
基于多类型文本的半监督性别分类方法研究
2017-06-01 11:29戴斌李寿山贡正仙周国栋
山西大学学报(自然科学版) 2017年1期
戴斌,李寿山,贡正仙,周国栋
(苏州大学 自然语言处理实验室,江苏 苏州 215006)
基于多类型文本的半监督性别分类方法研究
戴斌,李寿山*,贡正仙,周国栋
(苏州大学 自然语言处理实验室,江苏 苏州 215006)
提出一种基于多种文本类型的半监督性别分类方法,即根据微博平台中用户所产生的不同类型的文本(如:原创微博、转发微博等)对用户的进行性别分类。文中的方法是一种基于协同训练(Co-training)的半监督学习方法,旨在减少分类器对大量标注样本的依赖。首先将不同类型的文本分为不同的独立视图;其次,在每个视图中利用LSTM分类器挑选置信度最高的未标注样本;最后,将挑选出来的未标注样本加入训练模型迭代训练。实验结果表明我们的方法能够有效利用非标注样本信息,并明显优于其他现有的半监督性别分类方法。
性别分类;半监督学习方法;文本分类;LSTM
0 引言
随着互联网的迅猛发展,各种类型的社交网络平台受到越来越多用户的青睐。其中,微博(Mirco-blog)平台是目前最为流行的社交网络平台之一。微博的强大影响力吸引了众多的研究人员,一系列基于微博数据的分析研究和应用应运而生[1-2],例如,利用微博进行用户的情感分析、用户的类型识别和用户的广告推送[3-4]等。微博用户性别自动分类是其中一项基本任务,旨在对微博中的用户进行自动的性别判别。该任务在市场推广、广告推送和法律侦查等多个应用中具有较高的应用价值。
目前性别分类方法研究主要集中在基于监督学习的分类方法,并取得了较好的分类效果。例如:Nowson等[5]利用博客文本构建了一个自动识别性别的特征集;Mohanmad等[6]发现不同性别的用户在他们的工作邮件中使用的情感类词汇存在明显差异;Rao等[7]选用两类特征模型:社会语言学特征、N-gram特征及两类特征叠加作为特征空间,对Twitter用户性别进行分类。这些研究主要集中在采用不同的文本特征,如词特征,POS特征和N-gram特征去训练分类器。最近的一些监督学习的性别分类研究主要针对特定的应用场景。例如:Ciot等[8]探索识别Twitter中非英文用户性别的有效特征;Li等[9]尝试利用用户之间的交互文本推测出交互用户的性别。
然而,监督学习往往需要大量的人工标注样本,要获取大量人工标注的样本耗时耗力,这是目前性别分类在推广应用中遇到的一个主要障碍。基于半监督学习的性别分类方法研究相对较少。Ikeda等[10]提出了一种半监督学习方法针对博客文本进行性别分类,他们主要是利用一个子分类器来测量两篇博客的相关性,以捕捉未标注样本中的分类信息,有效地提升性别分类性能。Burger等[11]利用Twitter用户的tweets和个人资料(账户名、全名、个人描述)以及他们的结合作为特征,利用未标注数据和自训练方法去识别用户的性别。Wang等[12]使用协同训练的方法,将交互信息和非交互信息作为两个视图进行性别分类,取得了不错的分类性能。
我们注意到微博中用户相关的文本包括多种类型,例如用户自己原创的微博、转发微博,收到的评论和发表的评论。一般而言,某个用户主页中的这四种类型文本都有可能表现出用户的性别信息。例如表1所示的用户样例,可以从用户A收到的评论“妹妹,你真好看!”判断出用户A是一个女性。同时,用户A主页中的原创文本和转发文本中包含 “项链”,“海藻面膜”等关键词,也同样能够帮忙推测这个用户更有可能是女性。因此,用户主页中不同类型的文本能够从多方位帮忙推断用户的性别信息。

