
面向开源软件的演化确认方法*
2017-04-17 01:38韩俊明
计算机与生活 2017年4期
韩俊明,王 炜,2+,李 彤,2,何 云
1.云南大学 软件学院,昆明 650091
2.云南省软件工程重点实验室,昆明 650091
面向开源软件的演化确认方法*
韩俊明1,王 炜1,2+,李 彤1,2,何 云1
1.云南大学 软件学院,昆明 650091
2.云南省软件工程重点实验室,昆明 650091
软件演化;确认;主题模型;开源软件
1 引言
软件系统的构造性和演化性是软件系统的两个基本属性,特别是开源软件由于其自身的特点导致了如何确认其演化活动成为当前产业界和学术界研究的热点。
如今,软件的应用越来越广泛,已经深入到各个行业内部,成为大部分工作中不可替代的一部分,特别是开源软件,它的产生和发展是一种社会现象,也是一种经济现象[1]。开源软件广义上的理解,就是让软件的使用者能够得到其源代码,还可以按照自己的需要修改源代码,并发布给别人使用。
但是,开源软件相较传统软件,在开发过程上都有着极大的不同[2]。
从开发的角度与传统方法相比较,首先在项目计划上,开源软件就没有严格的时间、人员和资金等管理信息;其次在需求分析方面,传统软件开发中,需求一直都是核心问题,而对于开源软件的开发,项目大多时候是因为某些人把自己的想法公布于众,却没有明确的文档信息;然后在设计和实现方面,分散开发是开源软件的一个明显特点,因此不会产生详细或统一的开发文档;最后在测试与维护上,开源软件由于开发和使用人数众多,虽然测试缺乏严密性,但错误的修复人员也是极其庞大的,许多错误在很短时间内就能得到修复。
从开发过程的角度来说,传统的软件开发方法认为,好的软件开发过程就能开发出高质量的软件,但对于开源软件来说,这个假设是不成立的,因为开源软件的开发过程很难做到统一管理,原因在于:(1)对于开源软件,开发人、使用人和维护人三者往往不会存在于一个组织内,因此缺少相应的文档进行软件演化记录,对于使用人而言,就很难去确认一个演化是否与演化意图相符合。(2)开源软件采用群智开发模式,无法或很难实现开发过程的建模,导致难以使用基于过程的软件确认,而当前研究大多关注于对演化过程的验证,并未对演化产品是否与演化需求一致进行验证。(3)目前大型的开源软件,对其进行修改的人很多,因此会出现缺少或没有相关的文档,导致无法对演化进行确认。
当前开源软件还被认为是一种获取可信软件的新途径[3],同时开源软件价格低廉和性能可靠两个特点,而被认为是专有软件的可替代品,其发展和应用都得到了一定程度上的提高,许多组织都投身于这些软件的开发中,但是因为这些软件的开发和演化大多都是由不同的组织和个人完成,所以对软件的可靠性或演化的真实性无法进行确认。特别是近年来,开源活动得到了学术界和工业界的广泛关注,开源就意味着可以获取到软件的源代码,利用这些源代码可以迅速完成产品开发。同时开源软件的贡献者一般互相不认识,他们在开源社区内进行高效的合作来完成代码的相关工作,因此开源软件的演化活动就变得广泛且不可避免。
综上所述,由于开源软件具有与传统开发模式迥异的特征,导致了传统软件确认方法无法实现对开源软件的自然延伸。因此急需一种面向开源软件的演化确认方法。同时,相关文献[4]指出,过去对软件演化的研究大多把重点放在了软件开发或演化过程上,而对于演化后的确认工作却很少有人开展。
本文利用主题模型进行了研究,提出了一种可以对开源软件进行确认的方法,把源代码按不同粒度进行聚类分析,每一个聚类结果就代表了源代码的一个主题,而每一个主题表示软件系统中的一个功能模块,从而把确认工作转换为建立功能模块与演化需求之间的映射关系。
本文方法具有如下特点:
(1)针对目前研究较少的开源软件的演化确认,将主题模型应用于软件源代码的处理,并提出了一套确认方法。
(2)已演化的和没有演化的开源软件在实验结果中能进行很好的区分,并与其他可以进行确认的方法进行对比,结果表明本文方法更好。
(3)对文中所用方法,已给出相应的确认工具。
本文组织结构如下:第2章介绍软件确认技术的发展和所用到的相关方法;第3章描述本文所用的方法;第4章介绍面向开源软件的演化确认方法;第5章介绍实验所用到的工具;第6章具体描述实验结果,对结果进行分析,并给出实验结论;第7章对实验进行评价,并阐述未来的研究方向。
2 研究综述
1978年,首次提出了软件确认技术[5],当时软件应用具有不普及,软件规模小和演化慢等特点,因此当时研究人员认为对于一个软件系统,其验证的关键在于需要减少复杂性和大量细节,基于该认识,提出了确认软件演化需要对抽象数据类型进行验证。若干年后,研究人员在开发重要的系统时,意识到保证软件质量可靠的主要手段还是确认,同时针对特定的软件确认提出了一种从软件开发方法到测试的技术[6]。1992年,软件行业发生了巨大的变化,计算机和因特网的普及推动了软件的大量产生,人们开始对软件的开发过程研究感兴趣,并提出了基于Petri网的软件确认技术[7],并对该方法的前景和验证过程进行详细描述,作者认为Petri网能在一定程度上对软件过程进行验证,但对演化结果却无法确认。在随后的十几年间,科研人员把主要的研究工作放在了使用形式化方法对过程进行确认。文献[8]对形式化验证方法进行了总结,将该方法分为两类:(1)静态分析方法,该方法能自动计算其行为信息而不用去执行程序;(2)软件模型检测法,该方法实际上是一个算法,用于确认一个系统的模型是否满足正确性规范。随后的几年里,软件高度普及化,因此人们把确认的主要研究工作放在了模型相关方法上。文献[9-10]分别采用了有界模型和无界模型的方法对软件进行确认;文献[11]则对模型检测法进行了详尽的描述,并介绍了相关的工具;而文献[12]指出软件确认是一项非常耗时的工作,现存的或者新的代码必须要加上注释以说明其用意,但是目前开源软件的大量使用,来自不同组织的人员对代码的修改变得特别频繁,因此就很难有详细的注释和相关的文档来对其演化进行确认。随着软件规模日趋庞大,组织形态日益复杂,传统的演化确认把软件开发过程认为是“白盒”的方法,已经不能对开源软件的演化进行确认。例如,软件系统抽象为Petri网将具有规模庞大的状态空间,在此基础上进行状态空间遍历将很困难。当前,对软件演化的研究主要集中在过程上,研究方法也主要是在理论上的推导和证明。文献[13]通过引用进程代数(algebra of communicating processes,ACP),基于等式推理验证软件演化过程模型的行为,对软件演化过程原模型进行了扩展,但未使用实际的软件或程序进行分析或证明。
针对上述研究,可以发现其中的3个问题:(1)没有对软件演化实质与演化需求是否相符进行确认;(2)对于演化确认的研究,大多没有采取实验的方法,并给出实验数据;(3)对于文档缺失的开源软件,目前的研究都没有明确给出确认的方法。
由于开源软件的出现和大量使用,同时由于群智开发而缺少相关的文档,以及演化过程不可建模而无法使用过程确认的方法,导致了前期的研究成果不适用于开源软件的确认。因此需要采用语义功能的方法,从演化需求和代码之间的关联性建模是解决开源软件演化确认的一条可行之路。
主题模型是一种可以从大量的文档中提取出文档中包含主题的方法,因此它可以从语义功能层面分析出软件源代码中包含了哪些主题,进而通过主题得到哪些代码实现了软件的某个功能。
当前,主题模型大多作为工具用于自然语言和信息检索领域的研究。文献[14]将主题模型应用于分析人们看到在线新闻时的情感,并把这些分析结果反馈给新闻发布人员;也有研究人员在文本信息的识别和处理研究中,提出把主题模型用于文本的主题挖掘,并将原有的主题模型进行改造,提出双稀疏主题模型[15],进而提出了双层主题模型用来从引文网络中发现知识[16]。
目前也有一些研究把主题模型与软件相关领域结合:文献[17]提出了一种基于构件验证的API构件测试模型和相关的测试覆盖标准,并通过相关实验进行了验证,可是并没有对演化实质和需求是否相符进行确认。文献[18]把主题模型应用于物联网的服务发现,提出了相应的算法,最终找到与服务请求最相似的服务集合,但使用的数据集仍是自然语言,并没有将其与软件领域相结合,而把主题模型与软件领域相结合进行研究的,国内包括国外都很少有人开展。文献[19]把软件源代码用主题模型进行处理,然后分析出代码的功能,将分析结果用于帮助开发人员对软件进行理解,并没有把主题模型与软件演化相结合。
主题模型的应用,除了用于自然语言和信息方面的研究,还有人员将其与图像识别处理技术相结合,并取得了一定的成果。文献[20]认为目前计算机视觉领域最大的挑战是从复杂的环境中识别出人的动作,作者通过使用主题模型的方法更好地解决了动作识别的问题。最近,人们还把主题模型应用于实时交通故障侦察[21]、视频质量评价[22]、图像质量和特点评估[23]等方面的研究。
由上述研究方向的多样化和成果可以看出,主题模型是一种成熟的可以处理文本信息的工具,并且自身也被扩展为其他领域的研究工具,因此可以使用它来对软件演化进行确认。
3 预备知识
主题模型(topic model)是用来在一系列文档中发现抽象主题的一种概率统计模型,其主要应用在自然语言处理和机器学习领域。该模型是从大量的文档信息中,提取出内在的主题。从更基础更直观的角度理解,就是人们在撰写一篇文章时,都会围绕一个主题思想开展写作,就会有一些与该主题相关的词汇出现,甚至频繁出现,主题模型就是试图使用数学中的概率模型来说明该现象,软件开发人员在编写代码时,也会如此。例如当需要不断获取参数并赋值时,就会反复使用get和set两个词汇。主题模型会自动分析文档,统计文档内的词汇,根据统计结果进行分析,并给出文档、主题和词汇三者之间存在的概率关系。人们使用主题模型对文档的生成过程进行模拟,再通过参数估计得到各个主题[24]。将主题模型应用于文本信息进行建模分析,有互操作性强,降低维度和可自动分类等优点[25]。
隐含狄利克雷分布(latent Dirichlet allocation,LDA)[26]是一种非监督机器学习的方法,其最早是在2003年由Blei等人[24]提出,研究目的是将其应用于自然语言处理和信息检索领域。主题模型本身就是一种生成模型,它通过一定的样本训练后,描述了一种以一定概率生成某一文本信息的过程[27]。同时,LDA也被证实了是LSI(latentsemanticindexing)的一种替代方法,并且在效率和定位上都优于LSI[28]。
在主题模型LDA中,有一个假设称为词袋假设[29],其把文档信息视为词频向量,并且不去考虑词与词间的顺序,这样一来就把本不能建模的文字信息转变成了可以建模的数字信息。在整个模型中,包含了文档、主题和词汇三层结构,并通过对训练集的训练,以概率模型的形式给出了文档和主题、主题和词汇间的关系。在LDA[30]的模式下,文档是若干个主题按照一定的概率生成的,而主题是若干词汇按照一定的概率生成的,因此对一个文档集D中的文档d,LDA假设了下面的生成过程[31-32]:

在使用LDA对文本信息进行处理时,需要输入一些相关的参数,主要包括以下参数[28]:
D,文档;
K,主题数;
α,主题比例的Dirichlet超参数;
β,多项式比例的Dirichlet超参数。
而LDA的输出,包括以下两项:
φ,词-主题的概率分布;
θ,主题-文档的概率分布。
在模型中,超参数α和 β起着平滑作用。详细地说,α影响着每一个代码文件的主题分布,β则影响着每一个主题的词分布。降低超参数的值会使得α和θ矩阵变得更加稀疏。尤其是在α取较小值时意味着代码文件中更少的主题。同样对于β,其值越小,通常就会增加描述特定文档所需的主题数量。LDA模型的粒度归因于 β的值[33],因为当每一个代码文件需要更多的主题来描述时,语料库中的每一个文档就会被分解得更细。
文献[33]对于K值的初始化,只给了一些经验性的参考,并没有给出一种选择的方法。文献[34]介绍了超参数值设置复杂的估计方法,但这些方法对不同的文档内容的影响尚不清楚。因此超参数的估计通常都是根据经验性的方法来赋值,通常α=50/K,β=0.1。
对于参数φ和θ,LDA在进行主题分析时,只能做近似的推理,很难进行精确推理。例如在LDA中包含了吉布斯采样[35],这是用马尔科夫链蒙特卡洛模拟的一个特殊情况,根据词在各个文档中的情况得出准确的分布估计是一个消耗很大的问题。
对于参数估计方法,目前主要有变分贝叶斯推断(variational Bayesian inference,VB)、期望传播(expectation propagation,EP)和Collapsed Gibbs Sampling。基于Gibbs抽样的参数推理方法容易理解且实现简单,能够非常有效地从大规模文本集中抽取主题,因此Gibbs抽样算法成为当前最流行的LDA模型抽取算法。
本文参数估计利用MCMC方法中的Gibbs抽样算法,可以将该算法看作文本生成的反向过程,即在已知生成结果的情况下,利用参数估计得到参数值[36]:
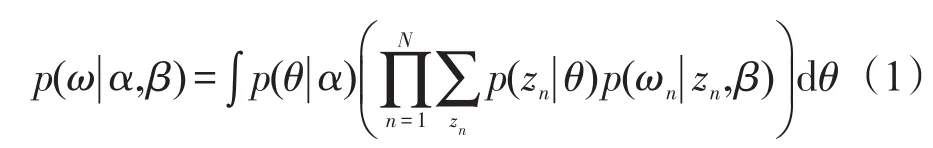
“Collapsed”是指采用了积分的方法避开了实际需要去估计的参数,而对每个包含单词的主题进行采样,如果每个单词的主题不变,参数就可以在统计频次后计算出来。因此,参数估计问题变为计算单词序列下主题序列的条件概率:

式中,zi表示第i个词所对应的主题;乛i表示不包括第i项;表示主题k中出现词t的次数;βi是词t的狄利克雷先验;表示文本m出现主题k的次数;ak是主题k的狄利克雷先验。
如果能够获取到单词主题标号,需要的参数计算公式可由下面公式计算出[24]:

式中,φk,t表示主题k中词t的概率;θm,k表示文本m中主题k的概率。
4 演化软件的确认方法
开源软件普及速度快,利用率高,演化频繁,同时也由于开源软件是群智开发而缺少相关文档,演化过程在不可控的环境下进行而导致过程不可建模,致使传统软件确认方法无法实现对开源软件的自然延伸。因此本文从故能语义的角度,以源代码主题模型作为工具进行了研究,提出了一种可以对开源软件演化活动进行确认的方法。本文的演化软件确认方法为:获取软件源代码中的特征,并把这些特征按不同粒度进行聚类分析,聚类分析的每一个结果就表示源代码中的一个主题,每个主题表示软件系统中的功能模块,把这些主题与演化需求进行相关性计算,找出与演化需求最相似的主题,从而把确认工作转换为建立功能模块与演化需求之间的映射关系,进而确认演化是否与演化需求相符合。
本文方法总体上分为3个过程,如图1所示。

Fig.1 Verification method of evolved software图1 软件演化确认方法
4.1 源数据获取及处理
本文方法的第一步就是获取实验数据,即软件的源代码。但是对于一个成品软件,其源代码文件中除了代码外,还包含了大量的其他文件[28],例如xml文件、图片等,就连代码文件本身都有许多符号和代码关键字等[37]。这些信息大多都是一些固定的词组语句,或标记类的语言,而图片也很难用现有方法进行处理。如果把源代码文件直接使用主题模型进行分析,不但分析速度会受到影响,连分析结果的准确度也会受到很大的影响,因此只对代码本身进行主题建模。因为代码在编写时,需要写入大量与所完成功能无关的符号和关键字,所以就需要对代码进行特征提取。依据文献[38]中的内容“……源代码中的变量名、函数名、类(对象)名、API函数、注释等关键词中蕴含了丰富的主题知识,可以通过其识别源代码与特征之间的映射关系”,就需要从代码文件中提取方法名、变量名和注释作为能够反映代码所完成功能的特征。
根据上面的描述,本文对实验源数据的处理,可分为以下步骤:
(1)从分布式版本控制系统中下载同一个软件的两个不同版本,并获取对应的源代码。
(2)预处理(主要是指对方法名、变量名和注释的处理)。把提取后特征按类(针对面向对象语言)形成单独的文件,并以类所在的包名加上自己的类名对该文件进行命名。观察调整后的特征,发现由于源代码的格式较为特殊且复杂,故需要做相应的预处理达到去噪的效果。预处理主要包含:去除停词(如“the”和“and”等),词根还原(如把“gone”还原为“go”等)和去除运算符等非特征信息。通过这几个操作,可以减少无用特征的数量,提高有用特征的比例。
(3)版本内容协同化处理。在软件演化过程中,常常会涉及到功能的增加、删除和整合,或者说代码的变化。例如一个文件在更新时被删除了,就会使得在确认时,找不到这个文件,从而无法确认;亦或是软件在更新时,对某个文件进行了大量的增加和删除,当需要对这个文件进行确认时,确认的精确度就会受到影响。因此需要对两个版本的特征文件集进行处理。根据文献[39]所描述的方法,需要把在低版本中存在,但是高版本中不存在的添加到高版本中,具体的操作是“若低版本中有而高版本中没有的文件,则直接把该文件拷贝到高版本中;若某个文件在低版本和高版本中均存在,则以行为基础,找出低版本中有而高版本中没有的行,加入到高版本的该文件中”。
表1为提取源代码中的特征并处理后的文件内容示例。

Table 1 Sample of features表1 特征示例
通过使用LDA主题模型对提取后的特征进行建模分析后,就可以得到主题和词之间的概率模型。表2为一生成概率模型示例。
如表2所示,Topic 0包含了3个单词,分别是tokenset、classifier和java,它们属于该主题Topic 0的概率分别为0.022 089 578 250 261 414、0.018 458 812 594 399和0.015 263 738 817 241 778。同样的情况,Topic 1也是如此。

Table 2 Sample of probabilistic model表2 概率模型示例
4.2 相关性计算
演化活动的确认,或者说是特征匹配,本质上是识别演化活动中被修改的代码在功能语义上是否与演化需求存在相关性,建立特征描述向量与代码主题之间的映射关系,该过程必须依赖某种相似性的测度方法。主题中各代码向量在几何空间上的分布往往是不均匀的,因此不能简单地将相似性理解为计算特征描述向量与主题中各代码向量的中心点间的欧式距离。另外,由于特征描述向量和代码向量维数大多超过三维,程序员无法直观想象代码向量与特征描述向量的分布情况。
因此相关性的计算是演化确认的关键,而实际上要做的就是识别出演化活动的影响,或者说就是定位出软件演化前后工作人员都修改了哪些代码文件,而如何找到这些被修改了的文件,就需要借用到一些相似度计算方法。
在对已经演化的代码文件进行定位时,需要输入与演化相关的描述性语句,将其称为演化需求。输入的演化需求在进行定位时意义重大,因为其内容直接关系到能否准确定位到相关文件,也就直接关系到能否确认演化。
选取一条演化需求,并对这条需求也做去除停词和词根还原处理。然后计算该条需求和每一个主题的相似度,实际上就是计算需求和每个主题夹角的余弦值。根据计算出来的相似度,选择相似度最高的一个或若干个主题中所包含的主题词,然后统计这些主题词在所有特征文件中的出现次数,同时也需要统计出每个特征文件中的总词数。根据文献[39]所提的内容,使用“出现率”这一标准来对所有特征文件进行排序。
定义1使用ONT(occurrence numbers of topicwords)表示在一个特征文件中所选主题词出现的总次数,使用TWD(total words in a document)代表该特征文件中词汇总数,则出现率(occurrence rate)可定义如下:

4.3 演化确认
演化确认的方法有很多种,例如对演化的过程模型进行验证,亦或是用静态的方法去验证,或者进行形式化验证,但是这些方法对开源软件都不可用,原因如下:
(1)开源软件由于群智开发,开发过程和演化过程不可建模的特点,前期使用过程确认的研究成果无法适用于开源软件。
(2)静态方法的基本思想是要考虑程序的所有执行路径,并且需要验证每条执行路径上的断言是否满足。如果是大型的系统采用这种方法进行确认,则会出现数量极其庞大的路径网,这就需要确认人员对系统具有较高的理解程度,而开源软件的维护人员往往不是开发人员,因此维护人员对系统的理解程度就会比较低,导致这种方法可行度不高。
(3)形式化的验证方法需要有软件系统对应的文档支持,但绝大多数的开源软件文档缺失严重,无法使用形式化的方法。
本文提出的软件演化确认方法,是针对具有群智开发,开发过程和演化过程不可建模,文档缺失等特点的开源软件进行的,同时确认人员不需要对系统有较高的理解程度,因此最终希望通过实验给出一个具体的数值结果,根据这个结果来区分是否演化。
本文不但需要对已经演化的需求进行实验,也要对没有演化的需求进行实验。故在本文中,对大量没有演化的需求也进行了实验,并分析两者的实验结果。通过大量实验结果和相关数据的分析,得出了本文所题方法在确认软件演化时的结论:当结果达到或高于该标准的某个值时,就认为选取的这条演化需求已经成功演化;当低于该标准的这个值时,就认为没有演化或演化失败。
5 实验
5.1 实验数据及获取
为了保证实验的客观性,本文构建了一个benchmark。在benchmark中,有相应的演化需求和该需求对应修改的源代码文件。
对于实验数据的处理,3.1节已经做了详细的介绍。
通过对现有开源软件的查找和benchmark的分析,并根据文献[39]的描述,下载了ArgoUML(http:// argouml-downloads.tigris.org/)0.20和0.22两个完整的版本(ArgoUML是由Java编写),同时也找到了与这两个版本对应的benchmark(http://www.cs.wm. edu/semeru/data/benchmarks/),这样本文所需要的实验数据就基本获取完毕。
在benchmark中,有多个文件夹,每个文件夹内文件所对应的内容如表3所示。

Table 3 File and its content in benchmark表3 benchmark中的文件及其内容
本文所用的查询语句就来自于Queries中的Short-Description。
5.2 实验过程
本文使用的LDA建模工具为JGibbLDA(http:// jgibblad.sourceforge.net/)。按照其对输入文件的要求(文件第一行为文档的数量,其余每行为文档内的具体词汇,词汇与词汇间用空格分开),把源代码的特征文件进行整理并形成一个单独的文件。输入文件内容和格式如表4所示。

Table 4 File format of input表4 输入文件格式
经过观察发现,源代码的特征文件数量特别庞大,一般都是几千甚至上万个,如果将一个特征文件作为一个文档进行整理,则输入文件内的行数会特别多,导致运行结果的收敛速度慢。因此把一个包中所有类的特征文件视为一个文档进行整理。
JGibbLDA是一个很复杂的非监督机器学习程序,其理论依据主要来自文献[26]。现在非监督的机器学习方法或者半监督的机器学习方法,大多需要设置一些参数调整后启动运行,JGibbLDA也是如此。表5介绍了JGibbLDA启动运行时所需要的主要参数和这些参数的意义。

Table 5 Parameter and its meaning表5 参数及其意义
在这些主要的参数中,dir、K、niters和twords的设置都相对简单,也不会对运行结果产生很大影响。但是α和β两个参数,都属于超参数,目前国内外的研究结果中,没有一种带有理论依据的设置方法,需要使用时赋值大多凭借的是人工经验。文献[33]的研究结果表明,α和 β可以赋值为50/k(k为输入文件内文档的数量)和0.1,因为这样运行结果会有较快的收敛速率。
在JGibbLDA运行结束后,使用一个名为modelfinal.twords的数据进行相关性计算,计算步骤大致为以下5步[39]:
(1)从ShortDescription中选取一条演化需求,对其进行去停词和词根还原处理。
(2)假设参数ntopics和twords分别设置为N和T,则生成N个T维的向量,同时需要把这N个T维的向量赋上初始值0。
(3)对这N个T维向量赋值:假设主题m(0<m<N+1)包含了处理后的演化需求中的单词wi(0<i<T+1),那么将单词wi所对应的概率p加到第m个向量的第i个位置。
(4)重复步骤3,直到这N个T维向量全部赋值完毕。然后将第m个T维向量的值,与文件modelfinal.twords中第m个主题词对应的值计算两个向量夹角余弦值,其中m=1,2,…,N。
(5)将计算出的余弦值按降序排列,取前一个或者多个主题的所有主题词,在所有源代码的特征文件中进行词频统计,计算出现率,把出现率按降序排列。
5.3 实验结果文件
使用JGibbLDA对源代码的特征进行分析,其结果文件可按后缀名分为5类文件,具体如表6所示。

Table 6 Filename extension and its content表6 文件后缀名及其内容
6 实验结果和分析
6.1 度量标准
为了对本文方法在性能等方面进行评测,需要使用一些度量标准。在信息检索领域,目前常常会使用查全率和查准率作为衡量指标,并通过这两个指标来对输出结果进行评价[40]。
定义2Recall表示查全率,correct代表所需查找的演化文件,retrieved代表使用本文方法查找出来的文件,则查全率的定义为:

查全率,也称为召回率,是指检出的相关文献量与检索系统中相关文献总量的比率,是衡量信息检索系统检出相关文献能力的尺度。
定义3 Precision表示查准率,correct代表所需查找的演化文件,retrieved代表使用本文方法查找出来的文件,则查准率的定义为:

查准率,也可称为精度,是衡量某一检索系统的信号噪声比的一种指标,即检出的相关文献与检出的全部文献的百分比。
定义4使用F-measure代表查全率和查准率调和平均数,Recall代表查全率,Precision代表查准率,则调和平均数定义为:

6.2 实验结果
本文实验使用了ArgoUML的0.20和0.22两个版本的源代码作为实验源数据,按照上文所提到的处理方法进行整理后,一共得到1 562个类(或特征文件)和96个包,然后按照JGibbLDA输入文件的要求整理成一个文件。根据输入的文档数和所需要的结果,α、β、K、niters和twords共5个参数的值分别设置为0.528、0.1、30、1 000、100和50。
表7为从ShortDescription中选取的10条已经演化的描述。
因为本文试图找到一种能够确认软件是否已经演化的方法,所以不但需要对已经演化的进行实验,而且还要对没有演化的也进行同样的实验,进而找出两者的区别。故从其他版本的ShortDescription中,也找了10条在0.20和0.22版本没有进行演化的描述,具体如表8所示。

