
学术社交平台论文推荐方法
2017-03-02 08:20汤志康李春英黄泳航蔡奕彬
计算机与数字工程 2017年2期
汤志康 李春英 汤 庸 黄泳航 蔡奕彬
(1.广东技术师范学院计算机科学学院 广州 510665)(2.广东技术师范学院计算机网络中心 广州 510665) (3.华南师范大学计算机科学学院 广州 510631)
学术社交平台论文推荐方法
汤志康1李春英2,3汤 庸3黄泳航3蔡奕彬3
(1.广东技术师范学院计算机科学学院 广州 510665)(2.广东技术师范学院计算机网络中心 广州 510665) (3.华南师范大学计算机科学学院 广州 510631)
基于搜索学术论文对研究者造成的困扰问题,在学术论文聚合平台基础上提出一种学术社交平台相似论文推荐方法,给出了推荐方法的总体架构及各部分的详细设计方案。该方法首先使用ANSJ对论文数据集中的论文进行分词并统计词条的TF-IDF,使用这些词条表示该论文的关键信息。其次使用Word2Vec把每一篇论文映射到一个高维向量,使用余弦相似度公式计算其与用户查询论文间的相似度,根据相似度结果高低生成论文推荐列表。最后在SCHOLAT论文数据集上通过应用实例以及量化指标分析验证了该推荐方法的有效性。
学术社交平台; 论文检索; 相似论文; 推荐方法
Class Number TP311
1 引言
学术社交网络平台主要面向科研工作者,旨在为全球科研工作者提供学术信息服务。平台提供便利的条件让科研工作者发布个人学术信息,搜索、分享和推荐相关学术研究成果并追踪感兴趣领域的最新研究动态。学术社交网络平台也能使科研工作者可以跨地域、跨单位、跨学科进行学术交流、思想碰撞,从而有效促进科学研究工作的协同高效开展。
随着学术社交网络的快速发展,科研人员之间的交流变得更加容易,获取信息也变得更加方便。学术社交网络平台为我们提供极大便利的同时,信息过载已经成为科研工作者所面临的主要困境之一。如何在学术社交网络平台的海量信息中快速精准定位所感兴趣的内容,是需要研究的重要课题。推荐系统[1]是目前解决信息过载的有效方法。本文以学术论文的搜索与推荐作为切入点,主要研究基于用户搜索信息的相似论文推荐问题。
当前提供学术论文检索的平台很多且都比较成熟。国内比较著名的有中国知网、万方数据库和百度学术等。国外则细分到各个学科领域,以计算机学科为例,有Springer、ACM、ScienceDirect、Microsoft Academic Search等。如果一名科技工作者想要搜索一篇学术论文,需要选择某一种搜索引擎进行搜索,倘若搜索的结果不理想,则需要继续选择其他的搜索引擎进行查找。这样,研究者为找到自己需要的学术论文,通常需要频繁切换搜索平台,耗费了大量的时间资源,也给科研工作者带来诸多不便。另外,学术论文的检索本身是繁琐和耗时的,检索某一主题时还可能遗漏一些重要的学术成果,尤其一些较新的具有重要参考价值的成果。因此,本文提出一种基于学术社交平台的学术论文推荐方法,该推荐方法以学术社交网络平台中聚合了其它多个平台论文的搜索引擎为基础,科技工作者通过这个搜索引擎提供的统一入口,可以方便快捷地检索出来自多个学术论文搜索引擎平台的数据,基于已有的研究成果和数据集,针对用户选择的搜索结果给出与选择结果相似的论文推荐列表。
2 相关工作
随着科技论文数量的快速增长,如何快速有效地在海量的论文数据集中进行精准定位找到自己想要的学术论文。对于一个给定的查询主题,系统自动推荐相似论文研究具有良好的现实应用价值。基于这一原因,学者们做出了很多努力,也产生了丰富的研究成果。张玉连等[2]提出通过建立隐语义模型,然后利用用户和论文的特征向量进行论文推荐的算法,其将所推荐论文的引用和引用该论文的情况加入到论文的特征向量中,通过用户和论文特征向量之间内积的大小确定推荐的论文。通过与基于用户的协同过滤算法以及基于论文的协同过滤算法进行比较,该论文推荐算法取得了较好的准确率和召回率。贺超波等[3]提出了基于学术社区的学术论文推荐方法。该方法首先抽取用户基本信息、论文信息、用户关系网络以及用户对论文的评价信息,然后通过社区发现模块对用户群体进行社区划分,计算目标用户在社区内最相近的K个用户,然后结合基于网络社区的协同推荐算法以及用户论文评价数据进行综合计算后给出论文推荐列表。