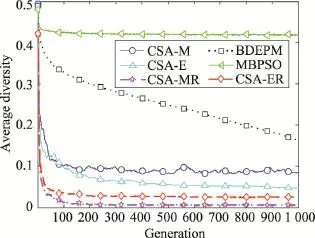
Fig.5 Comparison of average diversity with generations of each algorithm on KP-200图5 针对KP-200各算法的平均多样性搜索曲线
表3给出了各算法对每个问题执行30次所获的每代所需的平均时间。由表3可知,CSA-E算法所需的时间最短,也即基于RE机制的算法执行时间低于基于0/1二进制突变策略的算法。这是因为0/1二进制突变策略对被突变抗体的每个基因均按一定的概率进行突变操作,最坏情况下每个抗体要进行n次突变操作,而RE机制仅对被编辑抗体执行一次基因段替换,最坏情况下每个抗体最多执行一次编辑操作。

Table 3 Comparison of average running time表3 平均执行时间统计值 s
5 参数敏感性分析
CSA-ER涉及到的参数主要有克隆选择率α、基因段基准长度σ和受体编辑率Tr,分别对这3个参数进行敏感性分析。对KP-100和KP-200在不同的参数设置下各算法独立执行30次,图6~图8为KP-100在不同参数下所获的平均目标搜索曲线。
图6为克隆选择率α由0.1变化到1.0的平均目标值变化曲线。由图可知,选择率α较小或较大时均降低算法的搜索能力,如α为0.1,0.2,0.7,0.8,0.9,1.0,特别是α为0.7~1.0区间时算法陷入局部搜索,完全失去开采能力。当α为0.3,0.4,0.5,0.6时获得较好的搜索性能,其中α为0.5时达到最好。

Fig.6 Curves of average objective values with clonal selection rate α from 0.1 to 1.0图6 克隆选择率α由0.1变化到1.0平均目标搜索曲线
图7描绘了基因段基准长度σ在1到10之间的平均目标搜索曲线。观察图7易知,σ为1时算法搜索能力最差,起始代就陷入局部搜索。σ由2到4算法的搜索能力逐渐提高,在σ为4时达到最佳性能。σ为8和9时起始搜索速度慢,在较大代(如1 000代)时达到比较好的性能。其他情况优化能力较弱。总体比较σ为4时搜索速度较快。
图8给出了受体编辑率Tr取不同值时所获的平均目标搜索曲线。由图8可知,Tr为0.9时表现最佳的搜索行为,Tr在0.7~0.8时也表现较好的搜索能力,但其他值稍差,由此可知编辑率Tr不宜过小。

Fig.7 Curves of average objective values with gene segment length σ from 1 to 10图7 基因段长度σ由1变化到10平均目标搜索曲线

