
一种基于分层智能混合决策的多Agent框架*
2017-02-17 03:05冯进朱江沈寿林
火力与指挥控制 2017年1期
冯进,朱江,沈寿林
(南京陆军指挥学院,南京210045)
一种基于分层智能混合决策的多Agent框架*
冯进,朱江,沈寿林
(南京陆军指挥学院,南京210045)
智能对于指挥决策模型非常重要,也是提高模拟训练和作战实验质量的关键。作战中指挥决策内容多,问题性质不一,对智能要求高。在分析指挥控制模型发展现状基础上提出模型对智能的需求,分析设定了智能的5个层次,提出一种混合Agent框架,并在框架中对每一层智能给出解决方案,框架兼具认知Agent、BDI Agent和刺激反应Agent的优长,对构建智能化的训练和实验系统有较大帮助。框架在指挥装备作战运用实验中得到应用,具有较好的理论意义和应用价值。
智能,多Agent,指挥控制,决策模型
0 引言
当今,模拟训练和作战实验对指挥决策模型的要求日益增高。模拟训练需要解决导调人员偏多,人工干预过频,模拟蓝军不像的问题;作战实验需要解决实验可信度不高、难以自动探索想定空间的问题。这对指挥决策模型的智能性提出了需求。
传统指挥控制使用僵死的、静态的公式,无法建模认知、无法体现智能。1998年,美国国防部DMSO指出目前决策模型存在的缺陷与具体的改进方法,成立“人员行为和指挥决策建模”专家组,展开了前瞻性研究。在个体决策方面,Klein在1998年提出识别决定(RPD)模型,使军事决策者在困难环境和有时间压力的情况下决策;Rasmussen和Vicente的Decision模型对指挥中的认知决策过程进行描述;Bryant于2003年提出了批评、评估、比较和适应(CECA)模型,该模型以目标导向的心理模型为基础,给出认知控制方法,能揭示指挥决策中的对抗机制。美军提出一种较新的框架——PMFService集成框架,PMFService由DMSO资助,以现有各种行为建模文献中所包含的关于个人认知模型为基础建立的一个统一的行为体系结构,旨在描述生理、压力、个性、文化、情感和社会关系对人进行决策的影响,并利用该框架模拟美军士兵、恐怖分子和民众的行为,重演美军在索马里的“黑鹰坠落”事件。
Agent内部过程与指挥决策过程有自然的相似之处,还可以构建信念、个性、压力、感情[2-7],这类似于一个鲜活的人。目前,使用Agent构建指挥实体是各国军队的主流做法。美军就明确提出基于A-gent来构建指挥实体,从上世纪90年代执行CFOR计划,开发一类具有完全自主能力的合成指挥实体(主要是营、连级别),它具有任务分析、计划作业、通信协调、指挥控制、战场监视、任务监视等功能。1997年,美军考虑了战场压力、疲劳程度、训练水平及个人差别,设计一个能有效仿真更高指挥层次的高级指挥模型ASTT-ASCF,使指挥Agent具有智能性和真实性[1]。国内也有构建具有认知能力和学习能力的Agent相关研究[8-9]。
1 指挥决策对智能的需求
智能由低到高划分为简单的反应、组合的反应、学习、推理、综合等层次,高级智能行为往往比较复杂,执行需要更多的时间,而低级智能行为往往简单而迅捷。
指挥决策涉及不同层次的指挥所、指挥装备实体,其指挥决策内容不同,对智能的需求也不同。对于指挥装备,它们对技术操作层面产生的物理行为进行决策,要求能感知环境、察觉和说明态势、判断和控制动作,通常决策突然且情况严峻,需要在很短的时间内作出反应,对简单的反应、组合的反应等智能行为较为青睐。
对于分队以上的高级指挥所,通常根据战斗使命,对将来作推理和规划,在一定的时间约束以及资源约束范围内形成一个行动序列方案,生成命令传递给低级指挥所和行动实体。这种人工智能范畴的任务规划,实际上是一种问题求解技术,即要具有识别对象和事件的能力、表达环境模型中的知识、发现一系列行为或构造一系列步骤,以达到最优或满意的解决方案。这往往需要学习、推理以及综合的智能行为。
2 混合Agent框架设计
