
冷水机组故障诊断中重要特征的选择
2017-07-05 13:46马露露陆慧娟
中国计量大学学报 2017年2期
马露露,严 珂,陆慧娟
(中国计量大学 信息工程学院,浙江 杭州 310018)
冷水机组故障诊断中重要特征的选择
马露露,严 珂,陆慧娟
(中国计量大学 信息工程学院,浙江 杭州 310018)
在数据驱动的集中式空调系统故障诊断过程中,特征选择是一个必要的预处理.选取重要的特征作为分类依据,无论是从经济的角度还是对故障的有效判断上,都具有非常重要的意义.现采用不同的特征选择方法对一组冷水机组故障数据进行特征选取,并利用支持向量机完成分类,最后通过对比分析获取冷水机组故障诊断中最重要的特征子集.
特征选择;遗传算法;ReliefF算法;支持向量机
为实现空调系统更高效节能的运行并营造出健康舒适的建筑环境,大量学者对空调设备故障诊断进行了研究.考虑到故障原因的种类繁多,如果由人工来排查空调运行过程中可能发生的问题将消耗大量的时间和人力资源.在发达国家,政府要求一些大型工厂的集中式空调系统每三个月到半年就要进行一次例行检查以确保空调运作正常[1].每次空调保养的费用对这些工厂而言也是不小的负担.另一方面,信息网络的飞速发展为自动空调查错诊断系统提供了可行性基础.即通过在一些关键位置,如冷凝器进出口、蒸发器进出口、排气口等地方安装一些传感器,再通过因特网传输数据到电脑中.通过这些数据,科学家们可以找到其中的一些规律,从而总结出当前空调的运行状态.如果有故障发生,系统会自动发出警告,而更先进的系统可以自动诊断出故障类型.此类自动检测和诊断系统称为数据驱动的空调自动查错与诊断系统.
目前数据驱动的空调自动差错与纠错研究主要针对集中式空调中最重要的两个子系统:冷水机组(chiller)和空气处理机组(Air Handling Unit, AHU).这两个子系统是集中式空调中最重要的组成部分,同时也是消耗最大,最容易出错的两个子系统.Zhou[2]等人在2011年利用模糊逻辑(fuzzy logic)和人工神经网络(Artificial Neural Network, ANN)对冷水机组进行自动的差错与纠错.他们的方法在一组美国采暖、制冷与空调工程师学会(American Society of Heating, Refrigerating and Air-Conditioning Engineers, ASHRAE,项目代码1043-RP)提供的真实数据集上进行实验,取得了较好的效果[2].Han等人在2010年使用了支持向量机与遗传算法(Genetic Algorithm, GA)相结合的数据驱动算法来查找冷水机组中的错误[3].其平均实验准确率可以达到95%以上.在最近的五年时间里,更多的数据驱动方法被提出,其中包括Li等人提出的模式匹配(pattern matching)方法[4]、Wang等人提出的实时诊断方法[5]、Bonvini等人基于卡尔曼过滤器的诊断方法[6].基于Han等人的工作,我们在2014年提出了利用ARX(auto-regressive model with exogenous variables)模型和支持向量机相结合的算法来对冷水机组进行错误诊断[7],即利用ASHRAE项目1043-RP数据中的6种特征对冷水机组中可能出现的错误进行诊断,得到了较好的实验效果.在2016年,我们又提出了单类支持向量机和卡尔曼过滤器相结合的冷水机组故障检测算法[8].
特征选择是数据驱动的空调自动查错与诊断系统中的重要步骤.合理的特征选择方法能够找到对于空调系统查错与诊断过程中最重要的特征子集,从而以最少的数据量来有效地识别空调系统中可能出现的问题.从经济角度来说,较少的特征数能够减少所需安装的传感器个数,从而降低所需预算.从诊断效果上看,选取重要的特征数能够以最少的时间和较小的空间代价得到最高的诊断效果,提高诊断效率.