Fig.8 Curves of average objective values with receptor editing rate Tr from 0.1 to 1.0图8 受体编辑率Tr由0.1变化到1.0平均目标搜索曲线
对于KP-200,克隆选择率α和受体编辑率Tr对目标值的敏感性与KP-100所获结果非常类似,而基因段基准长度σ对目标值的敏感性有所不同,在σ= 6时达到最好的收敛效果(对于KP-100,在σ=4时达到最好收敛效果)。其原因是由于KP-200与KP-100的主要不同是个体编码长度,KP-200编码长度增长了,而在相同的受体编辑率下,要想达到种群的最佳收敛效果,必将要求个体突变程度增强,故σ的最适合值增大。
6 结束语
本文基于免疫系统的受体编辑机制及二次修补策略提出了改进的CSA处理高维KP。设计二次修补策略能提高算法的约束处理能力,提出受体编辑算子提高抗体的多样性。数值实验将被提出的算法用于两种高维的KP,并与CSA的一系列变体进行了仿真比较,结果表明了被提出的算法解决高维KP的优越性,收敛速度比其他算法快。最后对被提出算法的3个重要参数进行了敏感性分析。
需要指出的是本文重点分析受体编辑机制和二次修补策略对CSA性能的影响。因此,未研究其与更多其他类算法的比较,该内容将是后续工作。另外,本文提出的受体编辑及修补策略也可结合其他类算法,以及用于其他类组合问题的求解,如TSP、投资组合等,这也将是后期的研究工作。经数值实验可知,所提出的相关机制能提高算法的优化性能,但算法时间开销有所增大,这在实验比较部分均有分析,如何克服这些缺点有待进一步讨论。
[1]Wu Congcong,He Yichao,Chen Yiying,et al.Binary bat algorithm for solving 0-1 knapsack problem[J].Computer Engineering andApplications,2015,51(19):71-74.
[2]Changdar C,Mahapatra G S,Pal R K.An ant colony optimization approach for binary knapsack problem under fuzziness[J].Applied Mathematics and Computation,2013,223 (9):243-253.
[3]Kong Xiangyong,Gao Liqun,Ouyang Haibin,et al.Binary differential evolution algorithm based on parameterless mutation strategy[J].Journal of Northeastern University,2014, 35(4):484-488.
[4]Bansal J C,Deep K.A modified binary particle swarm optimization for knapsack problems[J].Applied Mathematics &Computation,2012,218(22):11042-11061.
[5]Kong Min,Tian Peng,Kao Yucheng.A new ant colony optimization algorithm for the multidimensional knapsack problem[J].Computers&Operations Research,2008,35(8): 2672-2683.
[6]Chang Xingong,Liu Wenjuan.Self-adaptive quantum-inspired evolutionary algorithm combining the strategy of keeping away from the worst[J].Journal of Frontiers of Computer Science and Technology,2014,8(11):1373-1380.
[7]Castro L N D,Zuben F J V.Learning and optimization using the clonal selection principle[J].IEEE Transactions on Evolutionary Computation,2002,6(3):239-251.
[8]Basu S K,Bhatia A K.A naive genetic approach for nonstationary constrained problems[J].Soft Computing,2006, 10(2):152-162.
[9]He Yichao,Wang Xizhao,Kou Yingzhan.A binary differential evolution algorithm with hybrid encoding[J].Journal of Computer Research and Development,2007,44(9):1476-1484.
[10]Zeng Zhi,Yang Xiaofan,Chen Jing,et al.An improved genetic algorithm for the multidimensional 0-1 knapsack problem[J].Journal of Computer Sciences,2006,7(7):220-223. [11]Tuo Shouheng,Yong Longquan,Deng Fang'an.A novel harmony search algorithm based on teaching-learning strategies for 0-1 knapsack problems[J].The Scientific World Journal,2014.doi:10.1155/2014/637412.
[12]Wu Huihong,Qian Shuqu,Xu Zhidan.Immune genetic algorithm based on clonal selection and its application to 0/1 knapsack problem[J].Journal of Computer Application, 2013,33(3):845-848.
[13]Berek C,Ziegner M.The maturation of the immune response[J].Immunology Today,1993,14(8):400-404.
[14]Nussenzweig M C.Immune receptor editing:revise and select[J].Cell,1998,95(7):875-878.
[15]George A J,Gray D.Receptor editing during affinity maturation[J].Immunology Today,1999,20(4):196.
[16]Matthyssens G,Hozumi N,Tonegawa S.Somatic generation of antibody diversity[J].Nature,1983,302(5909):575-581.
[17]Castro L,Zuben F.Artificial immune system,Part 1 basic theory and applications[J].International Journal of Electrical Power&Energy Systems,1999,33(1):131-136.
[18]Simões A,Costa E.Improving the genetic algorithm's performance when using transformation[J].Artificial Neural Nets&GeneticAlgorithms,2003,20(2):175-181.
附中文参考文献:
[1]吴聪聪,贺毅朝,陈嶷瑛,等.求解0-1背包问题的二进制蝙蝠算法[J].计算机工程与应用,2015,51(19):71-74.
[3]孔祥勇,高立群,欧阳海滨,等.无参数变异的二进制差分进化算法[J].东北大学学报:自然科学版,2014,35(4):484-488.
[6]常新功,刘文娟.结合远离最差策略的自适应量子进化算法[J].计算机科学与探索,2014,8(11):1373-1380.
[9]贺毅朝,王熙照,寇应展.一种具有混合编码的二进制差分演化算法[J].计算机研究与发展,2007,44(9):1476-1484.
[10]曾智,杨小帆,陈静,等.求解多维0-1背包问题的一种改进的遗传算法[J].计算机科学,2006,7(7):220-223.
[12]武慧虹,钱淑渠,徐志丹.克隆选择免疫遗传算法对高维0/1背包问题应用[J].计算机应用,2013,33(3):845-848.

