
面向论文检索的同名作者区分方法
2017-03-02 08:20张新征雷鹏飞李玉坤车向东
计算机与数字工程 2017年2期
张新征 雷鹏飞 李玉坤 车向东
(1.天津市普迅电力信息技术有限公司 天津 300384)(2.天津理工大学计算机与通信工程学院 天津 300384)
面向论文检索的同名作者区分方法
张新征1雷鹏飞2李玉坤2车向东2
(1.天津市普迅电力信息技术有限公司 天津 300384)(2.天津理工大学计算机与通信工程学院 天津 300384)
作者同名问题为论文检索带来了困难。论文研究了论文检索中的作者同名问题,提出了一种面向文献检索的同名作者区分框架,并在此框架基础上提出了基于作者的单位、合作者、论文发表期刊信息对同名作者进行区分的方法。实验结果证明了论文所提出的方法的有效性。
同名作者; 文献检索; 区分
Class Number TP391
1 引言
随着互联网的发展,很多数字学术图书馆随之产生,如DBLP,CitSeer,PubMed,ACM DL,IEEE DL,知网、万方等。这些数字学术图书馆为文献检索带来了便利,并且为研究者提供了研究科学家合作网络的充足的数据集。但是如何对于大量文献的集合进行有效的检索依然是一个挑战性的问题。Lee et al.[1]认为主要挑战来自于数据输入的错误,包括检索词格式输入的错误以及输入标准的缺失,作者的同名问题以及出版地点缩写的问题等。在这些问题中作者同名问题因其固有的难度,已经引起数字图书馆研究者的极大关注。
在现实世界中会有这样的情形。当用户希望通过输入一个作者的名称从计算机文献数据库DBLP中找到需要的文章时,常常会得到大量的同名作者的文章,用户需要花费更多时间从中找出特定的一个作者的文章。比如,用户在DBLP中输入作者名称“Dong Xin”。其返回的结果中包含Xin Dong、Xin Luna Dong、Dong Xin、Tian-Xin Dong、Jing-Xin Dong等作者名字。此时用户面临两个问题: 1) 按照从实际生活中获取的信息,“Xin Dong”和”Xin Luna Dong”这两个名字对应的是现实世界中的同一个人,然而却被列为两个条目; 2) 当选择“Dong Xin”时,所有作者为“Dong Xin”的文章会返回,但其对应的可能是现实世界中不同的人。前者可以称为“异名同人”,后者可以称为“同名异人”。
实际上,重名问题早已有之,研究者们也在这个问题上花费了大量的时间,尝试了多种方法。Lizhu Zhou et al.提出了一种称为GHOST的解决问题的框架[2]。Tang Jie et al.使用了一种统一的概率模型来形式化该问题[3]。
Wu Jiang et al.提出了一种递归加强的重名区分方法结合了合作者和所在单位的信息并特别关注了合作信息和作者所在单位的变动问题[4]。Yang Xia et al.提出了一种面向中文的同名区分方法(PND)[5]。Stasa Milojevic使用模拟的书目数据集对重名区分方法的准确性得出切实的估计[6]。Ferreira et al.提出了两步区分法:SAND(Self-training Associative Name Disambiguation)[7]。Yoshida提出了使用自学习的两阶段聚簇算法来改善低召回率问题并且实现了一个用于对Web检索结果进行重名区分的系统[8]。Byung-Won On et al.提出了可扩展的图分割算法[9]。Pei Li et al.针对该问题提出了考虑记录的时间顺序并作出全局决策的聚簇算法[10]。
尽管已经存在一些关于作者重名区分的工作。然而由于问题的复杂性,同名问题依然没有得到很好的解决。基于此,本文提出了一个轻量级的在线方法,来解决在文献检索中的作者同名区分问题。
本文主要贡献如下: 1) 提出了面向文献检索的同名区分框架。 2) 提出了三个层次的解决同名区分的方法。
2 问题定义与初步解决思路
2.1 同名作者问题定义
