
基于主动学习的新闻读者情绪分类方法
2017-06-01 11:29陈敬刘欢欢李寿山周国栋
山西大学学报(自然科学版) 2017年1期
陈敬,刘欢欢,李寿山,周国栋
(苏州大学自然语言处理实验室,江苏 苏州 215006)
基于主动学习的新闻读者情绪分类方法
陈敬,刘欢欢,李寿山*,周国栋
(苏州大学自然语言处理实验室,江苏 苏州 215006)
读者情绪分类具体是指针对某个文本推测读者可能产生的情绪。针对该新问题,目前遇到的主要挑战是标注语料库的匮乏问题。文章提出了一种基于主动学习的读者情绪分类方法,即在已有少量标注样本的基础上,利用主动学习方法挑选优质样本,使得使用尽量少的标注代价获得较好的分类性能。考虑到新闻读者情绪分类可以同时使用新闻文本和评论文本的特殊性,提出了分类器融合分类方法,并在主动学习方面提出了结合不确定性与新闻评论信息量的挑选策略。实验表明,分类器融合方法能够获得比仅用新闻文本更好的分类性能。此外,文章提出的主动学习方法能够有效减小标注规模,在同等标注规模下,获得比随机更佳的分类性能。
读者情绪分类;主动学习;分类器融合;评论信息量
随着各种社交平台的兴起,网络上用户的生成内容越来越多,产生了大量的文本信息,如新闻、微博、博客等。面对如此庞大且富有情绪表达的文本信息,完全可以考虑通过探索它们的潜在价值为人们服务。因此近年来情绪分析受到计算语言学领域研究者们的密切关注,成为一项基本的热点研究任务[1-2]。情绪可以分为两类:作者情绪(作者在写作文本时所表达的情绪)和读者情绪(读者看完文本后所产生的情绪),本文将利用新闻文本与评论文本对新闻的读者情绪进行粗粒度(消极和积极情绪)的探讨研究。下面举例详细说明作者情绪与读者情绪。
(a) 新闻文本:今天的日本地震很可能是2011年大地震的余震。
(b) 评论文本:我希望一切都能好,真的好难过,我依旧无法忘记去年的场景。 我的岳父岳母经历了这次地震,多么痛苦啊。
从以上的新闻文本与评论文本中,我们可以看出新闻文本没有作者情绪,而新闻文本的读者情绪为消极情绪。
在已有的研究工作中,作者的情绪分类研究较多,而读者的情绪分类研究起步相对较晚,相关的研究较少。Lin等人[3]利用机器学习方法训练了一个识别读者情绪的分类器,在后期的研究[4]中,通过探索更多有效的特征,获得了相对更好的分类结果。Lin和Chen[5]将新闻的读者情绪分类看作是一个多标签分类问题,并采用回归方法得到情绪类别的排序。Bai等人[6]使用一个带有特定权值的情绪词典构建文本向量,然后通过训练SVM和NB模型分别进行读者情绪预测。Xu等人[7]提出了基于PLDA模型的多标签读者情绪预测方法,利用PLDA将特定情绪类型的词与特定话题结合,再将PLDA的结果作为分类的特征用于情绪预测。Liu等[8]利用新闻和评论两个相互独立的视图分别构建两个分类器进行协同学习(Co-training)对新闻读者的情绪进行粗粒度情绪分类研究。叶璐[9]利用主题模型实现读者情绪预测,并且在LDA的基础上采用加权方法进行改进,利用WLDA主题模型实现降维进而对读者情绪进行预测。刘欢欢[10]利用两个关联的二部图子图(新闻文本二部图和评论文本二部图)用于描述新闻文本和评论文本之间的关联,进行基于标签传播算法的粗粒度情绪分类;再者又构建了特征-标签因子图(FLFG)模型用于实现对文本特征和情绪标签间关联的共同学习,进行基于特征-标签因子图模型的细粒度情绪分类。温雯等人[11]先使用Wordvec模型学习文本初始的语义表达,在此基础上结合各个情绪类别分别构建有代表性的语义词簇并采用一定准则筛选出对类别判断有效词簇,最终使用多标签分类的方法进行新闻读者情绪分类。
与以往研究不同的是,本文首先探究了全监督学习方法下分类器融合方法对新闻读者情绪分类的效果;再者采用了基于不确定性与评论信息量相结合的主动学习算法,并结合分类器融合方法对新闻读者情绪进行粗粒度的情绪分类研究。