QIAN Shuqu was born in 1978.He received the M.S.degree in operations research and control theory from Guizhou University in 2007.Now he is an associate professor at Anshun University and is pursuing the Ph.D.degree at College of Automatic Engineering,Nanjing University of Aeronautics and Astronautics.His research interests include computer intelligence,complex system modeling and control,etc.He has published more than 20 papers, presided 4 scientific research projects,including the National Natural Science Foundation and the Science and Technology Foundation of Guizhou Province.
钱淑渠(1978—),男,安徽枞阳人,2007年于贵州大学获得硕士学位,现为安顺学院副教授,南京航空航天大学自动化学院博士研究生,主要研究领域为智能计算,复杂系统建模与控制等。发表学术论文20余篇,主持国家自然科学基金1项、贵州省科技计划基金2项、贵州省教育厅自然科学基金1项。

WU Huihong was born in 1980.She received the M.S.degree in application mathematics from Yunnan University in 2009.Now she is an associate professor at Anshun University.Her research interests include intelligence optimization,group and graph,etc.She has published more than 10 papers,presided 2 scientific research projects,including the Science and Technology Foundation of Guizhou Province.
武慧虹(1980—),女,山西太原人,2009年于云南大学获得硕士学位,现为安顺学院副教授,主要研究领域为智能优化,群与图等。发表论文10余篇,主持贵州省科技计划基金1项,省教育厅优秀人才创新基金1项。
Improved Clonal Selection Algorithm for Solving High-Dimensional Knapsack Problem*
QIAN Shuqu1,2+,WU Huihong2
1.College ofAutomation Engineering,Nanjing University ofAeronautics andAstronautics,Nanjing 210016,China
2.School of Sciences,Anshun University,Anshun,Guizhou 561000,China
+Corresponding author:E-mail:shuquqian@163.com
Since clonal selection algorithm(CSA)on high-dimensional knapsack problems(KPs)can only obtain a low feasible rate,and falls easily into local search,this paper proposes an improved clonal selection algorithm(CSAER)to solve high-dimensional KPs.In CSA-ER,a receptor editing mechanism is developed based on antibodies diversity function in immune system.Also,a repeat repair strategy is introduced to enhance the ability of handling constraints.CSA-ER is compared with several variants of CSA(CSA-M,CSA-E,CSA-MR)and two other intelligent algorithms on KPs in simulation experiments.The results show that CSA-ER has strong exploitation and convergence capability.Meanwhile,the sensitivities of three parameters(selection rate α,editing rate Tr,and basic gene segment length σ)in CSA-ER are also analyzed,and the appropriate parameter settings are obtained in the last.
high-dimensional knapsack problem;clonal selection algorithm(CSA);receptor editing mechanism;repair strategy
10.3778/j.issn.1673-9418.1511066
A
TP306.03
*The National Natural Science Foundation of China under Grant No.61304146(国家自然科学基金);the Science and Technology Foundation of Guizhou Province under Grant No.20152002(贵州省科技计划基金);the Science and Technology Reward Program for Excellent Creative Talents of Guizhou Province under Grant No.2014255(贵州省教育厅优秀创新人才支持计划基金).
Received 2015-11,Accepted 2016-03.
CNKI网络优先出版:2016-03-07,http://www.cnki.net/kcms/detail/11.5602.TP.20160307.1710.006.html
摘 要:针对克隆选择算法(clonal selection algorithm,CSA)求解高维背包问题(knapsack problem,KP)时可行抗体比率低且易于陷入局部搜索的问题,充分挖掘免疫系统的抗体多样性机理,提出了受体编辑机制,并设计了二次修补策略增强约束处理能力,获得了改进的克隆选择算法CSA-ER(clonal selection algorithm with receptor editing and repair)。数值实验将CSA-ER与CSA的一系列变体(CSA-M、CSA-E、CSA-MR)及两类其他群智能算法应用于两类KP进行了仿真比较,结果表明CSA-ER具有较强的开采和收敛能力。同时对CSA-ER的3个参数(克隆选择率α、编辑率Tr及基因段基准长度σ)进行了敏感性分析,获得了合适的参数选择策略。
猜你喜欢
阅读(高年级)(2022年9期)2022-10-08
今日农业(2021年1期)2021-11-26
国际种业前沿动态(2020年18期)2020-12-23
新闻传播(2018年11期)2018-08-29
新闻传播(2018年13期)2018-08-29
哈尔滨医药(2016年3期)2016-12-01
科学24小时(2016年11期)2016-11-08
新闻传播(2016年9期)2016-09-26
癌变·畸变·突变(2016年3期)2016-02-27
新闻传播(2015年7期)2015-07-18