从目前已有的冷水机组诊断工作中看,分类精度最高的算法是支持向量机,故在本文中利用支持向量机测试选得特征子集的分类性能.本文利用ASHRAE项目1043-RP提供的真实数据集进行实验,对集中式空调系统中的冷水机组展开研究.利用序列前向选择、ReliefF、遗传算法、互信息最大化遗传算法,四种不同的特征选择方法找到最有代表性的特征子集,并利用支持向量机对多种故障模式特征进行训练分类.最后通过比较找出最适合冷水机组故障诊断的特征子集,为后续针对冷水机组的诊断工作做好预处理.
1 特征选择方法概述
已知的特征选择方法主要分为两大类:Filter方法和Wrapper方法[9].其中Filter方法不依赖于分类器,而Wrapper方法需要考虑特定的分类器.在已知分类器的前提下,Wrapper方法,例如序列前向选择(sequential forward selection, SFS)往往能够取得较好的分类结果[10].而ReliefF是一种常用的Filter方法.在过去的工作中,我们往往利用ReliefF进行特征选择,取得了令人满意的实验结果[7].在已有的工作中,遗传算法和互信息最大化(mutual information maximization,MIM)算法在不同数据集上普遍反映出较好的实验结果[11-14].
序列前向选择方法是一种被广泛使用的自下而上的Wrapper特征选择方法.特征子集X从空集开始,每次根据分类器的评分指标选择一个特征x加入特征子集Y,使得最终的分类精度最优.简单说就是,每次都选择一个使得分类精度达到最优的特征加入,故Wrapper是一种简单的贪心算法.序列前向选择的缺点是必须提前选定比较适合的分类器(比如本文中的支持向量机),而“前向”指代的含义是这个算法只能加入特征而不能去除特征.
Relief算法最早由Kir提出,最初局限于二类分类问题,1994年Kononeko对其进行了扩展,得到了ReliefF作算法,可以处理多类别问题[15-16]和目标属性为连续值的回归问题,以及数据缺失的问题.ReliefF属于一种特征权重算法,其基本思想是在数据集中赋予所有和类别相关性高的特征,选择出较高的权重[17].
ReliefF算法具体流程如下:
输入:训练数据集为D,特征总数为n,抽样次数为m,特征的权重阀值δ,最近邻样本个数k;
输出:特征的特征权重W.
1)将特征权值初始化为0,(W(A),A=1,…,n)为空集;
2)fori=1:mdo;
3)在训练数据集D中随机选择一个样本记为Ri;
4)从Ri的同类样本集中找到Ri的k个近邻样本Hj(j=1,2,…,k);
5)从每一个不同的类别C≠class(Ri)中,找出k个最近邻Mj(C);
6)forA=1:n,对每个特征用步骤2)更新权值
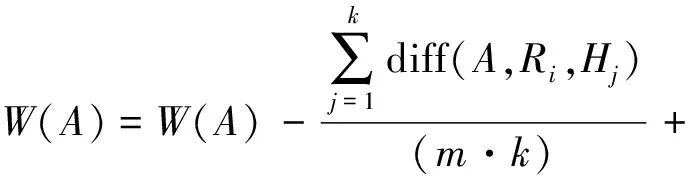
(1)
7)end转步骤6);
8)end转步骤2).
其中在(1)式中,diff(A,Ri,Hj)是样本Ri和Hj关于特征A距离,P(C)代表C类目标样本数占样本总数的比例,即
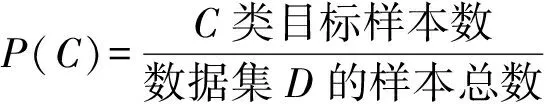
(2)
经过上述流程,最终求得特征权值向量W,权值越大表示该特征对样本的区分能力越强,这样通过阀值就可以选择新的特征子集,从而达到降维的目的.
遗传算法(GA)是模拟达尔文的遗传选择和自然淘汰的生物进化过程的计算模型.遗传算法的组成部分包括编码机制、适应度函数、遗传算子(选择、交叉和变异)和控制参数.利用遗传算法求解问题时,问题的可能解都将被编码成染色体,即个体.若干个个体组成初始解群,通过适应度函数计算后,满足终止条件的个体可以被输出,通过适应度函数计算后,满足终止条件的个体可以被输出,算法结束.否则,个体经过交叉、变异再组合生成下一代新种群,新种群继承了上一代的优良性能,优于上一代,这样就可以逐步朝着更优解的方向进化.遗传算法步骤如下:
1)随机产生初始种群D;
2)计算种群中每个个体的适应度(分类错误率);
3)对种群的个体基因进行选择、交叉和变异操作;
4)满足终止条件结束,否则返回步骤2),输出最终个体即分类错误率最低的个体.
