
Enriching Basic Features via Multilayer Bag-of-words Binding for Chinese Question Classification
2017-10-10 03:27SichunYangandChaoGao
Sichun Yang and Chao Gao
EnrichingBasicFeaturesviaMultilayerBag-of-wordsBindingforChineseQuestionClassification
Sichun Yang and Chao Gao*
Question classification helps to generate more accurate answers in question answering system. For an efficient question classifier, one of the most important tasks is to fully mine useful features. Aiming at solving the problem of lacking of rich syntax and semantic features in Chinese question classification, an operator called MBWB(Multilayer Bag-of-Words Binding) is proposed to extract potential features by binding part-of-speech, word sense, named entity and other basic features to bag-of-words respectively. Through performing MBWB operator on two kinds of bag-of-words i.e. A_BOW and T_BOW, the corresponding A_MBWB and T_MBWB features are generated automatically. The MBWB operator can explore potential information contained in basic features, and enrich syntactic and semantic representation of questions. Experimental results on the Chinese question set show that the classification accuracy gets significantly improved when combining two kinds of MBWB features with basic features.
question answering system; question classification; A_MBWB feature; T_MBWB feature
1 Introduction
Question answering (QA) is a popular research direction in natural language processing (NLP) and information retrieval (IR), which allows users to ask in the form of natural language and returns an accurate, concise answer. Generally speaking, a QA system usually consists of three important processing modules including question analysis, passage retrieval and answer extraction. As the first step of question analysis, question classification is the task of classifying questions into corresponding semantic categories according to the types of the expected answers. Question classification plays an important role in semantic constraints for subsequent answer extraction, by making the answer candidates only belong to particular semantic categories[1]. Take the following question as an example: “安徽省的省会在哪里?” (WhereisthecapitalofAnhuiProvince?), the question expects a city name as an answer, if learn that the intention of this question is to ask location (LOC), one will quickly find its answer. The accuracy of question classification can directly impact the performance of QA system, some previous research shows that 36.4% of wrong answers are caused by errors in question classification[2].
In earlier research on question classification, the method based on hand-crafted rules was widely used[3,4], but its shortcoming of this method is that laborious human effort is required to create these rules. Existing literatures mainly employed machine learning methods to classify questions and its key to constructing an efficient question classifier is fully mining useful features. In English question classification[5-15], (Li,2002) chose lexical words, part of speech tags, chunks, head chunks, named entities and class-specific related words as features, and achieved the accuracy of 84.2% for UIUC fine grained classes. Later, (Li,2006) used more semantic information sources including WordNet senses and distributional similarity based categories, and reached the accuracy of 86.2%. (Huang,2008)chose wh-word, unigram, word shape, head words and their hypernyms in WordNet as features, and obtained the accuracy of 89.2% for UIUC fine grained classes. (Silva,2011) chose unigram, head words and their hypernyms in WordNet as features, and obtained the accuracy of 90.8% for UIUC fine grained classes. (Loni,2012) chose unigram, bigram, word shape, related words, head words and their hypernyms in WordNet as features, and obtained the accuracy of 89% for UIUC fine grained classes. With these features, they all obtained better classification results.