新闻的读者情绪分类有一个特性:既可以用新闻内容作为判断情绪的依据,也可以利用评论内容作为判断情绪的依据。例如:新闻内容的“地震”预示着读者的消极情绪;同时,评论文本中的“难过”、“痛苦”等描述也直接清晰表达了该新闻的读者情绪为消极情绪。因此,分别利用新闻文本和评论文本构建两个分类器,继而提出了基于分类器融合方法用于融合这两个分类器进一步提高读者情绪分类性能。
此外,目前主流的读者情绪分类方法是基于机器学习的全监督学习方法。标注语料库的匮乏问题是全监督学习方法最大的挑战。针对该挑战,本文探究基于主动学习的新闻情绪分类方法。具体而言,主动学习是一种通过挑选优质样本进行人工标注,从而能够在尽可能使用少的标注样本的情况下保持较好的分类效果。然而,在读者情绪分类任务中,传统的基于不确定性的主动学习方法在挑选优质样本的时候,样本的信息量未被充分利用。在读者情绪分类任务中,虽然每个样本中的新闻文本内容都比较充分,但是每个样本的评论文本信息差异较大。具体表现为,有些样本的评论较多,有些样本的评论较少甚至没有。考虑到评论文本的信息量可能对读者情绪分类带来积极影响,本文同时考虑样本不确定因素和评论文本的信息量来挑选优质样本,并结合分类器融合方法改善新闻读者情绪分类性能。实验结果表明本文提出的主动学习方法能够明显优于随机样本选择方法及传统的基于不确定性的主动学习方法。
1 主动学习方法
1.1 基于机器学习的读者情绪分类
向量空间模型是目前主流的文本表示方式,文本可以用D(document)表示,特征项(Term)用t表示,文本可以表示为D(t1,t2,t3,…,tn),其中t为特征项,对于文档D中的每一个特征项,通常会预先设置一个权值表示各特征项的重要程度,例如D(t1,w1;t2,w2;…;tn,wn),简记为:D(w1,w2,…,wn),其中wk为tk的权重,1≤k≤n。本文采用的特征为词特征,借助分词工具,可以方便地提取出这种特征。
在本文所用语料中,新闻文本与评论文本对应存在。基于全监督的学习方法,分别利用新闻文本特征和评论文本特征训练分类器,然后采用分类器融合的方法得到最终的分类结果。主动学习过程中从未标注样本中挑选不确定性样本加入已标注样本时,采取新闻文本和评论文本的融合特征来表示最大熵模型特征,而在测试时所用的特征与基于全监督的学习方法所用的特征一致,即分别利用新闻文本特征和评论文本特征训练分类器,并利用分类器融合的方法得到最后的实验结果。为了更清晰表达这些特征,表1通过一个例子来说明。

表1 新闻文本与评论文本特征以及融合特征的例子
1.2 分类器融合方法
本文利用新闻文本和对应的评论文本分别构建了两个分类器,即新闻读者的情绪分类器和评论作者的情绪分类器,来预测新闻的读者情绪。形式上将新闻读者的情绪分类器记作CN,评论作者的情绪分类器记作Cc。两个分类器最终会分别赋予测试样本(记作x)一个后验概率向量,即PN(x)和PC(x):
其中,PN(c1|x)表示分类器CN预测样本x属于类别c1的概率。PC(c1|x)、PN(c1|x)和PC(c2|x)有类似的定义。
在多个分类系统(MCS)的研究中,可以利用多种基于分类器后验概率的融合方法得出最终的分类结果。一般来说,融合方法可以分为两种[12]:一种是确定的规则,例如多数投票法、乘法规则和直接求和规则[13]等;另一种是训练的规则,例如加权求和规则[14]和元学习方式[15]等。本文主要采用加权求和规则来融合新闻读者和评论作者的情绪分类器的输出,即通过求后验概率的加权和来实现两个分类器的融合,进而得到最终的分类结果,计算方法如下:
assigny→cj
(1)
其中,参数λ用来表示分类器的权重,其值是通过对训练数据进行全局最优搜索调整所得。在本文实验中,经10倍交叉验证所得,λ的值为0.7。
1.3 基于不确定性与评论信息量相结合的主动学习方法
传统的基于不确定性的主动学习方法是根据分类结果的后验概率挑选不确定样本进行人工标注[16-17]。不同于传统的方法,本文方法利用评论信息量辅助传统的不确定性选择策略,进行未标注样本的选择,并结合上述的分类器融合方法进行分类。
1)评论信息量

(2)
2) 不确定性与评论信息量相结合的主动学习算法
样本的不确定性是通过已标注样本构建的分类器对其进行测试的分类结果进行判定[18-19]。具体通过情绪分类结果的后验概率进行计算,计算方法如下:

(3)
综合评论文本的信息量和样本的不确定性,样本选择的打分公式如下:
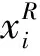
(4)
不确定性与评论信息量相结合的主动学习算法的主要步骤如下。
输入:已标注样本L,未标注样本U;
输出:新的已标注样本L;
程序:
循环N次
1) 根据未标注样本U的评论文本算出平均中心向量CR;
2) 从L中学习分类器f;
3) 使用f对U进行分类得出每个未标注样本的不确定度,即Uncertainty(xi);

5) 计算Score(xi),并将U按照值从大到小的次序进行排列;
6) 选择中前n个样本,放入L中。
2 实验结果与分析
2.1 实验设置
本文从Yahoo! Kimo新闻网站*Yahoo新闻数据集[CP/OL].[2015-05-25].http:∥tw.news.yahoo.com中搜集了多个领域(世界新闻、生活资讯等)的中文新闻语料,为了保证新闻的粗粒度情绪标签的准确性,选择显著情绪类别的投票比例在50%以上的新闻语料,同时过滤掉不含评论信息的新闻。最终,含有“积极”情绪的语料有1 497篇,含有“消极”情绪的语料有1 997篇,从“积极”情绪的语料和“消极”情绪的语料中各随机抽取1 000篇作为实验样本,其中,80%作为训练语料,20%作为测试语料,从训练语料中选取10个样本作为主动学习中的已标注样本集,其余的训练语料都作为未标注样本集。
本文所用的特征为新闻文本与评论文本的词特征,考虑到中文句子中词与词之间没有明显的分词信息,需要对其进行分词。本文采用目前使用最广泛的汉语分词开源工具*Ictclas开源工具[CP/OL].[2011-02-16].http:∥ictclas.org/[EB],即,ICTCLAS分词工具对收集的中文新闻语料进行分词。
实验中使用了基于Mallet工具包*Mallet开源工具[CP/OL].[2002-11-06].http:∥mallet.cs.umass.edu/的最大熵分类方法进行新闻读者情绪分类,同时本文采用准确率(Accuracy,Acc.)作为新闻读者情绪分类效果的衡量标准。
2.2 实验结果分析
2.2.1 全监督分类方法的结果
在基于全监督的学习方法下,研究了取训练样本的10%、20%、40%、60%和80%作为新的训练样本,以下几种全监督方法的分类效果。
▶新闻读者的情绪分类:基于已标注的新闻文本训练分类器,对未标注的新闻文本进行分类;
▶评论作者的情绪分类:基于已标注的评论文本训练分类器,对未标注的评论文本进行分类;
▶两种文本特征融合的情绪分类:将新闻文本和评论文本的特征进行融合训练分类器,对未标注的新闻文本进行分类;
▶两种文本分类加权融合的情绪分类(加权加法规则):将新闻读者和评论作者的情绪分类得到的后验概率采用加权求和的规则。通过训练样本的十倍交叉实验结果选取最佳权重(λ值)为0.7。
表2给出了上述四种分类方法的分类性能,从表中可以看出:
(1)基于新闻文本的情绪分类方法性能明显优于基于评论文本的分类方法,这主要是因为新闻文本所包含的文本内容往往比评论文本多。有些样本的评论文本比较少,很难有足够分类能力。
(2)简单将两种文本的特征进行叠加并不能提高分类性能,获得分类效果甚至比单用新闻文本的方法差。然而,采用本文的分类器融合方法能够稳定获得比新闻文本分类方法更好的分类性能。

表2 4种全监督方法下的实验结果
2.2.2 主动学习分类方法的结果
本实验比较了以下三种样本选择方式用于基于主动学习的读者情绪分类:
▶随机方法(RAND):从未标注样本集中随机选择样本进行人工标注后加入到已标注样本集中,再基于已标注样本集训练分类器,对未标注的新闻文本进行分类;
▶不确定性(UNCE):基于不确定性对未标注样本进行选择,人工标注后加入到已标注样本集中,再基于已标注样本集训练分类器,对未标注的新闻文本进行分类;
▶基于不确定性与评论信息量相结合(MULTI):本文提出的主动学习方法,具体方法见在1.3节。