确定作者身份包含两个层面的意义:多人同名和一人多名。很多人同名的现象在现实生活中是很普遍的。在一些拉丁语系的国家,使用首字母和缩写也经常见到。在中国,同名也是很常见的问题。当用户输入特定的作者名字来检索文献时,会返回很多的文章,尽管这些文章对应的是现实世界中不同的人
分析发现有时一个人也会对应几个不同的名字。例如,“Xin Dong“,”X.Dong”和“Xin Luna Dong”对应的是同一个人。出现这个问题的原因主要分为两个方面: 1) 拉丁国家的名字在简写时经常省略首中间名字; 2) 同一个名字会存在多种不同的表示方式。因此分类方法必须考虑作者名字不同的表示方式。
本文所要解决的问题是:对于一个论文集,当用户输入作者名称N时,将会返回所有作者中包含此名字N的文章,本文所要解决的问题就是对返回的文章进行划分,使每一个划分中的作者名字N对应现实世界中的同一个人。除此之外,不同的作者名称可能对应的是现实世界中的同一个人。所以这些文章也应该被分在同一个子集中。
图1通过一个示例对本文研究的问题进行了说明。假设用查找作者为“Xin Dong”的文章,系统返回的文章有4篇{Paper1,Paper2,Paper3, Paper4},其中Paper1对应的作者为“Dong Xin”;Paper2和Paper3对应的作者为“Xin Dong”;Paper4对应的作者名字为“Xin Luna Dong”。而现实世界的情况是:这四篇论文中的作者对应现实世界中不同的3个人,如图1所示。本文的目的是找到一种方法将输入作者名字后检索得到的文章分为若干类,使每一类中的文章对应现实世界中的同一个人。

图1 研究问题描述示例
2.2 初步解决思路
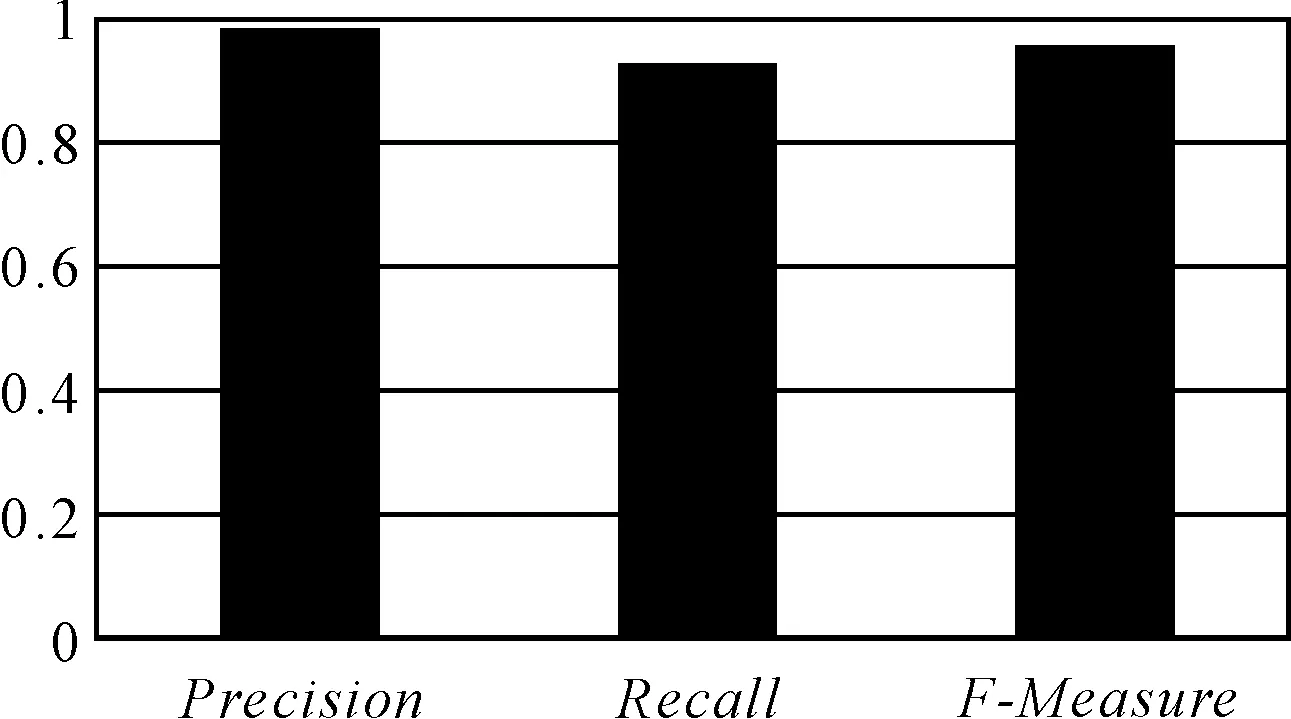
此问题可以形式化表示如下:令N为用户输入的作者名称,S为作者中包含N的论文集合。并且S表示为一个集合{Pi|1 根据人们的日常经验可以得出如下结论: 1) 不同文章的同名作者对应同一单位,那么其可能是同一个人; 2) 有相同合作者的同名作者很可能是同一个人; 3) 在相同的期刊或者会议上发表文章的文章的同名作者很可能是同一个人。基于以上结论,本文提出根据单一属性来对重名作者进行区分的初步方法。 首先是根据论文合作者来进行分类。令N为用户输入的作者名,假定P1和P2为用户输入N时的检索结果,如果两篇文章中N的合作者存在交集,则这两篇文章的作者就被认定为同一个人。 此处,将每一个作者的名字作为一个标志,使用Jaccard距离来计算论文合作者的相似度。P1,P2为两篇文章,P1.Au.Na代表文章P1的作者集,P1.Au.Na-{N}代表文章P1中名字为N的合作者,同样,P2.Au.Na-{N}代表文章P2中名字为N的作者的合作者。则Jaccard距离可以根据以下公式计算: 如果Jac>0,则认为这两篇文章对应的同名作者对应的是现实中的同一个人。 第二种初步方法是基于作者的单位,如果两个同名作者的工作单位相同,则这两个同名作者被当做同一个人。其所著文章被分为同一类。 第三种初步方法是基于论文所发表的期刊或者会议,如果两篇文章发表在同一个期刊或者会议上,在某种程度上,这将意味着两篇文章有着相似的研究方向,因此他们很可能是同一个人。 由于问题的复杂性,上述初步方法的分类效果并不太好。例如,如果某一作者更换单位,则其可能会被分到不同类中。另外现实中不同的同名作者和相同的人合作过,这些不同的同名作者会被错误地分在同一类中。 针对在第2节提出的基于单属性的初步方法的不足,本文提出了更为有效的解决方法。这种方法分为三个步骤:首先,产生文章的初始集合;其次,根据作者所在单位将文章分为不同的子集;最后,根据论文合作者和文章所发表的期刊或会议对第二步产生的子集进行聚类。 3.1 初始文章集合的产生 为了使检索结果更加完整,首先需要找出与所输入的作者名字相对应的所有的名字。获得同名作者初始集的方法为:当用户输入一个名字N时,首先获得一个N可能的其他表示形式所组成的候选集。以DBLP中的论文为例,作者的名字经常是保持固定的,所以大多数情况下作者名字的形式是规范的。