其中,交叉率pc和变异率pm的公式如下:
(3)
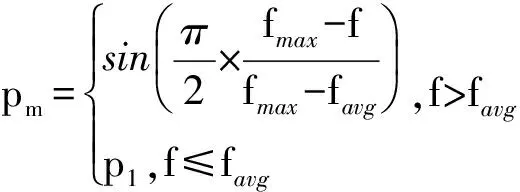
(4)
f′是交叉染色体的适应度最大值,f是变异染色体的适应度.fmax是最大适应度,favg是平均适应度,p0和p1设置为p0=0.1,p1=0.01.
对于遗传算法的具体步骤分析读者可以参见文献[12,14].
互信息最大化遗传算法(MIM-GA)是一种基于信息论模型的特征选择法.互信息最大化的基本思想是选择后的特征集合应当尽可能多地提高关于类别的信息,互信息是运用特征与类别的概率分布及它们之间的条件概率分布来计算特征的选择强度[11,13].互信息最大化遗传算法在遗传算法的基础上加入了互信息最大化的特征选择方法.在我们过去的工作[11]中,在不同的数据集当中可以取的广泛的有价值的特征选择结果.
2 实 验
实验中所用的计算机配置环境为:处理器为Intel(R)Core(TM)i3-4150 CPU @3.50 GHZ,内存为4 GB,操作系统为Windows 7.计算软件是MATLAB 7.11.0(R2010b);SVM分类算法调用的是WEKA(Waikato Environment for Knowledge Analysis)中的LIBSVM工具箱.LIBSVM使用RBF核函数,核函数参数为gamma=1/特征数,SVM的错分代价参数设置为C=1.
2.1 数据集与预处理
在ASHRAE项目1043-RP当中,一架90吨的离心式冷却器在实验室中模拟出冷却器系统七种可能的故障数据包,以及在常规状态下的数据包.每种故障还被细分为了4种不同的故障程度(以百分比来衡量),不同变量故障程度如表1.

表1 故障严重性级别
整个数据包记录了两组数据,一组以10 s为固定时间间隔,另一组以2 min为固定时间间隔.每一次记录,ASHRAE项目1043-RP都会提供64个数据,其中包括29个温度数据、5个压强数据、5个流量数据、7个阀门位置数据、以及压缩机的电能消耗、工作效率等.这是一份较为详尽的空调查错与诊断数据.
预处理的过程中,首先要对样本数据进行归一化.在提取数据的特征之前,对数据进行预处理是有必要的,其中的归一化可将数据限制在实验需要的一定范围内,以抑制部分其他干扰及方便实验数据的后续处理,保证程序运行的过程中收敛加快.本实验中对故障样本集和正常样本集同时进行归一化.
使用混合、多类的特征选择方法对样本数据进行特征选择.样本数据分别采用SFS、ReliefF、遗传算法以及互信息最大化-遗传算法的混合特征选择后,取出特征选择后权值较大的特征,分别将其作为样本模型特征,用于后续的SVM的分类处理.本实验中按照特征权重选取4组作为样本模型特征.
将样本特征模型输入至WEKA软件的LIBSVM分类器,在数据集中,取出66%的数据用于训练,其余的数据用于测试,得到故障识别模型.
训练结束后,根据分类器输出区域显示的训练和测试结果,对结果进行分析总结.
上述步骤的流程如图1.
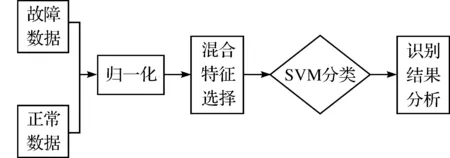
图1 故障识别流程图Figure 1 Flowchart of classification and recognition of chiller data set
2.2 实验结果与分析
根据实验设计对不同的特征选择方法进行分类识别,找出一组更有利于空调故障识别的特征子集,得到的实验数据是分别由不同的特征选择方法处理后的特征子集进行同类分类器生成的故障识别准确率.