该方法通过社区的互动和分享来提高推荐的质量和效率。李建国等[4]提出了基于领域认知度的学术信息服务平台论文推荐方法。该方法首先对论文所属的领域进行分类,然后计算作者对研究领域的认知度,领域相近的作者为目标论文预测评分,根据评分实现论文推荐。文献[2~4]在推荐中使用了用户显性信息或者隐性信息,这种方法对于新注册且信息极少的数据稀疏用户存在推荐冷启动问题。文献[5]提出使用读者在数字图书馆的共访问记录比以及共引记录进行论文推荐具有更好的覆盖率,使用共访问记录可使没有获得足够引用的研究论文获得推荐。但是这种方法对于首次使用数字图书馆的科技工作者难于获得推荐。文献[6]基于奇异值分解理论通过已出版论文的参考文献列表预测目标研究者的研究兴趣,并根据预测的研究兴趣推荐新出版的科技论文给目标用户。通过在DBLP真实数据集上的实验表明该方法比基于引用网络的方法具有更好的推荐效果。但这种方法存在科技工作“新人”难于获得论文推荐的问题。
3 该推荐方法详细设计
本文以大型学术社交网络平台学者网(www.scholat.com)为依托,以其中文论文数据库作为研究语料,提出学术社交网络平台相似论文推荐方法,如图1所示。该模型预处理阶段对研究语料中的论文进行分词,分词结果分别存入文本文件wordList.txt和数据库HBase中。对存储在HBase中的论文,根据分词结果统计词条的TF-IDF,并将这些词条作为论文的关键词。论文分词结果文本文件在Word2Vec程序的训练下得到相应的向量表示并使用余弦相似度计算其与用户输入论文的相似程度,根据相似度从高到低排序生成论文推荐列表。

图1 推荐方法整体架构图
3.1 数据库设计
HBase[7]是Apache Hadoop的子项目,是构建在HDFS上的典型的key/value分布式列存储系统,尤其适合于海量非结构化数据存储。对于迅速增长的海量论文数据而言,HBase可以依靠横向扩展,通过在廉价PC Server上搭建大规模结构化存储集群可以提高系统的计算、存储能力。因此,本推荐系统采用Apache HBase作为数据库管理系统存储和计算海量论文数据并对用户提供论文推荐服务。另外,Apache HBase表的属性可以根据需求动态增加。表是由行和列构成的,一个列名由column family前缀和qualifier构成,所有的列都从属于某个column family[8]。在本推荐方法中共涉及四个Bigtable:词条文档数表,论文关键词表,关键词论文集合表和论文推荐结果表。
词条文档数表如表1所示,用于统计语料中出现某词条的文档数,其中term代表一个词,qualifier的列数代表出现该词条的文档数量。

表1 词条文档数表
使用3.2节Ansj分词工具动态产生词条,并利用式(1)计算词条在文档中的词频。通过遍历表1中的词条,获取拥有该词条的文档数,使用3.3节的式(2)计算词条的逆文档频率值,据此计算每个词条对应的TF和IDF之积。TF-IDF值越高的词条与论文的相关性越高,因而选择TF-IDF值较高的前15个词条作为论文的关键字,存储于表2中。为了计算相似度并进行论文推荐,设计表3用于存储以某个词条作为关键词的论文的集合。表3中qualifier的值是出现该关键词的论文id,列数则代表以该词条作为关键词的论文的篇数。
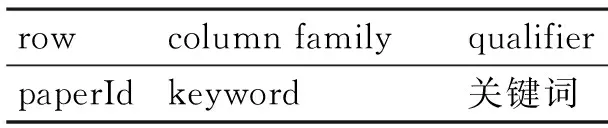
表2 论文关键词表

表3 关键词论文集合表
利用表2和表3中存储的数据信息,结合Word2Vec训练结果,计算输入论文与数据库中论文的相似度,并产生论文推荐结果,并存储于表4中。
3.1 护理质量管理的信息化 信息技术的使用是当前护理质量管理走向科学化的必由之路。通过充分整合搜索引擎技术、数据库技术、分布存储技术等,设计医院护理质量信息化管理软件,包括数据录入、统计分析、实时反馈、重大案例分析、专家在线咨询、工作提醒、危重症护理实时监测、标准查询等护理质量管理资源共享模块,实现全市护理质量评价数据实时监测、动态评价、专家反馈以及护理质量改进的科学决策,研制开发护理风险危机管理系统,建立全市范围的护理安全管理共享平台,从而真正实现护理质量管理的自动化与智能化。