但是在一些文章中,作者有中间名字,但是也有很多文章的作者没有中间名字。 本文提出了如下方法来根据用户的输入来产生可能的同名作者集。令“X(Y)Z”为用户输入的作者名,其中Y为可省略的内容,所以可能的同名作者集为:{“XZ”,“ZX“,”Z*X”,”X*Z”},此处“*”指作者的中间名字可能是任意字符串。如果未省略“Y”,可能的同名作者集为{“XYZ”,“XZ”,“ZX”}。例如,如果用户输入的作者名为“Xin Luna Dong”,可以得到可能的同名作者集:{“Xin Luna Dong”,“Xin Dong”,“Dong Xin”}。如果用户输入的作者名为“Xin Dong”,则可能的同名作者集为:{"Xin Dong","Dong Xin","Xin*Dong"}。 基于可能的同名作者集,能够得到文章初始集。方法如下:对于任意文章Pi,如果Pi的一位作者包含于可能的同名作者集,则Pi将会被加入初始集。基于初始集,本文提出了一种为返回的文章集合基于名字进行分类的算法,算法分为两步: 1) 使用严格的规则将文章集合分为若干子集,保证每一个子集对应的是同一个作者; 2) 根据下文提到的多种规则将子集合并,得到最终分类结果。 3.2 基于作者所在单位进行分类 首先是根据论文合作者来进行分类。令N为用户输入的作者名,假定P1和P2为用户输入N时的检索结果,如果两篇文章中N的合作者存在交集,则这两篇文章的作者就被认定为同一个人。这种方法的目的是将返回的初始文章集合分为若干子集{Si},每一个Si代表一个文章的集合,在这个集合中,同名作者极有可能代表的是现实世界中的同一个人。依据生活经验,可以知道同一单位中存在同名的人的概率是很低的,据此可以根据作者所在单位产生同名作者集。 由于DBLP中并不包含文章作者的所在单位,因此最大的挑战是如何获得作者的单位信息。本文提出了一种方法来找到并抽取DBLP中文章作者的工作单位并实现了系统iSearchPapers。对于如何获取作者工作单位信息的工作,因与本文并无太大关系,因此不作过多介绍。基于此可以得到文章P1、P2所对应的作者的单位信息并进行比较,如果二者相同则认为P1、P2对应作者为现实世界中同一个人。 分析发现:作者的工作单位可能有不同的书写格式。同一个单位可能有不同的表示方式,可能会有缩写或者省略的情况。例如"University of Washington"可以表示为:"Univ. Washington"或者“WU”,“Google”可以表示为“Google Inc.”,因此如果仅仅通过字符串匹配来确定作者的工作单位是否相同,可能出现错误。为此,本文在对作者所在单位的名称的确定过程中,通过提取单位名称字符串中的代表词来代表该单位,以此来对作者工作单位进行标识,在此过程中借鉴了TF-IDF的思想。首先,对于一个特定的作者名字。该作者所对应的所有单位名称字符串使用IKAnalyzer分词器进行分词,去除停用词,得到分词词库,进而统计每个词的出现频率。对于每一个工作单位字符串,对其选择代表词的主要思想是:对于分词结果中的每一个词在分词词库中进行查找,找出该工作单位所对应的每一个词在词库中的词频,词频较小的词语被选为代表词。将具有代表性的词挑选出来后,在对作者的工作单位进行比较时使用代表词来代替工作单位的详细信息,据此可以根据工作单位将初始文章集合分为不同的子集,如算法1所示。 算法1 分类方法 输入:所要研究的作者名称A 输出:A所对应文章的分类结果S 1.根据A得到A的可能同名作者集A′ 2.对于A′中所有名称获得同名作者文章初始集P,P中文章数目N,P中元素表示为Pj 3.获取P中所有元素Au.Af属性的代表词集合W,W元素个数T,W中元素表示为Wj 4.定义i=1,j=1 5.Forifrom 1 toT 6. Forjfrom 1 toN 7. 选出Pj.Au.Af的代表词Wj 8. If(Wi=Wj) 9. 将Pj插入集合Si中 10. end if 11. end for 12.end for 3.3 基于合作者和论文发表情况的聚簇 利用算法1所得的子集包含如下特性: 1) 同一个子集的同名作者极有可能代表现实世界中的同一个人。 