
样品温度对植物油的近红外定性分析模型的影响
2016-12-26 06:22宋志强曾路路何东平亓培实
中国粮油学报 2016年4期
涂 斌 宋志强 郑 晓 曾路路 尹 成 何东平 亓培实
(武汉轻工大学机械工程学院1,武汉 430023)(武汉轻工大学食品科学与工程学院2,武汉 430023)(武汉百信环保能源科技有限公司3,武汉 430023)
样品温度对植物油的近红外定性分析模型的影响
涂 斌1宋志强1郑 晓1曾路路1尹 成1何东平2亓培实3
(武汉轻工大学机械工程学院1,武汉 430023)(武汉轻工大学食品科学与工程学院2,武汉 430023)(武汉百信环保能源科技有限公司3,武汉 430023)
主要研究不同的样品温度对基于激光近红外食用植物油分类模型预测能力的影响。选择样品温度分别为30、40、50、60 ℃作为研究对象,利用激光近红外光谱仪采集4种温度下的合格食用油样品的光谱数据,用标准正态变量变换(SNV)对光谱数据进行预处理,应用支持向量机分类(SVC)方法建立独立温度分类模型和混合温度分类模型,然后采用遗传算法(GA)对模型参数组合(C,g)进行寻优,确定最佳参数组合,利用建立的8个模型对4种不同温度下的预测集样品分别进行预测。试验结果表明:某个样品温度下的独立模型对于该温度下的样品的预测准确率较高,但是对于其他温度下的样品的预测准确率不够理想;混合模型对不同温度的样品预测能力相对较好,具有更好的预测稳定性和温度适应性。研究表明:样品温度对模型的预测能力有很大的影响,是建立食用植物油分类模型过程中需要考虑的重要变量。
油脂 激光近红外 样品温度 模型 遗传算法 支持向量机
由于计算机技术、光谱技术和化学计量学的快速发展,近红外光谱分析技术(Near Infrared Spectrum,NIRS)因其分析速度快、效率高、样品无需预处理、无损分析和易于实现在线分析等特点,在医药、食品、烟草、农业和石化等行业得到了广泛的应用[1-3]。由于近红外光谱分析技术所拥有的优点,国内外许多学者应用近红外技术对植物油脂进行品质分析,刘莹等[4]利用研制的近红外山茶油品质分析系统,对搀兑玉米油的山茶油进行体积分数的建模与预测,结果显示,体积分数的预测值与真实值基本一致,能够实现山茶油的品质分析。Julia Kuligowski等[5]结合近红外光谱技术与偏最小二乘法建立1个全局模型和4个子模型,对煎炸油中的聚合甘油三酯(polymerised triacylglycerides,PTG)进行定量预测,结果显示,5个模型都能实现PTG含量的预测,其中全局模型预测效果更好、更准确。一般近红外光谱分析流程包括:第一步,分析样品,分析样品的组成成分,可能出现波峰、波谷的波段;第二步,建立数学模型,研究适合待测物光谱数据预处理、建模方法等,应用最佳建模参数建立可以应用于分析的数学模型;第三步,优化并确定模型参数,确定最优建模参数;但是建立的数学模型一般只能适应一定的时间和空间范围,随着测量时间、光程、样品温度和样品状态的改变对模型的预测能力和稳定性产生一定的影响[6-9]。加热对样品的含氢基团产生影响,导致吸光度变化,即不同温度的样品的光谱存在差异,容易造成待测样品温度与建立数学模型时的温度有较大差别时预测结果偏差较大。在特定条件下采集的光谱,建立的模型,只适应于该条件下的样品品质分析,对于其他条件下的样品的品质分析的结果不理想,影响模型的推广应用,同时制约了近红外光谱分析技术的发展[10-12]。
本试验采用激光近红外光谱仪采集食用油的光谱,以新型的超辐射发光二极管(super luminescent Light Emitting Diode, SLED)作为光源,具有宽光谱、高能量、低噪声和小发射角等特点,不仅消除了卤钨灯热效应,避免因卤钨灯发射的紫外等光谱的能量转化为热能,对仪器和样品起到加热作用,而且线性度、单色性更好。同时食用油是多种脂肪酸甘油三酯的混合物,其化学成分含氢基团(C-H、O-H)振动的合频和倍频的吸收区与近红外光谱区是一致的,因此近红外适用于对食用油的快速检测[13]。试验中以样品温度为变量,在其他条件不变的情况下,采用支持向量机(Support Vector Machine,SVM)方法建模,应用遗传算法(Genetic Algorithm,GA)进行参数寻优,研究样品温度对于植物油脂分类模型预测能力的影响,找到消除样品温度对模型预测准确性和稳定性影响的建模方法。
1 材料与仪器
1.1 试验样品
