
AI决策浪潮背后
2017-04-27 12:02黑爪
中欧商业评论 2017年4期
文/黑爪
AI决策浪潮背后
文/黑爪
基于概率模型的人工智能技术,在具体案例的决策、判断中存在不足,可能会造成巨大的决策风险。
人类自古就在梦想,要制造出会思考的机器。这个愿望至少可以追溯到古希腊时代,传说中的皮格马利翁、代达洛斯、赫菲斯托斯都被赋予了传奇发明家的形象,经他们之手而诞生的葛拉蒂雅、塔罗斯、潘多拉,也许便是出现在人类叙述中最早的人工智能。
今天,人工智能已经真实地活跃在众多的应用和研究领域。但它不是魔术,也不创造奇迹。让我们透过喧嚣,回顾一下人工智能的前世今生,借此看清它究竟是什么,现在能作什么,未来能作什么。
早期的人工智能,迅捷地攻占了一些对人类大脑而言相对困难,而对计算机来说则显得直截了当的问题,换句话说,那些可以用一系列数学规则所描述的问题。
但人工智能所面临的真正挑战却恰恰相反。我们希望它能替代我们的,有更多的是人类很容易执行,却非常难以用规则来描述的任务,那些我们通过直觉来解决的问题。例如,听懂别人说话,或者在一幅图片里找到人脸。
第一波浪潮:难以理解现实的专家系统
人工智能的第一次技术发展,是基于人类专家知识的人工智能。人工智能专家提取特定领域的知识,将其转换成可输入计算机的规则,以及遵循不同规则带来的不同后果。计算机继而运用逻辑推理来“懂得”这些采用正规语言所描述的说明。
这个技术可以用于日程安排,棋类游戏(例如IBM战胜国际象棋大师卡斯帕罗夫的超级计算机深蓝),或者替人报税等,有非常明确而具体的条件,执行明确的任务。对现实世界进行认知,则是第一波人工智能的短板。此外,它不具备自我训练和提高的能力,这恰恰又是作为智能体的一个要素。那期间有个著名的项目叫作Cyc,由推理引擎加数据库组成。人们希望这样的一套系统,可以利用足够的复杂度,来精确地描述现实世界。然而Cyc让人失望了。例如,它试图去读一个故事,故事里有个人叫弗雷德,每天早上会刮胡子。然而它的推理引擎检测到了故事中有一处前后矛盾:它知道人的身上没有电动部件,可是每当弗雷德剃须时手里拿着电动剃须刀,于是它相信这个“剃须时的弗雷德”身上包含了电动部件,因此它问,弗雷德剃须时还是不是人。

这是仰仗硬编码知识的智能系统,也就是第一波人工智能所面临的一个经典困难。它说明人工智能系统需要具备通过从元数据中提取规律来自主获取知识的能力,这就是我们今天说的机器学习。
但这并不意味着第一波技术对于今天毫无意义,去年美国国防高研署(DARPA)成功完成了一项数字安全测试,便是基于第一波人工智能技术的应用。孤立的技术,在外部环境(硬件、数据量、配套技术)不成熟的情况下,可以作的另一件事,就是等待。
第二波浪潮:个体精度欠缺的机器学习系统
第二波人工智能出现的最好例子,也出自美国国防高研署。他们在2004到2005年两年间鼓励并组织业界进行了大量的自驾车研究,并推出一个挑战赛,看谁的自驾车能在加利福尼亚和内华达的沙漠里跑150英里。结果,2004年那一届,没有一辆车跑完,事实上没有一辆车跑过了8英里。原因是这些自驾车的视觉系统分辨不出远处的黑色物体,究竟是阴影还是石块,“我”是应该避开呢,还是应该碾过去。因此它们大多在这个问题上翻了船。到了2005年这一届,情况一下子大不一样,有5辆车跑完了全程。
造成这个差别的原因,正是他们大多开始使用机器学习的技术,运用概率方法来处理信息。这就是人工智能技术的第二波。
