
基于密度网格的概念漂移检测算法研究
2017-05-18 03:40崔泽林
网络安全技术与应用 2017年5期
◆崔泽林
(北京交通大学计算机与信息技术学院 北京 100044)
基于密度网格的概念漂移检测算法研究
◆崔泽林
(北京交通大学计算机与信息技术学院 北京 100044)
数据流的概念会随着时间的变化而变化,例如天气预报和网络监控。这种随时改变概念的现象叫做概念漂移。如果不处理好概念漂移不仅降低聚类的质量,并且还会导致错误的聚类结果。现有的概念漂移算法大多都依据分类算法,根据分类算法中的错误率来判断概念漂移。然而,在随时变化的数据流中很难发现类标签。在聚类检测概念漂移中,很多聚类算法都是再概念漂移检测之前,所以当发生概念漂移的时候还要重新聚类。我们提出了一种基于密度网格的数据流聚类和概念漂移检测算法,这个框架采用了一种策略动态地改变滑动窗口。由于用到了密度网格技术,它提升了DCDA检测算法的效率,并且利用可变滑动窗口替换了固定滑动窗口以适应数据流的变化。实验结果证明我们的框架在准确率和时间效率上好于DCDA。
数据流挖掘;聚类;密度网格;概念漂移
0 引言
数据流聚类[11]在许多决策支持系统应用的信息分析中发挥着越来越重要的作用,如网络流量监测、股票市场和信用卡欺诈检测[2]等。聚类分析可以帮助我们理解数据分布和本质。以往的研究表明,数据流的特点是实时、快速、海量、和无限的[8]。由于这样的特点,数据流是不可能被控制顺序并且难以放置所有数据流在内存中的处理(通常,数据被处理一次,不能再次访问)。其聚类要求就是数据流聚类算法的时间复杂度必须低。
然而,数据流的概念也会随时间的变化而变化的,即概念漂移[9]。换句话说,我们从当前数据中分析的概念会随时间推动而漂移。例如,客户的购买偏好可能会随着时间而改变,这中购买偏好可能取决星期、爱好的转移、折现率等[3]。如果我们不及时检测到概念漂移,我们最终可能得到错误的概念,这不仅降低了聚类的质量,也可能导致意想不到的聚类结果。因此,处理概念漂移在许多应用中是至关重要的。
在本文中,我们提出一个新概念漂移检测框架,这个框架基于密度网格[1]。此外,我们提出了一个可变大小的滑动窗口,根据我们提出的策略动态的改变滑动窗口的大小以适应数据流的变化,并加快检测速度和准确度。实验结果表明,我们提出的检测框架比现有方法更准确和更有效。
1 研究相关工作
概念漂移[9]是由Schlimmer和Granger提出。数据流中的概念漂移是指数据点在不同的时间段服从不同的分布模型的现象。Stream-detect[7]提出了通过随着时间的推移测量在线聚类结果偏差,识别数据流的变化。通过比较聚类中心均值、标准偏差、平均聚类规模、集群中新老聚类中心的聚类特征来度量聚类之间的偏差。如果超过一定的阈值,那么概念已经改变。但无论数据流是否漂移,流检测需要重新聚类的每一步。因此它的时间效率非常低。在论文[2],基于粗糙集理论和滑动窗口技术,作者提出了一种改进依赖于聚类的检测算法算法,它通过计算当前滑动窗口和历史滑动窗口之间的距离来检测概念漂移。只有当距离大于阈值时,才在当前滑动窗口中进行重新聚类,以捕捉新出现的新概念。结果时间效率有所提升。不幸的是,该算法只适用于分类性数据流,并且因为滑动窗口是固定的,它不适应数据流的变化。
基于密度网格的聚类算法已经成为了一个被广泛接受的聚类框架[1],并且有很好的聚类效果。它可以找到任意形状的簇集和有效地处理噪声。在此基础上也有许多基于密度网格的聚类算法被提出,如D-Stream I[4]、DD-Stream[10]和GDC-Stream[6]。这些都是单遍扫描算法,只处理原始数据一次,并且不需要设置的簇群个数。网格具有统计效果,所以聚类仅依赖于网格的数量,而不再管数据流中数据点的实数。基于密度网格的聚类算法采用两阶段方案[5],包括一个在线组件和离线组件。在在线组件钟,将读取的数据点映射到网格中,并更新的网格钟的密度。在离线组件中,它使用不完全分区策略,将密度网格聚类得到结果。
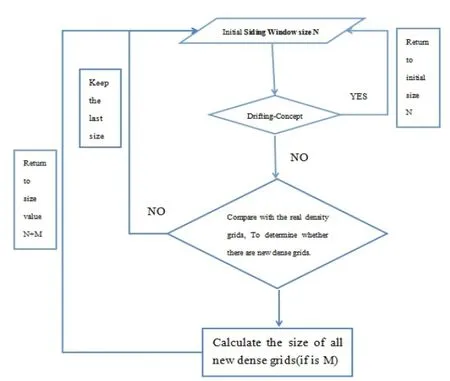
图1 可变滑动窗口调整策略
2 基于密度网格的概念漂移检测算法