试验样品来源包括在武汉各大超市购买的不同品牌、不同种类的合格植物食用油以及一些油脂生产厂家提供的合格食用油共7类,总共79个样品,见表1。试验采用K-S(Kennard-Stone)算法按3∶1的比例选取校正集和预测集样本,随机选择60个样品组成校正集,其余的作为预测集,其中校正集样本用于模型建立,预测集样本用于模型预测性能的检验,以预测的准确率来判别所建模型的好坏。

表1 样品的种类、数量
1.2 试验仪器与软件
试验中采用课题组研制的植物油脂激光近红外检测仪采集光谱,主机为美国Axsun科技公司生产的Axsun XL410型激光近红外光谱仪,光谱测定范围为1 350~1 800 nm,扫描次数32次,分辨率为3.5 cm-1,信噪比(250 ms,RMS)>5 500∶1,测量方式为透射,可以选用2、5、10 mm光程的比色皿,温控范围为20~100 ℃,可以准确的控制样品温度;本次试验主要采用:50 μL移液枪,石英比色皿(2 mm光程),数显恒温水浴锅;基于MATLAB_2012a平台自主设计的光谱数据处理系统,主要包括光谱的预处理、特征波长提取、模型的建立、未知样品预测等功能。
1.3 试验方法
针对试验样品,分别保持样品温度在30、40、50、60 ℃下进行激光近红外光谱的扫描,得到4组样品光谱数据。在扫描光谱之前,把样品置于数显恒温水浴锅中,调节到相应的检测温度,待达到设定温度,静置10 min,以保证试剂瓶中的样品温度相同,每次取出1个样品进行光谱扫描。样品装样与图谱采集:取光程为2 mm比色皿,进行空载扫描,去除暗背景,使用移液管将样本注入比色皿约3/4处,将比色皿放入样品池中,恒温静置1~2 min,试验中采用仪器自带的软件完成样品图谱采集。每个样品采集3次稳定的谱图后取其平均图谱作为最终图谱,原始光谱见图1。试验期间保证室内温度(25 ℃)、湿度、光线的基本一致。

图1 原始光谱(30、40、50、60 ℃)
2 结果与讨论
2.1 技术路线
2.1.1 预处理方法
通过近红外光谱仪采集的光谱,包含丰富的信息,但是同时伴有谱带重叠严重、信噪比低等,这些影响模型好坏的因素使得必须对采集的原始光谱数据进行预处理。一般比较好的预处理方法应尽可能放大不同种类植物油样品光谱数据的差异,同时减小相同种类植物油样品光谱数据的差异,达到提高建立的模型的准确率和泛化能力。主要考察了3种预处理方法,包括:原始光谱(RWA)(不处理)、标准正态变量变换(Standard normal variate transformation,SNV)、矢量归一化(Unit vector normalization,UVN)。UVN可以消除因微小光程差异带来的光谱变动;SNV可以消除光谱的基线漂移及光程的影响。图2为SNV处理后的50 ℃光谱图。

图2 预处理光谱图
2.1.2 建模方法
本试验中将SVM作为建立模型的方法。支持向量机是数据挖掘中的一项技术,是借助最优化方法来解决机器学习问题的新工具,最初由V. Vapnik领导的AT&T Bell实验室研究小组在1995年提出的,在解决小样本、非线性及高维模式识别中表现出许多特有的优势,成为克服“维数灾难”和“过学习”等困难的强有力手段,并能够推广应用到函数拟合等其他机器学习问题中[14-15]。
试验中将原始数据作为支持向量机分类模型的输入,建立支持向量机分类(Support Vector Machine Classifier,SVC)模型,采用遗传算法(GA)进行寻优,确定影响SVC分类器准确率的惩罚参数C和径向基(RBF)参数g,使得C-SVC分类器能够更好得实现分类预测功能,同时保证有较高的分类准确率。本试验选用RBF核,因为RBF核的参数少,参数过多将会影响到模型的选择,同时实际应用表明RBF核具有很强的SVM学习能力[16]。以预测准确率的高低评价模型,准确率越高,模型的预测能力越好。
2.2 研究样品温度对模型的影响
2.2.1 温度对近红外光谱的影响
同一个菜籽油样品分别在30、40、50、60 ℃等4个温度点下按照图谱采集方法采集的近红外光谱,如图3,可以看出,随着温度的变化,同一样品的激光近红外光谱图发生了变化,其中1700~1800 nm波段的波峰、波谷位置的吸光度相比较其它波段的变化较显著。通过图3中可以看出变化是微弱的,不能够确定温度对近红外光谱是否有本质的影响,这有可能是加热的过程中含氢基团受到了破坏,导致吸光度的变化;也有可能是选择的样品数量少,存在随机性误差,因此需要进一步研究温度对样品近红外光谱的影响。

图3 4种温度下相同样品的原始光谱