Table 7 Description of evolution requirement表7 对演化需求的描述

Table 8 Description of non-evolution requirement表8 对没有演化需求的描述
文献[40]推荐了取出现率最高的前10%~15%样本来进行查全率和查准率的计算,那就取前10%来进行计算。
对于已经演化和没有演化的进行实验后,都计算查全率和查准率,具体数值如表9所示。
为了防止实验结果的偶然性,针对一条已经演化的需求,需要把10条没有演化的需求都给出结果,取平均值。例如对于实验序号1中的实验,未演化的查全率和查准率是把表8中的10条没有演化的都求出查全率和查准率后取的平均值。从实验结果可以得出,已演化的查全率和查准率平均值为90.00%和1.09%,而没有演化的却只有41.58%和0.49%,两者具有很明显的差异。

Table 9 Results of experiments with 10%sampling表9 取10%样本的实验结果
图2是表9中的数据,其中图(a)是查全率,图(b)是查准率。

Fig.2 Recall and Precision with 10%sampling图2 取10%样本的查全率和查准率
从图2中可以很明显地看出,针对每一个实验,已经演化的在查全率和查准率上都高于没有演化的,这说明本文方法确实能区分演化与否。但是进一步思考会发现,对于查全率和查准率,已演化和没有演化的都不能指定一个数值,这个数值能把10次实验都区分开来。
从上述查全率和查准率的表达公式可以看出,两者存在着互逆的关系,更直观地说一个将文档集合中所有文档返回为结果集合的系统有100%的查全率,但是查准率却很低(http://baike.baidu.com/view/ 2126615.htm?fr=aladdin)。举个例子来说,比如从1 000个文件中找1个文件,那么correct就是1,当retrieved取1 000时,那查全率必定是100%,反而查准率只有0.1%。因此为了综合评价两者的性能,就需要使用调和平均数F-measure。
表10为取10%样本的调和平均数。

Table 10 F-measure with 10%sampling表10 取10%样本的调和平均数
图3为已演化和未演化的调和平均数对比图。

Fig.3 F-measure with 10%sampling图3 取10%样本的调和平均数
从表10和图3中可以得出,已演化的调和平均数的平均值为0.021,而未演化的只有0.009 7,具有很明显的差异,从一条实验结果也可以看出两者也有差异。但是同样存在和查全率、查准率一样的问题,就是对于整体不能指定一个数值来划分两者。
从查全率、查准率和调和平均数的图可以很直观地看出,对于一个实验点是具有很强区分度的,但是无法将整体进行区分,因此考虑缩小文件数量,从10%缩小到5%,来重新计算实验结果。
表11为取5%样本的查全率、查准率和调和平均数的统计结果。

Table 11 Recall、Precision and F-measure with 5%sampling表11 取5%样本的查全率、查准率和调和平均数
从表11中可以得出,已演化的在查全率、查准率和调和平均数三者的平均数为68.33%、1.28%和2.50%,没有演化的确只有25.67%、0.56%和1.10%。
图4为取5%样本的查全率、查准率和调和平均数三者的比较结果。其中图(a)是查全率,图(b)是查准率,图(c)是调和平均数。
从图4中可以直观地看出,在图(b)和(c)中,已演化和没有演化的区别已经比较明显。若图(b)中查准率在1.15%和1.28%之间取值,或图(c)中调和平均数在2.27%和2.44%之间取值,都可以在10条数据中按是否演化区分出9条,区分度已经达到90%。

Fig.4 Recall、Precision and F-measure with 5%sampling图4 取5%样本的查全率、查准率和调和平均数
是否有方法能进一步区分是否演化,或者说是否能再次提高查全率、查准率和调和平均数,文献[39]针对该问题,使用了一类被称为“组合词”的词汇来提高查全率、查准率和调和平均数。所谓的组合词,就是由两个或者两个以上的基本单词复合而成,类似于“listenerlist”和“loadedfromfile”。这类词汇在预处理时没有进行分词操作,同时在人类的自然语言中是不会出现的,在使用LDA进行分析[41]时也不会进行特别处理。然而实际上,这些词汇在系统开发人员编写代码时,会经常使用到这类的词汇来表达一些复杂的操作,同时也方便以后维护时能很快理解这块代码所完成的功能。例如看到“listenerlist”,开发人员很直观的感受就是这应该是个侦听列表。组合词的组合方式很多,同一个组合词在整个系统的源代码中不会出现太多次,因此使用组合词的方式来提高查全率、查准率和调和平均数。
使用组合词提高相应的数据,具体可以分为以下3步:
(1)将所选主题中的主题词提取出来;
(2)在所有源代码特征文件中统计这些组合词出现的次数,并把这些出现次数按降序排列;
(3)若组合词出现次数最好的演化文件排第M位,出现率最低的演化文件排第N位,则把前M个文件和前N个文件进行交集操作,找出公共部分。
对表7中10条已经演化的描述,再次利用组合词的方法进行处理,减少了很多无关文件的数量,具体如表12所示。
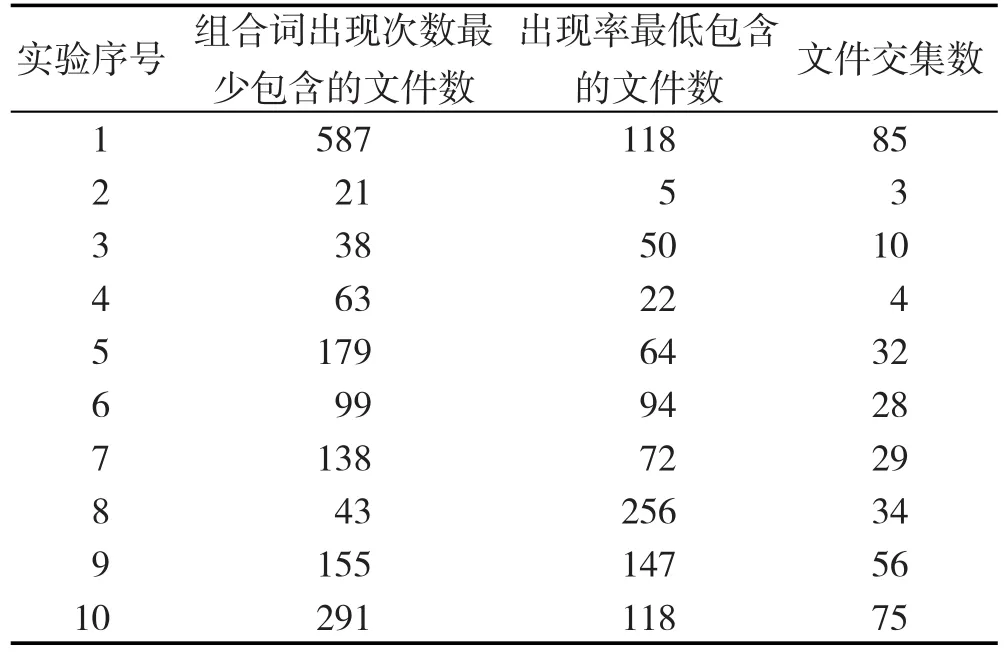
Table 12 Statistical results within compound words表12 考虑组合词统计结果
从表12的统计结果可以看出,最好的情况下,可以减少222个无关文件,最差减少了2个文件,平均减少了49。
表13给出了在考虑组合词后,取前5%样本的查全率、查准率和调和平均数。
根据表13的计算结果,通过使用组合词的方法,在取前5%样本时,10组已演化的查全率、查准率和调和平均数的均值分别是100.00%、2.56%和4.95%,而未演化的只有25.67%、0.56%和1.10%,两者间的差距与表11相比较更加明显。
图5为取5%样本并考虑组合词的查全率、查准率和调和平均数的比较结果。
从图5的数据中可以很明显地看出,对于查全率和查准率,若查全率取90%到100%之间的值,或查准率取1.15%到1.28%之间的值,都可以把10个已演化的和10个没有演化的需求进行区分。

