
融合协作表达和时空金字塔的人体行为识别
2017-06-28 16:22潘今一
浙江工业大学学报 2017年3期
潘今一,申 瑜,李 杰
(浙江工业大学 信息工程学院,浙江 杭州 310023)
融合协作表达和时空金字塔的人体行为识别
潘今一,申 瑜,李 杰
(浙江工业大学 信息工程学院,浙江 杭州 310023)
为了能够充分正确地利用视频数据从而保证直方图向量对行为的高描述性,提出了一种新颖、有效的人体行为识别算法.所提算法融合了协作表达方法和时空金字塔表示,并且采用引入局部限制的方式保持了局部特征与其相邻字典向量之间的相似性.协作表达的引入使得算法可以得到一个闭式,避免了在稀疏表示分类算法中因迭代造成的高时间复杂度问题,同时为了增强直方图向量的行为鉴别能力,算法巧妙地借助时空金字塔描述视频中特征的结构化分布.在KTH和Hollywood2人体动作数据集上的识别率分别可达96%和59.1%,明显高于其他对比算法.
行为识别;局部时空特征;协作表达;时空金字塔
行为识别的主要任务是利用计算机对包含人体的图像序列进行分析,从而识别人体行为.基于视频信息的人体行为识别是计算机视觉、模式识别以及人工智能领域中一个重要的研究课题.通常情况下,将人体行为识别算法分为采用全局时空特征的算法和采用局部时空特征的算法,全局时空特征不能够描述因为人体关节变化而导致的行为类内差异[1],而局部时空特征描述视频中兴趣点邻域内的时空信息,Laptev等[2]证明了时空兴趣点方法在简单人体行为识别中的可靠性.Dollar等[3]基于可分离线性滤波器检测时空兴趣点后对兴趣点进行Cuboids特征的描述,并基于PCA算法对描述子进行降维,最后采用1-NN法识别人体行为.
近年来,视觉词袋模型[4](BOW)在人体行为识别的研究中已经得到了广泛关注和显著发展.它的主要思想是离线训练视觉字典,按照某种编码规则将视频中每个局部特征映射到视觉字典中某个或某几个向量上,使用编码矢量的聚集特性描述视频.在局部特征编码阶段,早期BOW模型采用的硬分配策略会产生较大的量化误差.Gemert等[5]使用K近邻匹配代替最近邻分配,和硬分配策略相比,此方法能够大幅降低量化误差,然而值的大小将对量化结果产生显著的影响.Yang等[6-7]将稀疏编码运用到BOW模型中,在满足一定稀疏度的情况下,该方法可以自适应地从字典中寻找到一组可以较好地表征待量化特征的视觉字典向量.稀疏编码方法虽然提高了对局部特征的表示精度,但是需要反复迭代才能求得过完备字典,计算过程复杂、费时.在特征汇总阶段,针对传统BOW模型没有考虑局部特征之间空间关系的问题,戴光麟等[8]借鉴了空间金字塔匹配模型.在空间金字塔表示框架下,Liu[9]以子区域内编码矢量的平均值作为区域的矢量表示;Yang等[6]提出矢量各维最大汇总算法来融合局部特征的空间信息.但是,平均统计值和最大统计值都不能够充分体现编码矢量之间的空间关系,也未考虑数据的局部结构.针对上述问题,提出一种融合协作表达和时空金字塔的人体行为识别算法,协作表达方法的引入较大程度地降低了算法的计算复杂度,同时为了增强视频直方图向量的行为鉴别能力,算法巧妙地借助时空金字塔描述视频中特征的结构化分布.
1 局部时空特征的协作表达
在视频中,使用可分离线性滤波器[3]检测时空兴趣点,每一个时空兴趣点都对应着一个包含复杂动作的3维局部区域块,使用3D-SIFT[10]描述该区域的时空信息,将3D-SIFT特征称为局部时空特征(简称局部特征).
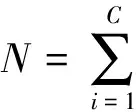
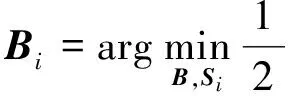
(1)
式中λ为稀疏正则项,使用Si的1范数即‖Si‖l1约束编码系数的稀疏性.B∈Rd×k是由第i类行为中的k个局部特征组成的字典.