体系结构决定了模型的整体结构形式和运行方式,目前有很多Agent体系结构[10-11],主要归类为慎思式体系结构(BDI Agent)和反应式体系结构(刺激反应Agent)。作战过程是动态变化的过程,一般都会包含变化着的作战目的,慎思式体系结构的规划库难以穷尽所有作战目的,而反应式体系结构面临着如何将作战目的融入到个体所感知的具体局部激励信息。它们都存在难以克服的弱点,即如何执行上级全局意义的命令。
本文设计一种用于指挥决策的混合Agent框架,Agent是各层次的指挥实体,框架的示意如图1。指挥Agent内部都有一个感知、认知、决策、行动的过程,Agent内部模块包括:①通信模块。主要负责指挥Agent与外部的通信联络,体现指挥Agent间的交互,指挥命令的上传下达等。②感知模块。主要负责指挥Agent感知战场态势和外部环境的变化。③决策模块。是指挥Agent的核心,它针对所要达成的目标,进行作战决策,并产生作战行动过程序列。④执行模块。产生指挥Agent的输出,产生状态空间的轨迹(运动),表现为行动过程序列;最终以并行或者串行的方式向战场输出移动、射击、防护、通信等动作;⑤知识库。是进行推理的知识来源,它包括对世界的认识模型,还包括战术规则库和经验知识库,战术规则用来进行战术推理,而经验知识用于处理紧急战场情况。
Agent在输出物理动作过程中产生与战场环境之间的能量、信息和物质交互,执行的结果也通过实体内部状态、环境的改变以及其他实体的行为改变来体现。
3 智能的实现
3.1 智能级别1:简单的反应
简单的反应是Agent为应对外部刺激而作出的简单决策。其依据自身状态和外界环境的改变或其他实体行为的改变引起触发事件,并通过刺激-反应规则来动态地改变自己的行为。在上世纪60年代初期,科学家只构建激励-响应,而不考虑心智、意识,这是一种简单的智能。
If满足条件Then执行行动
在执行过程中根据各触发器的优先级开启相应的触发器。一般认为,命令触发器具有较高的优先级、状态触发器次之、态势触发器最低。
3.2 智能级别2:组合的反应
组合的反应是应用一组具有领域知识的组合。相比较孤立的规则,把注意力集中在让规则链接起来控制规则的交互影响。组合反应可用下式表示:
其中,Ω是对领域的认识,Ω=(D,P,T,A),D包含了Ω所能观察到的所有领域特性,P是Ω的问题域,包含了所发生的状态,T是一个自然规律集,能解释P中所有状态。A是Ω中关于P的回答集,A中每一个元素都是关于某个状态P的回答。


例如,建立基于个性的行动决策。Ω就是个性所在心理学领域的相关认识,P'是要表示的个性集合,F是将真实心理学个性映射到Agent的决策个性,采用的是个性因子的表达:
个性因子有6类,ω1为冒险因子,ω2为保守因子,ω3乐观因子,ω4悲观因子,ω5冲动因子,ω6理智因子。I是方法集,对冒险与保守,引入效用曲线实现;乐观与悲观可通过权重方程体现;冲动与慎思可通过设置抑制阈值实现等,R就是在决策个性下Agent行动。
If Agent具有某种个性,当满足条件时Then执行行动。
3.3 智能级别3:学习
学习是根据经验,通过泛化增强规则。Agent实体通过不断尝试,初始时,选择一个行动的倾向(Propensity),然后,根据各个行动的倾向计算选择概率,按概率选择行动,并根据该行动的回报调整其倾向。作用于环境,导致某种反馈,从环境中得到奖惩的方法来不断地“学习”和“积累经验”,从而发现或逼近能够得到最大奖励的策略。常常采用Q-Learning算法、Roth-Erev算法等。
在Roth-Erev算法中,实现中关键的两步是行动倾向的更新和从倾向到概率的转化。行动倾向的更新方法为:
其中,变量t为时刻,qi为选择行动j的倾向,k为上次选择的行动,rk为选择行动k的回报,N为所有行动的个数,ξ为经验系数,φ是更新系数。
上式含义为对上轮采取的行动k,其新的选择趋向是以前的选择倾向和上轮所获回报的组合,回报越大,该行动倾向的增量也越大,而其他行动的选择倾向以相同程度发生小的调整,这样随着主体行动历史,获得较高回报的行动选择倾向会增大,而低回报的行动选择倾向会减少。
