
FPGA的多路数据并行录取和时序资源优化
2017-07-31 21:57苏阳赵英潇黄睿张月陈曾平
单片机与嵌入式系统应用 2017年7期
苏阳, 赵英潇, 黄睿, 张月, 陈曾平
(国防科技大学 自动目标识别重点实验室,长沙 410073)
摘要: PCIe总线在雷达系统中应用日益广泛,但FPGA内部集成的PCIe硬核数量有限,难以满足雷达并行录取多种数据的需求。为此,本文提出了一种改进的PCIe DMA数据传输方法,利用Xilinx FPGA集成的单个PCIe硬核实现了多路数据在高速传输情况下的并行录取。针对实现过程中遇到的时序问题,提出了采用多级FIFO级联方法进行时序优化。依据Xilinx FPGA的时钟网络特点,对时钟资源进行优化,便于日后系统的扩展和升级。
FPGA的多路数据并行录取和时序资源优化
苏阳, 赵英潇, 黄睿, 张月, 陈曾平
(国防科技大学 自动目标识别重点实验室,长沙 410073)
摘要: PCIe总线在雷达系统中应用日益广泛,但FPGA内部集成的PCIe硬核数量有限,难以满足雷达并行录取多种数据的需求。为此,本文提出了一种改进的PCIe DMA数据传输方法,利用Xilinx FPGA集成的单个PCIe硬核实现了多路数据在高速传输情况下的并行录取。针对实现过程中遇到的时序问题,提出了采用多级FIFO级联方法进行时序优化。依据Xilinx FPGA的时钟网络特点,对时钟资源进行优化,便于日后系统的扩展和升级。
FPGA;PCIe;并行录取;时序优化
引 言
PCIe(PCI-Express)总线作为芯片间和板间通信最常用的标准之一,目前在雷达系统中应用尤为广泛。然而随着雷达技术的不断发展,当前雷达在应用过程中面临目标多样化、环境复杂化和任务多元化等问题。用一部雷达代替多部雷达的功能,使一部雷达同时具有多种对抗能力成为当前雷达发展的主要趋势[2]。