2) 由于作者可能更换单位,不同子集中的同名作者有可能代表现实世界的同一人,因此需要将算法1的结果子集中的文章进行合并。 基于第2节的发现,可以对算法1进一步改进。在聚簇方法中考虑了两种属性:论文合作者和论文发表信息。用论文发表的会议或者期刊来近似表示论文作者的研究领域。算法2显示了聚簇算法的主要过程。输入为所有子集,目的是得到最终的聚簇结果,聚簇过程中,对聚簇结果中的每一个子集Ri,将其与初始集合S中的子集Si进行比较,如果二者中元素的合作者或论文发表情况存在重叠,则将Si中的对应元素插入Ri中,否则将Si作为一个独立的类插入R中。使用贪心算法来将对应现实世界中同一个人的作者的文章进行合并。 算法2 聚簇方法 输入:所有的子集的集合S,S中子集的个数m 输出:聚簇后的子集集合R 1.定义i=1,j=0表示R集合动态增长 2.对于S中的每一个子集Si,Si中任一元素为s,Ri中任一元素为r 3. While(S≠φ,j=j+1) 4. forifrom 1 tom 5. forkfrom 1 toj-1 6. If ((Si.s.Au.Co∩Rk.r.Au.Co≠φorSi.s.Jc∩Rj.r.Jc)≠φ) 7.Rk=Rk∪Si 8. end if 9. 如果Si和所有Rj到Rj-1都不能合并,则Rj=Si 10. end for 11. end for 12. end while 4.1 实验数据集 本文使用众所周知的计算机领域文献集合DBLP所收录的ACM出版的学术论文来作为实验数据集。由于本文的方法是基于作者的单位信息。然而,DBLP并没有包含作者的单位信息,所以作者开发了原型系统来从原始数据中集成同名作者的单位信息。例如,如果一篇文章发表在ACM,就从ACM的网站中抽取论文作者单位信息,并作为一篇文章的一个属性存入数据库。由于DBLP中有大量的作者,从中选取了一部分样本来进行实验。表1显示了选取的作者,包括作者姓名、文章数量、发表日期和文章所在数据源。 表1 实验中选取的同名作者 在实验中通过手工的方法获得实验的基准数据,作为实验结果的对比。过程如下:对于表1中的每一个作者,通过输入作者名来找出所有的文章。通过手工的方法对文章进行分类。从作者个人主页,多个文献集合如:Google scholar, ACM digital library, IEEE digital library等来查找作者信息,并对同名作者进行区分,获得基准数据。本文使用Recall,Precision,F-Measure来评估所提出方法的有效性。 2) 删除矩阵的第i行以及第j列,对剩余的(m-1)(n-1)重新组成矩阵,选择矩阵中的最大值并得到更多分类对应关系; 3) 继续第1)、2)步直到从矩阵中所得到的对应关系总数为min(m,n),由于m,n可能不相等,当C或C′中元素数目较小者中所有元素均参与运算,算法结束。 得到对应关系后对本文所提出的方法的有效性进行评估,本文使用Recall,Precision和F-measure来进行评估,计算方法如下: Precision=TP/(TP+FP) (2) Recall=TP/(TP+FN) (3) F-measure=2*Precision/(Precision+Recall) (4) 式中,TP代表被正确分类的文章的数目,FP表示文章数,FN表示漏报文章数。 4.2 实验结果 本文用人工的方法将样本中的名字和结果进行分类并作为基准。另外,根据基准数据对本文所提出的分类方法的分类结果进行了评估。使用Recall和Precision来对分类结果进行评估。 首先,计算对应于同名作者的分类结果的Recall和Precision。最终的Recall和Precision为样本中所有作者的论文分类的的Recall和Precision的平均值。图2显示了最终的实验结果。 从实验结果可以看出本文所提出的方法的Recall,Precision和F-Measure均为0.9以上。