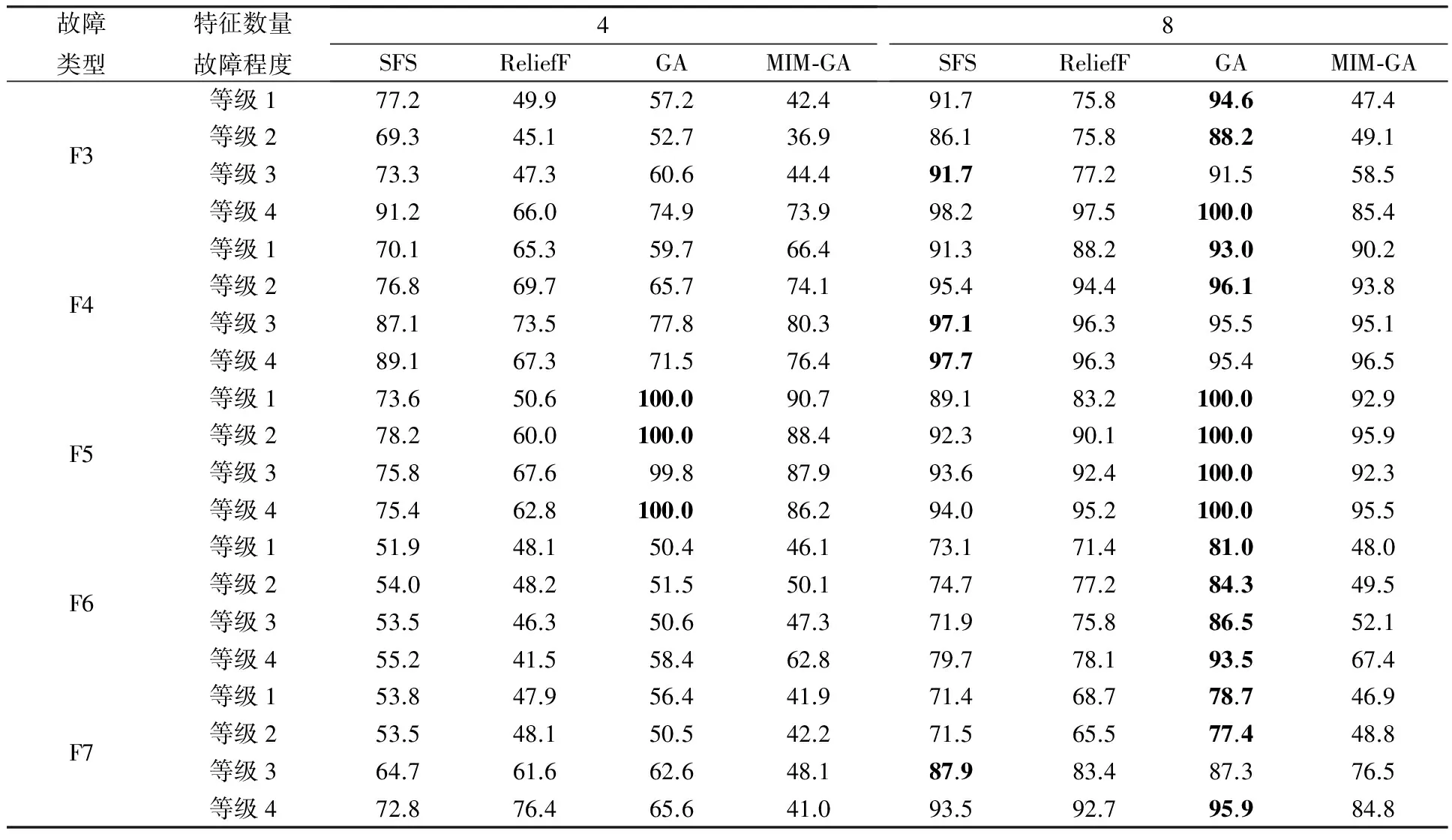
下面将采用4种特征选择的算法即SFS、ReliefF、遗传算法以及互信息最大化-遗传算法的混合特征选择中各自选取的4类样本模型特征数据进行分析整理,如表2.

