
一种用于微信信息分类的改进贝叶斯算法
2017-09-18 02:31张颖江库凯琳
湖北工业大学学报 2017年4期
张颖江,库凯琳
一种用于微信信息分类的改进贝叶斯算法
张颖江,库凯琳
(湖北工业大学计算机学院,湖北武汉430068)
微信的快速普及加快了信息的传播,随之而来的广告、诈骗等信息严重困扰人们的生活。针对朴素贝叶斯对信息分类时考虑所有特征并将特征赋予相同权值两方面的缺陷,提出一种用于微信信息分类的改进贝叶斯算法。采用改进的互信息进行特征选择,提取关键特征,通过改进TFIDF对特征加权,优化朴素贝叶斯的分类性能。实验结果表明,改进的贝叶斯算法能有效选择关键特征属性,提高微信信息分类的精准度。
贝叶斯;微信信息;特征提取;特征加权;信息分类
随着微信已成为人们日常交流和沟通的一种重要方式,微信平台的信息安全问题急需解决。目前对微信信息的监管主要是通过设置黑名单的形式,即大量收集传播垃圾信息的微信用户ID,并将其加入黑名单来阻断信息的传播。但由于微信用户量大,增长速度快等特点,传统的设置黑名单的方式很难从源头上杜绝垃圾信息的产生。并且实施周期长,工作量大,效果显微。
微信信息的处理本质上是对文本信息的处理。常见的文本分类器包括决策树(Decision Tree)[1]分类器、朴素贝叶斯(Naive Bayesian)[2]分类器、支持向量机(Support Vector Machine)[3]等。朴素贝叶斯分类器具有训练和分类速度快的特点,许多学者对其进行深入研究并提出了一些改进方法。邓桂骞提出一种条件属性相对于决策属性的相关性和重要性的属性权值计算方法[4];李静梅提出一种通过EM算法(期望值最大算法),自动增加训练量,得到较为完备的训练库,提高朴素贝叶斯的分类精度[5];赵文涛,孟令军等人针对朴素贝叶斯算法下溢问题,对算法基本公式进行优化改进,提出一种新的CITNB算法并通过实验验证其分类性能远优于朴素贝叶斯分类器[6],以上改进方法都是针对朴素贝叶斯属性权值相同进行的改进。
针对朴素贝叶斯属性选择和属性加权两方面的缺陷,提出采用互信息对文本特征属性进行选择,并针对传统互信息的缺陷提出改进措施,对选取的特征属性采用改进的TF-IDF加权[7],将改进后的贝叶斯算法用于微信信息分类。与传统贝叶斯算法、基于TF-IDF的朴素贝叶斯算法相比,该算法在查准率和查全率方面都有显著提升。
1 朴素贝叶斯分类
朴素贝叶斯(NB)分类是一种十分简单的分类算法,其基本思想可概括为:对给出的待分类项,求解出在该分类项出现的情况下各类别出现的概率,并认为该分类项属于类别中概率最大的类,朴素贝叶斯有如下定义:
设A={a1,a2,a3,…,am}为一个待分类样本,每个ai为A的一个特征属性。有类别集合B={b1,b2,b3,…,bn},计算p(b1|a),p(b2|a),p(b3|a),p(b4|a),如果

则a∈bk。根据贝叶斯定理:
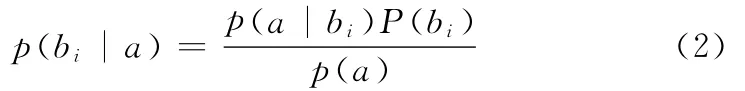