Table 13 Recall、Precision and F-measure with 5% sampling and within compound words表13 取5%样本并考虑组合词查全率、查准率和调和平均数
文献[42]是一种基于文本的确认方法,将其作为基线方法用于对表7中的数据进行处理,并与本文方法进行对比。
表14为取前5%样本,采用基线方法对表7中数据处理后得出的结果。
基线方法与本文方法在查全率、查准率和调和平均数上的对比如图6所示。
在对比图中可以直接看出,基线方法在区分是否演化时数值差距小,同时数值起伏大,不如本文方法的区分度强和稳定。通过表14和表13,可以直接算出差距。本文方法(在考虑组合词时)相较没有演化的,在查全率、查准率和调和平均数上三者均值的差值为74.33%、2.00%和3.86%,而基线方法与没有演化的差值却只有24.33%、0.56%和0.91%,差距显而易见。

Table 14 Recall、Precision and F-measure of baseline with 5%sampling表14 基线方法取5%样本的查全率、查准率和调和平均数
6.3 实验结论
在图6中,通过对查全率和查准率取值的调整,可以对一条演化需求是否已经演化进行确认。对查全率和查准率两者的取值,本文取可以进行确认的最大值和最小值的平均数给出实验结论,故查全率取95%,查准率取1.215%。