表2 不同特征选择算法在冷水机组故障数据的准确率对比
(续表2)
为选择出最合适自动化空调故障诊断的特征子集,本实验分别采用SFS、ReliefF、遗传算法以及互信息最大化-遗传算法作为实验样本的特征选择方式,然后对比这4种特征选择后的特征子集数据在使用支持向量机后的故障识别效果,找出适合空调诊断的特征子集,同时判断出适合诊断的特征选择算法.
表3 故障原因对应的识别率最高的特征子集
Table 3 The highest diagnosis feature subset corresponding to each fault type

故障类型特征选择算法特征子集F1遗传算法TWCI,SharedCondTons,FWE,TCA,P⁃lift,PO⁃feed,VE,THOF2序列前向选择THI,PO⁃net,TWCD,TWEO,TWE⁃set,Tsh⁃suc,To⁃sump,TEIF3序列前向选择THI,PO⁃net,TWCD,TWEO,TWE⁃set,Tsh⁃suc,To⁃sump,TEIF4序列前向选择THI,PO⁃net,TWCD,TWEO,TWE⁃set,Tsh⁃suc,To⁃sump,TEIF5遗传算法TWCI,SharedCondTons,FWE,TCA,P⁃lift,PO⁃feed,VE,THOF6遗传算法TWCI,SharedCondTons,FWE,TCA,P⁃lift,PO⁃feed,VE,THOF7遗传算法TWCI,SharedCondTons,FWE,TCA,P⁃lift,PO⁃feed,VE,THO
实验中使用7种故障原因数据,分别为冷凝器故障、原油过剩、制冷剂无法凝结、冷凝器管道水流速度降低、蒸发器管道水流降低、制冷剂泄漏和制冷剂过剩.每类数据分为4种不同的故障程度(表1).表2对比了使用不同特征选择算法,选取出4个和8个最重要的特征以后,并使用支持向量机后的分类精度.其中,最高的分类精度值加粗表示.表3根据实验结果中特征子集的识别率进一步分析整理出针对不同故障所对应的特征子集类型在算法、故障程度以及特征数量变化上的特点规律.
分析表2、表3可以看出,在空调数据整理时,同种分类器处理后,本文中利用遗传算法特征选择处理的数据子集的故障识别率较高于序列前向选择、ReliefF和互信息-遗传算法.本文中遗传算法相较其他3种选择算法提取的特征子集具有更好的识别性能,这说明在找出更适合自动化空调诊断特征子集的过程中遗传算法有较高的效率和选择性.根据该算法选择出的特征类型即:冷凝器水温度,计算共享热传递,蒸发器水流量,冷凝器临近温度,压缩机上的压力升降,供油压力值,蒸发器阀位置,出热水温度值.本文中涉及的特征子集变量的描述见表4.