从训练语料中选取10篇语料(积极和消极样本各5篇)作为初始已标注样本,采用以上三种不同样本选择方式的主动学习方法对新闻读者情绪进行分类。实验设定每次选择最不确定的10个未标注样本进行人工标注后加入到已标注样本集中。

Fig.1 Comparison of experimental results based on the method of active learning图1 基于主动学习方法的实验结果的比较
图1给出了基于三种样本挑选策略的分类效果,从图中我们可以看出:
(1)基于不确定性与基于不确定性与评论信息量相结合的主动学习方法都能够有效地减少标注规模,在同样的标注规模下能够获得比随机挑选样本方法更优的性能。例如,基于不确定性与评论信息量相结合的主动学习方法在加入50样本时就能够达到了基于随机的主动学习方法加入200样本数的分类效果。
(2)基于不确定性与评论信息量相结合的主动学习方法在样本比较少的情况下(少于200)能够优于传统的基于不确定性的主动学习方法。当标注样本较多的时候,这两种主动学习方法的性能表现接近。
3 本文结论和下一步工作介绍
本文针对新闻读者情绪分类问题提出了一种基于分类器融合的全监督学习方法,用于组合分别由新闻文本和评论文本训练的两个分类器。在此基础上,本文提出了一种基于不确定性与评论信息量相结合选择策略的主动学习方法,用于减轻监督学习对于标注样本的依赖。实验结果表明,分类器融合方法能够获得比仅用新闻文本分类器更佳的分类性能。此外,基于不确定性与评论信息量相结合选择策略的主动学习方法比随机样本选择策略及传统的基于不确定性的主动学习方法获得更好的分类性能,在少量的已标注样本的情况下就能获得较高的分类性能。
本文的研究中仅仅使用词特征,在下一步研究中,我们将考察更复杂的语言特征,例如句法、语义特征,进一步提升读者情绪分类性能。此外,我们将尝试结合主动学习和半监督学习方法,进一步减轻分类方法对标注样本的依赖。
[1]ZhengC,ShenL,DaiN.ChineseMicroblogEmotionClassificationBasedonClassSequentialRules[J].ComputerEngineering,2016,42(2):184-189.DOI:10.3969/j.issn.1000-3428.2016.02.033.
[2]ChangYC,ChuCH,ChenCC,et al.LinguisticTemplateExtractionforRecognizingReader-Emotion[J].中文计算语言学期刊,2016,21(1):29-50.DOI:10.1111/j.1541-0420.2007.00820.x.
[3]LinHY,YangC,ChenHH.WhatEmotionsdoNewsArticlesTriggerinTheirReaders[C]∥ProceedingsoftheInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval,2007:733-734.DOI:10.1145/1277741.1277882.
[4]LinHY,YangC,ChenHH.EmotionClassificationofOnlineNewsArticlesfromtheReader’sPerspective[C]∥ProceedingoftheInternationalConferenceonWebIntelligenceandIntelligentAgentTechnology,2008:220-226.DOI:10.1109/WIIAT.2008.197.
[5]LinHY,ChenHH.RankingReaderEmotionsUsingPairwiseLossMinimizationandEmotionalDistributionRegression[C]∥ProceedingsoftheConferenceonEmpiricalMethodsinNaturalLanguageProcessing,2008:136-144.DOI:10.3115/1613715.1613735.