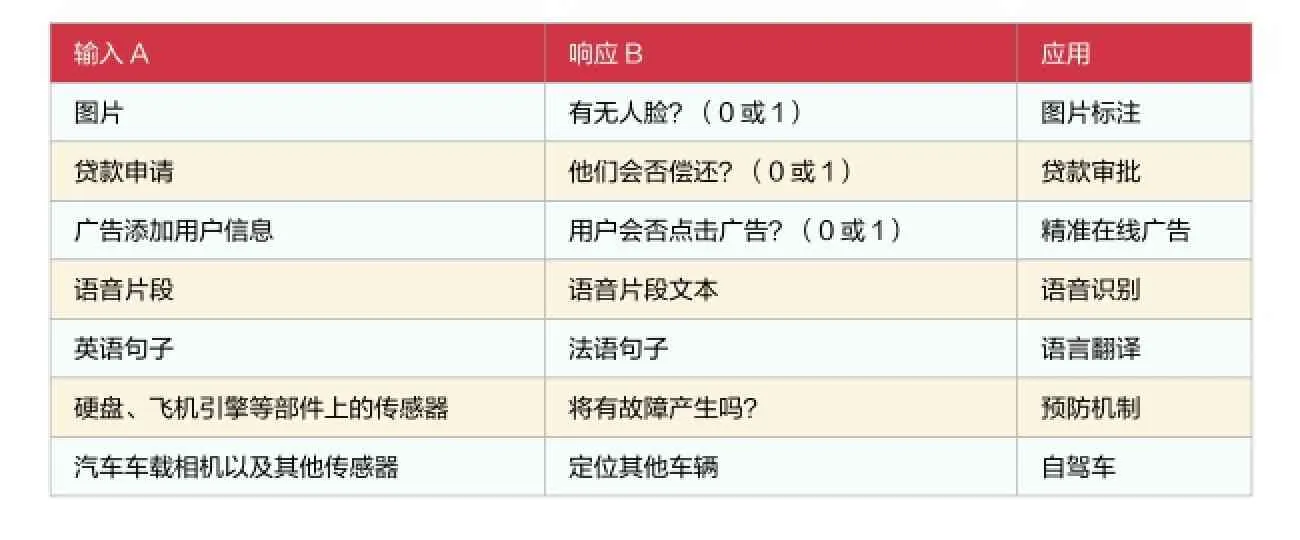
表1 第二波人工智能工作原理
这一波的特点是统计学习。它在语音识别,人脸识别等应用领域作得非常成功。人们常常会说,计算机“就是”会学习啊。但事实真的不是你以为的那样“就是”,若没有背后强大的,将现实问题用统计数学模型来描述的支撑,它便“就是”不会学习。
我们现在看见的、谈论的,并且真正应用到商业领域的,大多是此处描述的第二波人工智能技术。撇开它铺天盖地的舆论影响,真正被有效利用的类型极其有限。近来几乎所有的人工智能进展都只是一种,那就是输入数据(A),迅速产生简单响应(B),如表 1所示。
就这么简单地输入A,输出B,已经足够改变许多行业了。然而“A→B”与科幻小说向我们许诺的有感知的机器人,毕竟相去甚远,人类的智力更是远非“A→B ”所能相比。为什么这么说?例如有一张拿着牙刷的小男孩图片,被人工智能识别为,一个拿着棒球棍的小男孩。
这让我们发笑,因为我们人类绝不会这样说。从这个例子可以看出,第二波技术在大量的工作中一次又一次地让我们叹服,但也会忽然间爆出这种笑料来。它所反映出来的一个结论则是,第二波人工智能在统计学范畴表现出色,但个体样例不可靠。而这种个案的不可靠,若是发生在金融领域,就是灾难性的。
将“A→B”放到具体的商业环境下意味着什么?前百度首席科学家吴恩达教授用这样一句话来解释:一个正常普通人能够用少于一秒钟的思考所完成的任务,都可以通过人工智能来实现。
第三波浪潮:初现成效的语境适应系统
借用美国国防高研署对第三波的定义,那就是“语境适应”。第三波的系统,会逐渐建造出“有意义”的模型用以描绘现实世界的现象。
举个例子,让第二波系统来甄别一张猫的图片不是问题,但如果你问它,为什么你认为它是一只猫呢?它的答案肯定是:“经过大量的计算,结果显示猫位居榜首。”这个答案显然并不能令人满意,我们希望它说,当然是猫了,你看它有耳朵,有爪子,有毛,以及各种把猫与其他东西区分开来的特征呢。具备了这种知道“为什么”的能力的第三波系统,便绝不会在把前面提到的图片标注为“拿棒球棍的小男孩”。
第二波系统对数据的依赖,几乎达到“丧心病狂”的地步,这也是吴恩达为什么说,当今的人工智能企业要成功,最重要的一是数据,二是人才。比如你要教会一个系统识别一个手写的数字,大概需要交给它5万甚至10万个例子,才能保证基本不出错,设想如果你教一个小孩识字,每一个字要教5万到10万次是什么情景。
因此,第三波基于“语境”模型系统的到来便成为一件自然而然的事。
IBM的辩论机器人从海量的辩论文本中学习提取有说服力的论点,谷歌刚刚推出的“观点接口”用以在社交媒体上辨别恶意评论,都是较为成功的应用尝试。从前面的分析可以看出,第一波人工智能,基于严格的问题定义(硬编码)而获得了较强的推理能力,略有认知,却完全欠缺学习和抽象能力。第二波人工智能建立在统计模型基础上,能够进行精准分类和预测,其认知和学习能力有了长足进步,却丧失了第一波技术的推理能力,同时抽象能力依然十分不足。第三波人工智能,理论上可以粗略理解为前两波的取长补短,然而并非把二者相加那样简单。基于统计模型的学习和基于严格问题定义的专家系统,同时存在于同一个智能系统这个目标,还有大量需要克服的技术实现以及成本问题。越仰仗人类直觉、感知的问题,对机器的挑战越大。去年圣诞期间,一辆优步无人车在旧金山当代艺术博物馆门前闯红灯的事故,就是一例。
是不是泡沫?