3 结 语
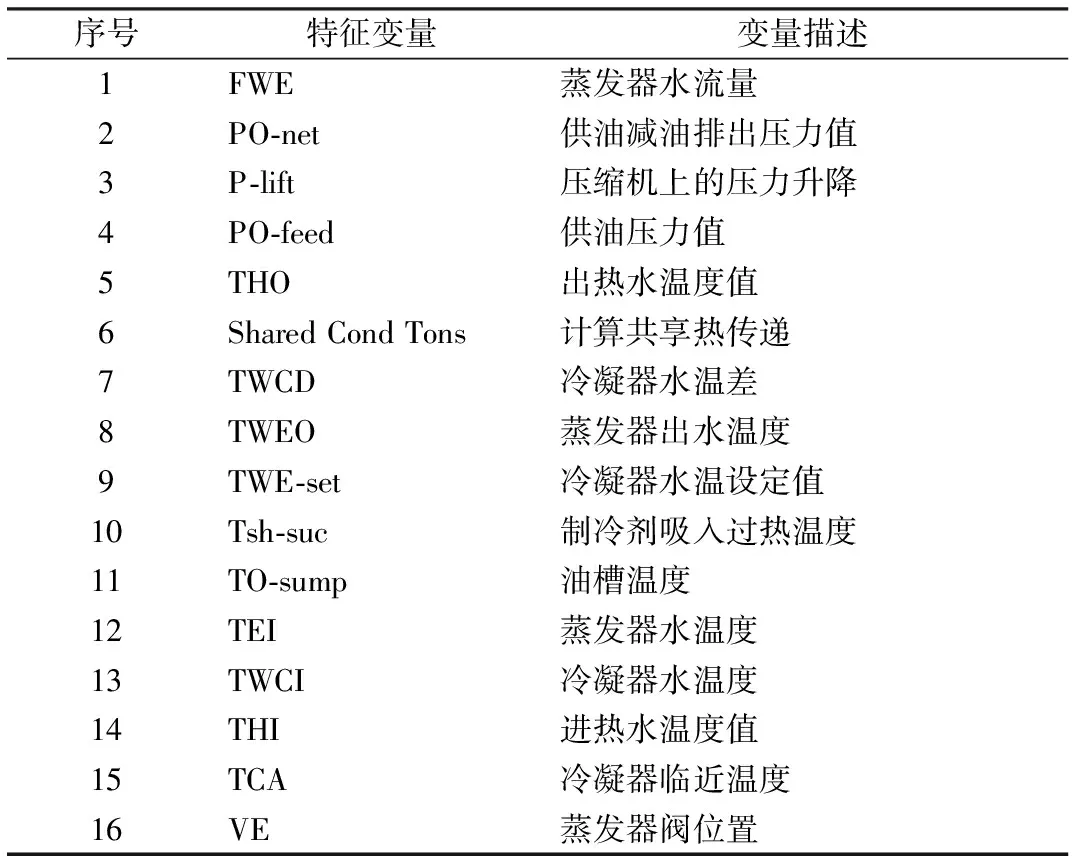
表4 特征变量及其描述
本文针对目前冷水机组故障诊断中的不足提出了一种利用多种特征选择方法提取最重要特征子集的综合性实验方法.利用AHSRAE项目1043-RP所提供的真实数据集对不同的特征选择结果进行分类精度对比.最终得到的结果能够更有效率地对冷水机组进行故障诊断.在对比了SFS、ReliefF算法、遗传算法以及互信息最大化-遗传算法在不同空调故障原因及故障程度下的识别准确率后,发现利用遗传算法特征选择的方式处理后具有较高的识别率,具体的特征子集包括冷凝器水温度、计算共享热传递、蒸发器水流量、冷凝器临近温度、压缩机上的压力升降、供油压力值、蒸发器阀位置、出热水温度值.
在今后的研究中,我们将利用实际物理模型与本文所发现的重要特征子集作比较,找出在实际热能系统中各个特征之间的关联,从而更好地分析空调诊断系统.
[1] ERGAN S,YANG X. Design and evaluation of an integrated visualization platform to support corrective maintenance of HVAC problem-related work orders[J].Journal of Computing in Civil Engineering,2016,30(3):04015041.
[2] ZHOU Q, WANG S, XIAO F. A novel strategy for the fault detection and diagnosis of centrifugal chiller systems[J].Hvac & R Research,2009,15(1):57-75.
[3] HAN H, GU B, KANG J,et al. Study on a hybrid SVM model for chiller FDD applications[J].Applied Thermal Engineering,2011,31(4):582-592.
[4] LI S, WEN J. Application of pattern matching method for detecting faults in air handling unit system[J].Automation in Construction,2014,43(43):49-58.
[5] WANG H, CHEN Y, CHAN C W H, et al. Online model-based fault detection and diagnosis strategy for VAV air handling units[J].Energy & Buildings,2012,55(12):252-263.
[6] BONVINI M, SOHN M D, GRANDERSON J, et al. Robust on-line fault detection diagnosis for HVAC components based on nonlinear state estimation techniques[J].Applied Energy,2014,124(1):156-166.