In Chinese question classification[16-24], lexical semantic features and structural features are the guarantee of high performance of question classification. However, due to the fact that the current Chinese NLP technology is not as mature as the English NLP technology, compared with English question classification, it’s quite difficult to extract more effect features for Chinese question classification, and as a result, the accuracy of Chinese question classification is much lower than that of English question classification. So it is appropriate to find an alternative solution to this problem.
By making a deep insight into existing research for Chinese question classification, to find those features was used only as independent templates when constructing feature vectors, the semantic relation among features was less considered, and thus affected the accuracy of question classification. In fact, each feature with its corresponding word can be regarded as a whole to form a class of new features, and add them to the original feature vector to enhance the performance of question classification. In this paper, an operator called MBWB (Multilayer Bag-of-Words Binding) is proposed to bind part-of-speech, word sense and other basic features to bag-of-words respectively. The MBWB operator can mine potential information contained in basic features, and enrich syntactic and semantic representation of questions. Moreover, since these potential features are extracted by a simple MBWB operator, the problem of existing methods, i.e. the difficulty to extract more effective features because of the limitation of Chinese NLP technology, can also be effectively alleviated. Experimental results on Chinese question set show that the accuracy of question classification gets significantly improved when combining two kinds of MBWB features with basic features.
The rest of this paper is organized as follows. Section 2 lists some basic features for Chinese question classification, Section 3 introduces two kinds of MBWB features i.e. A_MBWB features and T_MBWB features respectively. Section 4 describes feature a combination of two kinds of MBWB features with basic features. Section 5 presents the experimental results and analysis. Section 6 concludes the paper and provides some future work.
2 Basic Features
Take the question “从中国境内流入印度洋的河流有哪些?”(WhataretheriversfromtheterritoryofChinaintotheIndianOcean?) as an example, the analysis result of the sample question is demonstrated in Fig.1. Here, an open and free available Chinese language technology platform LTP 2.0(http://ir.hit.edu.cn/demo/ltp) provided by the IRSC lab of Harbin Institute of Technology in China was used to perform word segmentation, part-of-speech tagging, named entities recognition, word sense disambiguation and dependency parsing.
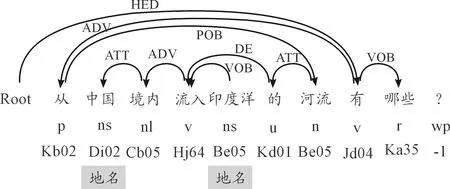
Fig.1 Analysis result of the sample question.
The feature vector of the sample question is demonstrated in Fig.2. It contains four feature templates i.e. bag-of-words (BOW), part-of-speech (POS), name entity (NE), word sense (WS) and dependency relation (DR). However, these feature templates are independent in the feature vector, and the semantic relationship between BOW and other basic features is ignored. In fact, from the view of semantic representation, POS, WS and NE features all actually correspond to the words in a question. So it is more intuitive and natural to regard these semantic relation as another important potential features.
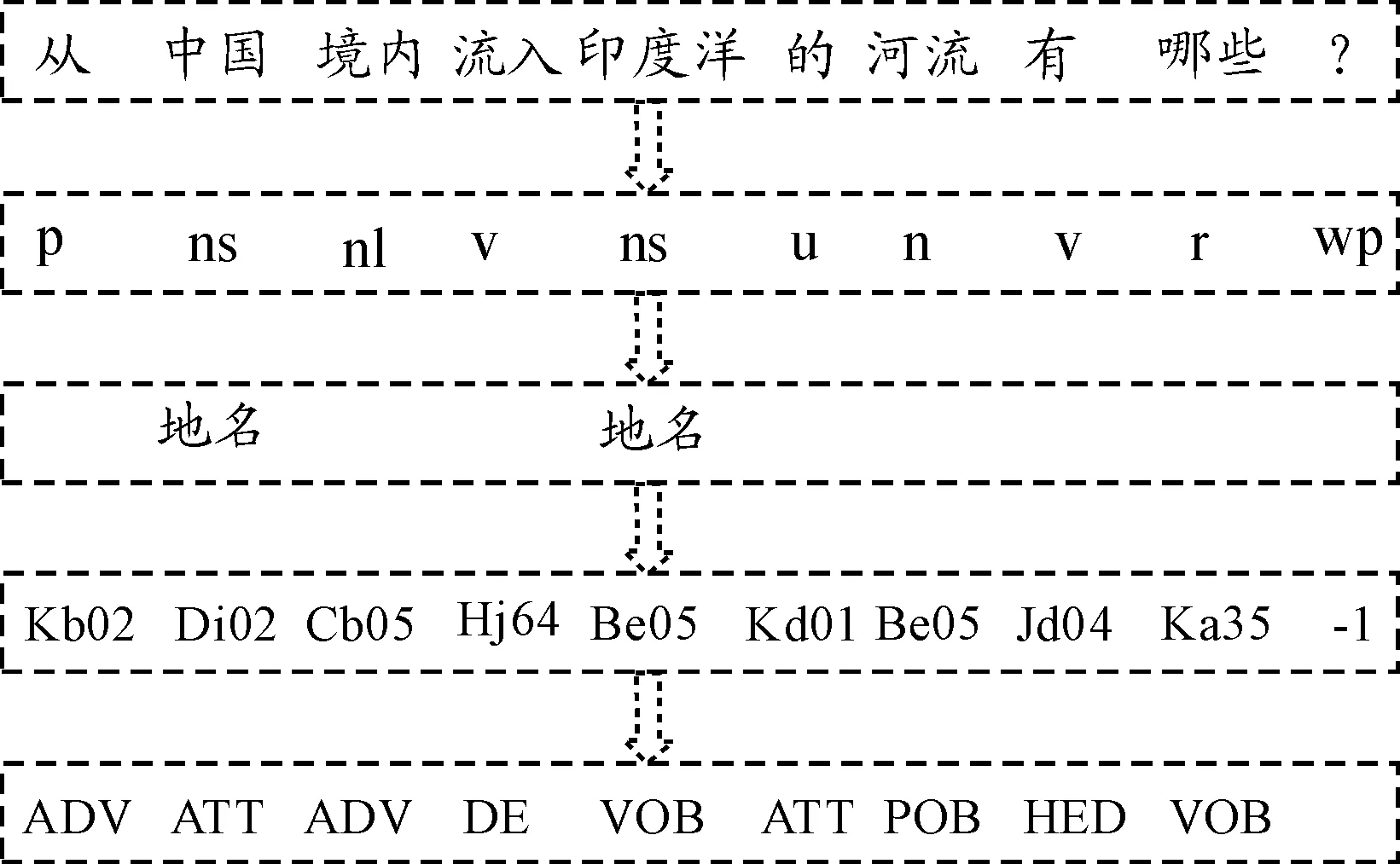
Fig.2 Basic features of the sample question.
3 MBWB Features
3.1 MBWB operator
Definition1(All_bag-of-words,A_BOW) An ordinary BOW which consists of all words in a question.
Definition2(Multilayerbag-of-wordsbinding,MBWB) An operator which is used to bind part-of-speech, word sense, named entity and other basic features to bag-of-words respectively.
When using the MBWB operator to bind basic features such as POS, WS and NE to BOW, a class of new features of the sample question is demonstrated in Fig. 3(a)~ 3(d).