2.2.2 光谱预处理
根据表2中各种预处理方法建立的模型的准确率的判断、对比,发现使用标准正态变量变换(SNV)处理的原始光谱数据建立的模型预测准确率最高,因此本试验选用此方法作为预处理方法。

表2 预处理方法的对比分析
注:建模方法为GA-SVC。
2.2.3 建立模型
2.2.3.1 独立模型
分别对30、40、50、60 ℃的光谱数据建立独立的植物油分类模型,并对建立的4个独立温度模型进行交叉检验,验证所建模型对不同温度的样品的预测能力,以预测集的预测准确率(%)为评价标准,评价结果(见表3)。
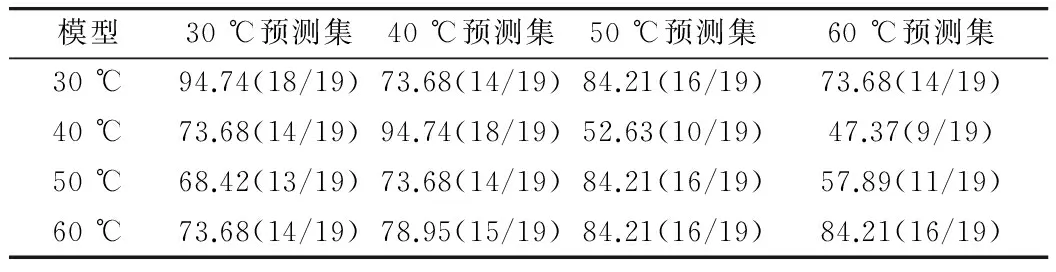
表3 独立模型交叉检验结果/%
通过表3可以看出,各个独立温度模型对该温度下的样品预测准确率均在84%以上,30、40 ℃模型的预测效果最好,预测集准确率为94.74%,出现了1个错判(见图4);50、60 ℃模型的预测能力相对差一点,但是错判数仅为3个;表明当采用相同的方法建立数学模型,不同温度下的光谱数据建立的模型的预测能力差异性很小。同时也可得出,某个样品温度下的独立模型对于该温度下的样品的预测准确率是最高的,但是对于其他温度下的样品的预测准确率仍然不够理想,温度相差越大,预测准确率越低,达不到实际应用中的需要,其中60 ℃模型相比较另两个独立温度模型的预测能力强,但是对于30、40 ℃样品预测准确率远远小于94.74%。说明独立模型的温度普适性不是很强,适合独立模型温度下的样品预测,很难实现对不同温度的待测样品进行准确预测,同时建立独立模型对试验条件有着严格的要求,一般只适合在实验室完成,不仅阻碍了模型的推广应用,而且制约了独立模型的建立。综上表明,温度对近红外光谱有实质性的影响,在不同的温度下,吸光度是变化的;独立模型单一温度的预测能力较强,多温度的预测能力相对差一点,但是随着样品温度的升高,独立模型的多温度预测能力逐渐增强;在能够保证试验条件的前提下,独立模型是最好的选择。

图4 预测集分类结果图
2.2.3.2 混合模型
从上述的独立模型的交叉检验可以看出,独立温度模型对该温度下的样品预测能力较强,但是对其他不同温度的样品预测能力相对弱一点,可以发现样品温度对模型的预测能力是有影响的。从理论上分析,加热有可能导致油脂中含氢基团破坏,影响吸光度,因此对于不同温度的样品光谱数据,是存在差异的,并且包含特有的样品温度信息。为了减小温度对模型预测能力的影响,建立了2元和3元温度混合模型,消除独立模型温度的单一性,加强模型的温度适应性,也就是增强所建模型的多温度预测能力。为了和独立模型对比,混合模型的校正集取自独立模型的校正集数据,预测集也是取自相应的预测集数据。混合模型包括混合模型1(40、50 ℃2种温度光谱集混合)、混合模型2(40、60 ℃2种温度光谱集混合)、混合模型3(50、60 ℃2种温度光谱集混合)、混合模型4(40、50、60 ℃3种温度光谱集混合),建模结果(见表4)。
从表4中看出,混合模型相比较独立温度模型,多温度预测能力、稳定性较好,错判数都是在3个左右。混合模型中包含某一温度的样品,对该温度下的样品预测准确率较高,有的甚至优于在该温度下独立模型的预测准确率。对30、40 ℃样品的预测效果仍然不是很好,错判数为3~5个,但是通过4个混合模型与4个独立模型对比,可以看出混合模型的预测稳定性、多温度适应性优于独立温度模型,究其原因,主要是因为独立温度模型的光谱数据偏少,虽然校正集和预测集的光谱数的选择具有随机性,但仍然容易造成随机误差相对偏大;混合模型的校正集包含的光谱数据是独立模型的2~3倍,减小了随机误差,提高了模型的预测稳定性和温度适应性。结果表明:虽然混合模型对某个温度的样品预测能力低于独立模型,但是对于多温度的综合预测能力是优于独立模型。在模型的推广应用过程中,当不能够满足特定温度条件的时候,可以采用混合模型。

表4 独立模型和混合模型检验预测集样本的准确率表(%)
3 结论
本试验将温度作为唯一变量引入,作为植物油分类模型预测稳定性的影响因素,采用SVC方法建立独立温度与混合温度模型。通过对比所有模型的预测准确率,结果表明:1)某个样品温度下的独立模型对于该温度下的样品的预测能力很强,对于其他温度下的样品的预测能力较弱;当能够保证试验条件时,独立模型是最佳的选择。2)混合模型单一温度预测能力相对弱一点,但是对于不同温度下样品预测能力相对较好,具有更好的预测稳定性、温度适应性;当不能够保证独立模型的温度要求,混合模型可以作为一种选择。3)温度对模型的预测能力有很大的影响,是在采集光谱数据、建立数学模型过程中需要考虑的一个重要因素。本试验只是粗略的讨论了样品温度对模型预测能力的影响,没有更加深入的解决这一问题,但是为以后建立温度修正模型提供了参考。
