
语音驱动的口型同步算法
2017-11-01 08:58范鑫鑫杨旭波
东华大学学报(自然科学版) 2017年4期
范鑫鑫, 杨旭波
(上海交通大学 软件学院, 上海 200240)
语音驱动的口型同步算法
范鑫鑫, 杨旭波
(上海交通大学 软件学院, 上海 200240)
本文提出一种口型动画同步算法, 可以根据输入的语音信号, 生成与该信号同步的口型动画.该算法分为预处理与运行时两个阶段.在预处理阶段, 预定义一个基本口型动作集合, 然后令设计师通过定义该集合中元素的权重变化曲线, 来设计不同音素对应的口型动画.在运行时阶段, 首先获取输入语音信号对应的音素序列, 然后将该序列映射到一系列口型动画片段上, 最后将这些片段互相拼接, 即可得到最终输出的结果.试验表明, 该算法具有较高的准确率, 在运行时耗时较少, 并且对于不同的人脸模型具有较高的可重用性.
语音驱动; 口型同步; 音素
口型动画的制作在电影、游戏以及虚拟现实等新型人机交互方式中均占据重要地位.在观看模型动画时, 观众往往对模型口型动作的一些细微变化较为敏感.因此如何生成真实自然的口型动画是当今计算机图形学领域中的一个富有挑战性的课题.
在生成口型动画的方法中, 有一系列采用语音驱动的方法.这类方法一般以一段语音信号作为输入, 生成一段与该信号同步的口型动画.在这类方法中, 输入的语音信号首先被转化为由一串发音单元构成的序列, 这些发音单元被称为音素.然后序列中的每个音素都会被映射到一个口型动作单元上, 这些口型动作单元被称为视素, 视素是音素可视化的形态.最后, 将所得到的视素序列进行拼接与插值, 即得到最终的口型动画[1].
在实际应用中, 除当前正在发音的音素外, 该音素之前或之后的一些音素也会对当前口型动作产生影响,这种现象叫做协同发音.协同发音现象是设计口型同步算法时必须考虑并且解决的问题.
为了解决口型同步与协同发音问题, 研究者们提出了不同的方法, 大致分为下述4种类别:
(1) 程序式的方法.这类方法定义了一系列针对音素的规则[2], 并且依照这些规则解决协同发音问题.其中Kalberer等[1]提出的方法最具代表性, 该方法为不同音素定义了不同的优先级, 在协同发音现象发生的时候, 优先级越高的音素对口型动作的决定作用也越大.
(2) 基于物理的方法.这类方法利用力学定律, 模拟脸部不同肌肉之间的相互作用, 进而生成对应的口型动画[3].这类方法生成的口型动画具有很高的真实度, 但是由于需要经过复杂的力学计算, 计算量较大且效率较低.
(3) 数据驱动的方法.这类方法需要预先采集大量的口型动作数据, 然后对于一段输入的语音信号, 根据该信号对应的音素序列, 在所采集的数据中搜索最匹配的口型动作[4-5].为了满足精确度的要求, 这类方法需要大量数据作为支撑.
(4) 基于机器学习的方法. 比较典型的有利用隐式马尔科夫模型或者高斯混合模型等方法[6-7].这类方法通过训练机器学习模型, 对输入语音信号对应的口型动作做出基于概率的估计.与数据驱动的方法相比, 这类方法需要的数据量较少, 但是对于协同发音现象进行建模的结果具有较低的精确度.
本文提出的方法不同于上述4类方法.本文预定义一个基本口型动作集合, 所有口型动作均由该集合中的元素按照不同权重线性混合而成[8].由一位动画设计师预先为每个音素设计对应的口型动画, 这些口型动画由一系列曲线构成, 分别代表每个基本口型动作的权重随时间的变化.设计师在设计每个音素对应的口型动画时, 需要考虑其后继音素的所有可能情况, 并且针对不同情况设计不同的曲线作为音素之间的过渡动画.在运行时, 分析输入语音信号对应的音素序列, 然后将序列中的音素对应的口型动画相互拼接, 最终得到完整的口型动画.