实验室采用的Xilinx公司Kintex-7 FPGA芯片内部仅集成了单个PCIe硬核,难以满足多种类型数据并行录取的要求。为此本文提出了一种改进的并行录取方法,并对其进行了时序和时钟资源方面的优化。
1 硬件平台简介
本文的硬件平台是某雷达系统的数据存储与管理工作站。该工作站主要由一台机架服务器和安装在其内部的磁盘阵列以及功能板卡组成。功能板卡主要是两块PCIe光纤接口卡和一块阵列控制卡。其中一块PCIe光纤接口卡用于接收中频直接采集宽带数据(以下简称“直采数据”)和宽带去斜回波数据(以下简称“去斜数据”),而本文的主要工作就是在此板卡上展开。
PCIe光纤接口卡采用Kintex-7 FPGA芯片接收直采数据和去斜数据并传输至阵列服务器。FPGA芯片通过PCIe接口与阵列服务器进行数据交互。另外,该板卡还提供8片DDR3 SDRAM芯片,可用作数据缓存。
2 多路数据并行录取的设计与实现
2.1 并行录取实现思路
阵列服务器与FPGA之间通过PCIe DMA(Direct Memory Access)的方式进行数据传输,其标准的数据传输流程如图1所示[3-4]。服务器在复位完成后会为DMA缓存块申请内存空间并设置DMA的写地址、TLP包的大小和数量,之后开启DMA写数据直至结束。
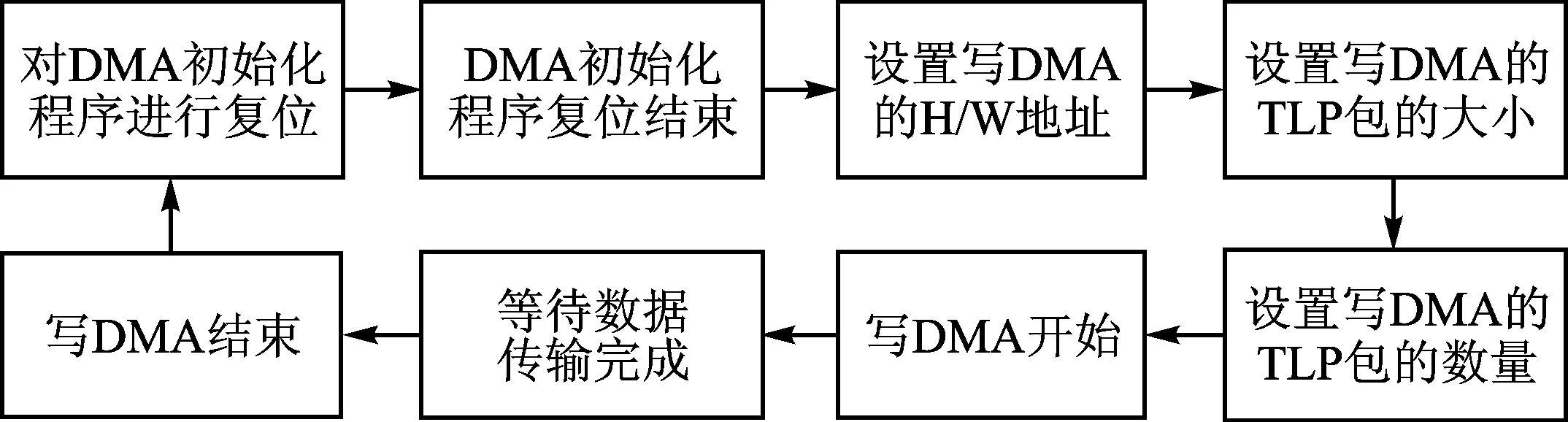
图1 DMA数据传输流程图
在FPGA PCIe的BAR内存中可以预先分配多个寄存器用于服务器控制FPGA的DMA进程。通过这些寄存器,服务器可以读取当前数据缓存的状态,FPGA也可以通过这些寄存器接收主机的控制指令[5]。由于需要实现并行录取直采数据和去斜数据,而Kintex-7 FPGA内只有一个PCIe硬核,即单次DMA过程中FPGA只能传输一种数据。因此对上述DMA流程加以改进以实现多路数据并行传输,具体如图2所示。