表4 论文推荐结果表
3.2 中文分词
分词是对语料进行统计和训练的前提条件。Ansj是基于Google语义模型和条件随机模型的中文分词开源工具,支持用户自定义词典。Ansj运行时首先读取停用词列表文件,去除语料中可能出现频率很高但无意义的词条。然后Ansj根据用户自定义词典对语料信息进行分词,并以词条作为键,paperId作为表1的qualifier。
3.3 计算词条的TF-IDF值
Salton的词频-逆文档词频TF-IDF是一种用于信息检索和文本挖掘的常用加权技术,用来评估词组在文档中的重要程度。词频是统计一个词在文档中出现的频率,词频越高,通常意味着该词在文档中的地位越重要;逆文档词频是一个词语重要性的衡量,如果包含该词条的文档数越少,说明该词条具有很好的类别区分能力,其值越大。词频和逆文档词频的乘积为TF-IDF,其作用通俗来讲就是:如果一个词条在一个文档中频繁出现,即其TF值很高;而同时在其他文档中又很少出现,那么说明该词条的区分度很高。词条ti在文档dj中的词频TF计算如式(1)所示。其中,ni,j表示ti在文档dj中出现的次数,∑knk,j表示所有词出现的次数之和。
(1)
词条ti在当前语料库中的逆文档频率IDF的计算如式(2)所示。其中,|D|是语料库中的文档总数,|{j:ti∈dj}|是出现词条ti的文档数。
(2)
根据语料数据集,通过遍历词条文档数表,对于每一行,统计其qualifier的列数,即可得到包含该词条的论文数,而论文总数在实验中是常量。依据式(2)计算词条的逆文档词频IDF,保存到词条逆文档频率表中。
3.4 相似度推荐
Word2Vec[9]是Google在2013年开源的一款将词表征为实数向量的高效工具,尤其适合对互联网大数据进行处理,其在一个优化的单机版本一天可训练上千亿个词条[10~11]。本文采用Word2Vec的Distributed Representation向量表示法[12]。该向量表示法的维数可自定义为超参数K,通过训练把对文本内容的处理简化为K维实数向量。并且使用余弦相似度计算向量之间的距离来判断文本之间的语义相似度。与潜在语义分析(Latent Semantic Index)[13]、潜在狄立克雷分配(Latent Dirichlet Allocation)[14]等经典的相似度计算模型相比,Word2vec结合深度学习的思想,利用了词语的上下文关系,语义信息、语义关联等表达得更加丰富。
4 实验
开发环境:Apache HBase 1.0、Google Word2Vec、Apache Solr、Ansj2.0.6、Intel(R)Core(TM) i3-3240 CPU @ 3.40GHz,4G内存,300G硬盘。基于提出的论文推荐模型,算法如下所示。
算法1 论文推荐算法
已知:学术社交网络论文集;当前用户的行为记录(输入关键词等)
求:论文推荐列表recommList
1.收集研究语料(包含标题、关键词、摘要)、用户行为;
2.信息预处理,去噪、对信息进行分词、统计词条TF-IDF;
3.利用Word2Vec训练,计算用户行为的余弦相似度;
4.对相似度进行逆序排列,取出TOPn篇论文形成推荐列表(最多推荐5篇);
5.return recommList,量化评价。
4.1 实例应用
考虑到直接采用论文现有的关键词信息不能很好地体现论文的实质内容,实验挑选学者网数据集SCHOLAT中文部分且论文的元数据信息包含标题、关键词、摘要等三种信息的数据作为研究语料。利用3.2节Ansj分词模型对研究语料进行分词并使用式(1)和式(2)计算词条的TF-IDF值,提取前15个词条作为论文的关键词,并将结果保存到表2中。将以空格作为分隔符的分词结果文件wordList.txt导入Word2Vec进行训练,训练完成后输出文件vectors.bin,该文件以二进制形式保存了词条的向量表示。使用Word2Vec提供的distance程序计算词条向量表示之间的余弦相似度,distance应用通过读取模型文件中每一个词条和其对应的向量,对应输入查询的词组,计算该词与其他被采样的词条的余弦相似度,按照分数从高到低排序后返回结果。然后根据关键词,查询表3中对应的论文,并将产生的推荐论文列表id信息保存到表4中。