本文方法的优点如下: (1)相比基于物理的方法需要在运行时进行运动模拟, 相比数据驱动的方法需要在运行时进行最优匹配的查找, 本文方法在运行时计算量很小, 这是因为所有音素对应的口型动画均已在预处理阶段被定义;(2)不同口型动画之间相互独立, 对其中一段口型动画的调整不会影响系统的其余部分;(3)本文方法可以生成多数脸部模型对应的口型动画, 在对模型进行变更时, 设计师只需要重新设计基本口型动作集合中的模型动作, 其余的模型动作均可由基本口型动作进行线性混合得到.
1 算法描述
本文方法包含两个阶段, 分别是预处理阶段以及运行时阶段.在预处理阶段中, 设计师可以通过绘制曲线的方式定义音素对应的口型动画; 在运行时阶段中, 根据输入语音信号对应的音素序列, 将序列中的音素对应的口型动画互相拼接, 最终得到完整的口型动画.
1.1预处理阶段
1.1.1 音素的分类
本文所使用的Timit语音集合定义了46种不同的音素[9].语音学的研究表明, 有些不同的音素会表现为相似的口型动作, 比如/t/和/d/的发音, 只区别于声带是否振动, 其对应的口型动作是相近的.这种不同音素映射到相似口型动作上的现象是普遍存在的.基于上述结论, 本文将Timit语音集合中的46种不同音素映射到16个不同的类别上.映射的结果如表1所示[7].

表1 音素的分类Table 1 Classification of phonemes
设计师在设计每个音素对应的口型动画时, 需要考虑其后继音素的每种可能情况.因此, 对于原本的46种音素, 设计师需要设计共计2 116段不同的口型动画, 这显然是不现实的.通过音素的分类, 本文将需要设计的口型动画数量减少到256种, 减少了约88%, 提高了预处理阶段的效率.
为了使表达简化, 下文中的术语“音素”均代指分类后的16类音素之一.
1.1.2 定义音素对应的口型动画
为了减少设计师需要设计的模型动作数量, 进一步提高预处理阶段的效率, 本文预定义了一个基本口型动作集合.通过定义基本口型动作的权重变化曲线, 设计师可以高效地设计不同音素对应的口型动画.基本口型动作集合还使得本文方法支持对模型的变更, 设计师只需要重新设计基本口型.
动作集合中的模型动作, 除此之外不需要对系统的其余部分进行任何更改, 就可以得到新模型对应的口型动画.
FaceGen建模软件[10]提供了一系列预设的口型动作, 本文选取其中的6种口型动作组成基本口型动作集合.该集合中, 第一个元素是中性口型动作, 记作f1; 其余的元素分别对应表1中的类别2、6、13、15以及16, 记作f2至f6.图1依次展示了上述6种基本口型动作.本文选取的基本口型动作参考了Xu等[11]的方法, 但本文认为, 基本口型动作集合的选取方式并非只有一种, 其他选取方式同样能够得出良好的效果.

图1 6种基本口型动作Fig.1 Six kinds of basic lip poses

(1)
然后, 系统根据式(2)自动生成f1, 即中立口型动作的权重变化曲线.
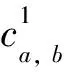
(2)
语音学的研究表明, 人类在发声的时候, 其唇部会迅速做出相应的动作, 然后在这个动作上稳定下来, 并且开始发声.基于上述结论, 本文提出了权重变化曲线中的两个阶段: 稳定阶段与变化阶段.在稳定阶段, 模型的唇部拥有与当前正在发音的音素相对应的稳定的动作; 在变化阶段, 其唇部的动作则迅速向下一个音素对应的动作转化.