FPGA会实时计算当前缓存中的数据量,一旦其超过设定的阈值,则会通过PCIe BAR内存中的寄存器反馈给主机。在DMA开始之前,通过读取直采和去斜数据的缓存状态,主机会向FPGA下达相应数据的选通指令。DMA开始后,FPGA根据选通信号输出相应的数据。一次DMA结束后主机根据数据类型的不同将接收到的数据存储至相应路径下。
由于直采数据的数据率和数据量都远大于去斜数据,直采数据缓存易变满,因而选择优先判断直采数据是否就绪。又由于设定的阈值大于单次DMA的总数据量且远小于DDR3芯片的存储容量,在并行录取时,能够保证数据传输类型快速切换而不致缓存变满出现丢数的情况。
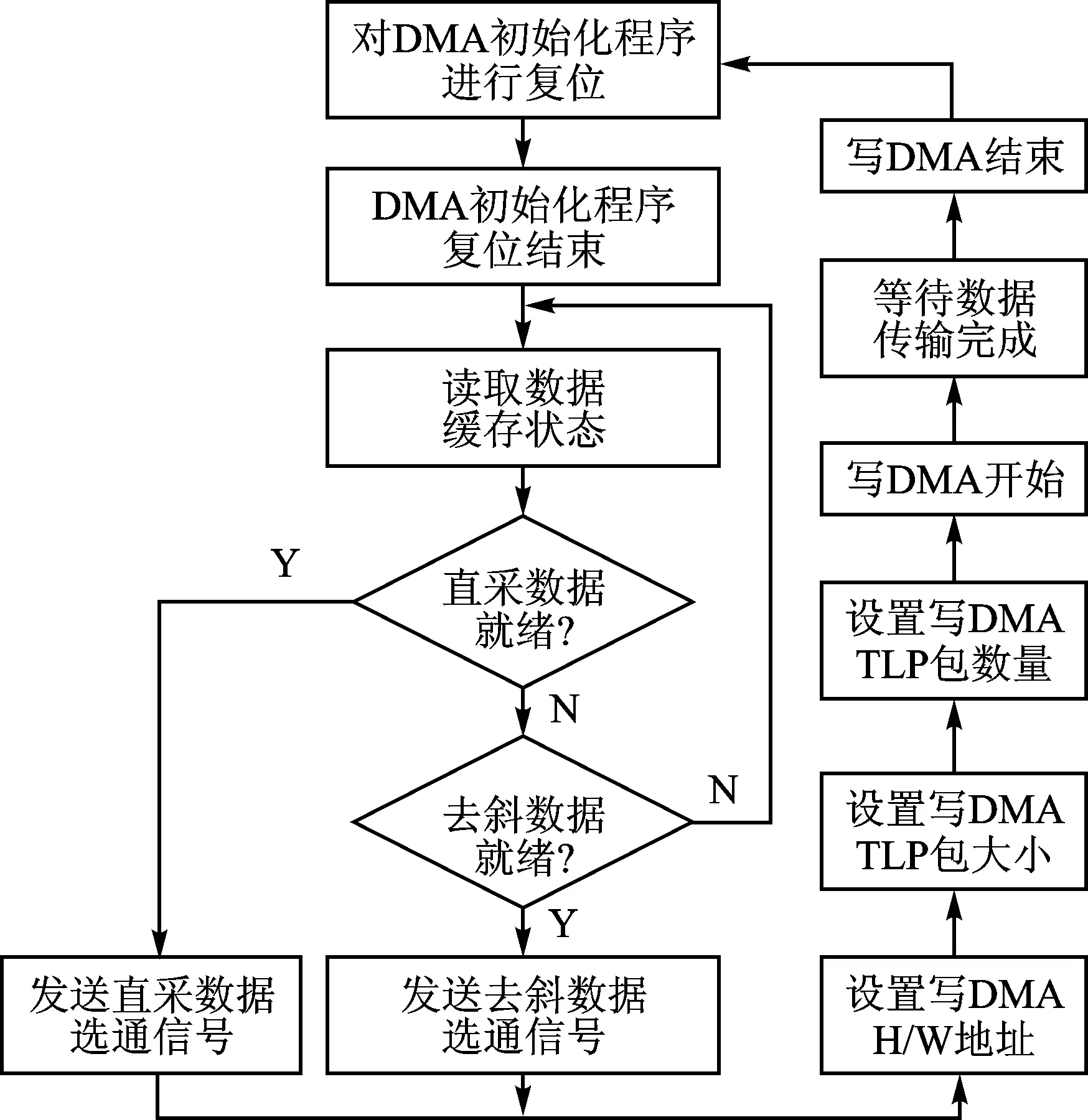
图2 改进后的DMA数据传输流程图
2.2 FPGA顶层结构设计
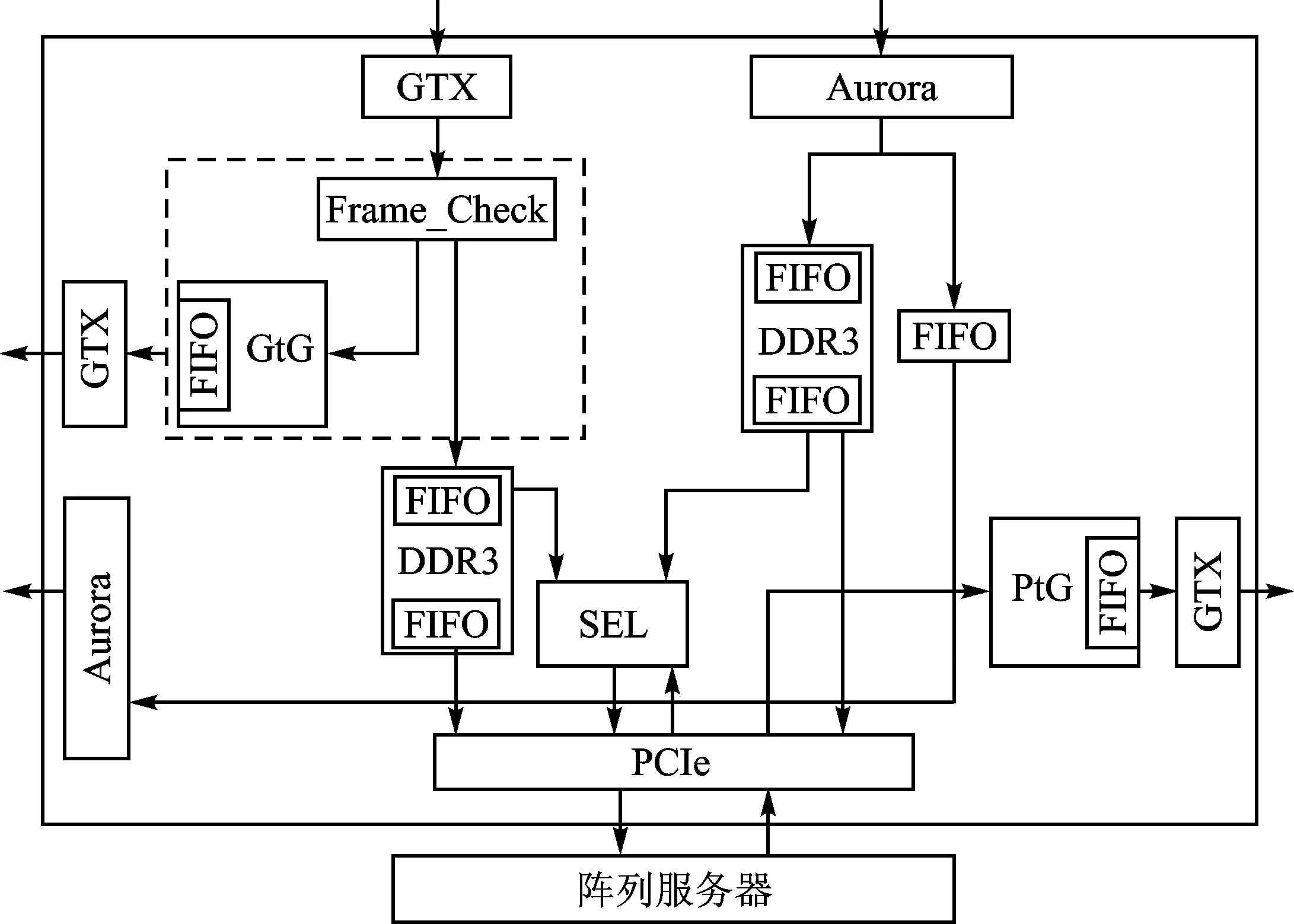
图3 FPGA顶层结构设计图
根据上述设计思路,FPGA顶层结构设计如图3所示,其中主要模块功能介绍如下:
① GTX模块用于接收去斜数据,Aurora模块用于接收直采数据;
② Frame_Check模块用于将接收的去斜数据进行位序调整,之后输入DDR3模块;
③ DDR3控制模块用于控制DDR3芯片读写时序,并将当前芯片读写状态通过PCIe模块反馈给阵列服务器;
④ PCIe模块由Xilinx提供的PCIe IP核配置生成,用于FPGA与服务器之间的数据交互;
⑤ SEL模块用于接收服务器的指令,选通相应数据通道,将相应的数据通过PCIe模块发送给服务器;
⑥ FIFO用作GTX或者Aurora模块与DDR3模块之间以及DDR3模块与PCIe模块之间的数据位宽转换和跨时钟域处理。
2.3 实现结果
通过上述方法,实际在用户端看到的结果即为直采数据和去斜数据能够实现并行录取,如图4所示。
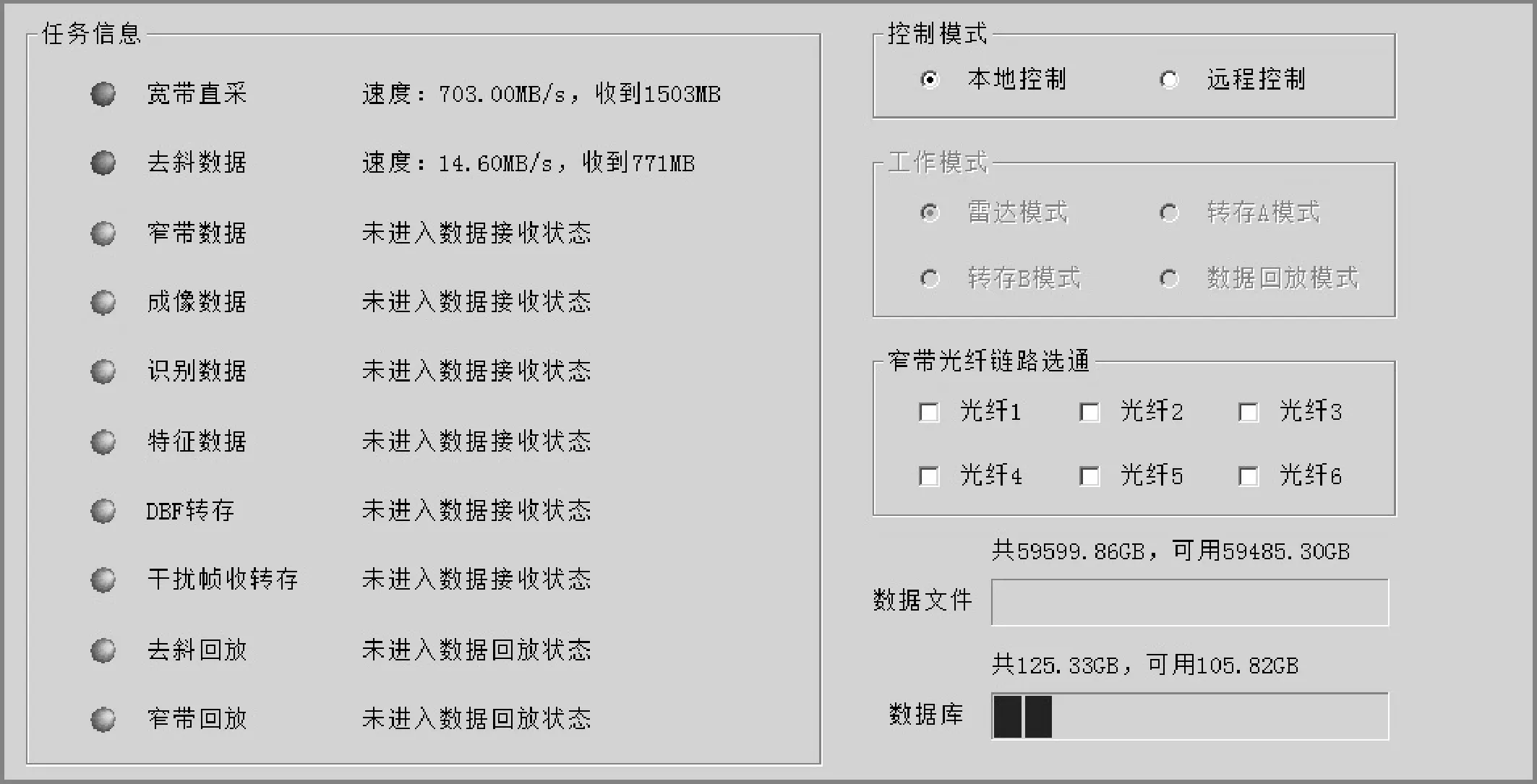
图4 数据并行录取结果图
3 时序优化
3.1 时序违例原因分析
