
基于自动智能分类器的图书馆乱架图书检测
2016-12-26 09:58刘汝翠
现代商贸工业 2016年25期
刘汝翠


摘要:整理乱架图书是图书馆日常维护工作的一个重要组成部分。人工检测图书乱架不但费时费力而且极容易出错。为此,设计了一种结合深度学习中的SoftMax回归算法和书脊图像特征识别相结合的乱架检测算法,算法主要包括书脊定位分割、字符识别、语义特征提取以及分类判决等环节,实现了自动高效的图书乱架检测。实验数据表明本文提出的检测算法能达到近98%的检测准确率,并且还具备速度快、几乎不需要人工干预等优势,能大大降低图书馆日常图书清点工作的劳动强度。
关键词:图书馆;乱架检测;图像分割;字符识别;深度学习
中图分类号:TB
文献标识码:A
doi:10.19311/j.cnki.16723198.2016.25.087
1概述
利用现代智能处理技术特别是用计算机代替人们自动的去处理大量的图像信息,能够解决人类器官的分辨能力容易受到环境、情绪、疲劳等因素的影响,从而部分代替人工劳动,大大提高生产效率。近年来,将传统的工作进行数字化和自动化加工逐渐成为图书馆行业越来越重视的工作内容之一。但是目前的图书馆数字化工作仍存在众多没有解决的问题。
图书乱架的整理工作是图书馆日常维护工作的一个重要组成部分。由于书籍众多,当出现不同种类的图书放置在一起时,工作人员很难人工将错误放置的图书进行正确地归类,即使能够做到,也会花费很长的时间和大量的精力,导致人力资源的浪费。
2006年,深度学习(Deep Learning)开始在学术界和工业界引领发展前沿,其中深度学习认为:1)多隐层的人工神经网络学习得到的特征对数据有更本质的刻画,有利于分类和检测;2)深度神经网络在训练上的难度,可以通过“逐层预训练”来有效克服。基于深度学习的图像视觉识别技术已经在许多行业中得到了应用,如检验零件的质量;识别工件及物体的形状和排列形态等。
本文结合图书馆日常管理中遇到的图书乱架这一实际问题,以书脊视觉图像为切入点,引入深度学习中的SoftMax回归,设计出一种包括单册图像分割、字符识别、语义特征提取以及归类判别等环节的图书乱架检测算法,其有效性已在实验中得到较好的验证。
2书脊图像的定位分割
由于获取的图像有可能会出现模糊,因此需要对图像进行预处理。将拍摄的书脊图像近似看成平稳过程,使用Wiener滤波器进行幅度相位去模糊。Wiener滤波器的基本原理是将原始图像f和对原始图像的估计f^看作随机变量,按照使f和对估计值f^之间的均方误差达到最小的准则进行图像复原。
然后使用Canny算子进行边缘检测,并进行纵向和横向的直线跟踪,对两条直线之间的区域进行判断,如果是书脊区域,就进行分割,然后定位第二本书,直到处理完整幅图像。
图1(a)为利用Canny算子进行边缘检测出来的结果,得到了所有书籍的边缘;图1(b)是对书籍进行分割定位的结果,把定位到的目标用直线标出,以供后续处理。
3书脊图像的字符识别
由于汉字的类别较大、结构复杂和类似字多,造成汉字的识别难度比较大。传统的仅用一种特征来识别汉字的方法已不能满足汉字识别的要求。因此,本文采用了二次识别的方法对汉字字符进行识别,第一次分类利用汉字的笔画穿过数目特征,第二次是对那些首次仍不能区别开的汉字利用汉字四角的能量值密度特征进行区分。
本文的汉字特征选择了笔画穿过数目和能量值密度这两个特征。笔画穿过数目是指对汉字图像的水平、垂直两个方向进行扫描,然后统计这两个方向上扫描线出国汉字笔画的次数即得到汉字的笔画直方图,得到笔画穿过次数的特征向量。
在进行汉字特征匹配时,首先对待识别的汉字笔画穿过数目特征进行提取,记该特征为C。识别时,首先计算待识别汉字与标准库中汉字的距离d,d定义为待识别汉字的笔画穿过数目矩阵C与标准库中汉字的笔画穿过数目矩阵B的对应值差值的绝对值之和,其表达式为
d=∑ni=1∑mj=1cij-bij