在本文建立的口型动画模型中, 每段口型动画的稳定阶段所持续的时间受说话的快慢、单词中音素的紧密程度等多种因素所影响, 而变化阶段所持续的时间则是基本恒定的.本文将变化阶段所持续的时间记作T.若T值过小, 会使得最终生成的口型动画动作过快, 表现得很不自然; 若T值过大, 则动画中的口型与当前正在发音的音素吻合程度并不明显, 表现得很不真实.试验表明,T取30~50 ms之间的数值可以得出良好的效果.
每段口型动画A(pa,pb)必须包含恰好一个稳定阶段以及一个变化阶段, 且稳定阶段位于变化阶段之前.其中, 稳定阶段表示当前音素pa所对应的口型动作, 变化阶段则表示当前音素pa向其后继音素pb进行过渡的口型动作.
1.2运行时阶段
运行时阶段的工作流程如图2所示.首先, 采用现有的音素分析工具, 根据输入的语音信号, 得到对应的音素序列, 并且对于序列中的每个音素, 确定其在原语音信号中的起止时间.满足条件的音素分析工具有很多, 如Festival系统[12]以及Julius系统[13]等, 本文采用了Festival系统进行分析.然后, 将音素序列映射到一系列预先定义好的口型动画片段上.最后, 将这些动画片段进行拼接, 根据拼接之后各基本口型动作的权重变化曲线, 混合成完整的口型动画.
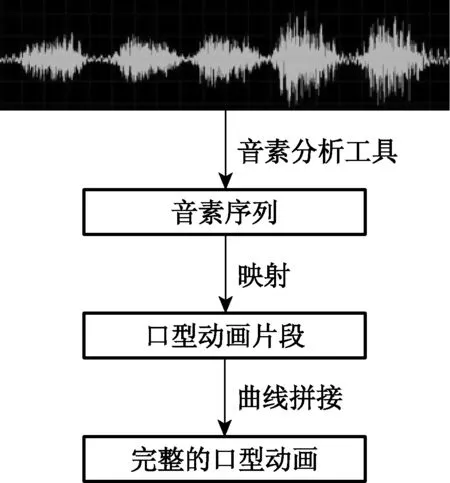
图2 运行时阶段的工作流程Fig.2 Flowchart of runtime phase
1.2.1 音素序列的映射
音素序列到口型动画片段的映射过程如图3所示.假设音素序列中存在一个音素pb, 并且其后继音素为pc, 本文方法需要将事先定义好的动画片段A(pb,pc)与音素pb相关联.假设pb的持续时间为t1到t2, 本文分为t2-t1≥T以及t2-t1 t2-t1≥T的情况如图3(a)所示.根据上文建立的口型动画模型, 在映射结束后, 动画片段A(pb,pc)中变化阶段所持续的时间应该保持恒定不变, 而稳定阶段所持续的时间则是可变的.所以, 本文令音素pb持续时间结尾处长度为T的部分, 即t2-T至t2, 作为新的变化阶段; 剩余的部分即t1至t2-T, 则作为新的稳定阶段.为了用动画片段A(pb,pc)填充这段时间, 需要将该动画片段中的稳定阶段按照时间尺度缩放, 以适应新的长度, 而该动画片段中的变化阶段则无需进行任何更改, 直接填充至目标位置即可. (a)t2-t1≥T (b)t2-t1 英文单词的音节紧凑, 为了保持语速, 在发音时经常不需要将当前音节完全发音, 而是只发音到一半便开始向着下一个音节过渡, 所以t2-t1 1.2.2 曲线的拼接 经过音素序列的映射步骤, 本文得到了一系列在时间轴上排列好的口型动画片段, 并且有些片段是互相重叠的.每段口型动画片段由6条权重变化曲线构成, 分别对应6个基本口型动作.所以, 将口型动画片段进行拼接, 其实等同于对每个基本口型动作的权重变化曲线分别进行拼接. 本文提出的曲线拼接算法可以通过对曲线序列的一次遍历完成.算法的输入为由n个音素p1~pn构成的序列, 以及这些音素映射到的n条曲线c1(t)~cn(t); 输出则为拼接完成的曲线c(t).在初始状态下,c(t)是一条空曲线, 即c(t)的持续时间为0 ms.然后算法对音素构成的序列进行遍历, 在遍历到音素pi时, 将c(t)与ci(t)进行拼接, 并且将拼接完成的曲线作为c(t)的新值.在拼接时, 算法根据pi的持续时间与T的大小关系, 分两种情况进行讨论. c′(t)=(1-r(t))c(t)+r(t)ci(t) (3) 其中:r(t)为线性插值的比例函数, 其对应的表达式如式(4)所示. (4) 图4是该算法作用在两条曲线上的一个示例.在拼接之前, 两条用虚线表示的待拼接曲线c(t)与ci(t)互相重叠.本文将上述两条曲线在重叠区域内进行线性插值, 重叠区域外则保持各自的值不变.最终拼接完成的曲线在图4中用实线表示. 图4 曲线拼接示例Fig.4 Example of curve stitching 经过曲线的拼接步骤, 本文得到了6条完整的权重变化曲线, 每段曲线的持续时间均等于语音信号的总时间.