利用Xilinx ISE的静态时序分析工具进行时序分析后发现部分路径存在时序问题[6]。从ISE提供的时序报告可知,出现时序问题的路径在于:PCIe模块输出PCIe_fifo_rd_en信号至DDR3控制模块,DDR3控制模块就是通过接收该信号实现对DDR3芯片内数据读取的控制。
根据时序报告中对路径的具体描述,如表1所列,该路径经过的3级组合逻辑,逻辑延迟为0.779 ns,线延迟却高达5.426 ns,占总延迟时间的87.4%。结合在FPGA Editor中看到的实际布线结果,可以发现走线延迟过长是导致时序问题的主要原因。而出现这种情况的根本原因在于用作DDR3读数据的缓存ddr3 read fifo在布局布线的过程中同时受到多个时序约束的影响。

表1 时序违例路径详细信息表
FPGA内部的FIFO是由多个blcok RAM搭建出来的,而单个RAM在芯片内部都占据固定的位置。随着FIFO容量的增加,使用的blcok RAM数量越多,但这些blcok RAM之间需要满足FIFO内部固有的时序约束,因而其布局不能过于分散。
除此以外,ddr3 read fifo还需要满足与DDR3控制相关逻辑之间的时序约束,如图5所示。最终ddr3 read fifo整体位置在图中左下区域且内部blcok RAM之间布局相对紧凑,而PCIe相关逻辑均分布在右上区域,靠近内嵌的PCIe硬核的位置。两者之间布局位置相隔较远,导致布线延迟过大。

图5 时序违例路径实际布局结果图
3.2 时序优化方法
基于以上分析可知,如果只是简单的在时序违规的路径之间添加一级寄存器,将整个路径分割开来。虽然能消除时序错误,但PCIe_fifo_rd_en信号将延迟一个周期,意味着读DDR3的数据时序会出现偏差,这将导致数据传输过程中出现丢数漏数的情况。因此采用多个FIFO级联的方法来改善时序,即大容量blcok RAM FIFO +流水线+小容量distributed RAM FIFO的方式,如图6所示。
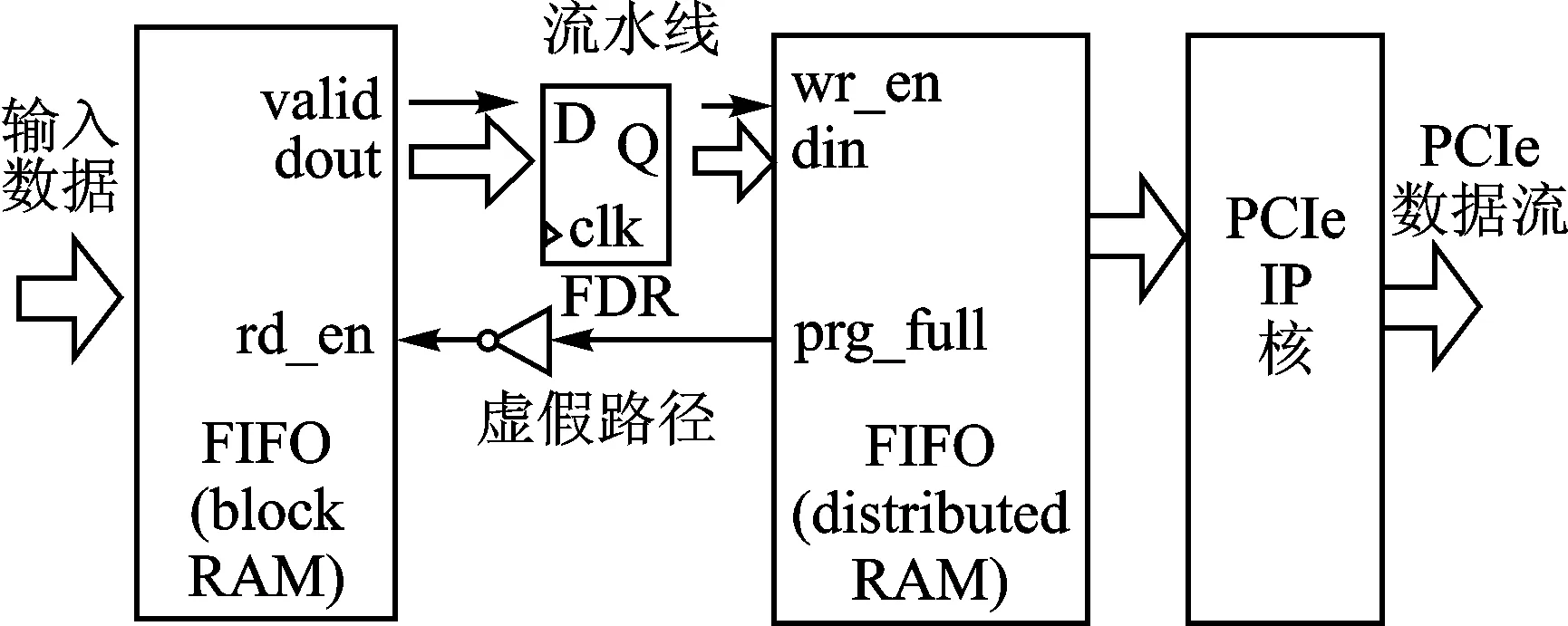