在视频特征编码应用中,稀疏编码的目的就是将输入的局部特征以字典中视觉向量的加权线性组合的方式来表示.视频中能够描述行为的局部特征数以万计,并且特征维度高,这就加剧了稀疏表示分类算法中因迭代造成的高时间复杂度问题.Zhang等[11]指出真正起作用的不是L1范数稀疏项,而是协作表达,其表达式为
(2)

(3)
在原始的协作表达算法中没有考虑局部特征之间的相似性,即局部特征有可能由与其相距较远的基向量重构,在识别阶段有可能造成识别错误,导致算法不稳定,优化协作表达框架为
(4)

(5)


(6)
将视频中的第t帧坐标为(x,y)的时空兴趣点p记为p=(vp,ep),其中vp=[x,y,t]T.
2 融合协作表达和时空金字塔的人体行为识别
2.1 人体行为视频表示
视频中的局部特征经过编码操作后,为了获得视频内容的紧致表示需要计算局部特征的聚集特征.近年来,在大量的相关研究工作中,空间聚类算法表现出了更优秀的描述性能,其中最有代表性的是空间金字塔模型.Choi等[12]将空间金字塔的匹配模型延伸到视频的范畴,提出了时空金字塔的表示框架.该框架构造一个多层的时空金字塔,记金字塔层次为l=1,2,…,L,总层数为L.在视频的第l层,分别在水平方向、垂直方向和时间维度上把视频分成2l-1份,第l层上的视频最终被分割为2l-1×2l-1×2l-1=8l-1个子区域.
为了增强人体行为鉴别能力,算法对每一个子区域内局部特征编码的结构化分布进行描述,以生成子区域的直方图表示向量.假设第i个子区域的中心坐标为oi,定义子区域中任意一个时空兴趣点p=(vp,ep)对该网格的隶属度为基于它们之间距离的截断高斯函数,即
(7)

hi=∑pdi(p)ep
(8)
图1(b)即为一个层的时空金字塔模型,它将整个视频按照三个维度分割为81-1+82-1+83-1=73个时空子区域.最后,连结金字塔子区域的特征向量,即[h1,h2,…,h73],并归一化后形成最终的视频直方图表示向量.
2.2 融合协作表达和时空金字塔的人体行为识别
将基于协作表达和时空金字塔的视频表示,应用于人体行为识别,其流程图如图1所示.将视频图像按时间轴组成一个3维时空体,首先提取其中时空兴趣点的3维局部特征,利用协作表达方法对局部特征进行编码;然后借鉴时空金字塔模型,计算视频中时空兴趣点编码的结构化分布,生成整个视频的表示向量;最后,使用训练视频的表示和标签来训练SVM分类器[13],用这样的分类器对测试视频进行人体行为分类.

图1 算法流程图Fig.1 Framework of the proposed method
3 实验结果与分析
3.1 人体动作数据集
为了验证算法的有效性和正确性,在KTH和Hollywood2两个常用的人体动作数据集上进行实验验证.KTH数据集是Schuldt等[14]在2004年提出的,它包括6种人体动作:walking,jogging,running、boxing,handwaving和handclapping,每个动作由25个主体在四种互不相同的场景中完成,总共599个视频.Hollywood2数据集包括从69个不同的好莱坞电影搜集的12种人体动作:answeringthephone,drivingcar,eating,fighting,gettingoutofcar,handshaking,hugging,kissing,running,sittingdown,sittingup和standingup[15].图2,3分别给出了这2个人体行为数据集的部分样本.

图2 KTH人体行为数据集的部分样本Fig.2 Samples from KTH

图3 Hollywood2人体行为数据集的部分样本Fig.3 Samples from Hollywood2
3.2 实验结果与分析
在KTH数据集上进行实验时,训练样本是从KTH中随机选取的16个人的行为视频,并将剩余9个人的视频则作为测试样本.经过多次实验比对,设置参数σ=2,τ=2.5.实验中,从所有训练样本的局部特征中随机选择100 000个特征进行字典学习,为了保证字典学习的精度,对随机选择的局部特征重复进行10次字典学习,选择重构误差最小的字典作为编码字典.在生成基于时空金字塔的视频表示过程中,构造一个3层的金字塔.在固定其它参数的情况下,图4展示了编码字典长度对识别率的影响.随着字典长度的增加,算法性能一直呈上升趋势,当字典长度达到2 048后,此时再增加字典长度,人体行为识别准确率基本不再提升.由此在接下来的实验中我们设置每个类别的字典长度为2 048.