表1 用户微博不同文本的样例
本文旨在利用上面的特性提出一种基于多种不同类型文本的半监督性别分类方法。本文方法的出发点是将四种不同类型的微博文本作为四个不同的视图,采用基于深度学习的LSTM模型作为基本分类模型,并用协同训练的方法进行半监督学习。具体而言,该方法通过迭代的方式将确定性高的视图的文本及其对应的其他类型的文本自动标注并加到标注样本中,从而扩充训练样本的规模。实验结果表明本文的方法可以在少量标注样本的情况下取得较好的分类效果,并且提出的四视图协同训练方法要比双视图协同训练方法[11]的效果更好。
1 语料描述
本文的数据来自新浪微博*weibo数据集[CP/OL].[2014-07-25]http:∥weibo.com。数据包含用户的个人信息(包含用户名、性别)及用户近期发表的微博。具体而言,首先随机选择一个用户,获取其用户信息包括他的关注者、粉丝ID。然后再收集其关注者、粉丝的微博信息。最后重复以上操作直到收集工作结束。需要说明的是,在获取语料的过程中考虑到存储空间的局限性及为了提高抓取的速度,限制每个用户的微博数目不超过500条。
收集到用户的微博文本可以根据文本类型分为“原创文本”、“转发文本”、“收到评论”和“发表评论”。其中“原创文本”是该用户自己发表的微博文本;“转发文本”是该用户转发了别人的微博文本;“收到评论”是其他用户对该用户微博的评论文本;“发表评论”是指该用户对其他用户微博的评论文本。在本文的实验中,随机选取3 000个男性用户和3 000个女性用户。表2显示男女用户主页中各种类型文本条数的平均数量。每一个用户主页中某一个类型的所有条数的文本合并起来作为这个用户的该类型文本表示。
2 基于协同训练的半监督性别分类方法
本文采用协同训练方法进行用户性别分类。首先构建一种LSTM分类器作为协同训练的基分类器;然后,将用户发表的微博文本分成四种不同的类型,并作为四个不同的且相互独立的视图进行协同训练。

表2 用户各类型文本平均数量
2.1 基于LSTM 的性别分类模型
长短时记忆(Long Short-Term Memory,LSTM)神经网络是由Hochreiter 和 Schmidhuber在1997年首先提出的[13],最初LSTM的提出是为了解决在传统RNN模型训练时遇到的梯度消失和爆发的问题。LSTM使用了记忆单元(Memory cell),解决了RNN训练中后面时间节点对前面时间节点感知力下降的问题,与此同时还继承了RNN模型大部分优秀的特性。近两年对LSTM的改进结构中又引入了遗忘门,使得LSTM在更为复杂的任务上具有非常大的潜力。
如图1所示,LSTM 模型由输入门i、输出门o、遗忘门f和记忆单元c组成,三个门元素的取值在[0,1]之间。其中输入门、输出门和遗忘门是控制记忆单元的读、写和丢失操作的控制器,t时刻LSTM的更新方式如下:
(1)
(2)
(3)
其中,xt表示当前t时刻的输入,σ是激活函数Sigmoid;⊙是点乘运算;W表示系数矩阵;it控制每个内存单元加入多少新的信息,ft控制每一个内存单元需要遗忘多少信息,ot控制每一个内存单元输出多少信息;ct表示t时刻记忆单元的计算方法,ht为t时刻LSTM单元的输出信息。由图1可以看出输入门、输出门和遗忘门的输出分别连接到一个乘法单元上,从而分别控制网络的输入,输出以及记忆单元状态。

Fig.1 A long short-term memory unit图1 长短时记忆神经网络模型

Fig.2 gender classification with LSTM图2 基于LSTM的性别分类方法
根据LSTM模型,我们使用了一种利用LSTM的性别分类方法。如图2 所示,基于LSTM的性别分类模型中第一层是LSTM层,输入的是文本特征表示。根据以上LSTM的更新方式,输入传播到LSTM层后返回高纬度的向量。随后向量传播到全连接层,全连接层类似于传统多层感知机的隐藏层,接受来自上一层的输出,通过常用的激活函数加权并传播到Dropout层。Dropout已经成功地运用在前馈网络中[14],在训练过程中,通过阻止网络中特征检测器的作用,获得更少相互依赖的网络单元,进而实现更好的性能。最后,本文采用“Softmax”激活函数输出性别分类结果,激活函数如公式4所示,labelpred是最后所输出概率最大的预测标签:

(4)
其中,xt为上一层输出的文本向量,i为标签预测值,W为LSTM更新方式中的系数矩阵。
2.2 基于多文本类型的协同训练算法
本文将每一种文本类型作为一个表示视图,于是四种文本类型就可以对应四个不同的视图。有了这些视图,就可以应用协同训练算法进行半监督学习。图3详细介绍了基于多文本类型的协同训练算法流程。

输入:已标注的四种文本集合L,包括:Lorig,Ltran,Lcom,Lrep;未标注的四种文本集合U,包括:Uorig,Utran,Ucom,Urep;输出:更新后的四种文本集合:Lorig,Ltran,Lcom,Lrep;(其中orig为原创文本,tran为转发文本,com为收到评论,rep为发表评论)程序:(1)进行N次迭代,直到U=ø结束循环;(2)分别利用Lorig,Ltran,Lcom,Lrep训练得到微博分类器Corig,Ctran,Ccom,Crep;(3)利用微博分类器Corig,Ctran,Ccom,Crep分别对Uorig,Utran,Ucom,Urep中的未标注样本进行分类;(4)从Corig对Uorig的分类结果中选择置信度最高的n1个正类样本和个负类样本M1;(5)从另外三种未标注文本中分别选择相对应的样本S1,N1,T1(M1所属用户的其他三种文本);(6)从Ctran对Utran的分类结果中选择置信度最高的n2个正类样本和n2个负类样本S2;(7)从另外三种未标注文本中分别选择相对应的样本M2,N2,T2(S2所属用户的其他三种文本);(8)从Ccom对Ucom的分类结果中选择置信度最高的n3个正类样本和个负类样本N3;(9)从另外三种未标注文本中分别选择相对应的样本M3,S3,T3(N3所属用户的其他三种文本);(10)从Crep对Urep的分类结果中选择置信度最高的n4个正类样本和个负类样本T4;(11)从另外三种未标注文本中分别选择相对应的样本M4,S4,N4(T4所属用户的其他三种文本);(12)Lorig=Lorig+M1∪M2∪M3∪M4();Ltran=Ltran+S1∪S2∪S3∪S4();Lcom=Lcom+N1∪N2∪N3∪N4();Lrep=Lrep+T1∪T2∪T3∪T4();(13)Uorig=Uorig-M1∪M2∪M3∪M4();Utran=Utran-S1∪S2∪S3∪S4();Ucom=Ucom-N1∪N2∪N3∪N4();Urep=Urep-T1∪T2∪T3∪T4();
Fig.3Co-trainingalgorithmforsemi-supervisedgenderclassification
图3 基于Co-training的半监督性别分类方法算法流程
3 实验设计与分析
3.1 实验设置
从获取的新浪微博语料中选取男女用户各3 000个作为实验语料,其中每个用户包含四种类型的文本:原创文本、转发文本、收到评论和发表评论。实验中,分别采用最大熵方法(MaximumEntropy,ME)和LSTM方法作为分类方法,其中ME使用的是MALLET机器学习工具包*Mallet开源工具[CP/OL].[2002-11-06].http:∥mallet.cs.umass.edu/,在使用个工具包的时候,所有的参数都设置为它们的默认值。LSTM模型具体参数设置如表3所示。在监督学习中,采用80%的样本作为训练样本,20%的样本作为测试样本。在半监督学习中,标注样本规模为200,测试样本为1 200,其余样本作为未标注样本,在半监督学习时,每次会从训练样本中选出10%的样本作为验证集。四种文本类型均用词特征表示,其中在LSTM里用词的unigram特征并用One-Hot模型表示。
3.2 实验结果与分析
首先,表4给出了监督学习时最大熵分类器与LSTM分类器性能比较,可以看出我们所使用的LSTM分类器对四种微博文本的分类效果明显好于最大熵分类器的效果。