Fig.3(a) Binding POS to BOW.

Fig.3(b) Binding NE to BOW.

Fig.3(c) Binding WS to BOW.

Fig.3(d) Binding DR to BOW.
It can be seen that the number of the values of new features is greater than that of original features. For example, when bound to BOW, the new POS feature has 10 values, while the original POS feature has 8 values. Similarly, the new NE feature has 2 values, while the original NE feature has 1 value. In the feature vector, the dimension space of new features will increase more significantly. In particular, when bound to BOW, the dimensions of POS and NE features both change from dozens to thousands. With these features added to the original feature vector, the set of features are much richer and more effective, and expect to enhance the performance of question classification.
3.2 A_MBWB features
Definition3(A_MBWBfeature) A feature generated by binding part-of-speech, word sense, named entity and other basic features to A_BOW respectively.
In the following, use LTP platform to perform word segmentation, part-of-speech tagging, named entity recognition, word sense disambiguation and dependency parsing. BOW, POS, NE, WS, WS’, DR and CW are extracted as basic features. Here, the WS’ feature is the 3-layer i.e. coarse, medium and fine grained word sense coding in semantic dictionary “TongYiCiCiLin” while WS is the 2-layer i.e. coarse and medium grained one, the DR feature is the dependency relation, the CW feature is the core word which is at the start of dependency arc.
By applying the MBWB operator on A_BOW, POS, NE, WS, WS’, DR and CW are bound to A_BOW respectively to generate a class of new features i.e. A_MBWB features, and mark it A/F1/…/Fn. Table 1 lists 1-layer A_MBWB features and their values of the sample question.
In this paper, A_MBWB features are generated by binding some basic features to A_BOW feature. Considering that exhaustive method will lead to generate a large number of A_MBWB features, and bring a lot of inconvenience to the subsequent feature combination, a heuristic method is presented to generate A_MBWB features. Algorithm 1 gives the implement of A_MBWB feature generation.

Algorithm1 A_MBWBfeaturegenerationalgo-rithmInput:A_BOWandotherbasicfeaturesOutput:A_MBWBfeatures(1)Takeallbasicfeatures(exceptforBOW)asF;(2)TakeallcandidatefeaturesasCands;(3)Cands=F;(4)fori=1to|Cands| //1-layerA_MBWBfeatures BindFitoA_BOWtoformA/Fi; i=i+1; (5)findthe1-layerA_MBWBfeatureA/FjwhoseaccuracyishigherthanthatofA_BOW;(6)Cands=F-Fj;(7)fori=1to|Cands| //2-layerA_MBWBfeatures BindFitoA_BOWtoformA/Fj; i=i+1; (8)findthe1-layerA_MBWBfeatureA/FjwhoseaccuracyishigherthanthatofA_BOW;(9)Cands=F-Fj;(10)Repeatabovestepsuntilthemaximumaccu-racyof(n+1)-layerA_MBWBfeaturesisnolon-gerhigherthanthatofn-layerones. //n-layerA_MBWBfeatures

Table1 1-layer MBWB feature.
3.3 T_MBWB features
3.3.1 Trunk words
The above MBWB features are generated by performing the MBWB operator on A_BOW, considering some words may bring noise to a question classifier, we further perform the MBWB operator on another BOW i.e. T_BOW.
Definition4(Trunk_bag-of-words,T_BOW) Another BOW which consists of trunk words in a question.
In this paper, we define trunk words as those words, including head word (HED), subject (SBJ), object (OBJ), question word (QW) and question-related word (QRW). The definition of each trunk word is as follows.
Definition5(headword,HED) In a dep_tree of question Q, the word at the end of the dependency arc HED is called HED_word.
Definition6(subjectword,SBJ) In a dep_tree of question Q, the word at the end of the dependency arc SBV or POB is called SBJ_word.
Definition7(objectword,OBJ) In a dep_tree of question Q, the word at the end of the arc VOB or POB is called OBJ_word.
Definition8(questionword,QW) In a dep_tree of question Q, the question word is called Que_word.
Definition9(question-relatedword,QRW) In a dep_tree of question Q, the word which has an arc with QW is called Que_rel_word.
Definition10(trunkword,TW) TW is the collection of HED,SBJ, OBJ,QW and QRW in question Q.
Here, the definitions of HED, SBJ, OBJ, QW and QRW are similar to those proposed by (Wen,2006). The difference is that the prepositional object(POB) may serve as the subject or object when defining SBJ and OBJ. For example, “河流” which is the POB of the sample question, actually serves as the SBJ.
3.3.2 Trunk words extraction
For the extraction of HED, SBJ, OBJ, QW and QRW from a question, it mainly follows the method proposed by (Wen,2006)[20], but we do some modification when extracting HED, SBJ and OBJ, the detailed processing rules are as follows.
(1) If wordxpointed by HED draws forth several continuous SBV arcs, then wordypointed by each SBV is added to SBJ.
(2) If wordxpointed by HED draws forth several continuous VOB arcs, then wordypointed by each VOB is added to OBJ.
(3) If wordxpointed by HED points draws forth several parallel SBV arcs, then wordypointed by SBV nearest to HED is added to SBJ.
(4) If wordxpointed by HED draws forth several parallel VOB arcs, then wordypointed by VOB far away from HED is added to OBJ.
(5) If wordxpointed by HED draws forth an IC arc, then wordypointed by IC is added to HED, and wordzpointed by SBV/VOB which begins atyis added to SBJ/OBJ.
(6) If wordxpointed by HED draws forth a VV arc, then wordypointed by VV is added to HED, and wordzpointed by SBV/VOB which begins atyis added to SBJ/OBJ.
(7) If wordxpointed by SBV/VOB draws forth a COO arc, then word y pointed by COO arc is added to SBJ/OBJ.
Algorithm 2 gives the implement of trunk words extraction.

