
海量非结构化网络招聘数据的挖掘分析
2017-10-23 10:35张学新贾园园
长春师范大学学报 2017年10期
张学新,贾园园,饶 希,蔡 黎
(湖北工程学院数学与统计学院,湖北孝感 432000)
海量非结构化网络招聘数据的挖掘分析
张学新,贾园园,饶 希,蔡 黎
(湖北工程学院数学与统计学院,湖北孝感 432000)
网络招聘凭借其独特优势,己成为招聘者发布信息和应聘者获取信息的主要渠道,挖掘海量网络招聘信息里隐含的社会和相关行业的需求特点与趋势有着非常重要的意义。本文抓取拉勾网站发布的50多万条招聘数据及58同城两千多条应聘数据,先对其中的非结构化数据进行去重去空、中文分词及停用词过滤等数据预处理,再使用TF-IDF权重法提取候选特征词,形成词袋,构造词汇-文本矩阵,利用基于潜在语义(LSA)分析的奇异值分解算法(SVD)对词汇-文本矩阵进行空间语义降维,最后通过k-means聚类算法对职位的职业类型和专业领域进行划分,找出热门需求,分析大数据职位需求情况与行业分布情况、大数据职位技能要求及IT行业供求与发展;对相关结果进行可视化展示,并运用关联规则挖掘信息间的内在联系。
大数据;网络招聘信息;TF-IDF;奇异值分解;Python语言
随着互联网技术的迅速发展,企业把人才招聘信息越来越多地发布到互联网上,产生了大量的非结构化数据。这些数据包含用人单位对人才的需求及能力要求信息,在一定程度上代表了人才需求的未来走向。但是,对模糊而且非结构化的文本数据进行挖掘比较困难,涉及统计学、机器学习、数据库技术以及专业软件使用等技术。国内对这方面的挖掘研究很少。钟晓旭[1-2]先后对2010年的3家招聘网站的78481条招聘信息及新安人才网上计算机类专业招聘信息进行聚类,统计各个职位的需求量,计算职位间的相关系数。王静[3]选择2011年的4家招聘网站、包括6种职业的2262个招聘网页,采用伪二维隐马尔可夫模型来分割,抽取其中的职位名、机构名等信息。总的来说,这些文本挖掘的研究深度有限,所用数据不是真正意义上的网络招聘数据,不是大量非结构化的招聘数据;统计分析方法简单,很少使用软件编程。本文利用八爪鱼采集器,结合Python语言爬取自2015年11月至2016年4月拉钩网25万多条企业招聘信息(http://www.lagou.com),58同城网上北京地区的人才招聘信息共2219条,深入挖掘并可视化海量非结构化网络招聘数据的有关信息。
1 数据预处理
观察抓取的数据,招聘信息.csv中的字段大多为文本格式,需要将其量化成数值形式才能对其进行分析。而职位描述.csv中有大量空行以及重复的情况,如果不做处理会对后续分析造成影响,并且招聘文本信息存在大量噪声特征,如果把这些数据也引入进行分词、词频统计乃至文本聚类等,则必然会对聚类结果的质量造成很大的影响,因此首先要对数据进行预处理。
