
基于改进的深度神经网络的说话人辨认研究*
2017-11-03 00:46赵艳,吕亮,赵力
电子器件 2017年5期
赵 艳,吕 亮,赵 力
(1.南京工程学院电力工程学院,南京 211167;2.东南大学信息科学与工程学院,南京 210096)
基于改进的深度神经网络的说话人辨认研究*
赵 艳1*,吕 亮3,赵 力3
(1.南京工程学院电力工程学院,南京 211167;2.东南大学信息科学与工程学院,南京 210096)
说话人辨认技术在许多领域有着广泛的应用前景。首先研究了两种基本的深度神经网络模型(深度信念网络和降噪自编码)在说话人辨认上的应用,深度神经网络通过逐层无监督的预训练和有监督的反向微调避免了反向传播容易陷入局部最小值的缺陷,通过实验证明了当神经元个数达到一定数量之后深度网络模型是优于普通BP网络的,并且其性能随着网络规模的扩大而提升。考虑到大规模的深度网络训练时间较长的缺点,提出使用整流线性单元(ReLU)代替传统的sigmoid类函数对说话人识别的深度模型进行改进,实验结果表明改进后的深度模型平均训练时间减少了35%,平均误识率降低了8.3%。
说话人辨认;堆叠降噪自编码;深度信念网络;整流线性单元
语音是人的自然属性之一,由于每个人的语音中蕴含不同特征,如果将这些特征提取出来作为标识,就可以在不同场合辨别说话人的身份。说话人识别又可以分为两个范畴,即说话人辨认和说话人确认。另外按照说话内容又可以分为与文本有关的说话人识别和与文本无关的说话人识别[1]。随着数字信号处理理论与人工智能的不断发展,说话人识别技术在电子商务、军事、银行等各个领域有了迅速发展,是当今语音信号处理与识别领域的重要课题[2]。本文所做的工作是关于文本无关的说话人辨认的研究。
由于每个说话人的个人特征具有长时变动性,并且每个说话人的发音与环境、说话时的情绪和健康程度有密切关系,同时实际过程中还可能引入背景噪声等干扰因素,这些都会影响与文本无关说话人识别系统的性能。对此,Tagashira S[3]等人提出了说话人部分空间影射的方法,提取只含有个人信息的特征进行说话人识别,但该方法对于个人信息的长时变动没有达到满意的效果。Liu C S[4]等提出了基于最近冒名者的模型的方法,但因为必须计算所有的冒名者的似然函数,使得计算量的变大。Reynolds[5]提出了基于说话人背景模型的平均似然函数来计算得分;Matsui和Furui[6]提出了基于后验概率的模型。Markov和Nakagawa[7]将整个语句分成若干帧,计算每帧得分,获得总得分,但它没有考虑目标模型和非目标模型的帧似然概率的特性。近年来在说话人识别方法方面,基于高斯混合背景模型GMM-UBM(Gaussian Mixed Model-Universal Background Model)方法已成为主流的识别方法[8]。基于GMM超向量的支持向量机和因子分析方法[9-10]则代表GMM-UBM方法的新成果。
总之,以往关于说话人辨认的研究主要集中在GMM、HMM、SVM、LR等可以看作含有一层隐含层的模型。但是进入到21世纪,由于互联网、物联网产业的迅速发展,人类对大数据的处理的要求越来越高,传统的浅层模型无法适应这一需求,为了解决这一需求,深度学习模型应运而生。深度网络模型起源于BP网络,所不同的是它通过逐层预训练和反向微调完成了参数的训练,从而避免了参数陷入局部最小值。本文尝试探索深度神经网络在说话人辨认上的应用,并且使用ReLU(Rectified Linear Unit)对其进行改进。
1 改进的深度神经网络模型
深度学习的基本模型[11]目前通常有3种:深度信念网络(Deep Belief Network)、自动编码机(Auto-Encoder)和卷积神经网络(Convolutional Neural Network)。卷积神经网络主要应用在图像识别方面,因此本文主要研究前两种模型在说话人辨认上的应用。
1.1 深度信念网络
深度信念网络(DBN)[12]是由受限玻尔兹曼机(RBM)堆叠而成。一个RBM是由可视层v和隐含层h构成的两层结构。假设它们的各个单元都服从伯努利或高斯分布。再加上连接权重w、两层的偏置,我们便可以计算RMB的能量函数。它是关于可视层单元和隐藏层单元的联合分布。在训练RBM时采用对比散度(CD)算法简化计算。将多个RBM堆叠就形成了DBN,下层的RBM的输出作为输入送给一层。逐层进行训练,最后将网络参数送给普通的神经网络,使用BP算法进行有监督的微调[13]便完成了整个DBN的训练。
1.2 降噪自编码
降噪自编码(SDAE)是自动编码机的一种,整体结构与MLP相同。只是训练的方式有所不同。当我们对每一层网络单独训练的时候[14],往往发现新得到的特征对前一层的特征对于研究对象有更好的表达能力。假设某一层有N个神经元,那么我们首先构造一个N-N的两层网络,使用上一层给予的输出作为该层的输入训练此两层网络直至收敛,并且将输出作为输入送给下一层。所有层网络训练结束和前面描述的DBN一样进行BP微调。降噪编码机的原理[15]是我们人为的在每一层的输入上随机叠加少量的噪声然后开始训练,这样可以防止数据的过拟合并且可以很好地抑制噪声[16]。
1.3 整流线性单元
Hinton和Nair于2008年在RBM上使用整流线性单元[17]ReLU(Rectified Linear Unit)完成了分类问题。因此我们设想使用ReLu作为深度网络的神经元代替传统的sigmoid或者tanh函数。ReLu的激活函数的数学表达式为:max(x,0),如图1所示。