[6]BaiS,NingY,YuanS,et al.PredictingReader’sEmotiononChineseWebNewsArticles[C]∥InternationalConferenceonPervasiveComputingandtheNetworkedWorld,2012:16-27.DOI:10.1007/978-3-642-37015-1-2.
[7]XuR,ZouC,XuJ.Reader’sEmotionPredictionBasedonPartitionedLatentDirichletAllocationModel[C]∥ProceedingsofInternationalConferenceonInternetComputingandBigData,2013:457-464.
[8]LiuH,LiS,ZhouG,etal.JointModelingofNewsReader’sandCommentWriter’sEmotions[C]∥MeetingoftheAssociationforComputationalLinguistics,2013:511-515.
[9] 叶璐.新闻文本的读者情绪自动预测方法研究[D].哈尔滨:哈尔滨工业大学研究生院,2012.
[10] 刘欢欢.面向新闻的读者情绪自动分析方法研究[D].苏州:苏州大学研究生院,2015.
[11] 温雯,吴彪,蔡瑞初,等.基于多类别语义词簇的新闻读者情绪分类[J].计算机应用,2016,36(8):2076-2081.DOI:10.11772/j.issn.1001-9081.2016.08.2076.
[12]DuinRPW.TheCombiningClassifier:ToTrainOrNotToTrain[C]∥Proceedingsof16thInternationalConferenceonPatternRecognition(ICPR-02),2002:765-770.
[13]KittlerJ,HatefM,DuinRPW,et al.OnCombiningClassifiers[J].IEEETransactionsonPatternAnalysis&MachineIntelligence,1998,20(3):226-239.DOI:10.1109/34.667881.
[14]FumeraG,RoliF.ATheoreticalandExperimentalAnalysisofLinearCombinersforMultipleClassifierSystems[J].IEEETransactionsonPatternAnalysis&MachineIntelligence,2005,27(6):942-956.DOI:10.1109/TPAMI.2005.109.
[15]VilaltaR,DrissiY.APerspectiveViewandSurveyofMeta-learning[J].ArtificialIntelligenceReview,2002,18(2):77-95.DOI:10.1023/A:1019956318069.
[16] 居胜峰,王中卿,李寿山,等.情感分类中不同主动学习策略比较研究[C]∥中国计算语言学研究前沿进展,2011:506-511.
[17] 刘康,钱旭,王自强.主动学习算法综述[J].计算机工程与应用,2013,48(34):1-4.DOI:10.3778/j.issn.1002-8331.1205-0149.
[18] 居胜峰.基于主动学习的情感分类方法研究[D].苏州:苏州大学研究生院,2013.
[19]LiS,XueY,WangZ,ZhouG.ActiveLearningforCross-domainSentimentClassification[C]∥Proceedingofthe22ndInternationalJointConferenceonArtificialIntelligence,2013:2127-2133.
Active Learning on News Reader Emotion Classification
CHEN Jing,LIU Huanhuan,LI Shoushan*,ZHOU Guodong
(NaturalLanguageProcessingLabofSoochowUniversity,Suzhou215006,China)
Reader emotion classification aims to predict the mood that the reader may have speculated according to some text. For this new issue, the main challenge is the lack of the annotated corpus. In order to alleviate this problem, this paper proposes an active learning approach to reader emotion classification, which is based on a few initial annotated samples, using active learning method to select high-quality sample, making use of the annotating cost as little as possible to get a good classification performance. Considering the specificity that news reader emotion classification, we make use of news text and the comment text and employ classifier combination method to combine them. Moreover, selection strategy combined with uncertainty and news comment information in active learning is proposed.The experiments demonstrate that the method of classifier combination performs better than the method that only using news text. In addition, the proposed active learning method can effectively reduce the dimension scale, and obtain better classification performance than random selection.
reader emotion classification; active learning; classifier combination; comment information
10.13451/j.cnki.shanxi.univ(nat.sci.).2017.01.004
2016-11-20;
2016-12-16
国家自然科学基金重点项目(61331011);国家自然科学基金(61375073;61273320)
陈敬(1992-),男,江苏扬州人,硕士研究生。
TP391
A
0253-2395(2017)01-0021-06
*通信作者:李寿山(LI Shoushan),shoushan.Li@gmail.com
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
海外华文教育(2016年1期)2017-01-20
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
