
基于数据挖掘的雾霾预测和分析
2017-08-16 14:51陈嘉昊
制造业自动化 2017年6期
陈嘉昊,刘 佳
(北京信息科技大学,北京 100192)
基于数据挖掘的雾霾预测和分析
陈嘉昊1,刘 佳2
(北京信息科技大学,北京 100192)
近几年我国很多地区出现的严重雾霾天气给人们的生活造成了巨大影响。根据互联网上北京近年的空气质量和气象数据,对雾霾的发生进行预测,并分析各因素在雾霾预测中的作用。建立包括BP神经网络在内的多种分类模型,通过交叉验证的方式训练模型并得到预测结果。选取不同属性组进行分类,结合ROC曲线、准确率等评价标准,分析不同属性组对雾霾天气的影响,从而得出供暖、交通等与雾霾天气的关系。该工作可为雾霾的防治提供理论支持。
雾霾;BP神经网络;分类器;数据挖掘
0 引言
近年来雾霾严重影响了人们的日常生活。众所周知,雾霾天气的形成,既有气象原因,也与污染气体排放、地形等因素密切相关。就北京而言,冬季燃煤供暖消费巨大,机动车保有量持续上升,是重要的污染来源。2015年柴静在《苍穹之下》之中指出“北京的污染源之中最大的就是来自机动车”,而中科院大气物理研究所某课题组曾对外公布了一组数据:三大主要PM2.5的来源是土壤粉尘(15%)、燃煤(18%)、生物质燃烧(12%),然而机动车尾气只占4%。各污染因素对雾霾的产生起多大作用,特别是机动车尾气和供暖对雾霾的影响哪个更大,一直是一个饱受争议的话题。近年来已经有不少学者运用多种非线性的模型对雾霾天气进行了预测和分析,但是对于上述争议性话题还没有系统的分析研究。本文基于网络数据,通过数据挖掘方法,对雾霾的成因,特别是机动车尾气和供暖污染对雾霾天气形成的影响做出分析和评估。
本文提出了一种新方法,基于多种分类算法对雾霾气象数据进行预测分析,通过计算不同属性组的分类准确率、ROC(Receiver Operating characteristic Curve)曲线等,对雾霾的不同成因做出评价,分析出机动车尾气和供暖废气对雾霾天气的形成的影响。本方法选取与机动车尾气、供暖、天气相关的属性分别构成三个属性组,首先用BP神经网络作为分类器,通过交叉验证对雾霾天气进行预测,并画出不同属性组的ROC曲线,对各属性组对分类的影响进行评估,然后用C4.5、RIPPER、k近邻、SVM、随机森林等多种分类算法进行分类预测,并对分类结果的正确率、ROC曲线面积等进行分析。经过以上过程分析得出结论:北京市机动车尾气和燃煤供暖对雾霾天气的影响较大,且作用相当。
1 相关工作
近年来已经有不少学者运用非线性的分析预测方式对雾霾天气进行了预测,其中,运用神经网络方法对进行雾霾预测并构建模型,该方法适用于对非线性特征对象的的分析和预测,以及网络具有自学习的能力和鲁棒性好的特点。艾洪福和石莹等[1]运用了BP神经网络,在对网络中间隐层的连接权和阈值进行修正,使得在雾霾天气指标比较单一的情况下,仍能保持网络预测分析的准确性;马楚焱、祖健、付清盼和罗凌霄等[2]设计了基于遗传算法的BP神经网络优化了在网络训练过程中局部极小化和平坦区域问题,提高了雾霾空气能见度预测模型的有效性。