图4 KTH数据集上不同字典长度的实验结果Fig.4 Experiment results of choosing different dictionary lengths on the KTH dataset
表1以混淆矩阵的形式给出了在KTH数据集上的识别率,其中jog行为的识别率相对较低,jog行为被误判为run和walk的原因是这3种行为都是人体移动,只是肢体动作速度和幅度不同稍有不同.而clap行为被误判为wave,主要原因是两种行为存在相似的手部动作,只不过wave行为的动作幅度比clap行为大一点.在KTH数据集,该算法的平均分类准确率为96%.
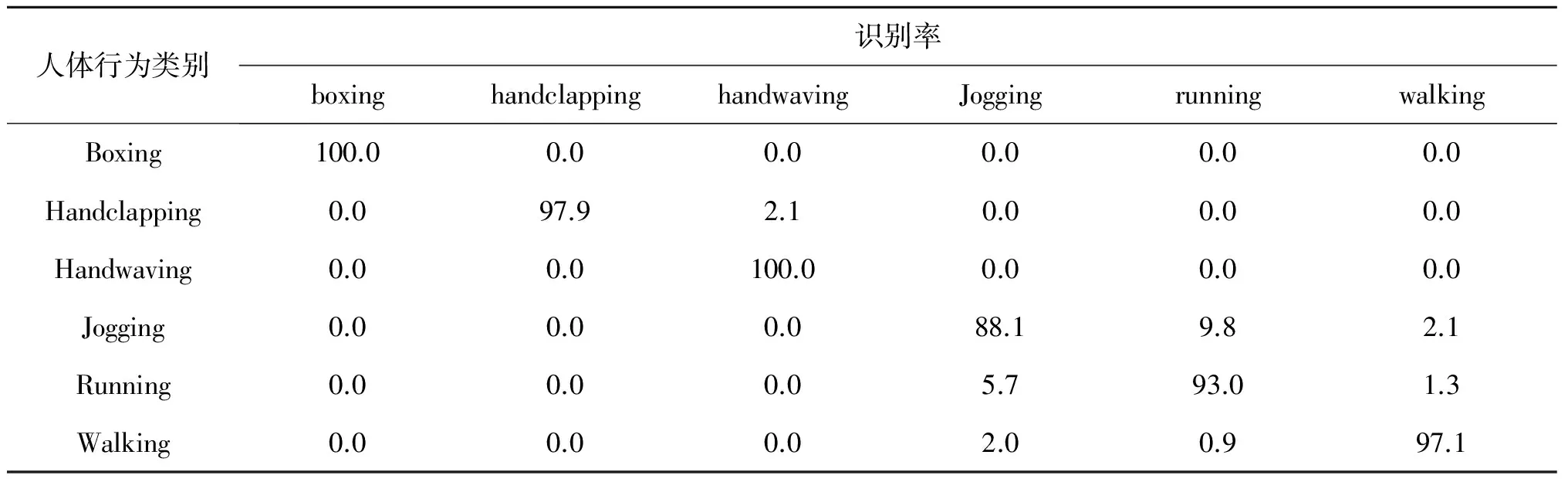
表1 KTH数据集上的混淆矩阵
为了分析算法的不同组成部分对人体行为识别率的影响,设计了以下3个对照方法:
1) 将3D-SIFT时空特征作为兴趣点的描述子,基于时空金字塔表示视频.
2) 使用编码作为时空兴趣点的描述子,基于常规的词袋模型表示视频.
3) 使用编码作为时空兴趣点的描述子,基于时空金字塔表示视频.