图1 ReLU激活函数
从生物学角度来讲,生物学家研究了突触对于输入信号的激发率,sigmoid类函数在0出具有稳定的状态并且具有对称性,这都与生物学激活函数矛盾。而ReLu则满足这两个条件。再者,研究发现人类神经元的编码方式具有稀疏性,同一时间只有约1%~4%的神经元被激活。但是传统的没有经过预训练的BP网络在不适用稀疏性限制条件的情况下使用sigmoid类函数不能满足稀疏性条件。Bengio等证明ReLU在MNIST、CIFAR10、NORB等训练集上的表现是稀疏的,因此考虑采用ReLU对深度神经网络进行改进。
ReLU存在的一个问题是它的函数值是无界的,因此对于未经预训练的网络权重和偏置需要进行不同程度的调整。更准确地说,对于第i层网络,我们有一个系数αi,然后将权重和系数调整为:
Wi=Wi/αi
(1)
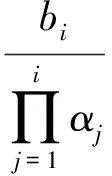
(2)
网络的输出修改为:

(3)
f(x,θ)=W′max(Wx+b,0)+b′
(4)
我们使用以下方案对其就行修正:
对编码层的激活值进行归一化到0和1之间,然后在重构层使用sigmoid函数,使用交叉熵作为代价函数:

(5)
使用DBN作为预训练模型时,为了让每一个神经单元表达更多的信息,Hinton提出将伯努利单元看M个伯努利单元的重复叠加[18],这些单元使用相同的权值和偏置。我们使用加噪的ReLU(NReLU):max[0,x+N(0,v)]代替原先的二值单元。其中N(0,v)代表均值是0,方差是v的高斯分布。实验证明使用NReLU进行预训练的RBM识别效果要好于普通的RBM。
2 实验与分析
2.1 实验语音数据库
本文实验采用的数据库是ELSDSR(English Language Speech Database for Speaker Recognition)。ELSDSR数据库是一款专门用于说话人识别的数据库。它由丹麦科技大学的数学信息系师生共同录制完成。该数据库总共包含23名说话人数据,其中有21名丹麦人,1名爱尔兰人和1名加拿大人。这些人员中有10名女性和13名男性。语音的采样频率为16 000Hz。经过计算,总体训练数据和测试数据的平均每人的时长分别为82.9 s和17.6 s。本文的实验是基于该数据库所有23人的语音完成的,特征参数取2阶差分MFCC,帧长取16 ms。
2.2 参数设置与结果分析
首先本文研究了网络模型对深度网络识别效果的影响,取每个说话人10 s语音作为训练数据,测试时间为2 s。网络结构分别使用1、2、3层隐含层。神经元数目分别使用20、50、100、200、400。为了方便讨论我们设置每层的神经元数目相同。对于初始参数的设置,下列参数的选择将从这些范围内手动选择以获取最优识别率:BP学习率(0.1,0.05,0.02,0.01,0.005),预训练学习率(0.01,0.005,0.002,0.001),加噪系数(0,0.1,0.2,0.4),稀疏系数(0.02,0.05,0.1,0.2)。图2显示了3种模型不同结构下的最优错误识别率。