[1]陈蛋,陈斌,陆道礼,等.近红外光谱分析法测定菜籽油中芥酸的含量[J].农业工程学报,2007,23(1):234-237
[2]彭严芳,史新元,周璐薇,等.基于四种NIR仪器类型的清开灵注射液中黄芩苷成分的多变量检测限研究[J].光谱学与光谱分析,2013,33(9):2363-2368
[3]赵峰,林河通,杨江帆,等.基于近红外光谱的武夷岩茶品质成分在线检测[J].农业工程学报,2014(1),30(2):269-277
[4]刘莹,胡云龙.基于ARM9的近红外山茶油无损检测仪研究[J].传感器与微系统,2013,32(4):72-75
[5]Julia Kuligowski, David Carrión, Guillermo Quintás,et al. Direct determination of polymerised triacylglycerides in deep-frying vegetable oil by near infrared spectroscopy using Partial Least Squares regression[J].Food Chemistry, 2012, 131(1):353-359
[6]严衍禄 赵龙莲 李军会,等,现代近红外光谱分析的信息处理技术[J].光谱学与光谱分析,2000,20(6):777-780
[7]于海燕, 应义斌, 刘燕德. 农产品品质近红外光谱分析结果影响因素研究综述[J].农业工程学报, 2005,21(11): 160-163
[8]杜敏,吴志生,林兆洲,等.光程对清开灵注射液中黄芩苷近红外定量模型的影响[J].药物分析杂志,2012,32(10):1796-1800
[9]王冬,熊艳梅,黄蓉,等,温度对复配乳油的近红外光谱定量分析模型的影响[J].分析化学,2010(9):1311-1315
[10]Hideyuki Abe, Toyoko Kusama, Sumio Kawano.et al. Analysis of hydrogen bonding related to water in foods[J].Japanese Spectrum Research,1995,44(5):247
[11]徐志龙,赵龙莲,严衍禄.减小样品温度对近红外定量分析数学模型影响的建模方法[J].现代仪器,2004(5):29-31
[12]孔翠萍,褚小立,杜泽学,等.近红外光谱方法预测生物柴油主要成分[J].分析化学,2010(6):805-810
[13]徐广通,陆婉珍.柴油近红外光谱与性质的相关性分析[J].石油学报(石油加工),2001,17(2):91-95
[14]Vapnik, Vladimir Naumovich. The Nature of Statistical Learning Theory[M].New York:Springer-Verlag,1999
[15]司守奎,孙玺.数学建模算法与应用[M]. 北京:国防工业出版社,2011
[16]宋志强,沈雄,郑晓,等.应用近红外光谱对低碳数脂肪酸含量预测[J].光谱学与光谱分析,2013(8):2079-2082.
Effect of Sample Temperature on Near-Infrared Qualitative Analysis Models of Vegetable Oil
Tu Bin1Song Zhiqiang1Zheng Xiao1Zeng Lulu Yin Cheng1He Dongping2Qi Peishi3
(School of Mechanical Engineering, Wuhan Polytechnic University1, Wuhan 430023)(College of Food Science and Engineering, Wuhan Polytechnic University2, Wuhan 430023)(Pashun Group3, Wuhan 430023)