把Hollywood2数据集依据每个动作随机分成两份验证分类效果(训练集共有823个视频,测试集共有884个视频).表2分别在KTH和Hollywood2数据集上对比了推荐的算法与其他文献识别方法的识别率,其中文献[2-3]分别使用HOG/HOF联合特征和Cuboids特征作为时空兴趣点的描述子.由于KTH是仅有4个不同的场景的单人动作,而Hollywood2数据集包含多人在复杂场景中的多种动作类别,因此人体行为识别率明显低于KTH数据集.Wang等[16-17]做了评估实验并提出了采用运动边界描述子的新方法,在两个数据集上获得的最好识别结果分别为94.2%和58.2%,而表中使用编码作为时空兴趣点的描述子,利用时空金字塔表示视频识别效果提升了1.8%和0.9%.并且由于Wang等[17]使用的是密集轨迹和运动边界描述符,运算复杂度高,需要消耗的时间也相对较长.
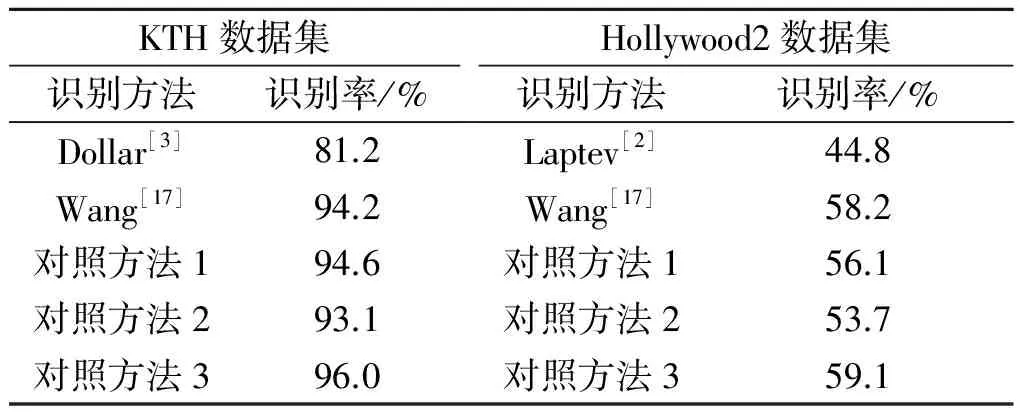
表2 行为识别结果
4 结 论
基于协作表达方法和时空金字塔模型,提出了一种新的人体行为识别算法.算法通过采用协作表达方法编码局部时空特征,较好地降低了计算复杂度,并且合理地运用了特征的局部相似性,降低了与局部特征相距较远的字典向量在重构局部特征时的贡献,由此得到的编码系数更有利于人体行为识别.最后,结合时空金字塔模型来描述视频中局部特征的结构化分布,增强了视频直方图向量的行为鉴别能力.在KTH和Hollywood2人体行为数据集中进行了实验,当前一些表现突出的算法相比,算法性能有了显著的提升.但值得指出的是,算法对实际生活中行为的识别率有待提高,如何提高局部特征编码的质量是今后的一个研究内容.
[1] 王泰青,王生进.基于中层时空特征的人体行为识别[J].中国图象图形学报,2015,20(4):520-526.
[2] LAPTEV I, MARSZALEK M, SCHMID C, et al. Learning realistic human actions from movies[C]//Proceedings of the 26thIEEE Conference on Computer Vision and Pattern Recognition.Anchoorage:IEEE Computer Society,2008:1-8.
[3] DOLLAR P, RABAUD V, COTTRELL G, et al. Behavior recognition via sparse spatio-temporal features[C]//Proceedings of the 2ndJoint IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance.Beijing:IEEE Computer Society,2005:65-72.
[4] SIVIC J, ZISSERMAN A. Video google: a text retrieval approach to object matching in videos[C]// Proceedings of IEEE International Conference on Computer Vision. Nice:IEEE,2003:1470-1477.
[5] GEMERT J, GEUSEBROEK J, VEENMAN C, et al. Kernel codebooks for scene categorization[C]// Proceedings of Europe Conference on Computer Vision.Marseille:Springer,2008:696-709.