Algorithm2 TrunkwordsextractionalgorithmInput:aquestionWOutput:alltrunkwords(1)fori=1to|W| ifawordW(i)ispointedbyHEDarc,thenW(i)isaddedtoHed_word; i=i+1;(3)W=W-Hed_word;(4)fori=1to|W| iftheHEDworddrawsforthseveralcontinu-ousSBVarcs,thenawordpointedbyeachSBVarcisaddedtoSBJ_words; iftheHEDworddrawsforthseveralcontinu-ousVOBarcs,thenawordpointedbyeachVOBisaddedtoOBJ_words; iftheHEDworddrawsforthseveralparallelSBVarcs,thenawordpointedbySBVnearesttoHEDisaddedtoSBJ_words; iftheHEDworddrawsforthseveralparallelVOBarcs,thenawordpointedbyVOBfarawayfromHEDisaddedtoOBJ_words iftheHEDworddrawsforthanICarc,thenthewordpointedbythisICisaddedtoHED,andanotherwordpointedbySBV/VOBwhichbeginsatW(j)isaddedtoSBJ/OBJ_words; iftheHEDworddrawsforthaVVarc,thenthewordpointedbythisVVisaddedtoHED,andanotherwordpointedbySBV/VOBwhichbe-ginsatW(j)isaddedtoSBJ/OBJ_words; ifW(i)pointedbySBV/VOBdrawsforthaCOOarc,thenthewordpointedbythisCOOarcisaddedtoSBJ/OBJ_words; ifthepartofspeechofW(i)is‘r’thenaddittoQus_words,andadditsdependencywordtoDep_rel_words; i=i+1;(5)OutputHed_word,SBJ_words,OBJ_words,Qus_words,Que_rel_words.
3.3.3 T_MBWB features
Definition11(T_MBWBfeature) A feature generated by binding part-of-speech, word sense, named entity and other basic features to T_BOW respectively.
The T_MBWB features generated by binding basic features to trunk words in a question, are similar to generating A_MBWB features. The T_MBWB feature is marked asT/F1/…/Fn. Table 2 lists all 1-layer T_MBWB features and their values of the sample question.

Table2 1-layer T_MBWB feature.
4 Combining basic features with MBWB features
In order to further improve the performance of question classification, we combine all A_MBWB features and T_MBWB features with basic features. Here, a heuristic method[21]is used to combine A_MBWB and T_MBWB features with all basic features(marked asBase). In the first round, combine each candidate feature withBase, and mark the feature combination with the highest accuracy in current round asBase1. In the second round, each candidate feature from the rest features is combined withBase1, and marks the feature combination with the highest accuracy in current round asBase2; Repeat above steps until the accuracies of all feature combinations in current round are no longer higher than the highest in previous round, or no candidate feature is available to be combined.
Algorithm 3 gives the implement of feature combination.

Algorithm3 FeaturescombinationalgorithmInput:basicfeatures,A_MBWBfeaturesandT_MBWBfeaturesOutput:finalfeaturecombination(1)TakeallbasicfeaturesasBase;(2)TakeallA_MBWBandT_MBWBfeaturesasCands;(3)fori=1to|Cands| combineCands(i)withBase; i=i+1;(4)TakethefeaturecombinationwiththehighestaccuracyasBase1;(5)Cands=Cands-(Base1-Base);(6)fori=1to|Cands| combineCands(i)withBase1; i=i+1;(7)TakethefeaturecombinationwiththehighestaccuracyasBase2;(8)Cands=Cands-(Base2-Base1);(9)Repeatabovestepsuntilnohigherfeaturecombination,ornocandidatefeature.(10)Outputthefinalfeaturecombination.
5 Experiment Results and Analysis
Our experiments focus on (1) testing the classification performance of basic features and their MBWB features (A_MBWB features and T_MBWB features) for fine classes, and (2) comparing the contribution of different A_MBWB features and T_MBWB features when combined with basic features.
Three experiments are conducted for the above purposes. The first evaluates the accuracies of basic features for fine classes. The second evaluates the accuracies of A_MBWB features and T_MBWB features for fine classes. The third evaluates the contribution of different A_MBWB features and T_MBWB features when combined with basic features.
We use the open and free available Chinese question dataset provided by IRSClab of HIT, which consists of 6266 questions (4966 training questions and 1300 test questions) belonging to 6 coarse classes and 77 fine classes.
The open and free available Liblinear-1.4 (http://www. csie.ntu.edu.tw/~cjlin/liblinear/) tool is used to be the classifier in our experiment. The parameters for Liblinear-1.4 classifier are all with the default values, and conduct 10-fold cross validation to evaluate the performance of question classification under fine classes, in terms of accuracy which is defined as follow.

(1)
5.1 Accuracies of basic features
Before training and test, word segmentation, part-of-speech tagging, named entities recognization, and word sense disambiguation, dependency parsing for all questions will be performed with LTP platform, and A_BOW, POS, WS, WS’, NE, DR, CW and T_BOW are extracted as basic features. Table 3 shows the accuracies of individual basic features.
It can be seen that the accuracies of POS, NE, and DR features are very low, which indicates that they all have little contribution to question classification. In addition, T_BOW gets the accuracy of 72.9492% which is 1.0292 percentage points higher than that achieved by (Wen,2006), showing that our improved method is effective for the extraction of SBV and VOB.