表3 LSTM中的参数设置
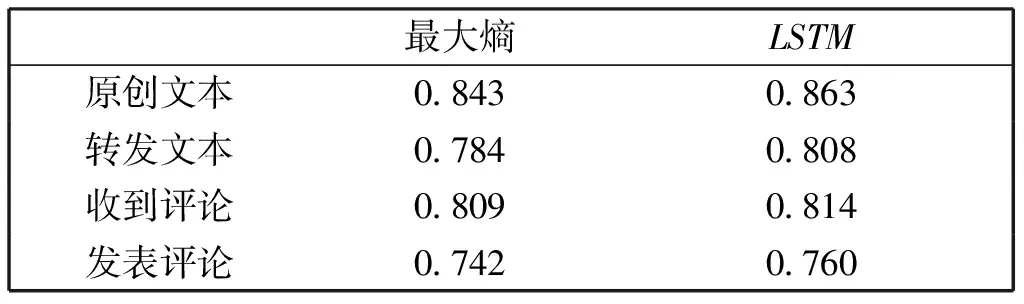
表4 LSTM与最大熵的分类效果
图4分别为使用半监督学习方法中四个视图的分类结果。实验过程中,每次迭代挑选每个视图中置信度最高的5个男性和5个女性样本。图中的Baseline方法是仅使用初始标注样本利用LSTM模型进行分类的分类结果。从图中可以看出:(1)随着未标注样本的加入,四个视图的分类器准确率总体上都在不断提高。(2)加入完所有的未标注样本后,每个视图的分类准确率都提高了约4%左右。(3)每个视图的分类器在迭代后期加入样本会有一些性能损失,但是最终的分类性能还是远远高于Baseline方法。

Fig.4 Classification results of using each textual view when varying the sizes of added unlabeled data in co-training图4 协同训练过程中加入不同数目的非标注样本后各个视图文本的分类结果
此外,我们实现了一些其他的半监督学习算法以进行比较研究,具体包括:
▶Baseline:仅使用标注样本的四个文本视图的合并训练分类模型;
▶Self-training:利用四个文本视图的合并作为一个特征空间构建分类器,每次迭代用最大熵分类器从未标注样本中挑选置信度最高的样本加入到已标注样本中。
▶Co-training(ME):使用最大熵作为基本分类模型的协同训练算法,按文本类型分为四个视图。迭代结束后利用四个文本视图的合并文本进行训练和测试。
▶Co-training(LSTM):即本文的方法,该方法使用LSTM作为分类器的协同训练算法,按文本类型分为四个视图。迭代结束后利用四个文本视图的合并文本进行训练和测试。
图5给出了不同半监督方法分类结果比较。以上方法在实现过程中使用的是所有视图文本的合并文本。从图中可以看出:(1)协同训练的方法要明显优于Baseline和Self-training。该结果主要由于协同训练方法能够充分利用多个视图之间的互补特性,能够更有效地加入非标注样本。(2)使用LSTM分类器的协同训练算法取得最佳的分类效果,比使用最大熵分类器的协同训练算法高出2.6%。