图6 FIFO级联示意图
前级FIFO由blcok RAM构成,作为数据缓存的主体。后级FIFO的容量较小,由distributed RAM构成。相较于block RAM,distributed RAM容量更小,但在布局布线的过程中更加灵活,可供选择的位置也更多,能够显著缓解大容量FIFO和PCIe 模块之间的时序压力。同时在两个FIFO之间添加一级流水线作为连接,后级FIFO的prog_full信号用于控制前级FIFO的rd_en端,且在时序约束中将该路径设为虚假路径,进一步缓解时序压力。如果布局布线的效果依然不理想,还可以在此基础上利用PlanAhead软件手动调整blcok RAM和distributed RAM的布局位置,用于降低时序冲突[7]。
3.3 时序优化结果

图7 时序优化后的布局结果图
时序优化后的布局情况如图7所示。优化后的ddr3 read fifo(图中标红色区域)和PCIe相关逻辑(图中标黄色区域)的布局位置相对靠近,整体上减少了走线延迟。且两者之间还有一级FIFO用作缓存,即图中标绿色区域,将原先时序违例的路径分割开来,极大地缓解了时序压力,时序问题由此得到解决。
4 时钟资源优化
在Xilinx的FPGA中,时钟网络资源分为两类:全局时钟资源和区域时钟资源。全局时钟资源是一种专用互连网络,它可以降低时钟歪斜、占空比失真和功耗,提高抖动容限。Xilinx的全局时钟资源设计了专用时钟缓冲与驱动结构,从而使全局时钟到达CLB、IOB和BRAM的延时最小。当FPGA内部使用全局时钟资源时,需要经过全局时钟网络缓冲器BUFG驱动。本文中使用的PCIe光纤接口卡上的Kintex-7 FPGA芯片内部仅有32个BUFG可供使用。