相关的文献中也有不少运用数理统计和数据拟合的方法进行雾霾天气的研究。侯琼煌和杨航[3]等对二氧化硫和烟尘的排放量以及环境污染总治理投资建立了时间序列的预测模型,并运用对所有时间序列都适用的三次指数平滑法进行雾霾趋势预测。杨文光、林连海和田立勤[4]等使用离散小波分析将二氧化硫和烟尘排放量分解到高频和低频两个频道,对上述的两个频道分别建立周期函数并用Fourier曲线的周期特性进行拟合,得到了较高的预测效果。付倩娆[5]等通过多元线性回归模型,采用在线更新的预测方式根据当天检测结果,不断更新模型,在无需大量预测数据的前提下,及时反映当前雾霾情况的变化。
但是对于各污染因素对雾霾的产生起多大作用,特别是机动车尾气和供暖对雾霾的影响哪个更大等争议性话题还没有系统的分析研究。
2 概述
本研究根据中国天气后报网和中国环境监测网站的600组天气数据数据,用多种分类算法对雾霾天气进行预测分析,通过计算不同属性组的分类准确率、ROC曲线等,对雾霾的不同成因做出评价,分析出机动车尾气和供暖废气对雾霾天气的影响。第3部分对本研究应用的各种分类算法和评估方法进行了介绍,第4部分给出了本研究的数据分析和处理过程,第5部分为方法的实验结果及分析。
3 基础算法简介
3.1 BP神经网络
BP神经网络是一种利用误差反向传播训练的前馈型网络,是迄今为止应用最为广泛的神经网络。BP网络目前广泛应用于函数逼近、模式识别、数据挖掘、系统辨识与自动控制等领域。BP算法实际上就是求取网络总误差函数的最小值问题,具体采用“最速下降法”,按误差函数的负梯度方向进行权系数的修正。具体学习算法包括两大类过程:其一是输入信号的正向传播过程。其二是输出误差信号的反向传播过程。逐层递归的计算是网络的输出值和期望输出值的误差,根据此误差调整网络连接权值和神经元的阈值[6]。
3.2 决策树(Decision Tree)
决策树(Decision Tree)是一种预测模型,它包括决策结点,分支和叶节点三个部分。其中,决策节点代表一个测试,通过代表待分类样本的某个属性,在该属性上的不同测试结果代表一个分支,分支代表每个决策节点的不同取值。每个叶节点存放某个类别的标签,表示一种可能的分类结果。决策树对未知样本的分类过程是,自决策树根节点开始,自上而下沿某个分支向下搜索,直到到达叶节点,叶节点的分类标签就是该未知样本的类别。
3.3 基于规则的分类器
基于规则的分类器是一种通过使用一组判断规则来对记录进行分类的技术。其中重要的算法为IREP算法和RIPPER算法。RIPPER算法是一个优化版本的JPip,其中JRip分类器实现了命题规则学习,重复增量修枝(RIPPER)算法生成一条规则,随机地将没有覆盖的实例分成生长集合和修剪集合,规则集合中的每一个规则是由两个替代规则和修订规则生成[7]。
3.4 基于实例的算法
基于实例的算法是推迟对训练数据建模,直到需要对未知样本进行分类才进行建模。其中,IBK分类器是一种K-最近邻分类器。IBK可用多种不同的搜索算法来加快最近邻任务。在样本中有比较多的噪点时,通过IBK算法就能解决一个邻居分类效果较差,出现误差较多的情况,此情况下IBK算法就成了一个较优的分类器选项。Kstar分类器在最近邻分类器的基础上对样本间距离的确定进行提升,使用的是熵的距离函数[7]。