1.1 属性数值化
对于招聘信息.csv、Salary(月薪)、Work Year(工作经验)、Position Advantage(职位优势)、Finance Stage(公司阶段)、Education(学历要求)、Company Size(公司规模)等指标,需要将其数值化,例如:Salary出现3种字符类型:8k~12k、8k以下、12k以上,正则表达式转换为数字型:10、8、12,单位:k;Finance Stage:初创型(未融资)、初创型(不需要融资)、初创型(天使轮)、成长型(不需要融资)、成长型(A轮)、成长型(B轮)、成熟型(不需要融资)、成熟型(C轮)、成熟型(D轮及以上)、上市公司。编码转换为:初创型—B1、成长型—B2、成熟型—B3、上市公司—B4。
1.2 去重、去空
对职位描述.csv,存在大量空行和岗位描述文本完全一致的样本,去除后数据仅剩365890行。
1.3 中文分词
由于中文文本的特点是词与词之间没有明显的界限,从文本中提取词语时需要分词,本文采用Python开发的一个中文分词模块——jieba分词,对每一个岗位描述进行中文分词,jieba分词的原理是采用Trie树进行词图扫描,得到一个有向无环图(DAG),其中包括汉字所有可能的构词。对句子中词的切分采用最大概率(词频的最大)方法,对词典中没有的词,采用Viterbi算法,使用HMM模型处理。该分词系统具有分词、词性标注、未登录词识别,支持用户自定义词典、关键词提取等功能。
部分分词结果示例如图1所示。

图1 部分分词结果
图1的分词结果是没有停用词过滤的结果,可以看到,其中含有大量标点及表达无意义的字词,对后续分析会造成很大影响,因此接下来需要进行停用词过滤。
1.4 停用词过滤
把文本里某些无实义的介词、连词、分号等字符,以及某些无助于分类的专用名词过滤掉,以减少存储空间,提高搜索效率。停用词有两个特征:一是极其普遍、出现频率高;二是包含信息量低,对文本标识无意义。
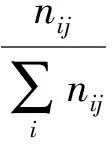
2 文本向量化
2.1 文档频数(DF)
文档频数(DF)即训练集合中包含某单词的文本数。当一个词在大量文档中出现时,这个词通常被认为是噪声词。本文选用DF方法筛选出如下停用词:我、有、的、了、是,等。将筛选出的停用词加入停用词表,再利用停用词表过滤停用词,将分词结果与停用词表中的词语进行匹配,若匹配成功,则进行删除处理。去除停用词后的部分结果示例如图2所示。
2.2 文本特征抽取
经过上述文本预处理后,虽然已经去掉部分停用词,但还是包含大量词语,给文本向量化过程带来困难,所以特征抽取的主要目的是在不改变文本原有核心信息的情况下尽量减少要处理的词数,以此来降低向量空间维数,从而简化计算,提高文本处理的速度和效率。

图2 停用词过滤后分词结果