区域时钟资源独立于全局时钟网络。Xilinx的器件分为若干个时钟区域,Kintex-7就有16个区域。它与全局时钟不同,区域时钟信号只能驱动限定的时钟区域。与BUFG类似,使用区域时钟资源需要经区域时钟缓冲器BUFH或者BUFR驱动。BUFH可驱动单个时钟区域中的水平全局时钟树,BUFR则最多可以驱动三个相邻时钟区域的区域时钟。相较于BUFH和BUFR,BUFG资源数量较少,不能盲目地将所有时钟都用BUFG驱动,这将不利于日后代码的扩展和升级[8]。
通过查看MAP Report中时钟资源使用情况的详细信息,可以了解每个模块内部时钟资源的使用情况。通过FPGA Editor可以了解每个时钟驱动的逻辑资源的分布情况。对于仅覆盖三个时钟区域以内的时钟改由BUFR驱动,对于仅覆盖单个时钟区域的时钟可改为由BUFH驱动。
如图8所示,图中黄色走线为时钟sync_clk_i经过BUFG之前的部分,红色走线为该时钟经过BUFG之后通过全局时钟网络驱动逻辑的部分,蓝色矩形框为该部分逻辑所在的时钟区域。

图8 sync_clk_i时钟布线结果图
可以看到sync_clk_i驱动的逻辑较少且仅分布在单个时钟区域,故而将其改为由BUFH驱动。优化结果如图9所示。黄色走线依然为时钟sync_clk_i经过BUFG之前的部分,红色走线为该时钟经过BUFG之后的部分,并且ISE在满足时序约束的条件下对驱动的逻辑部分重新进行了布局。通过实际数据传输测试,时钟资源优化后依然能够正常工作。

图9 优化后的sync_clk_i时钟布线结果图
结 语

[1] J. Gong T,Wang J H,Chen H Y,et al.An Efficient and Flexible Host-FPGA PCIe Comm-unication Library[C]//in Field Programmable Logic and Applications (FPL) 24th International Conference on IEEE,Germany:Munich,2014.
[2] 郭建明,谭怀英.雷达技术发展综述及第五代雷达初探[J].现代雷达,2012,34(2):5-6.