3.5 支持向量机
支持向量机(Support Vector Machine,SVM)分类器是一种监督式学习方法,广泛地应用于统计分类以及回归分析。SVM的特点是能够同时求取最小化经验误差与最大化几何边缘,因此支持向量机也被称为最大边缘分类器。支持向量机技术具有坚实的统计学理论基础。SVM可以很好地用于高维数据,避免维数灾难。
3.6 集成学习
集成学习(Ensemble Learning)就是通过聚集多个分类器的预测结果来提高分类准确率,集成的方式由训练数据构建一组基分类器(Base Classifier),然后通过每个基分类器的预测的投票来进行分类。例如,装袋(Bagging)、提升(Boosting)和随机森林(Random Forest)算法。
3.7 分类模型评估
分类模型能够正确预测先前没有见过的样本,分类标签能力为评估一个分离器性能的一个最为普遍的以及最为成熟的一个方法。在平衡的数据集中,它将每个类别看做同等重要,提高了分类的置信度。对于一个二元分类问题,预测可能产生四种不同的结果,如表1所示。

表1 二元预测的不同结果
真阳性率(True Positive Rate)是TP除以真实类别为yes的总数(TP+FN),TPR=TP/(TP+FN);假阳性率(False Positive Rate)是FP除以真实类别为no的总数(FP+TN),即TPR=FP/(FP+TN);综合准确率是正确分类总数除以全体分类总数[准确率=(TP+TN)/(TP+TN+FP+FN)]。
接受者操作特征(ROC)曲线是显示分类器真阳性和假阳性率之间折中的一种图形化表示方法。在ROC曲线中,X轴为假阳性率,Y轴为真阳性率,曲线的每个点对应某个分类器归纳模型。ROC曲线下方的面积(AUC)提供了另一种评估模型的平均值性能的方法。如果模型是完美的,则它的ROC曲线下方的面积等于1,当AUC的值在0.8以上能表示分类器的性能能够对未知数据做比较准确的预测[8]。
4 算法流程
4.1 数据收集与处理
本研究采用的雾霾天气数据来自中国天气后报网和中国环境监测网站共600组数据作为雾霾仿真数据(如表2所示)。
通过对冬季燃煤供暖和机动车尾气排放污染物详尽的调查和分析,把以上数据分成三个雾霾气象数据的属性组。燃煤供暖属性组的数据为温度(T)、最高和最低温度(TM,Tm)、湿度(H)、平均风速(V)、最大持续风速(VM)、NO2、SO2和平均能见度(VV)。机动车尾气排放属性组的数据为温度(T)、最高和最低温度(TM,Tm)、湿度(H)、平均风速(V)、最大持续风速(VM)、CO、O3和平均能见度(VV)。对以上两个属性组本实验增加了一个参照组用来作对照实验,在对比中更能反应出实验属性分组的客观性和科学性。
4.2 基于BP神经网络的雾霾预测
基于BP神经网络的雾霾天气预测,主要利用了网络本身良好的非线性处理能力,通过拟合训练数据关系进行分类。然后通过ROC曲线对不同属性组对雾霾的影响程度进行分析。具体流程如下:
对600组雾霾天气数据进行归一化处理。消除雾霾属性中数据的量纲差别。将处理过的数据按照三折的交叉验证处理方法分成网络训练组和网络预测组两部分。构建一个三层BP神经网络,输入结点与属性个数相同,隐层节点数利用隐层节点计算公式得出燃煤供暖、机动车尾气和参照组分别为4、3和2个节点,输出层结点数为1。进行对三个雾霾属性组样本进行分别训练。
画出ROC曲线(Receiver Operating characteristic Curve),根据ROC曲线形状,以及线下面积(AUC)定性和定量评价不同属性组对雾霾天气的影响。通过多次实验,对分类正确率和ROC曲线的线下面积取平均值。
4.3 基于其他分类算法的分析
首先,基于C4.5决策树算法进行分类。雾霾数据是具有离散属性和连续属性的多元数据,可用C4.5算法进行分类。针对三个属性组,分别运用二分法创建决策树,为决策树创建新节点对其进行扩展,使用信息增益率(GainRatio)筛选属性作为划分训练记录的测试条件。
第二步,运用RIPPER算法进行分类。这是一种基于规则的分类算法。在设计算法开始时把规则表R置为空,运用函数Learn-One-Rule提取类别y覆盖当前属性训练记录集的最佳规则。
第三步,运用K-近邻和Kstar算法进行分类,这是两个基于实例的分类算法。在每一个测试样本集中对每一个测试样本,使用熵的距离函数计算该样本与所有训练样本之间的距离,通过进一步修改距离权重,进一步降低距离较大分布点的干扰;通过扩大近邻学习的节点范围,从原来的一个相邻的节点单位(k=1)扩大到八个节点单位(K=8),降低异常点的干扰,以确定其最近邻的集合。
第四步,运用基于支持向量机分类器的序列最小化算法(SMO)。该算法在传统支持向量机的基础上使用高斯核的核函数,使属性数据映射到高维,避免了在对多维的雾霾属性数据进行分类处理时出现线性不可分情况,提升了分类器对多维的天气数据的鲁棒性。
第五步,在集成学习中,本文采用了三个不同的集成学习算法对三个属性组进行数据分析和预测。首先对每一个属性组原始的天气数据样本进行随机抽取。依据均匀概率分布从原始数据集中又放回的抽取,使每一个自助样本集和原始数据集一样大,确保每一个自助样本集包含原始数据集中60%以上的数据。选择对应抽取完成的自助数据集逐一构建分类器。分类器对单个预测值进行多数表决,得票最高的类别指派给测试样本。应用提升算法中的AdaBoost算法,对属性组中离群点数据赋予更高的权值,从最初单个变量权值为0.0017增加到0.0167降低对组中其他数据的误差影响。采取随机森林的集成学习算法。此类算法在最初基于单个决策树的单个分类器算法上,集成多棵决策树进行预测。