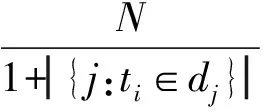
在Shannon的信息论的解释中,如果特征项在所有文本中出现的频率越高,它所包含的信息嫡越小;如果特征项集中在少数文本中,即在少数文本中出现频率较高,则它所具有的信息嫡也较高。这样词的权重可以定义为wij=tfij×idfi,将权重按照从大到小的顺序排列,抽取权重最大的前50000个特征词作为候选特征词。
2.3 文本的空间向量模型[5]
用向量空间的一个向量表示每一个文本,并以每一个不同的特征项(词条)对应为向量空间中的一个维度,而每一个维度的值就是对应的特征项在文本中的权重,这里的权重可以由TF-IDF等算法得到。向量空间模型就是将文本表示成为一个特征向量V(d)=(wi)n×1,其中,ti为文档d中的特征项,wi为该特征项的权值,可由TF-IDF算法得出。
2.4 文本的向量化表示
上述文本特征抽取将全部特征项筛选为50000个候选特征项,这时需要构建一个词袋,根据招聘文本的特征项对应词袋中的位置,组成一个同维数的向量,最后得到一个词汇-文本矩阵(wij)m×n,其每一行表示一个特征项在各个文档中的权重,每一列表示一个文档向量。表1和表2是部分结果显示。
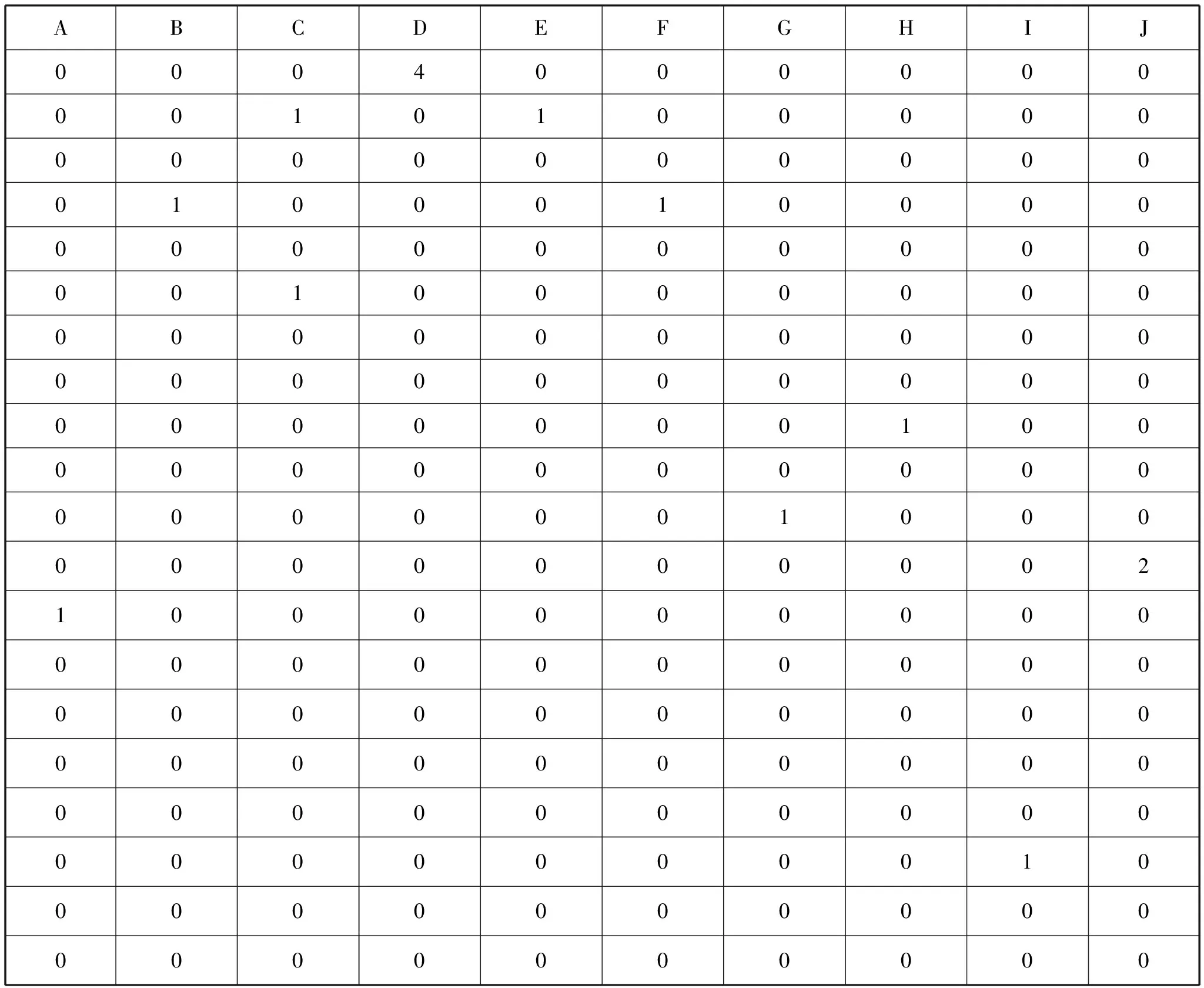
表1 词汇-文本词频矩阵
2.5 语义空间降维
理论上,当得出文本向量后就可以直接比较两向量夹角的余弦值进行相似度的计算。但可以发现,现在构造的词汇-文本矩阵是一个50000×365890的巨大矩阵,计算起来比较困难。另外,招聘信息文本信息中存在同义词和近义词等词语,即使通过特征抽取转化得到的文本向量也可能达不到自然语言属性本质的要求。
因此,这里需要借用潜在语义分析(LSA)理论,将招聘信息的文本向量空间中非完全正交的多维特征投影到维数较少的潜在语义空间上。而LSA对特征空间进行处理时用的关键技术就是奇异值分解(SVD),在统计学上,它是针对矩阵中的特征向量进行分解和压缩的技术。
2.6 奇异值分解的基本原理
奇异值分解可以将网页文本通过向量转换后的非完全正交的多维特征投影到较少的一个潜在语义空间中,同时保持原空间的语义特征,从而可以实现对特征空间的降噪和降维处理。
对于任意的矩阵A=Am×n,这里是由招聘文本信息组成的词汇-文本矩阵。它的奇异值分解表达式为A=U∑VT,其中,Um×m是酉矩阵,∑m×n是对角矩阵,Vn×n是酉矩阵。∑对角线上的元素是A的奇异值,∑=diag(σ1,σ2,…,σr,0,…,0),其中σ1≥σ2≥…≥σr>0。
奇异值分解定理[6]设A∈Rm×n,且r=rank(A)≤min(m,n),则存在正交矩阵U∈Rm×n和V∈Rm×n,对角矩阵∑∈Rm×n,∑=diag(σ1,σ2,…,σr,0,…,0),其中σ1≥σ2≥…≥σr>0,使得
A=U∑VT.