我们提出框架是一种基于密度网格的聚类框架[1],有一个在线组件和离线组件。在在线组件中,我们定义一个临时密度网格和旧密度网格。可变滑动窗口读取新的数据流记录。当可变滑动窗口满时,将数据流映射到临时密度网格中,临时网格单元更新网格中的特征向量。然后计算临时密度网格和旧密度网格概念之间的距离。如果距离小于某一阈值,则将临时密度网格合并到旧密度网格中,并通过策略改变滑动窗口的大小。否则,如果距离大于阈值,它会清除旧的密度网格和交换旧的密度网格和临时密度网格之间的作用,并且初始化滑动窗口大小。在离线组件中,我们对旧密度网格进行聚类并得到聚类结果。
2.1 概念漂移检测算法
在线部件处理过程中,为了检测概念漂移我们提高了DCDA算法检测模型,我们通过计算旧密度网格和临时密度网格的距离判断概念漂移是否发生。我们利用网格的统计特性,这意味着我们的方法适用于一般数据。我们的方法只依赖于网格的数量,而不管数据流的实数。因此,大大提高了检测速度。此外,DCDA使用一个固定大小的滑动窗口,不能适应数据流的变化。在本文中,我们利用一个可变的滑动窗口,我们将在下一节描述。
我们改进的检测公式如下:
那么T与O关于属性空间S的距离可以表示为:

2.2 滑动窗口调整策略
滑动窗口的大小对于概念漂移检测算法非常重要,它不仅影响着检测效率还影响着检测的准确度。在文章[3]中所提到的,我们需要一个相对小的滑动窗口来捕捉不稳定的数据流频繁的发生概念漂移。对于稳定的、不经常发生概念漂移的数据流,我们需要一个相对较大尺寸的滑动窗口,以提高检测效率。但是,具有挑战意义的是,一些数据流可能会交替出现相对稳定和频繁变化两种现象。对于这些数据流,由于其DCDA采用固定滑动窗口大小,DCDA的检测是无效的。
在本节中,我们提出了一个可变的滑动窗口,如图1所示。
首先,我们初始化一个滑动窗口大小N和基于内存容量设置最大值滑动窗口NMAX。当数据流装满滑动窗口时,我们的框架把滑动窗口中的映射到相应的网格中。当前副本网格是空的,所以我们复制当前网格的特征向量复制到副本网格中,并清空当前网格数据。我们使用我们提出的检测当前网格和副本网格之间是否发生概念漂移。如果当前网格和副本网格是相同的概念,我们寻找是否有新的密度网格在当前网格而不在网格副本中,计算所有新增的密度网格的密度,然后设置滑动窗口大小为N = N + M(如果N+M大于NMAX,然后N=NMAX),将当前网格数据合并到副本网格中;如果当前网格数据和副本网格发生概念漂移,则在下一步恢复滑动窗口为原来的大小。
3 实验结果
3.1 实验设备与数据集
我们为了验证我们提出的框架概念漂移算法和聚类效果,实验环境采用真实的数据集KDD CUP-99,这个数据集被多篇数据流聚类文章引用。这个数据包含了麻省理工学院林肯实验室收集的网络入侵检测的数据流数据,数据集包含了41维属性,其中有34维连续型数值属性和7中分类型属性。
3.2 实验结果评价指标
为了与DCDA概念漂移检测聚类框架做对比,我们的实验采用了跟它一样的评价指标即使用精度和召回率。如果a是数据集中存在的概念漂移现象次数,b是我们提出的框架检测出来的概念漂移现象的个数和c是我们正确检测出概念漂移现象的个数。那么精度和召回率分别定义为:
3.3 实验结果对比
为了和DCDA框架的实验结果综合比较,我们随滑动窗口大小不同做实验并采用的评价标准和测试两个实验框架的时间效率。首先我们设置概念漂移检测阈值 θ= 0.1和参数 α= 0.5。实验结果如图2所示:我们可以看出在前部分F1值我们的框架比DCDA高,往后跟DCDA趋于平衡。从图3可以看出时间的性能比较,很明显,我们的框架概念漂移检测时间成本比DCDA低很多。

图3 时间消耗的比较
[1]曹付元.面向分类数据的聚类算法研究[D].山西大学,2010.
[2]张杰,赵峰.流数据概念漂移的检测算法[J].控制与决策,2013.
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11
汽车维修与保养(2020年10期)2021-01-22
数学物理学报(2020年3期)2020-07-27
汽车维修与保养(2020年11期)2020-06-09
制造技术与机床(2018年11期)2018-11-23
意林(绘英语)(2018年1期)2018-04-28
燕山大学学报(2015年4期)2015-12-25
西北工业大学学报(2015年3期)2015-12-14
信息安全研究(2015年3期)2015-02-28
城市轨道交通研究(2015年11期)2015-02-27