[6] YANG J, YU K, GONG Y, et al. Linear spatial pyramid matching using sparse coding for image classification[C]// Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, CVPR.Florida:IEEE,2009:1794-1801.
[7] WANG J, YANG J, YU K, et al. Locality-constrained linear coding for image classification[C]// Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, CVPR.San Francisco:IEEE,2010:3360-3367.
[8] 戴光麟,许明敏,董天阳.基于空间金字塔视觉词袋模型的交通视频车型分类方法研究[J].浙江工业大学学报,2016,44(3):247-253.
[9] LIU L Q, WANG L, LIU X W. In defense of soft-assignment coding[C]// Proceedings of the 13thInternational Conference on Computer Vision.Barcelona:IEEE Computer Society,2011:2486-2493.
[10] SCOVANNER P, ALI S, SHAH M. A 3-dimensional sift descriptor and its application to action recognition[C]// Proceedings of the 15th Conference on Multimedia.Augsburg:ACM,2007:357-360.
[11] ZHANG L, YANG M, FENG X. Sparse representation or collaborative representation: which helps face recognition?[C]// Proceedings of IEEE International Conference on Computer Vision. Barcelona: IEEE,2011:471-478.
[12] CHOI J, JEON W J, LEE S C. Spatio-temporal pyramid matching for sports videos[C]// Proceedings of the 1stACM Sigmm International Conference on Multimedia Information Retrieval.Vancouver:ACM,2008:291-297.
[13] 陈敏智,汤一平.基于支持向量机的针对ATM机的异常行为识别[J].浙江工业大学学报,2010,38(5):546-551.
[14] SCHULDT C, LAPTEV I, CAPUTO B. Recognizing human actions: a local SVM approach[C]// Proceedings of International Conference on Pattern Recognition.Cambridge: IEEE,2004:32-36.
[15] MARSZALEK, M, LAPTEV, I, SCHMID, C. Actions in context[C]// Proceedings of Computer Vision and Pattern Recognition, CVPR.Dresden:IEEE,2009:2929-2936.
[16] WANG H, ULLAH M M, KLSER A, et al. Evaluation of local spatio-temporal features for action recognition.[C]//British Machine Vision Conference.London:BMVC,2009.
[17] WANG H, KLSER A, SCHMID C, et al. Dense trajectories and motion boundary descriptors for action recognition[J]. International journal of computer vision,2013,103(1):60-79.
(责任编辑:刘 岩)
Combining collaborative representation and space-time pyramid for human behavior recognition
PAN Jinyi, SHEN Yu, LI Jie
(College of Information Engineering, Zhejiang University of Technology, Hangzhou 310023, China)
Human behavior description is the key problem in behavior recognition. In order to make full use of video data and ensure the highly descriptive histogram vector of behavior, a novel and effective algorithm for human behavior recognition is proposed. The proposed algorithm combining collaborative representation with space-time pyramid, which preserves the similarity between the test sample and its neighboring training samples by employing the locality. The introduction of cooperative expression allows the algorithm to obtain a closed-form solution. Therefore, the algorithm not only avoids the dilemma of expensive computations in the sparse representation, but also improves the discriminative power of interest points by encoding the structured distribution of features in the video. The recognition rates on the KTH and Hollywood2 human action datasets reach 96% and 59.1%, which is better than the state-of-the-art methods.
behavior recognition; local space-time features; collaborative representation; space-time pyramid
2016-10-19
潘今一(1959—),男,浙江湖州人,教授,研究方向为模式识别与图形图像处理技术,E-mail:jypan@zjut.edu.cn.
TP391.4
A
1006-4303(2017)03-0300-05
猜你喜欢
环球时报(2022-09-19)2022-09-19
四川党的建设(2022年8期)2022-04-28
小学生学习指导(低年级)(2020年11期)2020-12-14
考试与评价·七年级版(2020年4期)2020-10-23
小学阅读指南·低年级版(2019年11期)2019-07-01
作文大王·低年级(2018年10期)2018-12-06
小天使·一年级语数英综合(2017年11期)2017-12-05
小学教学研究·新小读者(2017年9期)2017-10-25
读者(2016年14期)2016-06-29
小猕猴智力画刊(2016年5期)2016-05-14