p(a)对所有类均为常数,最大化后验概率p(bi|a)可转化为最大化先验概率p(a|bi)P(bi)。若训练数据集有许多属性和元组,假设各属性相对类别条件独立,即:为避免(3)式中出现乘积为0的结果,需要对公式进行平滑处理,常用的方法是对式(3)进行拉普拉斯平滑:
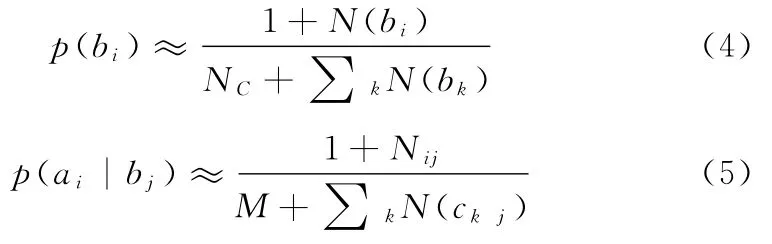
其中:N(bi)表示bi的文档个数,∑kN(bk)表示集中文档总个数,Nij表示特征属性ai在类别bj的文档中出现的次数,M表示特征词个数,∑kN(ckj)表示bj类中所有词出现的次数。
计算过程中由于p(ai|bj)、p(bi)的值都很小,两者相乘的结果偏小会导致精度下降,常用的做法是取对数进行运算,可减少计算开销并提高了计算结果的精度。
朴素贝叶斯在分类时有两个条件较为苛刻:(1)条件独立性假设:NB分类假设样本各特征之间相互独立,该假设在实际应用中往往是不成立的,从而影响了分类的正确性。(2)各属性权值都设为1:NB分类算法认为样本各属性具有相同的权值,但是在实际分类中,不同类别的样本属性出现的概率并不相同,将所有属性的权值设为1,影响NB算法的精准性。本文针对以上NB算法的局限性提出一种改进的贝叶斯算法用于微信信息的分类,并将实验结果进行对比,给出结论。
2 改进的贝叶斯算法
2.1 特征提取
微信信息可看作为文本特征向量,原始的特征向量空间由出现在微信信息中的所有词组成,如果将出现的所有词都作为特征向量的话,那么特征向量空间通常会维度过高,若直接对这种高维度的样本空间进行训练和分类,需要很大的计算开销,且无用的特征信息参与计算会导致分类不精准。通常在对样本进行训练前,在不影响分类精准性的前提下尽可能剔除无用的特征属性,这个过程称为降维。在特征提取前,首先对特征向量空间人工降维,去掉一些常用的数词、量词、语气词等,这类词对分类结果没有影响,但是会造成很大的计算开销。
本文采用MI互信息(Mutual Information)[8]进行特征提取,MI计算词元ai与类别bi之间的相关度作为特征提取的标准,定义如下:

其中p(a)为单词出现的概率,p(bi)为类别bi出现的概率,p(a∩bi)为两者同时出现的概率。式(6)可简化为:
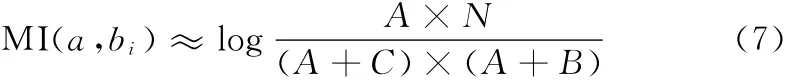
N表示训练集中样本总数,A表示词元a与类别bi同时出现的次数,B为词元a出现类bi不出现的次数,C为类bi出现但词元a不出现的次数,式(7)表示的词a与各类别bi之间的互信息。
若存在m个类别,则特征项a与m个类别分别有m个互信息,常用的方法是求平均互信息,平均互信息的计算公式为:
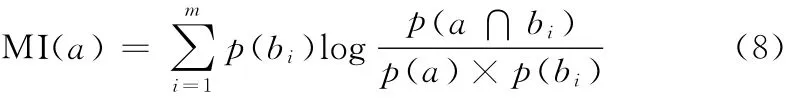
传统互信息在特征提取时,有两个突出的缺陷:(1)不考虑词频,更趋向于低频词汇;(2)忽略负相关特征,特征与类别的负相关部分会导致该特征的权值降低[8]。针对以上两个缺陷带来的分类性能较低的问题,本文采用改进的互信息进行特征提取。