Table 3 Accuracies of basic features (%).
5.2AccuraciesofA_MBWBandT_MBWBfeatures
Table 4~Table 5 list all A_MBWB features, T_MBWB features and their accuracies, where the accuracy in bold represents the maximum of n-layer A_MBWB or T_MBWB feature, and the one in bold with underline denotes the maximum of all combinations.
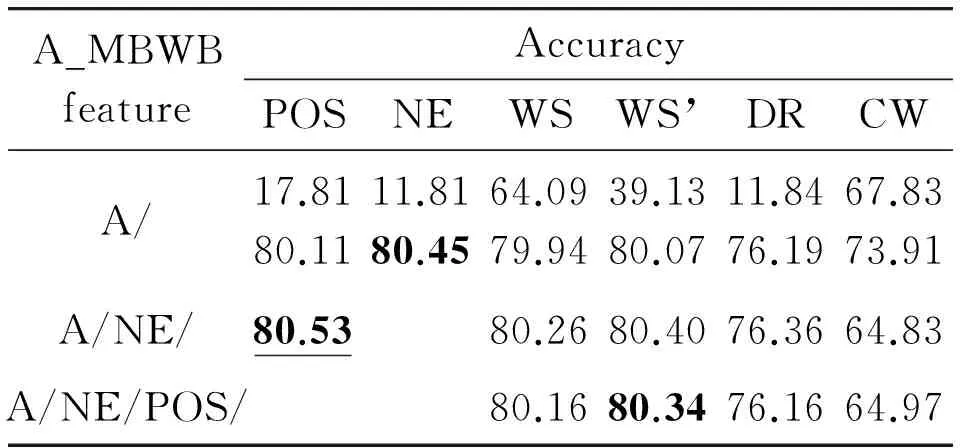
Table 4 Accuracies of A_MBWB features (%).
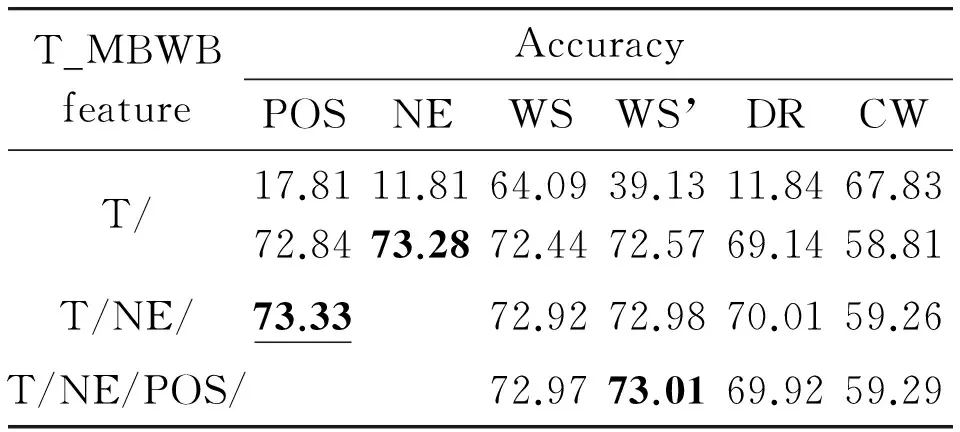
Table 5 Accuracies of T_MBWB features (%).
It can be seen that most A_MBWB features and T_MBWB features have much higher accuracies than the original basic features. The reason is that A_MBWB features and T_MBWB features carry more syntactic and semantic information than basic features, and thus have better ability of classification. In addition, all A_MBWB features have significantly higher accuracies than T_MBWB features, this is because T_BOW contains fewer words than A_BOW, and the dimension space of T_MBWB features is lower than that of A_MBWB features.
5.3CombineA_MBWBandT_MBWBfeatureswithbasicfeatures
In the following, based on individual feature contribution, A_MBWB features and T_MBWB features with basic features were combined to verify their contribution to question classification.The accuracies of feature combinations in each round are given in Fig.4(a)~Fig.4(e). Considering the length of paper, the accuracy of combining A_MBWB feature or T_MBWB feature in each round is listed in the same figure.

Fig.4(a)CombineA_MBWB/T_MBWBfeaturewithBase.
It can be seen that all accuracies of feature combinations in each round are higher than that ofBase, and most feature combinations are more than 1 percentage points higher thanBase. This is because combining more A_MBWB features and T_MBWB features can contribute to question classification from different syntactic and semantic levels. So we can draw a conclusion that combining A_MBW features and T_MBWB features with basic features can significantly improve the performance of question classification.

Fig.4(b)CombineA_MBWB/T_MBWBfeaturewithBase1.
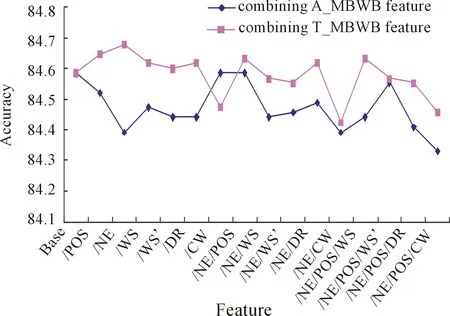
Fig.4(c)CombineA_MBWB/T_MBWBfeaturewithBase2.
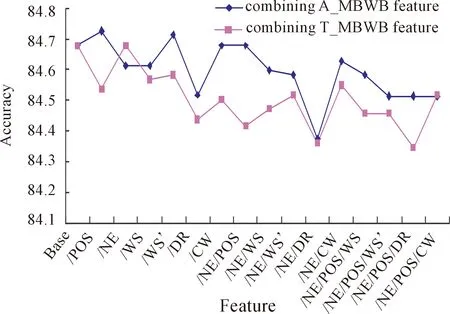
Fig.4(d)CombineA_MBWB/T_MBWBfeaturewithBase3.