答案很坚决,不是。那怎样解释反复出现的涨潮退潮呢?又得回头看历史,这一次我们单独回顾一下目前最主流的“深度学习”技术的历史。

深度学习的变迁深度学习经历了漫长而丰富的历史,跌宕起伏的热度,也被叫过不同的名字,每一个名字都反映了特定年代下的视角和观点。
今天深度学习在很多人眼里是一个令人振奋的新技术,而事实上,它的历史可以回溯到20世纪40年代。它之所以看上去新,仅仅是因为它在近几年的这股热潮之前不被人看好,也因为它经历了许多不同的名字,直到最近,才定下来被叫作“深度学习”。
最早的学习算法很多是生物学习的计算模型,所以它曾经叫作人工神经网络(Artificial Neural Networks,ANNs),是实实在在基于生物大脑的启发为基础的学习系统。所以那个阶段的“学习”概念比今天的更宽泛。
对今天的深度学习而言,神经科学仅仅被当作启发和参照,已经不再是这个领域的主导指南。因为如今的科学对大脑的认识依然非常有限,远不能给人工智能提供足够的信息来进行模拟。而媒体对舆论的误导往往正源于此,它们通常会将深度学习与生物大脑联系在一起。理解了现代深度学习技术除了从大脑获得灵感外,它的技术体系还架构在大量对线性代数、概率、博弈理论、以及数字优化的基础之上这一点,也许将不再会被舆论所带来的威胁论吓倒。当然,也不会对人工智能正在带来的颠覆视而不见。
到了80年代,伴随着认知科学的兴起,神经网络又热过一次,被称作符号推理。这期间值得一提的是一种叫联结主义的观点——大量可以进行简单计算的单元联结在一起,能够执行智能任务。这个潮流持续到90年代中期而终止,它的“遗产”到了今天,在包括谷歌在内的很多项目中仍然得到广泛的应用。
这一波原本非常有价值的研究之所以戛然而止,很大程度上是因为那些开展这项研究的公司在寻求投资时夸大其词,而结果并未能达到浮夸的预期,导致了投资者失望。
人工智能行业有一个众所周知的事实,许多自20世纪80年代起就存在的算法如今表现优秀,但它们的优秀在大约2006年之前并不明显,原因恐怕只能用硬件开销来解释。当今强大而廉价的计算能力、存储能力弥补了超前优秀算法的时代鸿沟。
大数据让人工智能从“艺术”变为“技术”深度学习早在50年代就出现了,为什么到了最近才忽然重要起来?这是一种随机出现的狂热和泡沫吗?
其实从90年代起,它就有过不少成功的商业应用,但人们更多地视之为“艺术”而不是“技术”。不可否认,提升深度学习算法的性能需要一些技巧,但幸运的是,技巧的需求与训练数据的尺寸之间是反比关系,随着数据量的猛增,对技巧的需求也随之降低。
今天的学习算法在一些复杂任务的执行能力上达到人类的水平,但这些算法本身与80年代用来解决一些小儿科问题都十分挣扎的算法几乎一模一样。带来巨变的无疑是今天的海量数据。这些海量的数据来自高度联网的计算机,来自全社会生活的数字化,人们的每一个行为,甚至每一个步骤都被数字化后记录了下来,这是“大数据”年代给机器学习领域的大礼。
人工智能商业时代需要什么
理解了眼下的人工智能所能做和不能做的,下一步便需要企业家们将这一理解贯彻到企业的策略之中,这意味着,理解价值在哪个环节产生,什么是难以复制的。人工智能行业是一个非常开放的领域,几乎所有的顶级研究人员都没有保留地在发表最新成果,分享经验、想法以至开放源代码。在这个开源的世界里,如下资源因而变得极其宝贵:
数据顶尖的人工智能团队要复制别人的软件,大多数不会超过一到两年就能做到。但是要获得别人的数据却难于上青天。因此,数据而不是软件,是许多企业的防御堡垒。
人才简单的下载,再把开源代码应用到你的数据上,通常很难奏效。人工智能要求对你的商业环境和数据进行量身定制,这正是眼下硝烟弥漫的人工智能人才战的起因。
至于人工智能模仿人性善恶两极的潜能,已经有许多的讨论。然而它对于每一个个体,在未来可见时间里的最大威胁,可能还是对一部分人力工种的取代。致力于建造一个让每一个个体都有繁荣机会的世界,是作为企业领袖的责任。理解人工智能可以做什么,并将它运用到企业策略中只是一个开始,而不是结束。
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
福建基础教育研究(2019年6期)2019-05-28
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
作文大王·笑话大王(2018年5期)2018-06-22
环球时报(2018-02-02)2018-02-02
小康(2017年16期)2017-06-07
南风窗(2016年19期)2016-09-21
青少年科技博览(中学版)(2016年1期)2016-06-01