[7] KE Y, WEN S, T MULUMBA, et al. ARX model based fault detection and diagnosis for chillers using support vector machines[J].Energy & Buildings,2014,81:287-295.
[8] YAN K, JI Z, SHEN W. Online fault detection methods for chillers combining extended kalman filter and recursive one-class SVM[J].Neurocomputing,2016,228:205-212.
[9] MOLINA L C, BELANCHE L,NGELA NEBO. Feature selection algorithms: A survey and experimental evaluation.[C]//IEEE International Conference on Data Mining. Louisiana: IEEE,2002:306-313.
[10] BOLON CANDEO V, SANCHEZ MARNON N, Alonso BETANZOS A. A review of feature selection methods on synthetic data[J].Knowledge and Information Systems,2013,34(3):483-519.
[11] 魏莎莎,陆慧娟,金伟,等.基于云平台的互信息最大化特征提取方法研究[J].电信科学,2013,29(10):38-42. WEI S S, LU H J, JIN W, et al. Maximum mutual information feature extraction method based on the cloud platform[J].Telecommunications Science,2013,29(10):38-42.
[12] LU H, CHEN W, MA X, et al. Model-free gene selection using genetic algorithms[J].International Journal of Digital Content Technology & Its Applications,2011,5(1):195-203.
[13] 魏莎莎,陆慧娟,安春霖,等.一种基于互信息最大化的模型无关基因选择方法[J].计算机科学,2014,41(9):243-247. WEI S S, LU H J, AN C L, et al. Model-free gene selection method based on maximum mutual information[J].Computer Science,2014,41(9):243-247.
[14] 陆慧娟,张金伟,马小平,等.基于特征选择的过抽样算法的研究[J].电信科学,2012,28(1):87-91. LU H J, ZHANG J W, MA X P, et al. Study of over-sampling method based on feature selection[J].Telecommunications Science,2012,28(1):87-91.
[15] KIRA K, RENDELL L A. The feature selection problem: Traditional methods and a new algorithm[C]//National Conference on Artificial Intelligence. California: AAAI Press,1992:129-134.
[16] KONONENKO I. Estimating attributes: Analysis and extensions of RELIEF[J].Lecture Notes in Computer Science,1994,784:171-182.
[17] 刘亚卿,陆慧娟,杜帮俊,等.面向基因数据分类的旋转森林算法研究[J].中国计量学院学报,2015,26(2):227-231. LIU Y Q, LU H J, DU B J, et al. Study on classifier algorithm of genetic data based on rotation forest[J].Journal of China University of Metrology,2015,26(2):227-231.
Important features selection in fault diagnosis of chillers
MA Lulu, YAN Ke, LU Huijuan
(College of Information Engineering, China Jiliang University, Hangzhou 310018, China)
In the data-driven centralized air-conditioning system fault diagnosis process, feature selection is the essential pre-process. The selection of important features is meaningful to effective fault judgment. In this paper, different methods were used to select features from the fault data of a group of chillers. Support vector machines were used for classification with selected feature subsets. The most important feature subsets of chiller failures were obtained through comparative analysis.
feature selection; genetic algorithm; ReliefF algorithm; support vector machine
2096-2835(2017)02-0190-06
10.3969/j.issn.2096-2835.2017.02.009
2016-12-09 《中国计量大学学报》网址:zgjl.cbpt.cnki.net
2015年浙江省重点学科建设科研启动费项目(No.000485).
马露露(1991- ),女,江苏省徐州人,硕士研究生,主要研究方向为机器学习.E-mail:1371443586@qq.com 通信联系人:严 珂,男,讲师.E-mail:yanke@cjlu.edu.cn
TP391
A
猜你喜欢
科技创新与应用(2022年31期)2022-11-07
电力需求侧管理(2022年4期)2022-07-24
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
计算机测量与控制(2020年7期)2020-08-03
上海节能(2020年3期)2020-04-13
合肥工业大学学报(自然科学版)(2020年2期)2020-03-23
南京大学学报(数学半年刊)(2020年1期)2020-03-19
计算机应用(2016年10期)2017-05-12
电脑知识与技术(2016年1期)2016-03-22
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