Fig.5 Comparison of classification results with different semi-supervised methods图5 不同半监督方法的分类结果比较
4 结论
本文提出了一种基于多种类型文本的半监督性别分类方法。该方法的特色在于将多种不同类型的微博文本作为不同的独立视图并进行协同学习,并使用LSTM分类器代替传统的最大熵分类器在迭代过程中挑选置信度高的样本。实验表明本文的方法能够有效利用非标注样本提升分类性能,能够帮助每个视图文本的分类器分类性能提高幅度达到4%左右。同时,本文的方法也明显优于传统的Self-training半监督学习方法及基于最大熵分类模型的协同训练方法。
微博平台中除了用户产生的几种不同类型的文本,还包含了其他与用户相关的信息,例如:关注者信息、粉丝信息、文本中的表情符号等微博信息。在下一步的工作中,我们将考虑将这些更多的用户信息加入到性别分类任务中用于提升用户性别分类性能。
[1] 文坤梅,徐帅,李瑞轩,等.微博及中文微博信息处理研究综述[J].中文信息学报,2012,26(6):27-37.DOI:10.3969/j.issn.1003-0077.2012.06.004.
[2] 张剑峰,夏云庆,姚建民.微博文本处理研究综述[J].中文信息学报,2012,26(4):21-27.DOI:10.3969/j.issn.1003-0077.2012.04.003.
[3]BurgerJD,HendersonJ,KimG,et al.DiscriminatingGenderonTwitter[C]∥ConferenceonEmpiricalMethodsinNaturalLanguageProcessing,EMNLP2011,27-31July2011,JohnMcintyreConferenceCentre,Edinburgh,Uk,AMeetingofSigdat,ASpecialInterestGroupoftheACL.2011:1301-1309.
[4]FlekovaL,CarpenterJ,GiorgiS,et al.AnalyzingBiasesinHumanPerceptionofUserAgeandGenderfromText[C]∥MeetingoftheAssociationforComputationalLinguistics,2016.
[5]NowsonS,OberlanderJ.TheIdentityofBloggers:OpennessandGenderinPersonalWeblogs[J].Proceedings of the Aaai Spring Symposia on Computational Approaches,2006:163-167.
[6]MohammadSM,YangT.TrackingSentimentinMail:HowGendersDifferonEmotionalAxes[J].Computer Science,2013.
[7]RaoD,YarowskyD,ShreevatsA,et al.ClassifyingLatentUserAttributesinTwitter[C]∥Proceedingsofthe2ndInternationalWorkshoponSearchandMiningUser-generatedContents.ACM,2010: 37-44.DOI:10.1145/1871985.1871993.
[8]CiotM,SondereggerM,RuthsD.GenderInferenceofTwitterUsersinNon-EnglishContexts[C]∥EMNLP.2013:1136-1145.
[9]LiS,WangJ,ZhouG,et al.InteractiveGenderInferencewithIntegerLinearProgramming[C]∥Proceedingsofthe24thInternationalConferenceonArtificialIntelligence.AAAIPress,2015:2341-2347.
[10]IkedaD,TakamuraH,OkumuraM.Semi-supervisedLearningforBlogClassification[C]∥NationalConferenceonArtificialIntelligence.AAAIPress,2008:1156-1161.
[11]BurgerJD,HendersonJC.AnExplorationofObservableFeaturesRelatedtoBloggerAge[C]∥AAAISpringSymposium:ComputationalApproachestoAnalyzingWeblogs,2006: 15-20.
[12]WangJ,XueY,LiS,et al.LeveragingInteractiveKnowledgeandUnlabeledDatainGenderClassificationwithCo-training[C]∥InternationalConferenceonDatabaseSystemsforAdvancedApplications.SpringerInternationalPublishing,2015:246-251.DOI:10.1007/978-3-319-22324-7-23.
[13]HochreiterS,SchmidhuberJ.LongShort-termMemory[J].Neural Computation,1997,9(8): 1735-1780.DOI:10.1162/neco.1997.9.8.1735.
[14]GravesA.GeneratingSequenceswithRecurrentNeuralNetworks[J].arXiv preprint arXiv:1308.0850,2013.DOI:10.1145/2661829.2661935.
Semi-supervised Gender Classification with Multiple Types of Text
DAI Bin,LI Shoushan*,GONG Zhengxian,ZHOU Guodong
(NaturalLanguageProcessingLabofSoochowUniversity,Suzhou215006,China)
This paper proposes a novel semi-supervised approach to gender classification by exploiting multiple types of texts in micro-blogs (e.g., original text and forward text).The approach is a semi-supervised learning approach based on co-training which aims to alleviate the dependence on large amount of labeled data.We divide the different types of text into different independent views,and we apply LSTM classifier to select unlabeled samples with highest confidence in each view,finally, we make the training model updated by adding the new obtained high-confidential samples.The experimental results show that our approach is effective for exploiting unlabeled data and outperforms other existing semi-supervised approaches to gender classification.
Gender Classification; Semi-supervised Learning; Text Classification; LSTM
10.13451/j.cnki.shanxi.univ(nat.sci.).2017.01.002
2016-11-20;
2016-12-06
国家自然科学基金重点项目(No. 61331011);国家自然科学基金(No.61375073;No. 61273320),国家青年科学基金(No. 61305088);江苏省产学研联合创新资金——前瞻性联合研究项目(No.BY2014059-16)
戴斌(1992-),男,江苏常州人,硕士研究生,研究方向为自然语言处理。
*通信作者:李寿山(LI Shoushan),E-mail:lishoushan@suda.edu.cn
TP391
A
0253-2395(2017)01-0014-07
猜你喜欢
新班主任(2022年4期)2022-04-27
科学大众(2020年23期)2021-01-18
汽车观察(2019年2期)2019-03-15
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
中国卫生(2016年5期)2016-11-12
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