现假设社交网络平台用户输入论文名称为“计算机辅助教学的优势与应注意的问题”为例,根据Word2Vec的训练结果,与“计算机”相近的词语有“多媒体”、“微机”等,如图2所示。在表3中检索对应的论文后产生推荐结果,如图3所示。

图2 词条“计算机”的训练结果图

图3 论文推荐结果图
4.2 量化分析
为了对本文提出的论文推荐算法进行量化评价,利用学者网提供的数据接口,采集了计算机相关类别的中文期刊92848篇论文作为测试集。文中用来评价论文推荐效果的指标是准确率、召回率、F1-Measure。如式(3)~(5)所示
(3)
(4)
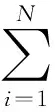
图4是本文提出的论文推荐算法在不同的推荐数量的情况下的效果比较,由图中可以看出,随着推荐数量的增加,尤其是达到200以上的时候,论文推荐算法趋于稳定,总体上具有较好的应用价值。

图4 推荐效果对比图
5 结语
提出一种学术社交网络平台相似论文推荐方法,给出了系统的总体架构及各部分的详细设计方案。在SCHOLAT(学者网)论文数据集上验证了模型的有效性。但由于当前推荐系统计算量较大,特别是计算词频-逆文档词频和词条之间的相似度。同时Word2Vec使用的语料数据集越大,效果越理想,但超大的数据集使单机系统的性能受到考验。因此当前仅抽取SCHOLAT数据集上少部分数据进行实验验证。下一步考虑采用Apache Hadoop平台实现学者网SCHOLAT完整论文数据集的分布式动态计算,提高系统的响应时间和训练效果,并将该论文推荐系统模型投入到学者网平台上推广使用。
[2] 张玉连,袁伟.隐语义模型下的科技论文推荐[J].计算机应用与软件,2015,32(2):37-40. ZHANG Yulian, YUAN Wei. Scientific Papers Recommendation Using Implicit Semantics Model[J]. Computer Applications and Software,2015,32(2):37-40.
[3] 贺超波,沈玉利,余建辉,等.基于学术社区的科技论文推荐方法[J].华南师范大学学报(自然科学版),2012,44(3):55-58. HE Chaobo, SHEN Yuli, YU Jianhui, et al. Method for Scientific Paper Recommendation Based on Academic Community[J]. Journal of South China Normal University(Natural Science Edition),2012,44(3):55-58.
[4] 李建国,毛承洁,刘晓,等.学术信息服务平台的研究与设计[J].华南师范大学学报(自然科学版),2012,44(3):51-54. LI Jianguo, MAO Chengjie, LIU Xiao, et al. Research and Design of Academic Information Service Platform[J]. Journal of South China Normal University(Natural Science Edition),2012,44(3):51-54.
[5] Pohl Stefan, RadlinskiFilip, Joachims Thorsten. Recommending Related Papers Based on Digital Library Access Records[C]//Proceedings of the 7thACM/IEEE-CS Joint Conference on Digital Libraries,New York: ACM,2007:417-418.