式中cij为矩阵C中的元素,bij表示矩阵B中的元素。
给定一个阈值σ,若距离dσ,则该字不能被识别,否则把该字放入二级识别队列中,如果二级队列中只有一个字,就判别这个字为要识别的字,若二级队列中不只一个汉字,则要对二级识别队列中的汉字进行二级识别。
在二级识别里用能量值密度作为特征,提取这些汉字的能量值密度。设一阈值为ε,计算待识别汉字的能量值密度矩阵和标准库汉字的能量值密度矩阵中对应值的绝对值之和,差值最小的汉字判别为要识别的汉字。
4语义特征提取
利用识别出来的字符,对其进行语义特征的提取,以判断书籍属于哪一类。首先通过在原始文本语义空间提取文本的局部分布信息,构造拉普拉斯矩阵和局部密度矩阵,然后通过奇异值分解SVD和广义特征值分解GEVD求解特征变换矩阵,最后实现文本数据的降维空间聚类。
给定m个文本数据的原始特征语义空间描述X=(x1,x2,…,xm)T,这里xi为文本i的特征向量描述,包含文本类别信息相关的关键词、主题词以及文本中出现的高频词等描述信息,并且xi中的每一个特征元素记录了这些词条的重要程度和出现的频度。
对X按列进行基于欧几里得距离的kNN近邻算法获取点向量xi的k个邻近点N(xi),并采用高斯核将邻接点向量的欧几里得距离转化为相似度:
sij=exp(-xi-xj2),xj∈N(xi)
得到文本集X的相似矩阵S,该矩阵为对称矩阵。通过矩阵S构造对角矩阵D,其中dii=∑jsij,令L=D-S,为谱图数据的拉普拉斯矩阵,为对称矩阵。利用局部密度矩阵D求取文本向量均值=∑ixidii∑idii,并将文本归一化i=xi-,对归一化的进行奇异值分解,降低文本的语义维度,简化数据描述。并通过非监督判别分析得到降维文本语义空间,即判别语义特征提取,获取分类判别能力最强的前l个语义特征。
在特征提取后的降维空间采用k-means聚类,进行文本分类,即语义特征的提取。
5书籍乱架放置的判别
进行了语义特征提取之后,为了检测书籍的乱架放置。因此,需要将提取到的语义特征进行分类。为了尽可能准确地进行分类,采用深度学习的方法进行模型的训练。其中训练过程分为两个阶段:贪心的逐层预训练和整个模型的全局微调。
在逐层训练预阶段,每次只训练模型的一层,然后将当前层的输出作为下一层的输入,进行下一层的训练,直到预训练完所有的层。
在模型的全局微调阶段,由于乱架放置的书籍的种类可能是多个,所以采用softmax回归多类分类器。Softmax回归多分类器是logistic回归模型在多分类问题上的推广,在多分类问题中,类标签y可以取两个以上的值。假设共有k个类别,则softmax regression的系统方程为
hθ(x(i))=p(y(i)=1|x(i);θ)p(y(i)=2|x(i);θ)p(y(i)=k|x(i);θ)=1∑kj=1eθTjx(i)eθT1x(i)eθT2x(i)eθTkx(i)
其中,x(i)为第i个输入样本,θ为系统参数,p为样本取特定类别时的概率。
此时,系统的损失函数方程为:
J(θ)=-1m∑mi=1∑kj=11y(i)=jlogeθTjx(i)∑kl=1eθTlx(i)
其中,1·是一个指示性函数,即当大括号中的值为真时,该函数的结果就为1,否则其结果为0。θ为代价最小化时所需要满足的系统参数。实际实现时,首先使用具有先验归属标记的书籍信息样本按照以上方式对书籍归属学习器进行训练,得到训练好的归属规则学习器。将提取的书籍信息输入到归属规则学习器,学习器输出到归属规则库进行书籍类别的判别,将判别出来的结果输入到乱架判决器,进行乱架检测,如果检测出来有书籍分错类,则会输出乱架警报。
6实验结果与分析
利用书脊检测出来的结果,进行字符检测并对检测出来的字符进行语义识别,判断某一本书是不是放错了类别,如果放错,则框出放错的书籍并发出警报。