(1)
2.7 词汇-文本矩阵的奇异值分解
对于矩阵词汇-文档矩阵Am×n的奇异值分解可表示为Am×n=Um×m∑m×nVn×nT,其中,Um×m称为词汇矩阵,每一行可以理解为意思相关的一类词,行中的元素就是某个词与该行其它词的相关性大小的度量,而Vn×nT视为文档矩阵,它的每一列都表示招聘信息中同一主题一类的文本,其中的每个元素代表这类文本中每篇文本的相关性,∑m×n矩阵表示的是某类词与招聘文本之间的相关性。在生成的这个“语义空间”中,大的奇异值对应的维度更具词的共性,而小的奇异值所对应的维度更具有词的个性。
对Um×m及Vn×n进行行分块,得到
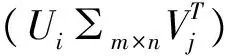
(2)
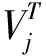
Am×n≈Um×k∑k×kVk×nT≜Ak.
(3)
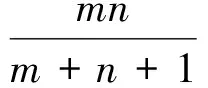
3 数据挖掘
3.1 文本聚类
相似度是用来衡量文本间相似程度的一个标准。本文采用基于距离度量的欧几里得距离测度招聘文本间差异。文本聚类对无类别标记的文本信息,根据不同的特征,将有着各自特征的文本进行分类,使用相似度计算将具有相同属性或者相似属性的文本聚类在一起。通过对不同职位进行分类,求职者可以结合自身状况更加快捷地获取相关信息资源。
聚类结果显示,目前所需人才分为产品类、技术类、运营类、金融类、设计类、市场与销售类、职能类等类型;人才需求中分为移动互联网、电子商务、分类信息、广告营销、教育、金融、旅游、企业服务、社交网络、生活服务、数据服务、文化娱乐、信息安全、医疗健康、硬件、游戏、招聘等专业领域。
3.2 分析热门需求
首先,要定义何为热门需求,本文认为热门需求具备以下几个特征:普遍供不应求、企业需求量大、平均工资高、未来需求量大、发展前景好。本文用企业发布招聘信息数量、平均薪水、发展阶段与公司规模描述人才需求情况。所抓取的文档涉及300个大中小地域,利用python 2.7求得各个地域发布的招聘信息量,首先筛选出发布信息量在前33名的地域占总招聘信息数的98.89%,因此其余267个城市可以忽略不计,进而构造上述指标,运用主成分分析法构建综合排名算法对其进行综合排名。热门行业排行前五的分别是:移动互联网、金融、电子商务·金融、移动互联网·金融、电子商务。经统计,所抓取文档中共有124类职位,首先筛选出发布信息量在前37名的行业占总招聘信息数的99.83%,因此其余87个行业可以忽略不计,同样对其进行综合排名。热门职位排行前五的分别是:后端开发、运营、销售、视觉设计、编辑。
3.3 未来人才需求走向
