
基于词典与机器学习的藏文微博情感分析研究
2017-12-07 02:16杨志
软件 2017年11期
杨 志
(青海民族大学计算机学院,青海 西宁 810000)
基于词典与机器学习的藏文微博情感分析研究
杨 志
(青海民族大学计算机学院,青海 西宁 810000)
随着互联网自媒体的兴起,越来越多的藏族人开始使用微博,并在其发表自己的观点和看法,与微博相关的藏文信息处理研究随之得到了学术层面的广泛关注。本文根据藏文微博的行文特征,提出了基于词典与机器学习算法多特征融合的藏文情感分类方法。在特征选择方面,运用藏汉情感词、表情符号等作为特征项。实验发现由于所构建的情感词典覆盖率不够髙导致分类效果不太理想。为了优化实验结果,本文引入了信息增益特征选择的措施,实验显示该措施完全较人工选择特征方法的分类结果有较大的提高。针对特定领域,实验证明融合后的分类效果有了一定程度的提升。
自然语言处理;情感分类;微博;机器学习;特征选取;特征项权重
0 引言
微博(微型博客 MicroBlog),当下较为流行的一种自媒体,是通过用户关系来实施分享、传递以及获取信息的平台。字符限制在140字(包括标点符号)之内,通常是为了表达自己的心情或看法,其更注重时效性和随意性。情感分析(Sentiment Analysis)也称为倾向性分析、主观分析(Subjectivity analysis)、观点挖掘(Opinion Mining)等,是对文本情感进行分析、处理、推理和归纳的过程。对于时事与热点话题评论的情感分析,有助于商家及时掌握产品的反馈信息,也有利于政府机构收集与分析舆情信息。目前国内外关于中文文本的情感挖掘的相关工作研究已经非常成熟[1]。但是,对于藏文尤其短文本领域的相关研究工作并未得到深入开展。藏文微博相较于中文微博,存在着以下几方面的特点,首先在内容上,藏文微博表述更为精炼且简短,所表述主题相对集中,其次,从表述形式看,双语甚至是多语种混合表达的情况较多。
本文根据藏文微博文本的特点,借鉴当前基于词典和基于机器学习的情感分析的方法各自存在的优劣,针对藏文微博文本,提出了基于词典和机器学习相结合的措施,用于藏文短文本方面的研究。
1 相关工作
文本情感分类,目前主要使用的两种技术实施方案,一是情感词典方法,二是机器学习方法。基于情感词典的分析方法,依据文本中所包含的正向和负向情感词的个数进行情感分类;而基于机器学习的方法,则依据文本特征,标注训练集和测试集,使用各种分类算法(KNN、NB、RF、SVM、DL等),进行情感分类。
1.1 基于情感词典的方法
基于情感词典的分类方法,使用一个标有极性的情感词典,其内容主要包含正向情感词和负向情感词。利用情感词典,统计待分析藏文本中的正向和负向情感词的数量,继而通过两者的差值来实施情感极性的判断[2]。由于藏文微博中出现藏汉混排的情况较为普遍,我们分别建立了藏文和中文情感词典。中文情感词典基于Hownet和NTUSD提供的第三方情感语料库建立,藏文情感词典则采取人工采集方式,选择情感极性较为饱满和使用较为普遍的情感词汇作为基准词汇,然后从微薄文本中抽取形容词、名词和动词并将其作为情感词的候选词,使用基于扩展的点间互信息(so-PMI)的方法计算候选词与基准词的相似度,从而判断候选词的情感倾向,将情感倾向极性较强的词语收录到藏文词典[3]。
1.2 基于机器学习的方法
基于机器学习的分类方法,通常是人工标注训练集和测试集,通过对文本进行特征选取、特征降维、特征权重计算等,然后利用一些常见的分类器对文本进行分类的过程。常见的分类算法有朴素贝叶斯算法(Naive Bayes)、支持向量机(Support Vector Machine,SVM)算法、最大熵(Maximum Entropy)算法、K 最近邻(K-Nearest Neighbor,kNN)算法等[4]。在本实验中采用SVM作为情感分类的方法。
2 词典与机器学习相结合的藏文微博文本情感分析
文本情感分析以带有主观性信息的文本为研讨对象,目标是辨别、分类、抽取、标注文本里表述的观点、情感。选取的含有表情图片以及情感词汇等情绪特征的文本后,先进行自动和人工标注,然后利用机器学习分类算法进行分类,并提出算法改进、建立分类模型,为文本分析的智能系统提供帮助,图1为本实验构建藏文向量空间模型的过程。
2.1 数据预处理
使用新浪微博和网络爬虫采集微博数据,对微博数据进行预处理,去除数据中的噪声,使用改进的CRF算法工具对微博数据进行分词处理[5]。
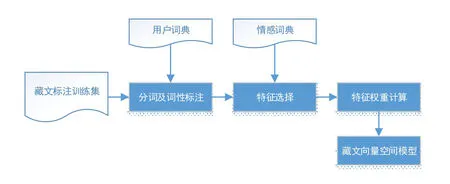
图1 藏文微博情感分析过程Fig.1 The sentiment analysis process of tibetan microblog