Fig.5 Recall、Precision and F-Measure with 5%sampling and within compound words图5 取5%样本并考虑组合词查全率、查准率和调和平均数
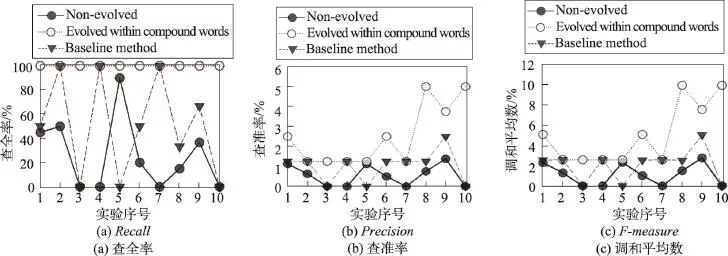
Fig.6 Method comparison of this paper and baseline图6 本文方法与基线方法的对比
通过上述实验结果,可以得出本文实验的结论:在使用组合词,并取出现率前5%高的文件数量进行计算后,若查全率不低于95%,且查准率不低于1.215%时,可以确定输入的演化需求与演化实质符合;若查全率低于95%,或查准率低于1.215%时,则输入的演化需求与演化实质不符合。
7 实验总结和展望
对于一个演化需求,软件是否按照需求进行了演化,一直都是软件演化领域一个重要的研究方向。过去对软件演化的研究,大多都是理论上的推演或者证明,而对演化确认的研究就更少了。为了能在软件演化或者软件工程领域取得一些突破和创新,本文特使用软件源代码作为实验数据,使用主题模型LDA作为实验工具,提出了软件演化确认的方法,并用大量的实验数据证明了方法的有效性,同时开发出与本文方法所对应的确认工具。
最开始研究非监督性机器学习主题模型的目的是将其应用于处理自然语言和检索信息,本文创新性地将其应用于软件演化领域,并取得一定的成绩,这也说明了未来人工智能和软件工程将有更多的融合,也必将取得更大的成就。
本文方法虽然取得了一定的成果,但是依然存在着一些问题:首先,确认软件是否演化,输入的演化需求很关键,这些单词都需要很客观和准确地描述在代码层面上修复了什么错误或者缺陷,这样确认出来的效果才能好;其次,很多演化语句描述的是两个正式版本间的测试版,使用这些语句时确认效果不会很好;最后,软件源代码文件中存在着许多xml或html文件,这些文件中也有大量的特征信息需要去提取。同时本文所提出的演化确认方法并不是一种通用性的方法,因此有它的适用范围和局限性。
(1)本文方法需要找到同一个软件的两个不同版本,并按上文所述方法进行处理和整合;若只有一个版本,则实验效果会受到很大的影响。
(2)本文的实验结论建立在大量实验结果的平均值上,实验数据真实可靠,实验结果可信度高,但是主题模型是一种概率模型,对于极少数的特殊情况可能会有一定的误差。
(3)数据源、数据预处理和代码书写的规范程度都会影响最终的结果。
本文将软件演化与机器学习进行创新性交叉研究,并采用真实的实验数据进行证明,这给了人们很多启示和未来的研究方向。首先在设置JGibbLDA运行参数时,对于两个超参数α和β,是否能提出一种有理论依据或有大量实验证明的方法;其次,在对软件源代码的处理上,能否引入其他的信息,包括一些简单的图片;最后,能否研究出新的方法将演化确认进行得更好。同时,将进一步研究主题模型是否还能应用在软件工程的其他领域,并对本文所开发的确认工具进行完善和扩展,以支持更多语言的源代码。
References:
[1]Von Krogh G,Haefliger S,Spaeth S,et al.Carrots and rainbows:motivation and social practice in open source software development[J].MIS Quarterly,2012,36(2):649-676.
[2]Ghapanchi A H,Wohlin C,Aurum A.Resources contributing to gaining competitive advantage for open source software projects:an application of resource-based theory[J].International Journal of Project Management,2014,32(1):139-152.
[3]Wang Huaimin,Shi Peichang,Ding Bo,et al.Online evolution of software services[J].Chinese Journal of Software, 2011,34(2):318-328.
[4]Balsamo S,Marco A D,Inverardi P,et al.Model-based performance prediction in software development:a survey[J]. IEEE Transactions on Software Engineering,2004,30(5): 295-310.
[5]Guttag J V,Horowitz E,Musser D R.Abstract data types and software validation[J].Communications of the ACM, 1978,21(12):1048-1064.
[6]Thomas N C,Reeves Jr H L.Experience from quality assurance in nuclear power plant protection system software validation[J].IEEE Transactions on Nuclear Science,1980,27 (1):899-908.
[7]Heiner M.Petri net based software validation,ICSI TR-92-022[R].Berkeley,USA:International Computer Science Institute,1992.
[8]Silva V D,Kroening D,Weissenbacher G.A survey of automated techniques for formal software verification[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2008,27(7):1165-1178.
[9]Ivančić F,Yang Z,Ganai M K,et al.Efficient SAT-based bounded model checking for software verification[J].Theoretical Computer Science,2008,404(3):256-274.
[10]Komuravelli A,Gurfinkel A,Chaki S,et al.Automatic abstraction in SMT-based unbounded software model checking [C]//LNCS 8044:Proceedings of the 25th International Conference on Computer Aided Verification,Saint Petersburg,Russia,Jul 13-19,2013.Berlin,Heidelberg:Springer, 2013:846-862.
[11]Bérard B,Bidoit M,Finkel A,et al.Systems and software verification:model-checking techniques and tools[M].Berlin,Heidelberg:Springer,2001.
[12]Philippaerts P,Mühlberg J T,Penninckx W,et al.Software verification with VeriFast:industrial case studies[J].Science of Computer Programming,2014,82:77-97.
[13]Dai Fei,Li Tong,Xie Zhongwen,et al.Towards an algebraic semantics of software evolution process models[J].Journal of Software,2012,23(4):846-863.
[14]Zhang Ying,Su Lili,Yang Zhifan,et al.Multi-label emotion tagging for online news by supervised topic model[C]// LNCS 9313:Proceedings of the 17thAsia-Pacific Web Conference on Web Technologies and Applications,Guangzhou,China,Sep 18-20,2015.[S.l.]:Springer International Publishing,2015:67-79.
[15]Lin Tianyi,Tian Wentao,Mei Qiaozhu,et al.The dual-sparse topic model:mining focused topics and focused terms in short text[C]//Proceedings of the 23rd International Conference on World Wide Web,Seoul,Apr 7-11,2014.New York: ACM,2014:539-550.
[16]Guo Zhen,Zhang Zhongfei,Zhu Shenghuo,et al.A two-level topic model towards knowledge discovery from citation networks[J].IEEE Transactions on Knowledge and Data Engineering,2014,26(4):780-794.
[17]Gao J,Espinoza R,He J.Testing coverage analysis for software component validation[C]//Proceedings of the 29th Annual International Computer Software and Applications Conference,Edinburgh,Jul 26-28,2005.Piscataway,USA: IEEE,2005,1:463-470.
[18]Wei Qiang,Jin Zhi,Xu Yan.Service discovery for Internet of things based on probabilistic topic model[J].Journal of Software,2014,25(8):1640-1658.
[19]Li Meng,Zhao Junfeng,Xie Bing.Obtaining functional topics from source code based on topic modeling and static analysis [J].Scientia Sinica Informationis,2014,44(1):54-69.
[20]Qian Xiao,Jun Cheng.Human action recognition using topic model[C]//Proceedings of the 2014 IEEE International Conference on Information Science and Technology,Shenzhen, China,Apr 26-28,2014.Piscataway,USA:IEEE,2014.
[21]Kinoshita A,Takasu A,Adachi J.Real-time traffic incident detection using a probabilistic topic model[J].Information Systems,2015,54:169-188.
[22]Guo Qun,Lu Xiaoqiang,Yuan Yuan.Video quality assessment via supervised topic model[C]//Proceedings of the 2nd IEEE China Summit and International Conference on Signal and Information Processing,Xi'an,China,Jul 9-13,2014.Piscataway,USA:IEEE,2014:636-640.
[23]Zhang Tianbing,Luo Wang.Image quality assessment using author topic model[C]//Proceedings of the 2013 International Conference on Information Technology and Applications, Chengdu,China,Nov 16-17,2013.Piscataway,USA:IEEE, 2013:63-66.
[24]Xu Ge,Wang Houfeng.The development of topic models in natural language processing[J].Chinese Journal of Computer,2014,34(8):1423-1436.
[25]Cassar G,Barnaghi P,Moessner K.Probabilistic matchmaking methods for automated service discovery[J].IEEE Transactions on Services Computing,2014,7(4):654-666.
[26]Blei D M,Ng A Y,Jordan M I.Latent Dirichlet allocation[J]. The Journal of Machine Learning Research,2003,3:993-1022.
[27]Steyvers M,Griffiths T.Probabilistic topic models[J].Handbook of Latent SemanticAnalysis,2007,427(7):424-440.
[28]Dit B,Revelle M,Gethers M,et al.Feature location in source code:a taxonomy and survey[J].Journal of Software: Evolution and Process,2013,25(1):53-95.
[29]Hoffman M D,Blei D M,Bach F R.Online learning for latent Dirichlet allocation[J].Advances in Neural Information Processing Systems,2010,23:856-864.
[30]Teh Y W,Jordan M I,Beal M J,et al.Hierarchical Dirichlet processes[J].Journal of the American Statistical Association,2012,101(476):1566-1581.
[31]Blei D,Carin L,Dunson D.Probabilistic topic models[J]. IEEE Signal Processing Magazine,2010,27(6):55-65.
[32]Wang C,Paisley J W,Blei D M.Online variational inference for the hierarchical Dirichlet process[J].Journal of Machine Learning Research,2011,15:752-760.
[33]Griffiths T L,Steyvers M.Finding scientific topics[J].Proceedings of the National Academy of Sciences,2004,101 (S1):5228-5235.
[34]Minka T P.Estimating a Dirichlet distribution[J].UAI,2003, 39(3273):115.
[35]Heinrich G.Parameter estimation for text analysis[R].Germany:University of Leipzig,2005.
[36]Wang Zhenzhen,He Ming,Du Yongping.Text similarity computing based on topic model LDA[J].Computer Science,2013,40(12):229-232.
[37]Abebe S L,Haiduc S,Marcus A,et al.Analyzing the evolution of the source code vocabulary[C]//Proceedings of the 13th European Conference on Software Maintenance and Reengineering,Kaiserslautern,Germany,Mar 24-27,2009. Piscataway,USA:IEEE,2009:189-198.
[38]He Yun,Wang Wei,Li Tong,et al.Behavior and topic oriented software feature location method[J].Journal of Frontiers of Computer Science and Technology,2014,8(12): 1452-1462.
[39]Han Junming,Wang Wei,Li Tong,et al.Feature location method of evolved software[J].Journal of Frontiers of Computer Science and Technology,2016,10(9):1201-1210.
[40]Ju Xiaolin,Jiang Shujuan,Zhang Yanmei,et al.Advanced in fault localization techniques[J].Journal of Frontiers of Computer Science and Technology,2012,6(6):481-494.
[41]Zhai K,Boyd-Graber J,Asadi N,et al.Mr.LDA:a flexible large scale topic modeling package using variational inference in MapReduce[C]//Proceedings of the 2014 International Conference on World Wide Web,Seoul,Apr 7-11,2014. New York:ACM,2014:879-888.
[42]Marcus A,Sergeyev A,Rajlich V,et al.An information retrieval approach to concept location in source code[C]//Proceedings of the 11th Working Conference on Reverse Engineering,Delft,Netherlands,Nov 8-12,2004.Washington: IEEE Computer Society,2004:214-223.
附中文参考文献:
[3]王怀民,史佩昌,丁博,等.软件服务的在线演化[J].计算机学报,2011,34(2):318-328.
[13]代飞,李彤,谢仲文,等.一种软件演化过程模型的代数语义[J].软件学报,2012,23(4):846-863.
[18]魏强,金芝,许焱.基于概率主题模型的物联网服务发现[J].软件学报,2014,25(8):1640-1658.
[19]李萌,赵俊峰,谢冰.基于主题建模和静态分析技术的软件代码功能性主题获取方法[J].中国科学:信息科学, 2014,44(1):54-69.
[24]徐戈,王厚峰.自然语言处理中主题模型的发展[J].计算机学报,2014,34(8):1423-1436.
[36]王振振,何明,杜永萍.基于LDA主题模型的文本相似度计算[J].计算机科学,2013,40(12):229-232.
[38]何云,王炜,李彤,等.面向行为主题的软件特征定位方法[J].计算机科学与探索,2014,8(12):1452-1462.
[39]韩俊明,王炜,李彤,等.演化软件的特征定位方法[J].计算机科学与探索,2016,10(9):1201-1210.
[40]鞠小林,姜淑娟,张艳梅,等.软件故障定位技术进展[J].计算机科学与探索,2012,6(6):481-494.