设基本口型动作fi对应的完整权重变化曲线为ci(t), 最终生成的口型动画F(t)可以通过基本口型动作按照式(5)的方式线性混合而成. (5) 设计师定义的每段曲线均满足G1阶连续, 并且可以从数学上证明c′(t)的连续性及其导函数的连续性, 所以最终得到的完整权重变化曲线满足G1阶连续, 由此生成的口型动画满足连续平滑的要求. 2.1时间分析 2.1.1 预处理阶段 预处理阶段消耗的时间主要用于对口型动画进行设计.本文方法需要设计师设计256段不同的口型动画, 为了提高设计的效率, 设计师可以将其中大部分权重变化曲线都定义为样条曲线, 通过定义控制点的位置, 即可简易地控制曲线的形状.假设设计师定义并调整每段口型动画平均需要15~20 min, 设计完成所有口型动画的时间则需要5~6 d. 2.1.2 运行时阶段 由于音素对应的动画片段已经在预处理阶段被设计师定义好, 本文方法在运行时阶段只需要完成音素的映射与曲线的拼接, 其中只涉及一些简单的线性插值计算.表2展示了本文方法分别处理Timit数据库中8段音频的耗时.观察表2可以得出, 本文的方法拥有运行时计算量小、时间消耗少的优点. 表2 本文方法运行时的耗时与准确率分析Table 2 Runtime time consumption and accuracyanalysis of our method 2.2口型动画效果分析 本文从根据Timit数据库中的8段音频生成的口型动画中, 分别以固定间隔选取了50帧与真实情况进行了比较, 表2的最后一列展示了比较的结果.本文选择了25名参与者, 请他们对本文的结果以及Xu等的结果进行评分, 评分的结果显示, 25名参与者中认为本文的结果更加真实的有13名, 认为Xu等的结果更加真实的仅有 8 名.由此可以得出, 本文的方法具有更加真实的结果. 以Timit数据库中的一段测试音频为输入, 最终生成的口型动画中一些关键帧的截图如图5所示.在图5中, 当前正在发音的单词从左到右、从上到下依次为“she”“had”“your”“dark”“suit”“greasy”.观察图5可以得出, 以本文的方法生成的口型动画基本上可以保持与语音信号的同步, 具有较高的精确度. 图5 本文生成的口型动画中关键帧的截图Fig.5 Snapshots of our result lip animation 本文的方法允许设计师在不重新定义权重变化曲线的情况下, 生成其他模型对应的口型动画.本文的方法作用在FaceGen建模软件预设的两个男性人脸模型上的效果如图6所示.观察图6可以得出, 定义好的权重变化曲线可以适应不同的人脸模型, 说明本文的方法具有较高的可重用性. 图6 本文方法作用在两个男性人脸模型上的效果Fig.6 Result of our method when acting on two male face models 本文提出了一种语音驱动的口型同步算法,该算法预定义了一个基本口型动作集合, 设计师可以通过定义该集合中元素的权重变化曲线, 设计不同音素对应的口型动画.本文提出了稳定阶段与变化阶段的概念, 并在此基础上对设计师提出了在设计口型动画时所需要遵循的3条约定.在运行时, 首先获取输入语音信号对应的音素序列, 然后将该序列映射到一系列口型动画片段上, 最后将这些片段互相拼接, 即可得到最终输出的结果.试验表明, 本文方法在运行时耗时较少,生成的口型动画基本上可以保持与语音信号的同步, 并且对于不同的人脸模型具有较高的可重用性. [1] KALBERER G A, MULLER P, GOOL L J V. Speech animation using viseme space [C] // Vision, Modeling, and Visualization Conference. Berlin, Germany: Akademische Verlagsgesellschaft Aka GmbH, 2002: 463-470. [2] CASSELL J, PELACHAUD C, BADLER N, et al. Animated conversation: rule-based generation of facial expression, gesture and spoken intonation