表1 藏文语料类型Tab.1 T ibetan corpus type
2.2 构建词典库信息

表2 基础情感词典Tab.2 Basic semantic lexicon
2.3 特征选取
在文本分类中,文本特征词的获取通常是基于词典或者使用一些分词算法以及词频统计的方式,从文档中选出尽可能多的词、词组和短语,由它们来构成文档矢量[6]。这种措施一方面将会造成文本特征空间的髙维性和文本向量的稀疏化,极大的耗费计算资源,并给后续的文档处理带来巨大的计算开支,降低了处理过程的效率,因而须采取特定的措施进行文档矢量的降维。目前常见的方式是对文本特征进行选择,如下:
(1)词频。词频方法是最简单的文本特征选择措施,根据词语出现的频次区分词的重要程度,最终依照词频从高到低排序,取前K个词作为特征。
(2)信息增益。在信息増益中,越重要的特征,带给分类系统的信息越多。基于此来进行特征的选择信息増益是针对某个特征而言的,分别计算系统包括与不包括特征X的信息量,两者差值即是该特征给本体带来的信息量,即信息增益。按照信息增益从大到小的顺序取前K个词语作为特征[7]。
(3)卡方统计量。通过卡方检验得出词语与情感极性相关性,依照卡方值从大到小的次序取前K个词语作为特征。
2.4 特征权值计算
TF-IDF(Term Frequency-Inverse Document Frequency)是在词频的基础上使用了逆文档频率IDF,逆文档频率缩放因子把常见词的权重进行减小,提高了在该篇文档中出现频数高同时在总的语料中出现频数较低的特征的权重[8]。TF-IDF权衡特征的重要程度不仅仅与特征在该文档中呈现的频数有关,而且还与该特征在整个语料中的频数有关。本文基于TF-IDF进行权重计算,对公式实施归一化后TF-IDF计算公式变为:

3 实验结果及分析
3.1 实验数据
首先分析新浪微博上较为活跃的藏族微博博主,选择微博内容较为丰富且关注度较高的微博博主作为种子用户,通过社交网络(Social Network,SNS)关系,遍历朋友圈,利用微博 API接口以及爬虫工具从新浪微博上抓取了部分数据。因为新浪微博没有针对藏文微博做主题分类,所以首先进行人工分类和筛选[9];然后选取了三个不同的主题,分别对语料进行情感标注,作为接下来的实验数据。
3.2 实验结果
本文针对藏文微博短文本进行情感分析的分类过程中,以正确率、召回率、F值作为评价指标。计算公式如下:

其中,correct表示情感分类器分类正确的微博个数;propose指所有标注为该分类的数量;all为测试样本中人工标记的数量。
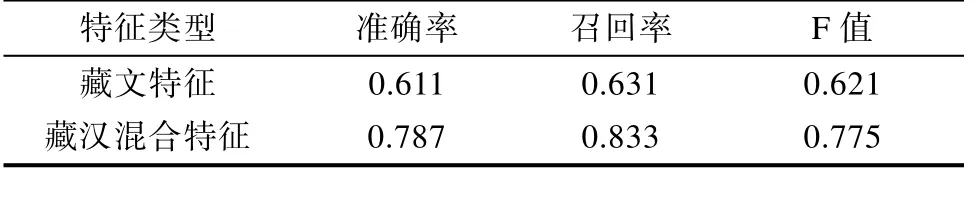
表3 双语和单语特征情感分析实验结果Tab.3 Bilingual and monolingual sentiment analysis
3.3 结果分析
实验结果说明,本文所提出的基于跨语言情感分类方法是行之有效的。基于多种特征选取方式和特征权值计算方法,随着所选特征维数的不断增长,情感分类结果正确率也不断提高[10],特征维度达到200维时,藏汉混合特征和藏文特征两种方式的测试结果的正确率都达到了顶点;当特征维数继续增长时,正确率开始出现了不同程度的回落。究其原因,由于测试集中的藏文微博文本语料普遍相对较短,选取的特征维数过高时会产生严重的数据稀疏问题,导致分类正确率下降。由此表明,并非特征选取的越多、特征维数越高,计算产生的分类效果就越好[11]。