首先,在特征提取时考虑词频信息。一般认为:词频越高、集中度越强的词对文本分类作用越大,而传统互信息在进行特征选择时通常是词频较小的词获得较大的互信息,与实际预期的情况不符,因此将词频、集中度等因素考虑进去采用改进的互信息进行特征提取。为此引入特征词a对于类别bi的先验概率p(a|bi),表示特征词a在bi中出现的频度,其参数公式表示为X=p(a|bi),同时引入后验概率p(bi|a),表示特征词a出现同时又属于类别bi的概率来表示其集中度,其参数公式表示为:
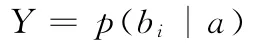
其次,在计算互信息时会出现负数的情况,特征项a与类别b不相关时,互信息为0,当特征项a在类别b中很少出现时,互信息为负值,这称为特征项a与类别b负相关。在计算中负相关会降低分类效果,但在实际情况中,一个特征若出现在少数类别中,这对分类具有较大的区分性。分析式(6)可知,在p(a∩bi)较小而p(a)较大时,MI(a)取值为负,且MI(a)的值随p(a)变大及p(a∩bi)变小而变小,但在实际情况中,特征a的区分性随着p(a)变大及p(a∩bi)变小而变大。针对此情况,本文对互信息取绝对值进行计算,该做法相对更为合理。综合传统互信息提取特征的缺陷来考虑,本文提出一种改进的互信息方案来提取特征,新的互信息计算公式可以表示为:

通过限定阈值,就可以对互信息选取特征的缺陷进行很好地补充。
2.2 特征加权
传统贝叶斯算法中认为所有的特征属性具有相同的权值(即将所有的属性权值设为1),但在实际应用中,应赋予特征属性不同的权值。如果某个特征在某个文本中重复出现,而在别的文本中很少出现,就可以认为该特征具有较好的区分性,应赋予其较大的权值。特征权值的计算方法有很多,词频权值、布尔权值、TFIDF都是常用的计算权值的方法[9]。TFIDF[10]用词频乘以逆文档来表示特征项的权值。TF表示特征项t在文档d中出现的频率,IDF表示特征项t在整个文档集中的分布量化[11]。TFIDF公式:
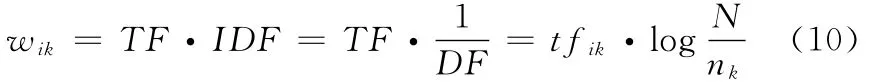
其中,wik表示文档i中第K维的向量值,tfik表示文档i中第K个特征值的TF值,N表示文本集的文档数,nk表示文本集中出现该特征项的文本数。将TFIDF归一化后得
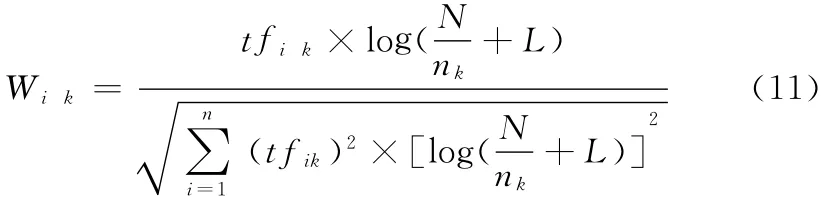
TFIDF的局限性表现在:若某一特征在某一类别文档中大量出现,而在其他类别文档中很少出现,或者某个特征只在某一类别的少量文档中大量出现而在别的文档中很少出现,这样的特征应该具有很好的区分性,应该赋予较大的权值,但实际上在式(11)中却不能体现出来,相反IDF更趋向于赋予少量出现的特征较大的权值,这与实际情况并不相符。TFIDF考虑特征与文档之间的信息,而忽略特征与类别的关系。为此,本文将特征的类别信息考虑进TFIDF进行特征加权,提出一种信息特征加权函数TFIDF*。改进的TFIDF*函数引入特征类函数K,其中