对于热门地域前五名,即北京、上海、深圳、杭州、广州,分析其对学历的需求,大多以本科、专科为主;分析其对工作经验的需求,要求大多在1~3年。分析各月发布的招聘信息中,热门地域所占比例均大于80%,占较大比重,且趋势较均衡,可以看出近期热门地域对人才的需求仍然很大。
3.4 大数据职位需求情况
首先需要将大数据相关职位筛选出来进行分析,本文通过对大数据相关职位的职位名称特点进行分析,发现其职位名称大多包含“数据”二字,但是某些职位如“数据库开发师”“数据仓库工程师”等并不属于大数据相关职位,因此,本文在筛选数据时,只在职位名称文档中选出包含“数据”字段且不包含“数据库”与“数据仓库”字段的数据,共得到10958条招聘信息。
3.5 关联规则挖掘[7]
进行关联规则挖掘时,首先对数据进行编码,将文本型数据转换为分类数据,编码结果是,城市C1~C4,对应一线城市~四线城市;公司规模B1~B4,对应员工50人以下~500人以上;应聘者教育水平E1~E4,对应大专及学历不限~博士;公司金融状况F1~F4,对应初创型~上市公司;工作年限要求W1~W4,对应1年以下(应届,不限)~5年以上;月薪资水平S1~S7,对应5千以下~3万以上。对编码后的数据对,分析各个指标之间的关联规则(图3)。
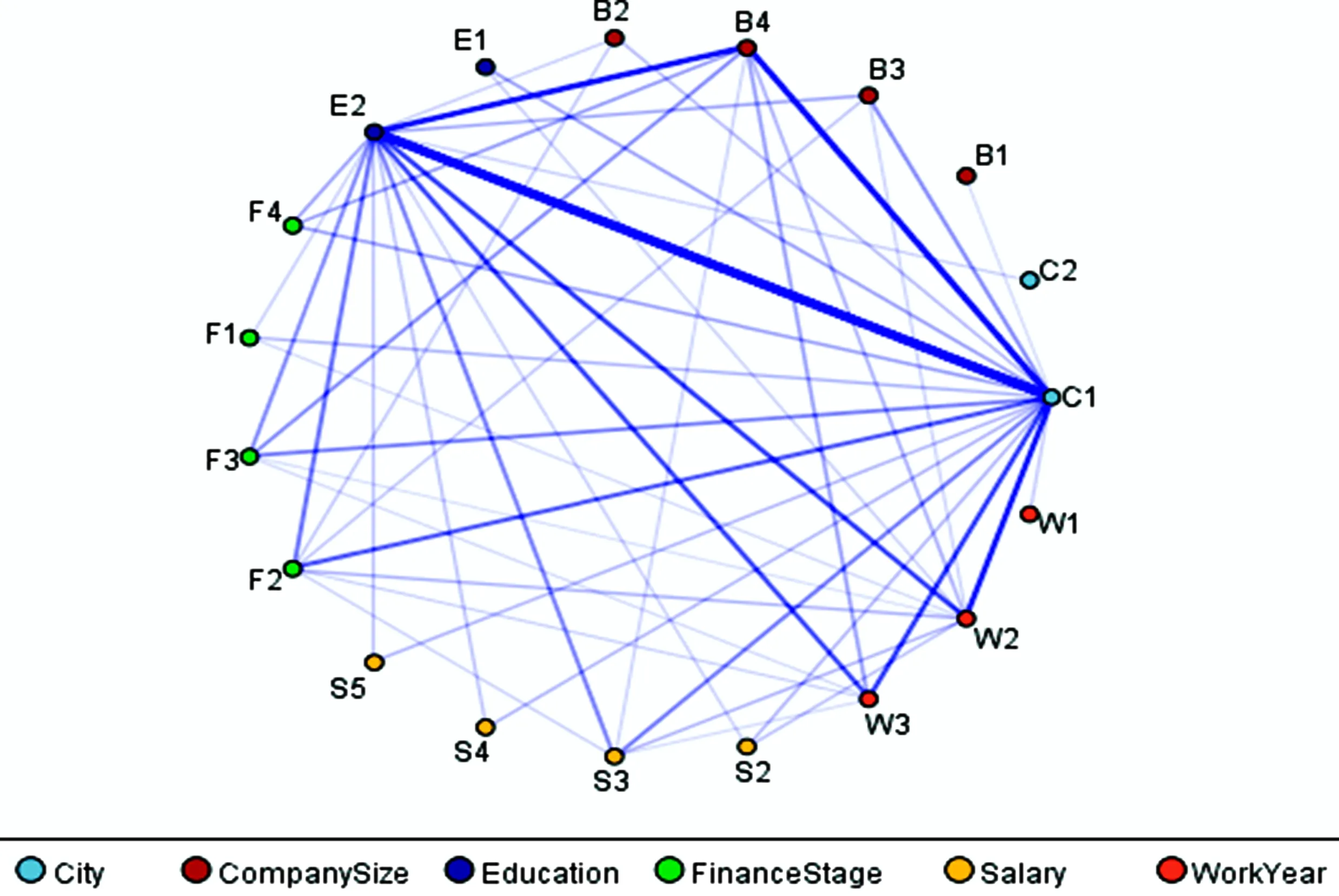
图3 关联规则网络
关联分析的部分结果如表3所示,在所有大数据相关职位中,存在的关联规则如下:如果一个企业提供的平均薪酬在2万~2.5万范围内,且要求学历是本科,那么这家企业92.83%的概率在一线城市。如果一家企业要求的工作经验是3~5年,公司规模是500人以上,位于一线城市,那么它有86.99%的概率需要本科以上学历。
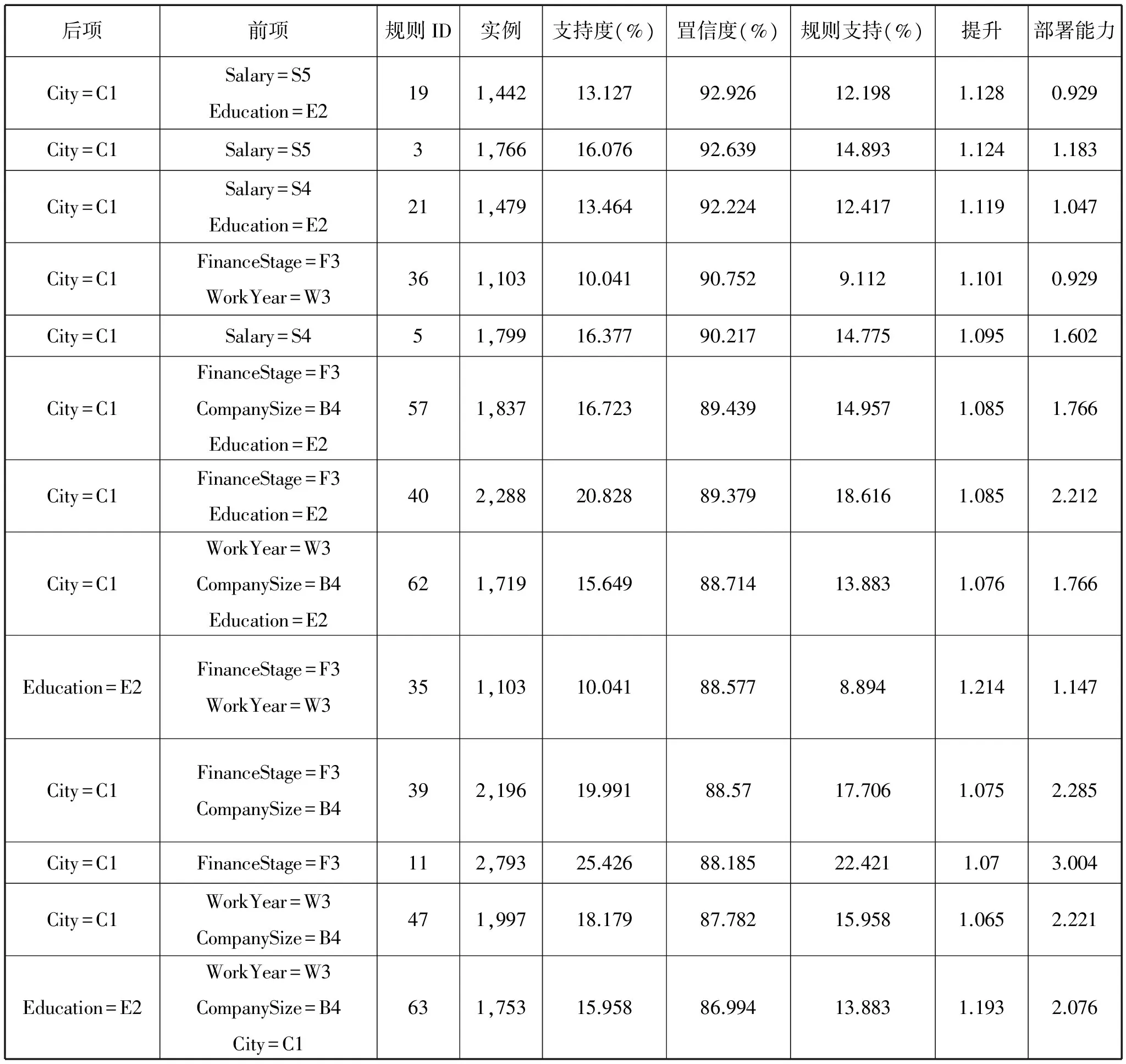
表3 关联分析部分结果
4 大数据职位的行业分布情况
4.1 地区分布情况
从大数据职位的区域分布来看,“北上深杭广”等特大一线城市合计占据89.2%的职位份额,仅北京地区占比就超过五成。因此,对于大数据的职业发展来说,“坚守一线城市”才是明智的选择。
4.2 大数据职位技能要求
本文筛选出所有的大数据职位与其对应编号,按照编号将抓取保存的数据集中相应的大数据职位的岗位描述和任职要求提取出来,利用武汉大学开发的ROST文本挖掘系统对这些文本进行分词,由于文本中有大量的专业术语如“数据分析”“数据挖掘”“云计算”等,需要添加自定义的用户词典,将这些专业术语添加进去,然后再进行分词,词频统计,画出词云图[8]如图4所示。

图4 词云图
根据图4可以看出,“数据”“数据分析”“数据挖掘”“开发”“技术”“算法”“模型”“系统”“互联网”等词语出现频数较大,这说明大数据相关职位要求应聘者具有良好的数据处理与分析能力,其次,“运营”“项目”“市场”“客户”“用户行为”“营销”等词出现频率也比较高,这说明要求应聘者具有对数据的业务理解能力;另外,“学历”“统计学”“数学”“计算机”等词语,说明大数据相关职位对与学历和专业都有一定的要求。