for multiple conversational agents [C] // Proceedings of ACM SIGGRAPH 1994. New York, NY, USA: ACM, 1994: 413-420. [3] ALBRECHT I, HABER J, SEIDEL H P, et al. Speech synchronization for physics-based facial animation [C] // Proceedings of the International Conference on Computer Graphics, Visualization, and Computer Vision (WSCG’02). 2002: 9-16. [4] BREGLER C, COVELL M, SLANEY M.Video rewrite: driving visual speech with audio [C] //Conference on Computer Graphics and Interactive Techniques. 1997: 353-360. [5] CAO Y, TIEN W C, FALOUTSOS P, et al. Expressive speech-driven facial anima-tion [J]. ACM Transactions on Graphics, 2005, 24(4): 1283-1302. [6] BRAND M.Voice puppetry [C] // Proceedings of the 26th annual conference on Computer graphics and interactive techniques - SIGGRAPH '99. New York, NY, USA: ACM, 1999: 21-28. [7] BOZKURT E, ERDEM C E, ERZIN E, et al.Comparison of phoneme and viseme based acoustic units for speech driven realistic lip animation [C] // 3DTV Conference. 2007: 1-4. [8] DENG Z G, LEWIS J P, NEUMANN U. Synthesizing speech animation by learning compact speech co-articulation models [C] // Proceedings of Computer Graphics International (CGI2005). Washington, DC, USA: IEEE Computer Society Press, 2005: 19-25. [9] SENEFF S, ZUE V W. Transcription and alignment of the TIMIT database [M]. Recent Research Towards Advanced Man-Machine Interface Through Spoken Language, H. Fujisaki (ed.), Amsterdam: Elsevier, 1996: 515-525. [10] Singular Inversions. FaceGen [CP/OL]. http: //facegen.com/. [11] XU Y, FENG A W, MASELLA S, et al. A practical and configurable lip sync method for games [C] // Proc. Motion in Games, 2013: 109-118. [12] The center for speech technology research, The University of Edinburgh. The festival speech synthesis system [CP/OL]. http: //www.cstr. ed.ac.uk/projects/festival/. [13] Kawahara Lab, Kyoto University. Julius: open-source large vocabulary continuous speech recognition engine [CP/OL]. https: //github.com/julius- speech/julius. [14] WEI L, DENG Z G. A practical model for live speech-driven lip-sync [J]. IEEE Computer Graphics & Applications, 2015, 35(2): 70-78. (责任编辑:杜佳) ASpeech-DrivenLipSynchronizationMethod FANXinxin,YANGXubo (School of Software, Shanghai Jiao Tong University, Shanghai 200240, China) A speech-driven lip synchronization method is proposed to generate lip animation according to the input speech signal. The method contains two phases: preprocessing phase and runtime phase. In preprocessing phase, a basic lip pose set is predefined. Through adjusting the weight curves of the predefined lip pose set, animators can design lip animation segments corresponding to different phonemes. In runtime phase, the phoneme sequence of the input speech signal is acquired and mapped to a series of lip animation segments. These segments are then stitched together to generate the final result. Experimental results show that this method has high accuracy and low time consumption, and is reusable between different face models. speech-driven; lip synchronization; phoneme TP 301.6 A 1671-0444 (2017)04-0466-06 2016-12-19 国家自然科学基金资助项目(61173105,61373085);国家高技术研究发展计划(863)资助项目(2015AA016404) 范鑫鑫(1994—),男,河北邢台人,硕士研究生,研究方向为软件工程数字艺术.E-mail: smwlover3601102@sina.com 杨旭波(联系人),男,教授,E-mail: yangxubo@sjtu.edu.cn



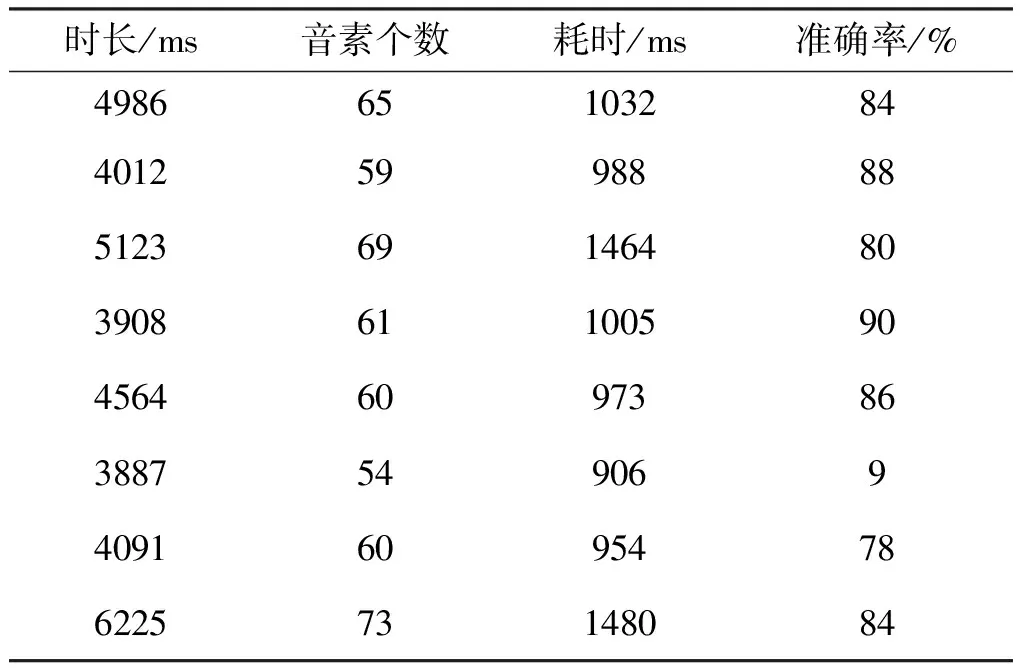
2 试验结果


3 结 语
猜你喜欢
科技经济导刊(2021年5期)2021-03-19北京教育·普教版(2020年9期)2020-10-09校园英语·中旬(2019年11期)2019-11-26阅读(快乐英语高年级)(2019年5期)2019-09-10电子制作(2019年14期)2019-08-20广西教育·D版(2019年6期)2019-07-11电子制作(2019年9期)2019-05-30小说界(2018年5期)2018-11-26速读·中旬(2018年8期)2018-10-23小学生时代·大嘴英语(2017年4期)2017-05-18