The paper has mainly emphasized that different sample temperature has different effect on the predictive ability based on the classification model of laser near infrared edible vegetable oil. First, three sample temperatures have been selected as 30, 40, 50, 60 ℃, respectively; the spectral data of qualified edible oil samples were collected by laser near infrared spectrometer. The spectral data were preprocessed through Standard Normal Variate (SNV), and classification model of independent temperature and classification model of mixing temperature were established by Support Vector Machine (SVM). Further, after the model parameters (C, g) being optimized by application of Genetic Algorithm (GA), the optimal parameters have been finally defined. The the prediction samples with the four different temperatures were predicted by exploiting 8 established mathematical models respectively. According to the analysis, at a certain temperature, independent model had high predicting accuracy in the temperature, while it was far from ideal for the samples in the other temperature. Hybrid model had the better predicting stability and thermal adaptability on the ability of predicting samples at different temperatures. The results showed that sample temperatures had great effect on the predictive ability of classification model, which could be a very important variable in establishment of classification model of edible vegetable oil.
oil, laser near infrared, sample temperature, model, genetic algorithm, support vector machine
O657.3
A
1003-0174(2016)04-0133-05
“十一五”国家科技支撑计划(2009BADB9B08),武汉市科技攻关计划(2013010501010147),武汉工业学院食品营养与安全重大项目培育专项(2011Z06)
2014-09-29
涂斌,男,1990年出生,硕士,智能检测技术
郑晓,男,1958年出生,教授,油脂压榨原理与智能检测
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
温州大学学报(自然科学版)(2022年2期)2022-05-30
健康之家(2021年19期)2021-05-23
空间科学学报(2021年1期)2021-05-22
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
潍坊学院学报(2020年2期)2021-01-18
中国交通信息化(2018年5期)2018-08-21
制导与引信(2017年3期)2017-11-02
中国光学(2015年5期)2015-12-09