通过将本算法的分类结果与手工分类结果进行对比,发现样本中的某些名字的手工分类结果与通过算法进行分类的结果存在不同。表明所提出的分类方法还存在一些不足。另外由于判断同名作者是现实世界中的同一个人的标准是同名作者是否有相同的合作者。然而不能排除合作者中也有同名不同人的现象。 图2 同名作者区分的实验结果 4.3 实验结果分析 通过分析没有被正确分类的文章,发现有两类错误。 1) 文章被错误地分类了; 2) 某一类中的文章不完整。 对于第一个问题,分析发现出在第一次对子类合并的时候,根据本文提出的方法,如果两类文章有相同的文章发表期刊属性,应该将二者合并,所以当两个同名作者在同一个期刊上发表文章时两篇文章应该归为同一个类中,尽管这两个作者不是同一个人。 第二个问题是同名作者的文章被分为很多类,如果同名作者更换了单位、合作者或者发表文章的期刊或会议,那么他/她的信息更换前后所写的文章可能不会有交集。 此外,实验发现,不同的作者的同名区分结果也有一些差别,因此本文所提出的方法依然有一些不足,我们将在以后对其进行完善。 本文提出了针对文献检索的作者同名区分框架。首先根据用户的输入产生一组可能的作者名字集合;其次根据作者名字集合在系统中返回文章集合;最后对文章集合进行分类,并在分类结果的基础上使用合作者和论文出处对分类结果进行聚类,得到最终文章分类结果。上述只是初步工作,在以后的工作中,会对文中所提出的方法进行改进,进一步提高其有效性。 [1] Dongwon Lee, Jaewoo Kang, Prasenjit Mitra, et al. On. Are your citations clean?[J]. Comm. ACM,2007,50(12):33-38. [2] Xiaoming Fan, Jianyong Wang, Xu Pu, et al. On Graph-Based Name Disambiguation[J]. Journal of Data and Information Quality(JDIQ),2011,2(2):1-23. [3] Jie Tang, Alvis Cheuk M. Fong, Bo Wang, et al. A Unified Probabilistic Framework for Name Disambiguation in Digital Library[J]. IEEE Trans. Knowl. Data Eng(TKDE),2012,24(6):975-987. [4] Jiang Wu, Xiu-Hao Ding. Author name disambiguation in scientific collaboration and mobility cases[J]. Scientometrics,2013,96(3):683-697. [5] Xia Yang, Peng Jin, Wei Xiang. Exploring Word Similarity to Improve Chinese Personal Name Disambiguation[C]//Web Intelligence/IAT Workshops,2011:197-200. [6] Stasa Milojevic: Accuracy of simple, initials-based methods for author name disambiguation[J]. J. Informetrics (JOI),2013,7(4):767-773. [7] Anderson A. Ferreira, Adriano Veloso, Marcos André Gonçalves, et al. Laender: Effective self-training author name disambiguation in scholarly digital libraries[C]//JCDL’10,2010:39-48. [8] Minoru Yoshida, Masaki Ikeda, Shingo Ono, et al. Person name disambiguation by bootstrapping[C]//SIGIR’10,2010:10-17. [9] Byung-Won On, Ingyu Lee, Dongwon Lee. Scalable clustering methods for the name disambiguation problem[J]. Knowl. Inf. Syst.