图2 两种文本特征效果Fig.2 Two text feature effects
4 结论
本文针对藏文微博文本进行了初步研究,探讨了对其进行情感分析的方法。与中文微博文本的情感分析相关工作相比,藏文微博存在藏汉多语种混排的情况,采用抽取单语特征进行情感计算,并在此基础上建立藏汉情感词典,基于多种特征选取方式和特征权值的计算方法。研究并改进了目前情感分析的方法,并采取一系列实验对改进方法的效果进行了评估。结果表明,通过这些改进措施,使之更适合藏文情感分析方法,能够有效的对藏文微博进行分析和处理。当然本文实验还存在较大的提升空间,例如受制于现有分词系统,网络中的一些新词,无法识别;另外由于语料库规模较小,从而对藏文情感分类的结果也有不小的影响。
[1] 文坤梅, 徐帅, 李瑞轩. 微博及中文微博信息处理研究综述[J]. 中文信息学报, 2012, 26(6): 27-37.
[2] 徐军, 下宇新, 王晓龙. 使用机器学习方法进行新闻的情感自动分类[J]. 中文信息学报, 2007, (1): 95-100.
[3] 谢丽星, 周明, 孙茂松. 基于层次结构的多策略中文微博情感分析和特征抽取[J]. 中文信息学报, 2012, 26(1):73-83.
[4] 刘志明, 刘鲁. 基于机器学习的中文微博情感分类实证研究[J]. 计算机工程与应用, 2012, 48(2): 1-4.
[5] 李婷婷, 姬东鸿. 基于SVM 和CRF多特征组合的微博情感分析[J]. 计算机应用研究, 2015.
[6] 刘全超, 黄河燕, 冯冲. 基于多特征微博话题情感倾向性判定算法研究[J]. 中文信息学报, 2014, 28(4): 123-131.
[7] 徐琳宏, 林鸿飞, 杨志豪. 基于语义理解的文本倾向性识别机制[J]. 中文信息学报, 2007, (1): 96-100.
[8] 李培, 何中市, 黄永文. 基于依存关系分析的网络评论极性分类研究[J]. 可计算机工程与应用, 2010.
[9] 李海刚, 于洪志. 藏文文本情感分类系统设计[J]. 甘肃科技纵横, 2011, (1): 106-107.
[10] 张俊, 李应兴. 基于情感词典的藏文微博情感分析研究[J].珪谷, 2014, 7(20):
[11] 韩忠明, 张玉沙, 张慧, 等. 有效的中文微博短文本倾向性分类算法[J]. 计算机应用与软件, 2012, 29(10): 89-93.
Lexicon and Machine Learning Based Sentiment Analysis of Tibetan Microblogs
YANG Zhi
(Qinghai University For Nationalities, Xining 810007)
With the development of Web2.0 era, more and more Tibetans began to express their own opinions and views on microblog. The Tibetan information processing research related to Tibetan microblog has drawn wide attention from academic communities.According to the expression features of Tibetan micro-blogs, this paper puts forward a method of multi-feature sentiment analysis which based on three kinds of machine learning algorithms.In the aspect of feature selection, it used of emotional words, morphological sequences, emojis and other features.The experimental results indicate that the classification performance was not ideal due to the inadequate coverage of the emotional dictionary constructed.In order to address this problem, the information gain feature selection method is introduced in this paper, and the experiment shows that the method is better than the classification effect of artificial selection feature.In the field of film topic, it is found that the classifier effect of fusion is better than that of single classifier.
NLP; Sentiment classification; Microblog; Feature selection; Term weight
TP391
A
10.3969/j.issn.1003-6970.2017.11.008
本文著录格式:杨志. 基于词典与机器学习的藏文微博情感分析研究[J]. 软件,2017,38(11):46-48
青海民族大学校级理工科项目(2016XJQ06)
杨志(1979-),男,青海西宁人,专业技术职称:高级软件工程师,现从事的研究工作:自然语言处理,教育信息化及大数据。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
布达拉(2020年3期)2020-04-13
西夏学(2019年1期)2019-02-10
电影(2018年8期)2018-09-21
疯狂英语(双语世界)(2017年3期)2018-01-19
疯狂英语(双语世界)(2017年1期)2017-07-01
西藏大学学报(自然科学版)(2016年1期)2016-11-15
新闻传播(2016年17期)2016-07-19
当代修辞学(2013年4期)2013-01-23