Fig.4(e)CombineA_MBWB/T_MBWBfeaturewithBase4.
We also conduct the accuracy comparison with its baseline in each round. In Fig.4(a), the accuracies of all feature combinations are higher than that ofBase. In Fig.4(b), there are three feature combinations whose accuracies are lower than that ofBase1. In Fig.4(c) and Fig.4(d), there are much more feature combinations whose accuracies are lower than that ofBase2 andBase3 respectively. In Fig.4(e), the accuracies of all feature combinations are lower than that ofBase4. It is not surprising that the diversity among features decreases gradually when combining more A_MBWB features and T_MBWB features, and then makes the inhibitory among features more obvious.
In addition, the accuracy of combining A_MBWB feature or T_MBWB feature is compared in each round. In rounds 1, 3 and 5,the accuracy of combining A_MBWB feature is almost higher than that of combining T_MBWB feature, but in rounds 2 and 4, the accuracy of combining A_MBWB feature is almost lower than the that of combining T_MBWB feature.
The overall performance of each round is also compared in Fig.5, according to minimum, maximum and average accuracy.
It can be seen that, from round 1 to round 4, the performance is getting better and better, but in round 5, its performance begins to decrease. This is because the diversity among features is increasing when adding more A_MBWB features and T_MBWB features, but to a certain extent, the growth room of accuracy is getting smaller and smaller, and the performance may begin to decline.
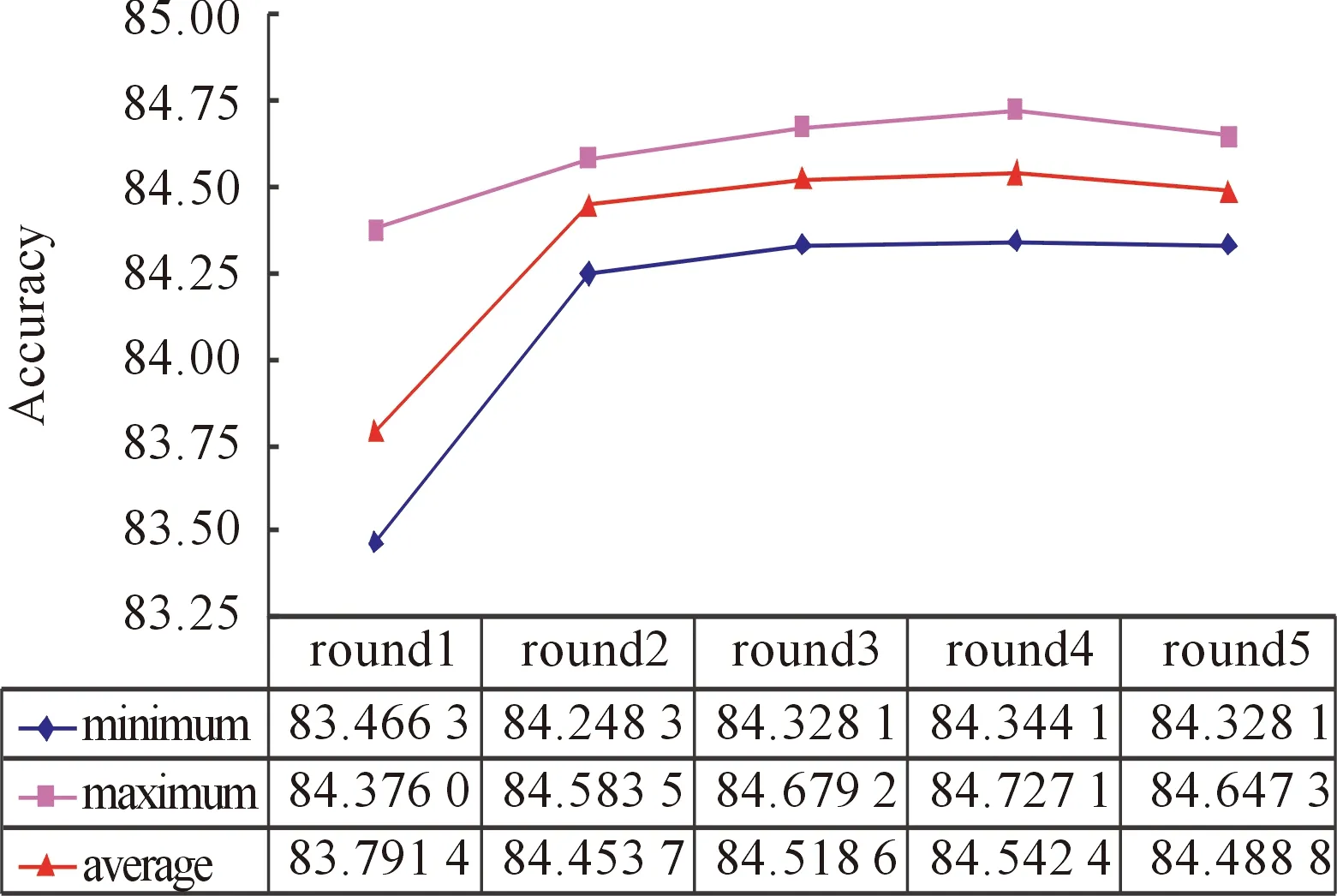
Fig.5 Overall performance comparison.
5.4 Comparison with other work
A_MBWB features and T_MBWB features prove to be very informative for Chinese question classification, and can further boost the question classification accuracy. Table 6 shows the accuracy comparison with previous research work for Chinese question classification, including (Wen,2006), (Sun,2007), (Zhang,2009), (Yu,2010), (Yang,2013).