[6] Ha Jiwoon, Kwon Soon-Hyoung, Kim Sang-Wook. On Recommending Newly Published Academic Papers[C]//Proceeding HT’15 Proceedings of the 26th ACM Conference on Hypertext & Social Media,New York: ACM,2015:329-330.
[7] Apache HBase Team. Apache HBaseTMReference Guide[EB/OL]. http://hbase.apache.org/book.html,2013-01-17.
[8] Dimiduk Nicholas, Khurana Amandeep. HBase in Action[EB/OL]. https://www.manning.com/books/hbase-in-action.
[9] 周练.Word2vec的工作原理及应用探究[J].科技情报开发与经济,2015(2):145-148. ZHOU Lian. Exploration of the Working Principle and Application of Word2vec[J]. Sci-Tech Information Development & Economy,2015(2):145-148.
[10] 郑文超,徐鹏.利用word2vec对中文词进行聚类的研究[J].软件,2013(12):160-162. ZHENG Wenchao, XU Peng. Research on Chinese Word Clustering with Word2vec[J]. Software,2013(12):160-162.
[11] Mikolov Tomas, Chen Kai, CorradoGreg, et al. Efficient Estimation of Word Representations in Vector Space[J]. eprintarXiv:1301.3781,2013,1:1-12.
[12] 邓澎军,陆光明,夏龙.Deep Learning实战之word2vec[EB/OL].网易有道,2014-02-27. DENG Pengjun, LU Guangming, XIA Long. Deep Learning Practice in Word2vec[EB/OL]. Net Ease You Dao, 2014-02-27.http://techblog.youdao.com/?p=915.
[13] Scott Deerwester, Dumais Susan T, Furnas George W, et al. Indexing by latent semantic analysis[J]. Journal of The American Society for Information Science,1990,41(6):391-407.
[14] Blei David M, Ng Andrew Y, Jordan Michael I. Latent Dirichlet Allocation[J]. Journal of Machine Learning Research,2003,3:993-1022.
Paper Recommendation Method Based on Scholar Social Platform
TANG Zhikang1LI Chunying2,3TANG Yong3HUANG Yonghang3CAI Yibin3
(1. School of Computer Science, GuangDong Polytechnic Normal University, Guangzhou 510665) (2. Computer Network Center, GuangDong Polytechnic Normal University, Guangzhou 510665) (3. School of Computer Science, South China Normal University, Guangzhou 510631)
According to the defects that researchers search academic papers. This paper proposed a similar paper recommendation method in scholar social platform that includes several popular search engine, and explainedthe framework of recommendation method and detailed design of the system. This recommendation method executes word-segmentation with ANSJ, calculate the TF-IDF of lemma and extract paper key words in initialization. Next, read the segmentation result to get the word-vectors by Word2Vec, calculate its similarity with querypaperfrom users according to cosine similarity formula. And further, the paper recommendation list will be generated. In the end, the efficacy will be proof by an application instance and quantitative index analysison SCHOLAT paper dataset.
academic social network, paper seeking, similar paper, recommendation method
2016年8月10日,
2016年9月22日
国家自然科学基金(编号:61272067,61370229);广东省自然基金团队研究项目(编号:S2012030006242);广东省自然科学基金-博士科研启动项目(编号:2014A030310238);广东省科技计划项目(编号:2015B010109003)资助。
汤志康,男,讲师,研究方向:社交网络与大数据应用。李春英,女,博士研究生,副教授,研究方向:社交网络与大数据应用、服务计算。汤庸,男,教授,博士生导师,研究方向:信息搜索与数据挖掘、协同计算。黄泳航,男,博士研究生,研究方向:社交网络。蔡奕彬,男,硕士研究生,研究方向:服务计算。
TP311
10.3969/j.issn.1672-9722.2017.02.006
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
电脑知识与技术·经验技巧(2020年3期)2020-05-07
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
亚太教育(2018年5期)2018-12-01
长江丛刊(2017年27期)2017-12-01
读者·校园版(2015年7期)2015-05-14
心理学报(2014年4期)2014-02-02
中学生英语·外语教学与研究(2008年4期)2008-03-18