图2 错误率随网络规模变化图
观察图2,当隐含层数较少或者神经元个数较少时没有经过预训练的BP网络性能较优,当只有1层隐含层时,神经元个数达到200时SDAE的错误率才和BP的相当,而当隐含层数为2层和3层时,神经元个数达到100和50时SDAE的性能就将接近并超过BP。DBN也同样,可以发现神经元数目较少的情况下SDAE的性能与DBN相比较优,神经元数目较多的情况下则相反。可以看到,过少的隐含层数及隐含节点数会降低深度模型的性能。原因可以这样解释,预训练模型的作用是提取输入特征中的核心特征,由于稀疏性条件的限制,假设神经元个数过少,对于一些输入样本的输入,只有少量的神经元被激活,而这些特征无法代表原始的输入,因此丢失了一些信息量,造成了性能的下降。虽然网络规模越大深度模型的性能越好,但同时训练时间也加长了。
ReLU激活函数的导数为1,极大地简化了反向传播算法的计算,因此可以有效提升模型的训练速度。
下面我们分别对使用sigmoid、ReLU、softplus的BP、SDAE、DBN模型进行了说话人识别实验。BP模型即未经过预训练的深度网络。同样,对于每个说话人使用10 s的训练数据,测试时间为2 s。每一种模型都使用3层隐含层,每层有100个神经元。对于SDAE,sigmoid作为激活函数时我们使用交叉熵作为重构误差,而ReLU和softplus作为激活函数时用平方误差作为重构误差。对于预训练深度模型加噪系数取0.05。对于所有的学习率,我们在(1,0.1,0.01,0.001)中间选取最优。迭代终止条件设为误差小于0.001。并且我们对目标函数添加了惩罚系数为0.01的L2惩罚因子防止参数过大。下表分别显示了3种函数在不同模型下的识别效果以及训练时间。

