
特征显著性的车辆目标检测算法
2017-11-14 03:10刘玉春
河南科技大学学报(自然科学版) 2017年1期
程 全 ,樊 宇,刘玉春 ,程 朋
(1.周口师范学院 a.机械与电气工程学院;b.网络工程学院,河南 周口 466001;2.国机精工有限公司,河南 郑州 450000)
特征显著性的车辆目标检测算法
程全1a,樊宇1b,刘玉春1a,程朋2
(1.周口师范学院 a.机械与电气工程学院;b.网络工程学院,河南 周口 466001;2.国机精工有限公司,河南 郑州 450000)
针对运动目标检测不适合实时性应用场合的问题,提出了一种将无监督特征学习和显著性检测相结合的地面车辆目标检测算法。通过学习得到表示车辆目标的局部特征并进行编码,根据这些特征对整个图像进行显著性检测,获得候选目标区域。通过相关分析去除那些高度相关的特征,有效抑制背景,突出显著对象。
特征学习;视觉字典;特征提取
0 引言
近年来,机载视觉监视系统正逐步应用于地面车辆活动监视、高速公路车辆流量统计和战场情报数据提取等方面。这些系统所具有的各类功能中,地面车辆目标检测是最基本和最重要的。由于背景变化、高杂波、视角变化以及计算资源有限等,使得某些问题变得难以处理。
目前,最为常规的目标检测方法是基于Viola和Jones提出的滑动窗口检测框架[1]。这类方法通常需要提取大量特征,并综合这些特征通过机器学习形成集成分类器,采用级联结构来减少计算量。对一般视觉目标的检测,通常采用尺度不变特征转换(scale-invariant feature transform,SIFT)、方向梯度直方图(histogram of oriented gradient,HOG)、局部二值模式(local binary pattern,LBP)和Gabor滤波器等人工特征表示目标[2],而通过无监督学习方法,则能从数据中习得具有更强表示能力的特征[3-4],相比于传统特征,这类特征的提取要耗费更多的时间和资源,而传统特征如Harr特征可用积分图像方法获得很高的计算效率[5-6]。文献[7-8]针对自然场景中背景复杂多变的特点,提出了一种基于边界先验的图像显著性检测方法。该方法能够在自然场景中突出不同大小的显著目标。但是,在显著目标偏离图像中心接触到图像边界,以及目标与背景的颜色对比度较低的情况下,会产生错误的检测结果。
本文提出了一种基于图像面片的无监督特征学习和视觉显著性检测的地面车辆目标检测算法,首先,将图像生成一个目标类别特异的视觉特征字典;然后在新的特征空间对整幅图像进行显著性检测;最后用目标分类器判断是否属于车辆目标,从而得到最终的显著图。
1 基于特征显著性检测的地面车辆目标检测
1.1构造数据集
以美国某实验室合成的车辆目标数据库NORB[9]为范本构建车辆目标数据集。实际应用要求以复杂自然场景图像为背景检测车辆目标,因此,选用可能的各类自然场景图像构建非车辆目标数据集。以美国某实验室航拍的视频数据库VIVID[10]为范本构建测试数据集。
1.2特征学习
采用K均值聚类学习车辆目标的视觉特征字典。首先在车辆目标中提取大量面片图像以供学习。在各种光照、姿态和种类的车辆目标图像中,随机选取s×s像素大小的面片图像,面片图像的数量为N,将每个面片图像保存为1个M维向量xn,M=s×s,所有面片图像形成一个M×N的数据集X=[x1,x2,…,xN]。
为了使聚类算法易于获得s×s像素空间上的局部特征,对数据集作预处理。首先把xn标准化为均值为0、标准差为1的向量,随后对整个数据集作白化处理:
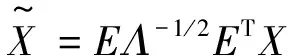
(1)
其中:Λ与E来自对协方差矩阵的特征值分解。
E{XXT}=EΛET,
(2)
Λ-1/2是对角阵,对角线上为特征值矩阵Λ中对角元平方根的倒数:
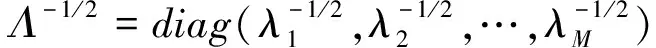
(3)
经白化处理后,协方差矩阵变为单位阵:

(4)
经预处理后,采用K均值聚类算法进行无监督学习,设定K个聚类中心,计算后得到K个聚类中心作为视觉特征字典D=[d(1),d(2),…,d(K)]。
特征学习习得的特征主要由不同宽度、方向和长度的边条构成,也包括稍小的点与稍大的斑。其中部分特征的方向、长度完全相同,只是位置略有偏移,说明特征存在冗余,主要是因为聚类中心个数K是人为指定的,与数据集真实分布情况有差别。送入学习的面片图像是随机选取的,因此会将同一个边条截取出不同的空间“相位”,但这种冗余并不影响目标识别的准确性。许多基于面片图像特征学习的研究说明,人为选取字典大小得到的冗余特征集可以取得很好的分类结果,而且识别结果随着使用更大规模的字典而改善,往往比人工选取的“正交化”的、低冗余的特征集效果更好[11]。