表2 原始天气属性类别

表3 三组雾霾属性组示例(燃煤供暖排放属性组)

表4 三组雾霾属性组示例(汽车尾气排放属性组)

表5 三组雾霾属性组示例(参照属性数据组)
5 实验结果及分析
5.1 数据采集与处理
本研究采用的雾霾天气数据来自中国天气后报网和中国环境监测网站发布的2014~2016年每年的秋冬春三个季节雾霾易发的五个月作为环境监测数据。经过属性组的筛选,共600组数据作为雾霾仿真数据(如表6所示)。
通过对冬季燃煤供暖和汽车尾气排放污染物详尽的调查和分析,把以上数据分成三个雾霾气象数据的属性组。对以上两个属性组本实验增加了一个参照组用来作对照实验,在对比中更能反应出实验属性分组的客观性和科学性。天气数据在数据分布上基本符合统计学中的高斯分布,反映了属性组中数据平衡性,表明实验数据客观真实有说服力。
国际上对烟雾的能见度定义为不足1km,薄雾的能见度为1km~2km,雾霾的能见度为2km~5km划分标准编辑。因此依照国际标准对平均能见度数据进行归一化处理(部分数据处理后的部分数据如表10所示)。
5.2 基于BP神经网络的分类
将网络的学习率调整为0.01,误差设定为0.001。经过网络对其中相关参数、节点的权值和阈值在网络训练中进行优化后,用MATLAB软件对网络进行仿真,基于ROC曲线和其线下面积AUC对三个属性组进行分析,部分仿真图表如图1所示。由图可知,燃煤供暖和机动车尾气排放这两个属性组的AUC数值大致相同,且都要大于参照组AUC数值,因此可得出燃煤供暖排放和机动车尾气排放这两个因素对雾霾天气有较大影响,并且作用大致相当。