表1 不同激活函数与深度模型结合的误识率

表2 不同激活函数与深度模型结合的训练时间
分析上表可以得出以下两点结论:
(1)是否进行预训练对ReLU性能的发挥取重要的作用。我们发现在未经预训练的情况下,ReLU的误识率为12.03%,相比于sigmoid函数下降了14个百分点,性能甚至超过预训练的模型,而在经过预训练的情况下ReLU的识别效果并未有明显的改善,DBN使用ReLU误识率下降比SDAE多,从某种意义上来说RBM与ReLU更匹配。因此是否适当调整预训练模型以改善ReLU的识别率值得继续研究。
(2)从训练时间上看,3种函数对应的训练时间分别为ReLU 深度神经网络模型被大量应用于计算机视觉的研究,本文探索性地将其应用于说话人辨认。基于ELSDSR数据库进行了全面的实验分析,证明了当隐层节点数超过一定数量时,深度神经网络的识别效果是优于普通的BP网络的,并且随着网络规模的扩大其性能越好,过少的隐含层和过少的节点数会影响深度模型的性能。但是注意到随着深度网络模型的扩大,其训练时间明显增长,为了解决这一问题,本文提出将ReLU应用于说话人辨认的深度模型,分别将其应用于未经预训练和经过预训练的深度网络,实验结果表明改进后的深度模型平均训练时间减少了35%,平均误识率降低了8.3%,并且网络的平均稀疏度有了明显提升。但是ReLU对经过预训练的深度模型的提升效果并不明显,平均误识率仅仅降低了5.5%,远低于其对未经预训练的网络性能的提升,因此未来的研究工作可以着眼于改进深度模型的结构和训练算法以和ReLU有效结合。 [1] Abu El-Yazeed M F,El Gamal M A,El Ayadi M M H. On the Determination of Optimal Model order for GMM-Based Text-Independent Speaker Identification[J]. Journal on Applied Signal Processing,2007(8):1078-1087. [2] Formisano E,de Martino F,Bonte M,et al. Who’s Saying What?Brain-Based Decoding of Human Voice and Speech[J]. Science,2008,322:970-973. [3] Tagashira S,Ariki Y. Speaker Recognition and Speaker Normalization by Projection to Speaker Subspace[J]. IEICE,Technical Report,1995,SP95-28:25-32. [4] Liu C S,Wang H C. Speaker Verification Using Normalization Log-Likelihood Score[J]. IEEE Trans Speech and Audio Precessing,1980,4:56-60. [5] Douglas A Reynolds. Speaker Identification and Verification Using Gaussian Mixture Speaker Models[J]. Speech Communication,1995,17:91-108. [6] Matsui TFurui S. Concatenated Phoneme Models for Text Variable Speaker Recognition[C]//Proc IEEEInter Conf on Acoustics,Speech,and Signal Processing(ICASSP’93)1993:391-394. [7] Markov K,Nakagawa S. Text-Independent Speaker Recognition System Using Frame Level Likelihood Processing[J]. Technical Report of IEICE,1996,SP96-17:37-44. [8] Dehak N,Dehak R,Kenny P,et al. Comparison between Factor Analysis and GMM Support Vector Machines for Speaker Verification[C]//The Speaker and Language Recognition Workshop(Odyssey 2008). Stellenbosch,South Africa:ISCA Archive,January 2008:21-25. [9] Campbell W M,Sturim D E,Reynolds D A,et al. SVM Based Speaker Verificationusing a GMM Supervector Kernel and NAP Variability Compensation[C]//IEEEInternational Conference on Acoustics,Speech and Signal Processing. Toulouse:IEEE,2006,1:97-100. [10] Ferras M,Shinoda K,Furui S. Structural MAP Adaptation in GMM Super Vector Based Speaker Recognition[C]//IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP). Prague:IEEE,2011:5432-5435. [11] Bengio Y. Learning Deep Architectures for AI[J]. Machine Learning,2009,2(1):1-127. [12] Safari P,Ghahabi O,Hernando J. Feature Classification By Means of Deep Belief Networks for Speaker Recognition[J]. Eusipco,2015. [13] Kenny P,Gupta V,Stafylakis T,et al. Deep Neural Networks for Extracting Baum-Welch Statistics for Speaker Recognition. Odessy,2014. [14] Erhan D,Bengio Y,Courville A,et al. Why Does Unsupervised Pre-Training Help Deep Learning[J]. Journal of Machine Learning Research,2010,11(3):625-660. [15] Vincent P,Larochelle H,Bengio Y,et al. Extracting and Composing Robust Features with Denoising Autoencoders[C]//Machine Learning,Twenty-Fifth International Conference,2008:1096-1103. [16] Jiang Xiaojuan,Zhang Yinghua,Zhang Wensheng,et al. A Novel Sparse Autoencoder for Deep Unsupervised Learning[C]//Sixth International Conference on Advanced Computational Intelligence,2013:256-261. [17] Nair V,Hinton G E. Rectified Linear Units Improve Restricted Boltzmann Machines. Proc Icml,2010(1):807-814. [18] Jaitly N,Hinton G E. Learning a Better Respresentation of Speech Soundwaves Using Restricted Boltzmann Machines. ICASSP,2011:5884-5887. ResearchonSpeakerIdentificationBasedonImprovedDeepNeuralNetwork* ZHAOYan1*,LüLiang3,ZHAOLi3 (1.School of Electric Power Engineering,Nanjing Institute of Technology,Nanjing 211167 China;2.School of Information Science and Engineering,Southeast university,Nanjing 210096,China) The technology of speaker identification will be used in many areas in the future. Firstly,a research is made on the use of two basic Deep Neural Network models which refer to Stacked Denoising-Autoencoders and Deep Belief Network on speaker identification. By pre-training layer-wisely without labels and back fine-tuning with labels,Deep Neural Network has overcome the shortcoming that is easy to fall into local minimum caused by back propagation. The experiments proves that Deep Network Model performs better than normal BP Network when the amount of neurons is bigger than certain number and its performance grows with the scale of Network enlarges. Considering the training time of large Deep Model is too long,this text proposes using Rectifier Linear Unit to replace traditional sigmoid function to improve deep model on speaker identification. The results of experiment show that the training time and error rate of improved deep model has decreased by 35% and 8.3% respectively. speakeridentification;stacked denoising-autoencoders;deep belief network;rectifier neural network 10.3969/j.issn.1005-9490.2017.05.034 项目来源:国家自然科学基金项目(61301219);南京工程学院校级项目(YKJ201107);2014年青蓝工程项目 2016-11-01修改日期2016-11-25 TN912.3;TP317.5 A 1005-9490(2017)05-1229-05 赵艳(1978-),女,陕西宝鸡人,2011年东南大学信息科学与工程学院博士毕业,获工学博士学位,现为南京工程学院讲师,研究方向为语音信号处理,lvzhuweng2001@163.com。3 结语

猜你喜欢
中国机械工程(2022年22期)2022-11-25
中国机械工程(2022年7期)2022-04-20
自然杂志(2021年6期)2021-12-23
电子制作(2019年19期)2019-11-23
中国机械工程(2019年17期)2019-09-19
现代装饰(2018年5期)2018-05-26
中国机械工程(2018年4期)2018-03-06
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
电源技术(2015年5期)2015-08-22