1.3显著性检测
用习得的视觉特征字典D=[d(1),d(2),…,d(K)]对原始图像进行编码,得到K个特征响应,再对各个响应zk计算显著性。为了快速计算,对原始图像编码时直接采用二维卷积:
zk=d(k)*I,
(5)
其中:I为原始图像;*为二维卷积运算;得到的响应zk和原始图像尺寸一样,将其视为一张图像进行显著性检测,并将K个显著图像累加合并。
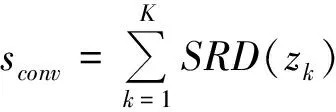
(6)
其中:SRD为某种显著性检测算法;sconv为合并后的结果,在sconv上响应强的区域即为待识目标区域。

图1 在特征空间上进行SR显著性检测的结果
本文采用频谱残差[12](spectral residual,SR)法进行显著性检测。在特征空间上作显著性检测,检测结果如图1所示。对于车辆目标检测,SR显著性检测方法可以在保证车辆目标区域出现强响应的同时尽可能地抑制背景区域,使高响应区域更集中于目标,在很大程度上排除了路面杂波干扰。
1.4特征选择
利用K均值聚类算法进行无监督学习,可以得到车辆目标的视觉特征词典,习得的100个视觉词汇代表着车辆的边条特征。通过分析它们之间的相关性可知,视觉词汇之间存在着大量冗余。
目标检测过程需要与特征模板进行匹配运算,大量冗余的特征模板意味着高度重复的卷积运算,这不满足实时计算的应用需求,因此需要采用相关分析进行特征选择,保留重要特征,去除冗余特征,但不能降低检测性能。
1.5目标识别
对车辆目标区域的判别是一个“目标与非目标”的二类分类问题。以各个待识目标区域为一张待分类的图像,将各个面片特征响应形成一张图像对应一个特征向量,用于后续目标识别,分为两步进行。首先对待识目标图像的各个面片进行编码表示。若图像I大小为w×w像素,以单个像素为步长取s×s像素的面片,从I中取(w-s+1)×(w-s+1)个面片。每个面片记为xi,采用基元数为K的特征字典进行编码,形成F(xi)=[f1(xi),f2(xi),…,fK(xi)]的K维表示。
对目标识别,几种常见编码算法识别结果无显著差别,且可与字典学习时所用编码算法不同。通过K均值聚类可得到K个基元的字典D,同样可计算聚类归属的0-1编码,
(7)
可以采用比式(7)宽泛一些的编码方式,
fk(xi)=max{0,μ(z)-zk},
(8)
2 实验结果与分析
实验硬件环境为1台4核2.2GHzCPU,8G内存的台式计算机。算法实现采用MATLAB与C++混合编程,显著性检测软件用C++编写。空地车辆目标数据集为VIVID数据集,使用其中不同视频通道的几段。
使用目标归类数据集NORB中的车辆目标图像学习特征。NORB数据库是用于目标归类的数据集,涉及多种光照、尺度和姿态变化。使用其中truck与car两类图像,共9 720张图像用于特征学习[10]。每张图像上随机截取4个6×6像素的小块,这样式(1)中用于特征学习的数据X的维数是36×38 880。特征字典的大小取K=100。虽然文献推荐使用更大的K以获得更好的识别效果(如1 600,甚至4 000),但是实验发现K=100性能已经很好了。
SR检测算法代码来自文献,将其封装为MATLAB可调用函数。支持向量机(supportvectormachine,SVM)算法采用LIBSVM,采用L2-SVM训练目标分类器,模型参数由交叉验证选择。
实际上,为适应目标尺寸变化,可以采用金字塔结构,引入过完备空间模板,通过集成学习选取特征,以提升检测速率与精度。应用多分辨率分析的方法,将各图像序列分解成多层金字塔数据结构,对每层分辨率图像进行滤波及显著性分析,得到相应的特征响应图,然后将各个特征响应图进行融合,这样可使响应值较大的点更为突出,甚至可以突出目标车辆的轮廓。图像中车辆所在区域的显著性得到了有效增强,而对周围背景的显著性进行了抑制,有利于目标区域的准确提取。
图2给出了在VIVID数据集上的检测结果。由图2可知:在场景复杂多变、图像对比度低、目标响应弱、图像质量退化和干扰物遮挡等多因素影响的情况下,本文的车辆目标检测方法具有较好的稳健性。
3 结束语
本文提出了一种将无监督特征学习和显著性检测相结合的地面车辆目标检测算法。随机采集车辆目标图像局部面片形成训练数据,使用K均值聚类生成视觉特征字典,即通过学习得到表示车辆目标的局部特征。基于习得的特征对待检目标图像进行编码,并根据这些特征对整个图像进行显著性检测,从而获得候选目标区域。显著性检测可以看作一种模拟人类视觉系统的选择注意机制的生理过程。目标分类器只针对那些显著性区域,从而保证了检测的高效性。为了节省特征提取所需的计算时间,通过分析习得特征之间的关系,去除那些高度相关的特征,进一步提高了检测的准确性。通过显著性检测,待检图像中只有较少的候选目标区域被送到分类器。该方法能更有效地通过显著分析,突出显著对象。