[3] Xilinx.Bus Master Performance Demonstration Reference Design for the Xilinx Endpoint PCI Express Solutions,2015.
[4] H Kavianipour,C Bohm.High Performance FPGA-Based DMA Interface for PCIe[C]//IEEE TRANSACTIONS ON NUCLEAR SCIENCE,2014.
[5] Xilinx.7 Series FPGAs Integrated Block for PCI Express v3.3 LogiCORE IP Product Guide,2016.
[6] 许天一.FPGA 静态时序分析的研究与实现[D].哈尔滨:哈尔滨工业大学,2014.
[7] Xilinx.Timing Closure User Guide,2012.
[8] Xilinx.7 Series FPGAs Clocking Resources,2015.
Parallel Data Transmission Timing and Resource Optimization Based on FPGA
Su Yang,Zhao Yingxiao,Huang Rui,Zhang Yue,Chen Zengping
(ATR,National University of Defense Technology,Changsha 410073,China)
The PCIe bus is widely used in the radar system,but the internal integrated FPGA PCIe core is limited.So ti is difficult to meet the needs of a variety of data parallel transmission of radar.In this paper,an improved PCIe DMA data transmission method is proposed,which ensures the data can be achieved in the parallel high speed transmission using Xilinx FPGA integrated PCIe core.In order to solve the problem of timing in the process of implementation,a multi-level FIFO cascade method is proposed.Based on the characteristics of Xilinx FPGA clock network,the clock resource is optimized for the system expansion and upgrade.
FPGA;PCIe;parallel transmission;timing optimization
TP336
A
�士然
2017-03-13)
猜你喜欢
中国农业信息(2021年3期)2021-11-22
数学小灵通·3-4年级(2021年9期)2021-10-12
小学生学习指导(低年级)(2020年10期)2020-11-09
电子制作(2019年15期)2019-08-27
小学生学习指导(低年级)(2018年12期)2018-12-29
电子制作(2017年13期)2017-12-15
数学大王·中高年级(2017年2期)2017-02-08
电子制作(2016年15期)2017-01-15
学苑创造·A版(2016年4期)2016-04-16
火控雷达技术(2016年3期)2016-02-06