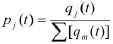
3.4 智能级别4:推理——规则发现和规则构建
前述的3个级别智能,都与规则有关,但不能在多层次上推理,也不使用带有约束的模型,不从多个角度观察问题,也不知道何时破除固有规则。简单的启发式规则对待优化问题较难适应,当这种Agent在涉及复杂的路径规划、任务分配、协同等决策任务时不能胜任。
Agent的BDI(Belief,Desire,Intention)模型借鉴了心理学的研究成果,对于一些未知情况模拟人的思维进行假设,重在描述人的思维状态属性,强调行为由其内部状态,即心智状态驱动,在变化的环境中,通过改变心智状态作出适应环境的行为。其具有心智,能自我推理,发现规则和建立新的分辨率层次。
该模型侧重于形式化描述信念、愿望和意图,当涉及到意图、信念等的决策表达,可以使用BDI框架,它是一个符号世界模型和推理引擎,处理信息在高层次的抽象,提供计划和作出决策。信念是指挥Agent的当前状态,是指它所拥有的关于陆军作战指挥相关的背景知识以及所面对的战场态势,包括对敌情、我情和友情的感知以及在知识库、模型库、数据库支持下的对当前态势的分析判断、评估和预测。愿望是指挥Agent在感知战场情况后,要达到的作战目标。它是指挥Agent一切行为的起始点。指挥Agent的愿望就是根据当前变化的态势、对态势的分析以及要达到的作战目标,在知识库、模型库和数据库的支持下而进行的决策与规划。意图是指挥Agent为实现愿望准备采取的具体的行动计划,包括作战计划的制定、计划协调与作战命令的生成,是指挥Agent根据作战方案、兵力兵器情况,通过与其他指挥Agent的协调进行作战计划制定的过程,也是作战任务与作战兵力、武器装备进行匹配的过程。
3.5 智能级别5:综合
综合是智能的高级阶段,将多种智能方式结合可以在自主地应对变化(反应式体系结构)和有序地调控作战(慎思式体系结构)之间平衡。指挥决策中很多情况需要规划,采用BDI的慎思结构进行决策。但是,当任务主题的明确或者训练产生的条件反射,可以存在“蛙跳”现象,即不许复杂的规划,而是从信息输入阶段直接进入了输出控制阶段。这就是刺激-反应架构进行决策,当有特殊的信息如战场情况发生剧变有可乘战机,需要马上采取行动,则将信息送往紧急反应模块。
还有决策不是一次性的,通过对环境的感知和交互,常需保持对作战行动的跟踪,看是否决策有效,如果情况发生变化,则立即进行重新决策。每一次决策情况又可用来学习。构建对被分配任务的响应和学习规则,据此调整各自的行为策略,表现出决策在时间轴上不间断的优化与适应。
4 结论
运用多层智能的混合Agent框架有以下特点:①由于指挥实体Agent的封装性和独立性较强,具有较好的模型重用性,可以使一些成熟、典型的A-gent得到广泛应用;②Agent具有自主性、学习性,能够像人一样决策,并能够学习以前的行为结果、任务完成情况的反馈以及其他Agent的行为,从而改变自身的行为策略,不断优化,增强智能;③是A-gent内部过程与指挥决策过程有自然的相似之处,指挥Agent能够接收其他Agent和外界环境的信息,并按照自身规则和约束对信息进行处理,并输出命令,代替指挥所完成既定任务。
由于人工智能技术发展的限制,指挥实体的信念、愿望、意图等难以刻画,认知行为模型有待完善。认知生命和智能依然隐藏着未知的机制。目前人工智能领域对这些机理的研究还举步维艰,这些约束了认知、思维建模向深层次发展。本文还是一个探索阶段,有待进一步提升实用性和系统性。
[1]DEBORAH V.Commander behavior and course of action selection in JWARS[C]//Proceedings of the 10th CGF&BR Conference,2001.