(KAIS),2012,31(1):129-151. [10] Pei Li, Haidong Wang, Christina Tziviskou, et al. Chronos: Facilitating History Discovery by Linking Temporal Records[J]. 2012,PVLDB 5(12):2006-2009. A Method of Same Name Author Distinguishment towards Paper Retrieval ZHANG Xinzheng1LEI Pengfei2LI Yukun2CHE Xiangdong2 (1. Tianjin Richsoft Electric Power Information Technology Co., Ltd, Tianjin 300384) (2. School of Computer and Communication Engineering, Tianjin University of Technology, Tianjin 300384) The problem that different authors share the same name brings difficulties for paper retrieval. This paper studies this problem and puts forward a framework towards same name disambiguation in paper retrieval. On the basis of this, the paper also proposes a method based on author’s unit, collaborators and paper periodical information.The experimental results shows the effectiveness of the proposed method in this paper. authors with same name, paper retrieval, distinguish 2016年8月11日, 2016年9月25日 国家自然科学基金项目(编号:61170027);天津市应用基础与前沿技术研究计划(编号:15JCYBJC46500)资助。 张新征,男,工程师,研究方向:信息化技术及管理。雷鹏飞,男,硕士,研究方向:信息集成与信息检索。李玉坤,男,博士,研究方向:数据集成、数据库与信息检索。车向东,男,硕士,研究方向:信息集成与信息检索。 TP391 10.3969/j.issn.1672-9722.2017.02.0053 基于作者名称的文献分类方法
4 实验

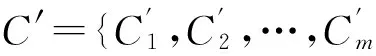

5 结语
猜你喜欢
西江月(2021年3期)2021-12-21
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
领导文萃(2021年19期)2021-11-05
文萃报·周五版(2021年10期)2021-09-13
南京大学学报(数学半年刊)(2020年1期)2020-03-19
意林(2018年20期)2018-10-31
连环画报(2016年10期)2016-12-16
都市丽人(2015年4期)2015-03-20
连环画报(2010年2期)2010-10-26