图2(a)中都是科技类的书籍,并没有其他类的书籍,所以输入的这张图片并不会输出乱架报警;图2(b)中除了科技类的书籍之外,还有一本建筑类的书籍混杂其中,所以系统会把这本书检测出来并用交叉直线醒目地标示出来。
中除了科技类的书籍之外,还有一本美术类的书籍混杂其中,所以系统会把这本书检测出来并用直线标示出来。
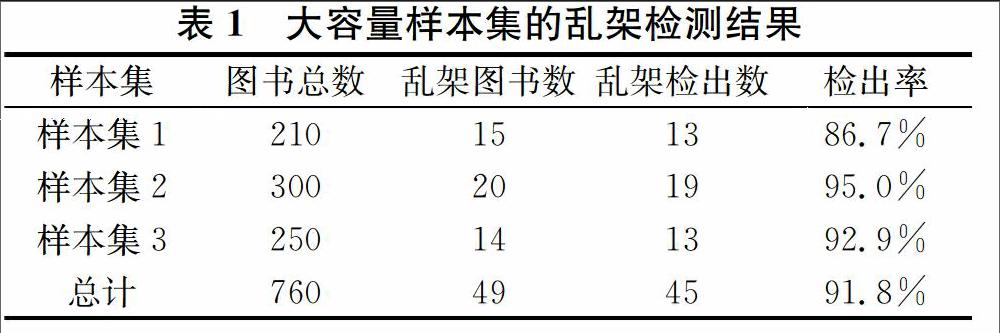
图2和图3只是笔者为了演示系统的运行效果而给出的个例图示,限于篇幅所限不能穷尽所有曾经检测处理过的案例。笔者曾经对科技类、哲学类和艺术类为主体的大容量样本集的乱架图像进行了分析,每个样本集的分析耗约为300~320秒,大大高于人工检测的速度。乱架检测实验的样本集实验结果列于表1之中。
7结论
在图书馆系统中利用机器视觉的方法进行书籍定位和检测是视觉研究的一个重要方向。本文给出了一种综合运用相关视觉图像技术对乱架图书进行自动检测的系统设计。实验表明,该方法可通过程序设计完全有计算机自动实现,平均检出率超过90%,速度快稳定性好,处理时间大大小于人工检测时间,并且能够在很大程度上降低图书管理员的劳动强度,有助于提高大型图书馆的架上书籍整理效率。
参考文献
[1]李因易.图像处理技术在图书馆藏书清点中的应用研究[D].贵阳:贵州大学,2006.
[2]方建军,杜明芳,庞睿.基于小波分析和概率Hough变换的书脊视觉识别[J].计算机工程与科学,2014,(36):126131.
[3]何耘娴.印刷体文档图像的中文字符识别[D].秦皇岛:燕山大学,2011.
[4]D.-J. Lee,Y.Chang,J. K.Archibald,C.Pitzak.Matching book-spine images for library shelf-reading process automation[C].in Automation Science and Engineering,2008.CASE 2008. IEEE International Conference on, 2008:738743.
[5]戴臻.内容文本分类中的语义特征提取算法研究[D].长沙:中南大学,2010.
[6]Y.Bengio, Learning deep architectures for AI[J].Foundations and trends in Machine Learning, 2009,(9):1127.
[7]Y. Bengio.Deep Learning of Representations for Unsupervised and Transfer Learning[J].in ICML Unsupervised and Transfer Learning,2012:1736.
[8]P.Baldi. Autoencoders, Unsupervised Learning,and Deep Architectures[J].in ICML Unsupervised and Transfer Learning,2012:3750.
[9]Y. Bengio,P.Lamblin,D. Popovici,H. Larochelle.Greedy layer-wise training of deep networks[J].Advances in neural information processing systems,2007,(19):153.
[10]郑胤,陈权崎,章毓晋.深度学习及其在目标和行为识别中的新进展[J].中国图像图形学报,2014,19(2):175184.
猜你喜欢
成都信息工程大学学报(2017年3期)2017-11-09
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
河南科技(2014年3期)2014-02-27