越来越多的企业将“大数据”视为未来发展的“能源”,期待数据能给企业的运营、产品策略、市场研究、品牌管理等方面带来价值。企业对数据分析师等数据相关人才的需求不断上升。2016年,据猎聘网人才大数据研究中心估计,中高级数据分析师的人才处于极度紧缺状态,人才紧缺指数在4.5以上。
4.3 IT行业供求与发展
IT行业包括计算机硬件业、通信设备业、软件业、计算机及通信服务业。原始数据没有给出IT人才市场的供应量,需要爬取外部网络招聘数据,构造TSI人才紧缺指数来分析IT人才市场的供求现状和发展趋势。
4.4 数据来源
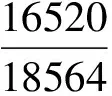
4.5 不同职位供求现状
不同学历TSI指数见图5和图6。由于职业种类很多,本文只对发布招聘信息数前8位的职位进行供求分析。根据图5可以看出,目前IT行业中网页设计/制作以及软件工程师的人才紧缺指数较大,呈现供不应求的现状;而硬件工程师、网络管理员、电子电器工程师和技术支持维护人员的紧缺指数较低,呈现供过于求的状态。根据图6可以看出,目前大专学历和硕士人才紧缺指数较大,呈现供不应求的现状;而本科生的人才紧缺指数较低,呈现供过于求的状态,可能是由于大学扩招导致本科毕业生数量急剧上升,就业形势险峻。
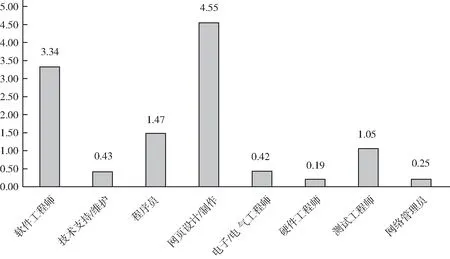
图5 不同职位TSI指数
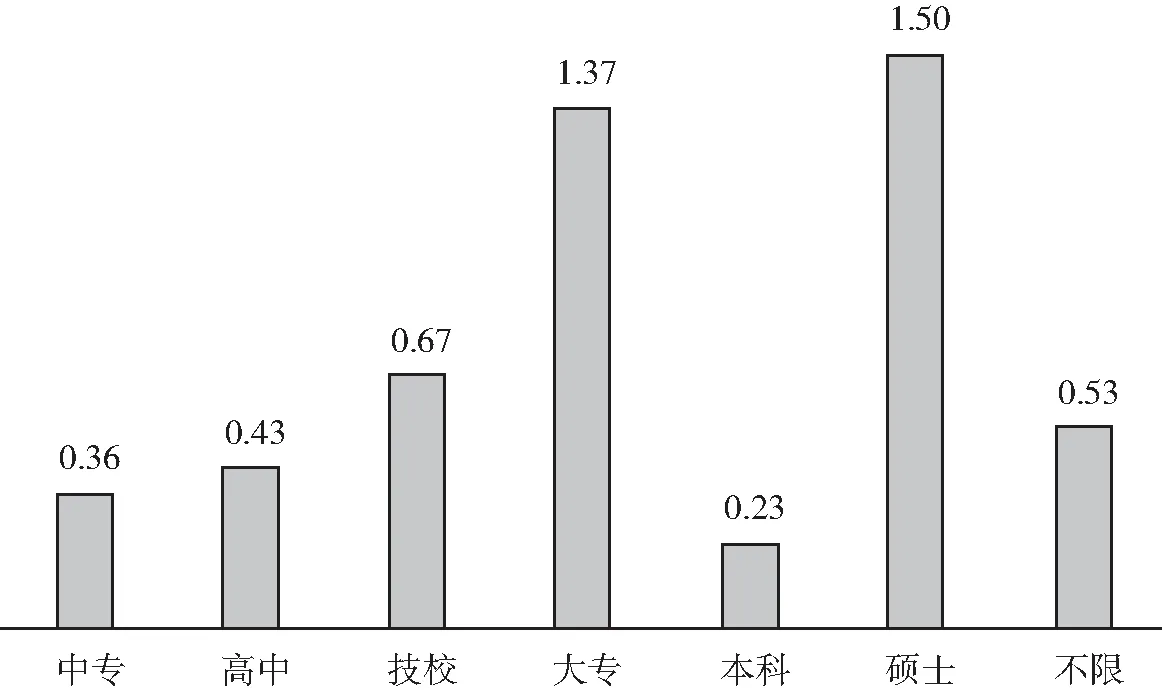
图6 不同学历TSI指数
5 结语
本文基于TF-IDF权重法提取特征词,构造词汇-文本矩阵,进一步运用基于潜在语义(LSA)分析的奇异值分解算法(SVD)对词汇-文本矩阵进行空间语义降维,通过k-means聚类算法对职位的职业类型和专业领域进行了聚类;分析了热门行业、职位、地域;对大数据相关新兴职位,深入挖掘其关联规则,分析其需求增长趋势、行业分布情况、地域分布情况、行业职位特征、行业薪酬情况以及技能要求。
得到的聚类结果准确度与抓取文档的结果在一定程度上有出入,主要是采用欧式距离测度相似性有局限性,k均值算法本身也需要改进。在中文文本挖掘过程中如何使用较复杂的数学统计模型值得进行深入研究。
[1]钟晓旭.基于Web招聘信息的文本挖掘系统研究[D].合肥:合肥工业大学,2010.
[2]钟晓旭,胡学钢.基于数据挖掘的Web招聘信息相关性分析[J].安徽建筑工业学院学报:自然科学版,2010,18(4):23-45.
[3]王静.Web对象的信息抽取的关键技术研究[D].西安:西安电子科技大学,2011.
[4]朱明.数据挖掘[M].2版.合肥:中国科学技术大学出版社,2008.