Table 6 Accuracy comparison of Chinese question classification (%).
Among all above studies for Chinese question classification, our best result gets the accuracy of 84.73% for 77 fine classes, which outperforms the previously reported best accuracy of 84.34% by (Zhang, 2009)[23]. In especial, compared with (Yang, 2013)[21], the difference is only the further use of A_MBWB features and T_MBWB features in our work, but it leads to 2.3% accuracy increase. This indicates that the A_MBWB features and T_MBWB features can greatly contribute the accuracy gain in Chinese question classification.
6 Conclusion
In current research on Chinese question classification, the semantic relation between basic feature and BOW is less considered when constructing feature vectors. An operator called MBWB is proposed in this paper for the extraction of potential features contained in basic features. By performing MBWB operator on two kinds of BOW, the corresponding MBWB features i.e. A_MBWB features and T_MBWB features are generated automatically. Experimental results on the Chinese question set show good performance of question classification when combing A_MBWB features and T_MBWB features with basic features.
Main contributions of our work are as follows:
(1) The MBWB operator can mine potential information contained in basic features, and enrich syntactic and semantic expression of a question. Moreover, since potential features are extracted by a simple MBWB operator, the difficulty of existing feature extraction methods for Chinese question classification can also be effectively alleviated.
(2) The contribution of POS, NE, DR and other basic features for Chinese question classification has been significantly enhanced. For example, previous research shows that NE has little contribution to question classification, but in this paper, the accuracy could be greatly improved when binding NE to A_BOW or T_BOW.
Our method has achieved good experimental results, but there are still some problems to be addressed.
(1) A heuristic method is used to generate the A_MBWB and T_MBWB features in this paper. Maybe there exists other effective method, and it requires us to further explore and validate.
(2) The classification accuracy will decline while combining more A_MBWB and T_MBWB features. In future, the selection of A_MBWB and T_MBWB features will be emphatically studied.
Acknowledgment
The authors thank the IRSC lab of Harbin Institute of Technology in China for their free and available LTP platform.
[1]D.Metzler and W.B.Croft, Analysis of statistical question classification for fact-based questions,InformationRetrieval, vol.8, no.3, pp.481-504, 2005.
[2]D.Moldovan, M.Pasca, S.Harabagiu, and M.Surdeanu,Performance issues and error analysis in an open-domain question answering system,ACMTransactionsonInformationSystems, vol.21, no.2, pp.133-154, 2003.
[3]E.Hovy, L.Gerber, U.Hermjakob, C.Y.Lin, and D.Ravichandran, Toward semantics-based answer pinpointing, inProceedingsoftheFirstInternationalConferenceonHumanLanguageTechnologyResearch(HLT2001), San Diego, CA, USA, 2001, pp.1-7.
[4]E.Brill, S.Dumais, and M.Banko.An analysis of the AskMSR question-answering system, inProceedingsofthe2002ConferenceonEmpiricalMethodsinNaturalLanguageProcessing(EMNLP2002), Philadelphia, PA, USA, 2002,pp.257-264.
[5]X.Li and D.Roth, Learning question classifiers, inProceedingsofthe19thInternationalConferenceonComputationalLinguistics(COLING2002),Taipei, China, 2002,pp.1-7.
[6]X.Li and D.Roth, Learning question classifiers: the role of semantic information,JournalofNaturalLanguageEngineering,vol.12, no.3, pp.229-250, 2006.
[7]D.Zhang and W.Lee, Question classification using support vector machines, inProceedingsofthe26thannualinternationalACMSIGIRconferenceonresearchanddevelopmentininformationretrieval(SIGIR2003), Toronto, Canada, 2003, pp.26-32.
[8]A.Moschitti, S.Quarteroni, R.Basili, and S.Manandhar, Exploiting syntactic and shallow semantic kernels for question/answer classification, inProceedingsofthe20thInternationalConferenceonComputationalLinguistics, Prague, Czech Republic, 2007, pp.776-783.
[9]D.Metzler and W.B.Croft, Analysis of statistical question classification for fact-based questions,InformationRetrieval, vol.8, no.3, pp.481-504, 2005.
[10] M.L.Nguyen, T.T.Nguyen, and A.Shimazu, Subtree mining for question classification problem, inProceedingsofthe20thJointInternationalConferenceonArtificialIntelligence, Hyderabad, India, 2007, pp.1695-1700.
[11] Z.H.Huang, M.Thint, and Z.C.Qin, Question classification using head words and their hypernyms, inProceedingsofthe2008ConferenceonEmpiricalMethodsinNaturalLanguageProcessing(EMNLP2008), Hawaii, USA, 2008, pp.927-936.
[12] Z.H.Huang, M.Thint, and A.Celikyilmaz, Investigation of question classifier in question answering, inProceedingsofthe2009ConferenceonEmpiricalMethodsinNaturalLanguageProcessing(EMNLP2009), Singapore, 2009, pp.543-550.
[13] J.Silva, L.Coheur, A.Mendes, and A.Wichert, From symbolic to sub-symbolic information in question classification,ArtificialIntelligenceReview, vol.35, no.2, pp.137-154, 2011.
[14] B.Loni, G.Tulder, P.Wiggers, D.Tax, and M.Loog, Question classification by weighted combination of lexical, syntactical and semantic features, inProceedingsofthe14thinternationalconferenceonText,SpeechandDialog(TSD2011), Pilsen, Czech Republic,2012, pp.243-250.
[15] F.T.Li, X.Zhang, J.H.Yuan, and X.Y.Zhu,Classifying what-type questions by head noun tagging, inProceedingsofthe22ndInternationalConferenceonComputationalLinguistics(COLING2008), Manchester, UK, 2008, pp.481-488.
[16] Y.Z.Wu, J.Zhao, and B.Xu, Chinese question classification from approach and semantic view, inProceedingsofthe2ndAsiaInformationRetrievalSymposium, JejuIsland, Korea, 2005, pp.485-490.
[17] Y.Zhang, T.Liu, and X.Wen, Modified bayesian model based question classification,JournalofChineseInformationProcessing, vol.19, no.2, pp.100-105, 2005.
[18] A.Sunand and M.H.Jiang, Chinese question answering based on syntax and answer classification,ActaElectronicaSinica, vol.36, no.5, pp.833-839, 2008.
[19] X.Li, X.J.Huang, and L.D.Wu, Combined multiple classifiers based on TBL algorithm and their application in question classification,JournalofComputerResearchandDevelopment, vol.45, no.3, pp.535-541, 2008.
[20] X.Wen, Y.Zhang, T.Liu, and MA Jin-Shan, Syntactic structure parsing based Chinese question classification,JournalofChineseInformationProcessing,vol.20, no.2, pp.33-39, 2006.
[21] S.Yang, C.Gao, J.Yao and X.Dai,Feature combination via importance-inhibition analysis,JournalofSoutheastUniversity(EnglishEdition), vol.29, no.1, pp.22-26, 2013.
[22] J.Sun, D.Cai, D.Lv, and Y.Dong, HowNet based Chinese question automatic classification,JournalofChineseInformationProcessing,vol.21, no.1, pp.90-95, 2007.
[23] Z.Zhang, Y.Zhang, T.Liu Ting, and S.Li, Chinese question classification based on identification of cue words and extension of training set,ChineseHighTechnologyLetters,vol.19, no.2, pp.111-118, 2009.
[24] Z.Yu, L.Su, L.Li, Q.Zhao, C.Mao,and J.Guo, Question classification based on co-training style semi-supervised learning,PatternRecognitionLetters, vol.31, pp.1975-1980, 2010.