[1]LI Q,GU Y,QIAN X.Latent-community and multi-kernel learning based image annotation[C]//Proceedings of the 22nd ACM International Comference on Information & Knowledge Management.New York,USA:ACM,2013:1469-1472.
[2]EVERINGHAM M,GOOL L V,WILLIAMS C K I,et al.The pascal visual object classes(VOC) challenge[J].International journal of computer vision,2010,88(2):303-338.
[3]蒋文,齐林.一种基于深度玻尔兹曼机的半监督典型相关分析算法[J].河南科技大学学报(自然科学版),2016,37(2):47-51.
[4]ZEILER M D,TAYLOR G W,FERGUS R.Adaptive deconvolutional networks for mid and high level feature learning[C].Proc.2011 IEEE International Conference on Computer Vision.2011:2018-2025.
[5]程全,马军勇.基于纹理和梯度特征的多尺度图像融合方法[J].清华大学学报(自然科学版),2014,54(7):935-941.
[6]PEELEN M V,LI F F,KASTNER S.Neural mechanisms of rapid natural scene categorization in human visual cortex[J].Nature,2009,460:94-97.
[7]范青,于凤芹,陈莹,等.自然场景下基于边界先验的图像显著性检测[J].计算机工程,2016,42(1):278-281.
[8]张颖颖,张帅,张萍,等.融合对比度和分布性的图像显著性区域检测[J].光学精密工程,2014,22(4):1012-1018.
[9]ZHANG D Q,ZHOU Z H,CHEN S C.Semi-supervised dimensionality reduction[C]//Proceeding of the 7th SIAM International Conference on Data Mining.2014:629-634.
[10]ZHENG W M,ZHOU X Y,ZOU C R,et al.Facial expression recognition using kernel canonical correlation analysis[J].IEEE transactions on neural networks,2014,17(1):233-238.
[11]范青,于风芹,陈莹.自然场景下基于边界先验的图像显著性检测[J].计算机工程,2016,42(1):278-281,286.
[12]CHANG C C,LIN C J.LIBSVM:a library for support vector machines[J].ACM transactions on intelligent systems and technology,2011,27(2):1-27.
国家自然科学基金项目(61401526);河南省自然科学基金项目(152300410134);河南省高等学校重点科研软科学计划基金项目(15A880023)
程全(1978-),男,河南沈丘人,副教授,硕士,主要研究方向为智能控制.
2016-06-20
1672-6871(2017)01-0048-04
10.15926/j.cnki.issn1672-6871.2017.01.010
TP391
A
猜你喜欢
图学学报(2021年2期)2021-05-13
中国煤炭工业(2019年5期)2019-11-04
铁道通信信号(2019年6期)2019-10-08
小学阅读指南·低年级版(2019年11期)2019-07-01
小天使·一年级语数英综合(2017年11期)2017-12-05
雷达学报(2017年6期)2017-03-26
读者(2016年14期)2016-06-29
互联网天地(2016年1期)2016-05-04
幸福家庭(2016年3期)2016-04-05
智能系统学报(2015年4期)2015-12-27