[5]邬启为.基于向量空间的文本聚类方法与实现[D].北京:北京交通大学,2014.
[6]郑慧娆,陈绍林,莫忠息,等.数值计算方法[M].2版.武汉:武汉大学出版社,2012.
[7]Pang-Ning Tan,Michael Steinbach,Vipin Kumar.数据挖掘导论[M].北京:人民邮电出版社,2006.
[8]Helic D,Trattner C,Strohmaier M,et al.Are tag clouds useful for navigation? A network-theoretic analysis[J].Journal of Social Computing and Cyber-Physical Systems,2011,1(1):33-55.
[9]周健,傅昭南,田茂再.基于TSI指数的中国运输服务指数构建[J].系统工程理论与实践,2015,35(4):965-972.
DataMiningAnalysisofMassiveUnstructuredNetworkRecruitmentInformation
ZHANG Xue-xin, JIA Yuan-yuan, RAO Xi, CAI Li
(Mathematics and Statistics School,Hubei Engineering University,Xiaogan Hubei 432000,China)
With its unique advantages, network recruitment has become the main channel for recruiters and candidates to release information, thus, it is of great significance to excavate the features and trends of the social & related industries demand hidden in the vast network of recruitment information. This paper crawl out about 500 thousand recruitment texts from Lagou net and more than 2 thousand application job data from 58 tong city. First of all, the unstructured data are reprocessed by discard empty, Chinese word segmenting and stop word filtering and other data preprocessing. Secondly, extracting of candidate feature words using TF-IDF weighting method, formation words bag, structuring term-document matrix, to reduce the dimensionality of the semantic space for term-document matrix based on the singular value decomposition algorithm for latent semantic analysis are carry out. Finally, post types of occupations and areas of specialization are divided through the K-means clustering algorithm, and the hot demand is find out, the demand for big data jobs and big data industry distribution, big data job skill requirements and the development of IT industry are analyzed, also, visualization of the relevant results, and the inherent link between information by association rules mining are implemented.
big data; network recruitment information; TF-IDF; SVD; Python language
TP391.4
A
2095-7602(2017)10-0028-09
2017-05-06
湖北工程学院教研项目“与大数据公司联合开展(应用)统计学专业实训教学的探索与思考”(2016A20)。
张学新(1966- ),男,副教授,博士,从事概率论与数理统计方法应用研究。
猜你喜欢
中国医院院长(2022年2期)2022-11-09
校园英语·月末(2021年13期)2021-03-15
铁道通信信号(2019年6期)2019-10-08
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
近代史学刊(2017年2期)2017-06-06
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
电子设计工程(2015年6期)2015-02-27
海外星云 (2014年22期)2015-01-19