该函数考虑词条i在某一具体类中的文档出现的概率。改进的TFIDF*函数定义如下:
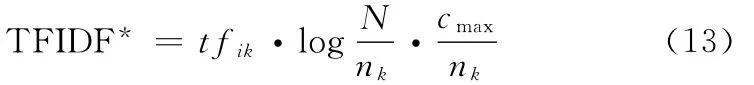
式中,nk表示包含词条i的文档总数,cmax表示包含特征i最多的类中文档数量。特征类函数设计的思想就是将特征与文本类别结合考虑,弥补TFIDF只考虑文本特征与数量的不足。如果特征在某一类文本中出现的次数较多,那该特征就可以很好地代表该类别,该类加权的结果值就大,因此,特征i在某一类中越重要,特征类函数权值也就越大。
3 实验结果与分析
为验证改进算法的可行性和有效性,设计实验采用本文改进的互信息对特征属性进行选择,并对选择后的特征采用改进TF-IDF赋予不同权值,通过贝叶斯公式计算概率得到最终的分类结果。实验数据集主要采用python网络爬虫和人工搜索的方式收集。数据来源是一些微信公众号推送的消息,共收集测试信息包含体育、健康、教育、科技、军事、文化等6类信息共2264条,采用其中的1509条作为训练集,其余的755条作为测试集用于测试。各信息分布情况见表1。
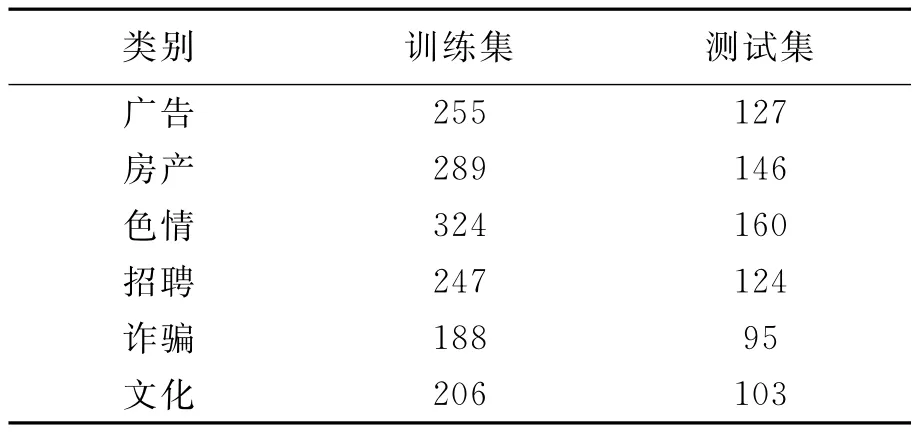
表1 数据集
本文采用查全率R和查准率P作为评测指标,计算公式如下:

查全率和查准率从两个不同方面反映了分类器的性能。

图2 查准率
从图1和图2的测试结果中可以看出:采用朴素贝叶斯对样本进行分类,其分类效果明显低于改进后的贝叶斯的性能。分析可知其原因主要有以下几个方面:本文在朴素贝叶斯分类的时候采用的是未改进的互信息方法挑选特征值,同时采用朴素贝叶斯的思想,认为所有的属性权值相同,全部设为1,导致其分类结果不尽人意,而本文提出的改进的贝叶斯采用改进的互信息提取特征,考虑互信息的负相关影响,将词频因素考虑进特征提取,同时使用改进的TFIDF对提取出的特征加权,从测试结果可以看出分类性能高于改进之前。
为验证本文提出的改进贝叶斯算法的稳健性,采用不同数量的训练集作为样本进行训练,观察训练样本数量对分类准确性的影响,实验结果见图3。
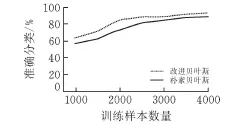
图3 样本数量对分类结果的影响
从图3可以看出,随着训练样本的不断增加,改进的贝叶斯分类器趋于稳定,并保持较高的分类性能。而朴素贝叶斯分类器在训练样本增加之后性能也得到提高,但整体分类性能没有改进贝叶斯分类性能高。可以看出,朴素贝叶斯在大样本训练集中具有较好的分类性能。而改进贝叶斯在小样本区间也具有较好的分类性能。
4 结语与展望
采用改进的贝叶斯分类器对微信信息进行分类,使用改进的互信息提取特征,然后使用改进的TFIDF对特征进行加权,最终较朴素贝叶斯取得了更好的分类效果。改进的贝叶斯算法在小样本区间也表现出较好的分类性能,可以将本方法及后续改进方法用于垃圾邮件检测和入侵检测系统中。
[1] Carreras X,Marquez L.Boosting trees for anti-spam email filtering[J].2001,3(4):1306-1311.