表6 原始天气数据
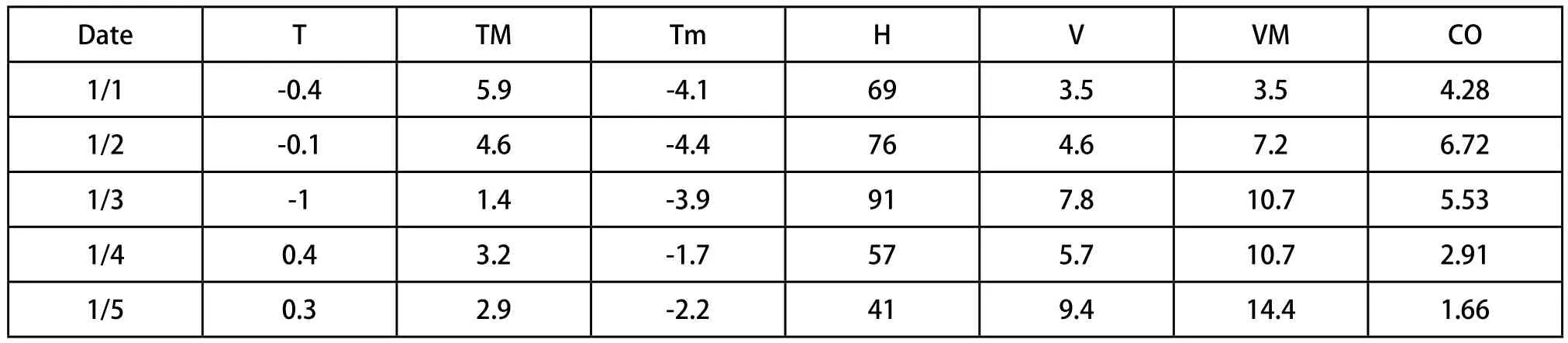
表8 汽车尾气排放属性组

表9 参照属性数据组

表10 对平均能见度处理后的部分数据

图1 三个属性组的仿真结果图
5.3 基于其他分类算法的研究
根据这八种分类器算法的分类结果做出定量与定性的分析,构建了对雾霾数据样本的分类混淆矩阵,矩阵的数据如表11~表13所示,表格中的每个元素均是实例的计数值,a和b的值代表平均能见度归一化之后的结果。从下列属性组中样本的分类结果分布情况上看,依照混淆矩阵的判别分类器分类效果方法,主对角线上的分类样本数目之和远大于副对角线上之和,因此采用这八种分类器是符合雾霾数据的特征,体现了设计算法的实效性,对属性组对雾霾天气的影响具有较高的支持作用。
针对600组雾霾数据,分成三个属性组进行分类算法的分析预测。每种算法的预测结果运用正确率和AUC数值进行评价。
对分类器的分类正确率和ROC曲线的线下面积分别进行了数据统计与分析。燃煤供暖、机动车尾气排放和参照组的正确率均值分别为84.2915、84.2075和79.2913;燃煤供暖、机动车尾气排放和参照组的AUC均值分别为0.8959、0.8898和0.8291。由数据可知燃煤供暖和机动车尾气排放这两个属性组的分类正确率和AUC数值大致相同,且都要大于参照组分类正确率和AUC数值,因此可得出燃煤供暖排放和机动车尾气排放这两个因素对雾霾天气有较大影响,并且作用大致相当。

表11 燃煤供暖属性组混淆矩阵数据

表12 汽车尾气属性组混淆矩阵数据

表13 参照组属性组混淆矩阵数据

表14 分类算法的评估结果

表15 分类器算法结果的统计分析
6 结束语
本方法选取与机动车尾气、供暖、天气相关的属性分别构成三个属性组,首先用BP神经网络作为分类器,通过交叉验证对雾霾天气进行预测,并构建出不同属性组的ROC曲线,对各属性组对分类的影响进行评估,然后用C4.5、RIPPER、k近邻、SVM、随机森林等多种分类算法进行分类预测,并对分类结果的正确率、ROC曲线面积等进行分析。通过数据挖掘方法,基于客观数据,对具有争议的污染因素:机动车尾气和燃煤供暖对雾霾的作用大小进行了定量分析。经过以上过程分析得出结论:北京市机动车尾气和燃煤供暖对雾霾天气的影响较大,且作用相当,可为相关部门政策的制定和雾霾的防治提供理论依据。
由于霾天气能见度的不仅仅与大气污染物有关,还受到某些气象条件的影响:例如,降雨降雪、大气压强、混合层高度;以及在光化学反应昼夜差异,大气上空流边界层发展的大气稳定性[9]等。未来工作中,会通过更全面地考虑影响因素来提高预测和分析的准确性。
[1] 艾洪福,石莹.基于BP神经网络的雾霾天气预测研究[J].计算机仿真,2015:01,32(1):402-405.
[2] 马楚焱,祖健,付清盼,罗凌霄.基于遗传神经网络模型的空气能见度预测[J].环境工程学报(2015)04:9(4):1905-1910.
[3] 侯琼煌,杨航.基于三次指数平滑模型的雾霾天气预测[J].环境保护科学(2014:40)06:73-77.
[4] 杨文光,林连海,田立勤.基于小波分析的雾霾天气分析与预测[J].2016:34,3:166-170.
[5] 付倩娆.基于多元线性回归的雾霾预测方法研究[J].2016,6:43(6A):526-528.
[6] 陈雯柏.人工神经网络原理与实践[M].西安电子科技大学出版社.
[7] 袁梅宇.数据挖掘与机器学习WEKA应用技术与实践[M].清华大学出版社.
[8] Pang-Ning Tan,Michael Steinbach,Vipin Kumar.数据挖掘导论[M].人民邮电出版社.
[9] 吕效谱,成海容,王祖武,张帆.中国大范围雾霾期间大气污染特征分析[J].湖南科技大学学报(自然科学版)2013:9,28(3):104-110.
Fog and haze forecasting and analysis based on data mining
CHEN Jia-hao1, LIU Jia2
TP29
:A
1009-0134(2017)06-0150-06
2017-05-27
国家自然科学基金(61501464)
陈嘉昊(1996 -),男,本科,研究方向为数据挖掘和模式识别。
猜你喜欢
中国特种设备安全(2022年1期)2022-04-26
计算机系统应用(2021年2期)2021-02-23
电子技术与软件工程(2019年18期)2019-11-18
电子制作(2019年24期)2019-02-23
消费导刊(2018年10期)2018-08-20
电子技术与软件工程(2017年14期)2017-09-08
船舶标准化工程师(2015年5期)2015-12-03
汽车维护与修理(2015年5期)2015-02-28
汽车维护与修理(2015年1期)2015-02-28
航天返回与遥感(2014年5期)2014-07-31