HAN Junming was born in 1988.He is an M.S.candidate at Yunnan University.His research interests include software engineering,software evolution and data mining.
韩俊明(1988—),男,云南文山人,云南大学硕士研究生,主要研究领域为软件工程,软件演化,数据挖掘。

WANG Wei was born in 1979.He received the Ph.D.degree in system analysis and integration from Yunnan University in 2009.Now he is an associate professor at Yunnan University,and the member of CCF.His research interests include software engineering,software evolution and data mining.
王炜(1979—),男,云南昆明人,2009年于云南大学系统分析与集成专业获得博士学位,现为云南大学副教授,CCF会员,主要研究领域为软件工程,软件演化,数据挖掘。发表学术论文15篇,出版教材1部,主持国家级项目1项、省部级项目5项。

LI Tong was born in 1963.He received the Ph.D.degree in software engineering from De Montfort University in 2007.Now he is a professor and Ph.D.supervisor at Yunnan University,and the senior member of CCF.His research interests include software engineering and information security.
李彤(1963—),男,河北石家庄人,2007年于英国De Montfort大学软件工程专业获得博士学位,现为云南大学软件学院党委书记、教授、博士生导师,CCF高级会员,主要研究领域为软件工程,信息安全。发表学术论文100余篇、专著2部、教材5部,主持国家级项目5项、省部级项目14项、其他项目20余项。

HE Yun was born in 1989.He is a Ph.D.candidate at Yunnan University,and the student member of CCF.His research interests include software engineering,software evolution and data mining.
何云(1989—),男,云南建水人,云南大学博士研究生,CCF学生会员,主要研究领域为软件工程,软件演化,数据挖掘。
Approach of Open Source Software Oriented Evolving Validation*
HAN Junming1,WANG Wei1,2+,LI Tong1,2,HE Yun1
1.College of Software,Yunnan University,Kunming 650091,China
2.Key Laboratory for Software Engineering of Yunnan Province,Kunming 650091,China
+Corresponding author:E-mail:wangwei@ynu.edu.cn
Software evolution is a hot research field in software engineering.Because the open source software has the characteristics of group intelligence development and the process of evolution uncontrollable and not modeling, the traditional validation method can not apply to open source software.This paper proposes a software validation method from semantic function,attempts to cluster the codes in the way of the topic,and each topic presents a function module in software system.This paper transfers the evolving validation into finding the mapping relation between the function module and the requirements of software evolution.Finally,this paper takes advantage of source codes in open software,makes experiment and gets many actual data,then analyzes these data,the results make clear that the proposed method is better than the comparison method in distinguishing whether evolved or not, and it can be used to verify the software evolution.
software evolution;validation;topic model;open source software
10.3778/j.issn.1673-9418.1604026
A
TP311.5
*The National Natural Science Foundation of China under Grant Nos.61462092,61262024,61379032(国家自然科学基金);the Key Project of Natural Science Foundation of Yunnan Province under Grant No.2015FA014(云南省自然科学基金重点项目);the Natural Science Foundation of Yunnan Province under Grant No.2013FB008(云南省自然科学基金).
Received 2016-04,Accepted 2016-06.
CNKI网络优先出版:2016-06-27,http://www.cnki.net/kcms/detail/11.5602.TP.20160627.0929.008.html
HAN Junming,WANG Wei,LI Tong,et al.Approach of open source software oriented evolving validation. Journal of Frontiers of Computer Science and Technology,2017,11(4):539-555.
摘 要:软件演化确认是软件工程领域的一个重点和热点的研究方向。由于开源软件具有群智开发,演化过程不可控和不可建模等特点,使得传统的确认方法不适合于开源软件,故从功能语义角度提出了一种软件演化确认方法,试图将代码按主题的方式进行聚类,每一个主题表征软件系统的一个功能集合,演化确认工作被转化为功能集合与演化需求之间的映射关系。通过对现有开源软件的源代码进行实验,获取了大量的真实可靠实验数据,对这些实验数据进行分析后得出的实验结果表明该方法相较基于文本的基线方法,更能有效区分是否已经演化,可以用于对软件演化进行确认工作。
猜你喜欢
现代信息科技(2021年21期)2021-05-07
现代电子技术(2018年20期)2018-10-24
现代电子技术(2018年16期)2018-08-21
中国司法鉴定(2018年4期)2018-07-30
现代情报(2018年11期)2018-01-07
现代电子技术(2017年23期)2017-12-20
计算机应用(2017年10期)2017-12-14
计算机应用(2016年10期)2017-05-12
中国管理信息化(2009年10期)2009-06-19