[2] Androutsopoulos I,Koutsias J,Chandrinos K V,et al.An evaluation of naive bayesian anti-spam filtering[J].Tetsu-to-Hagane,2000,cs.cl/0006013(2):9-17.
[3] Cortes C,Vapnik V.Support vector networks[J].Machine Learning.1995,20(1):273-329.
[4] 邓桂骞,赵跃龙.一种优化的贝叶斯分类算法[J].计算机测量与控制,2012,20(1):199-202.
[5] 李静梅,孙丽华.一种文本处理中的朴素贝叶斯分类器[J].哈尔滨工程大学学报,2003,24(1):71-74.
[6] 赵文涛,孟令军.朴素贝叶斯算法的改进与应用[J].测控技术,2016,35(2):143-147.
[7] Salton G,Yu C T.On the construction of effective vocabularies for information retrieval[J].Acm Sigplan Notices,1973,10(1):48-60.
[8] Zheng Z,Wu X,Srihari R.Feature selection for text categorization on imbalanced data.[C]//Acm Sigkdd Explorations Newsletter,1931:80-89.
[9] 张保富,施化吉,马素琴.基于TFIDF文本特征加权方法的改进研究[J].计算机应用软件,2011,28(2):17-20.
[10]Salton G,Introduction to Modern Information Retriveval[M].New York:McGraw Hill Book Company,1983.
[11]鲁松,李晓黎,白硕.文档中词语权重计算方法的改进[J].中文信息学报,2000,14(6):8-20.
[12]施聪莺,徐朝军,杨晓江.TFIDF算法研究综述[J].计算机应用,2009(29):167-180.
An Optimized Bayesian Classification Algorithm for WeChat Information
ZHANG Yingjiang,KU Kailin
(School of Computer Science,Hubei Univ.of Tech.,Wuhan 430000,China)
The prevalence and development of WeChat has facilitated the dissemination of information.However,it also comes with advertising and fraudulent information,which brings a lot of troubles to people’s lives.For the two important factors that naive bayes considering all the features and characteristics are given the same weight.We put forward an improved bayes algorithm.Selecting features by improved mutual information and weighting by improved TFIDF to optimize the bayesian classification performance.Experimental results show that the improved bayes algorithm can effectively select key features and improved classification precision
bayes;WeChat information;feature extraction;feature weighting;information classification
TP391.1
A
[责任编校:张岩芳]
1003-4684(2017)04-0051-04
2016-06-06
张颖江(1959-),男,北京人,湖北工业大学教授,研究方向为计算机网络安全
库凯琳(1991-),男,湖北黄冈人,湖北工业大学硕士研究生,研究方向为信息处理与网络安全
猜你喜欢
小资CHIC!ELEGANCE(2021年36期)2021-10-15
法律方法(2021年4期)2021-03-16
四川文学(2020年11期)2020-02-06
当代陕西(2019年23期)2020-01-06
当代陕西(2019年9期)2019-05-20
计算机应用(2016年10期)2017-05-12
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西北工业大学学报(2015年4期)2016-01-19
弹箭与制导学报(2015年1期)2015-03-11