ChaoGaoreceived the B.S. degree in Computer Science and Technology from Henan University of Technology, Zhengzhou, China, in 2008. He received the M.S. degree in Computer Application Technology from Anhui University of Technology, Ma’anshan, China, in 2011. His research interest includes natural language processing.
the B.S. degree in Computer Science from Anhui Normal University, Wuhu, China, in 1994. He
the M.S. degree in Computer Software and Theory from Nanjing University, Nanjing, China, in 2001. He received the Ph.D degree in Computer Application Technology from Nanjing University, Nanjing, China, in 2013. His research interest includes natural language processing, concept lattice and rough set.
•Sichun Yang is with School of Computer Science and Technology, Anhui University of Technology, Ma’anshan 243002, China.
•Chao Gao is with Department of Computer and Software Engineering, Anhui Institute of Information Technology, Wuhu 241000, China. E-mail: chaogao@aiit.edu.cn.
*To whom correspondence should be addressed. Manuscript received: 2017-05-20; accepted: 2017-06-20
猜你喜欢
少儿画王(3-6岁)(2022年6期)2022-07-19
原道(2022年2期)2022-02-17
成都信息工程大学学报(2021年2期)2021-07-22
家教世界(2021年7期)2021-03-23
家教世界(2021年5期)2021-03-11
家教世界(2021年2期)2021-03-03
阅读(快乐英语高年级)(2020年5期)2020-07-27
滇池(2018年1期)2018-01-17
领导决策信息(2017年10期)2017-05-17
新闻传播(2016年9期)2016-09-26
 CAAI Transactions on Intelligence Technology2017年3期
CAAI Transactions on Intelligence Technology2017年3期
- CAAI Transactions on Intelligence Technology的其它文章
- Micro Structure of Injection Molding Machine Mold Clamping Mechanism: Design and Motion Simulation
- Retinal Image Segmentation Using Double-Scale Nonlinear Thresholding on Vessel Support Regions
- The Fuzzification of Attribute Information Granules and Its Formal Reasoning Model
- Technology of Intelligent Driving Radar Perception Based on Driving Brain
- Technology and Application of Intelligent Driving Based on Visual Perception
- Interactions Between Agents:the Key of Multi Task Reinforcement Learning Improvement for Dynamic Environments