[2]MARIA S,CMY H,JOHN P.A common architecture for behavior and cognitive modeling[C]//2003 Conference on Behavior Representation in Modeling and Simulation,2003.
[3]CORY W,SCOTT N R,KAREN A H.Buliding a human behavior model for collaborative air-combat domain[C]//2006 Conference on Behavior Representation in Modeling and Simulation,2006.
[4]TURKIA M.A computational model of affects[C]//Simulating the Mind.Germany:Springer,2009:277-289.
[5]BARTENEVA D,LAU N,REIS L P.A computational studyonemotionsandtemperamentinMulti-agentsystem[DB/OL]2008,http://arxiv.org/abs/0809.4784.
[6]SLATER S,MORETON R,BUCKLEY K,et al.A review of agent emotion architectures[DB/OL].2008.http://www.eludamos.org/index.php/eludamos/article/viewArticle/44.
[7]BECKER C,LESSMANN N,KOPP S.et al.Connecting feelings and thoughts-modeling the interaction of emotion and cognition in embodied agents[C]//Proceedings of Seventh International Conference on Cognitive Modeling(ICCM-06).Ann Arbor,Michigan,USA,2006:32-37.
[8]韩月敏,林燕,刘非平,等.陆战Agent学习机理模型研究[J].指挥控制与仿真,2010,32(1):13-17.
[9]胡记文,尹全军,冯磊,等.基于前景理论的CGF Agent决策建模研究[J].国防科技大学学报,2010,32(4):131-136.
[10]JOHN A S.Enhanced Military Modeling Using a Multi-A-gent System Approach[C]//Proceeding of the 12th ICCRTS,2007.
[11]COSTANTINI S,TOCCHIO A,TONI F,et al.A multi-layered general agent model[C]//Artificial Intelligence and Human-Oriented Computing.Italy Rome:The 10th Congress of the Italian Association for Artificial Intelligence on AI*IA,2007:121-132.
A Hybrid Agent Architecture Based on Hierarchical Intelligence
FENG Jin,ZHU Jiang,SHEN Shou-lin
(Nanjing Army Command College,Nanjing 210045,China)
Modeling intelligence is very important for erecting C2(Command and Control)decision model,which is a key factor to improving the quality of simulation training and combat experiment.In joint combat senario,construction of decision model are used to meet various problem,and claim for different level of intelligence.This article analyses the current situation and the future requirements of modeling intelligence.A hybrid Agent architecture is proposed and five levels of intelligence are contained as a solution.The architecture contains both the advantages of the BDI Agent and the IFThen Agent.It benefits modeling training or experiment system with intelligence.This framework has been applied in C2 equipment combat application experiment,and it proved to have good significance and applied value.
intelligence,multi-Agent system,command and control,decision model
TP391.9
A
1002-0640(2017)01-0036-04
2015-10-05
2016-01-07
国家自然科学基金资助项目(71401177)
冯进(1980-),男,江苏大丰人,讲师。研究方向:军事运筹。
猜你喜欢
高教学刊(2022年13期)2022-05-24
黑龙江大学自然科学学报(2022年1期)2022-03-29
小资CHIC!ELEGANCE(2022年1期)2022-01-11
建材发展导向(2021年24期)2021-02-12
中国外汇(2019年18期)2019-11-25
电子制作(2019年10期)2019-06-17
当代陕西(2019年5期)2019-03-21
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
燕山大学学报(2015年4期)2015-12-25
