
结合注意力机制的新闻标题生成模型
2018-01-02 06:41李慧陈红倩马丽仪祁梅
山西大学学报(自然科学版) 2017年4期
李慧,陈红倩,马丽仪,祁梅*
(1.北京联合大学 管理学院,北京 100101;2.北京工商大学 计算机与信息工程学院,北京 100048)
结合注意力机制的新闻标题生成模型
李慧1,陈红倩2,马丽仪1,祁梅1*
(1.北京联合大学 管理学院,北京 100101;2.北京工商大学 计算机与信息工程学院,北京 100048)
针对新闻标题生成过程中的连贯性、一致性不佳的难题,提出了一种新闻标题生成模型,结合LSTM(Long Short-Term Memory)和注意力机制从新闻文章的文本中产生标题。模型编码部分,使用了BiRNN(bidirectional RNN)模型,解码部分使用了注意力机制。文章选用Gigaword数据集进行模型训练,实验表明提出的方法比基于RNN的模型在新闻文章标题生成问题上更为简明扼要。
新闻标题生成;注意力机制; LSTM;Gigaword数据集
0 引言
自动新闻标题生成是自动文本摘要的主要应用方面,文献[1-3]中指出文本摘要的目标是将大的文本段落生成一个简单的摘要。文献[4]对于生成一个10~15个词这样的非常短的摘要称为生成标题。
自动文本摘要是在保留文档意思的情况下,为文档创建一个连贯、翔实简单的概要。摘要系统大致可以分为两种类模型,一类是提取式(extractive)摘要模型,另外一类是抽象式(abstractive)摘要模型。提取式模型通过将原始文本中的重要片段剪切出来,重新组合成连贯的一段话,这段话就是摘要。抽象式模型是将文本的大意概括出来形成一段文字,这段文字不一定就在原始文本中呈现。
一般认为新闻标题生成是困难的事情,因为新闻标题是从新闻事件中提取出最关键的信息点,然后用更加精练的语言组合而成。新闻标题生成采用提取式方法,但是提取式文本有其固有的缺陷,其表现为比较简单,系统只是用模型选择出信息量大的句子,然后按照自然序组合起来输出即为摘要。但是摘要的连贯性、一致性很难保证,比如遇到了句子中包含了代词,简单地连起来根本无法获知代词指的是什么,从而导致效果不佳。
对于生成标题的研究目前已经有了很多实际的应用,如文献[5]在不含信息的数字化报纸文章标题中的应用。文献[6-9]将新闻标题看作是一个故事的简短陈述,让读者了解一个故事主要内容的简单概要。文献[10-11]指出递归神经网络(recurrent neural network,RNN)对于机器翻译的工作非常有效,已经应用于机器翻译和语音识别[12]。文献[13]提出了一些标题生成的应用框架。文献[14]对新闻文章的标题生成提供了数据集。文献[15]提出主题敏感神经模型,该模型通过文件主题指导,能够生成更准确的摘要。文献[16]通过借鉴人类在处理难理解的文字时采用的死记硬背的方法,提出了拷贝机制模型。将拷贝模式融入到了序列对序列模型中,将传统的生成模式和拷贝模式混合起来构建了新的模型,非常好地解决了超纲词问题。
本文提出了一种新的生成新闻文章标题的方法,文中提出的基于BiRNN的模型将模型中的解码器对输入的新闻文章内容进行摘要,通过控制摘要的长度作为新闻文章的标题,从而用来解决新闻标题生成的问题。模型编码部分使用BiRNN模型,解码部分使用了注意力机制。本文选用Gigaword数据集进行模型训练,实验证明本文提出的方法比基于RNN的模型在新闻文章标题生成问题上更为简明扼要。
1 新闻标题生成模型
传统的文本摘要方法,不管是句子级别、单文档还是多文档摘要,都严重依赖特征,随着深度学习的流行尤其是seq2seq(sequence to sequence)+attention模型在机器翻译领域中的突破,文本摘要任务也迎来了一种全新的思路。
本文提出了一个用于新闻标题生成任务的新闻标题生成模型。该模型编码部分,使用了BiRNN模型,解码部分使用了注意力机制。在该模型中每个单词可以“感知”到前后单词的意思,本文所借鉴的框架已经成功应用在语音识别的研究中。
1.1 Encoder-Decoder模型概念
Encoder-Decoder模型,又称做编码-解码模型,其根据一个输入序列x,生成另一个输出序列y。编码是将输入序列转化成一个固定长度的向量;解码就是将之前生成的固定向量再转化成输出序列。这种模型已经在翻译、文档提取及问答系统等得到了广泛的应用。在翻译中,输入序列是待翻译的文本,输出序列是翻译后的文本;在问答系统中,输入序列是提出的问题,输出序列是答案。模型示意图如图1所示。
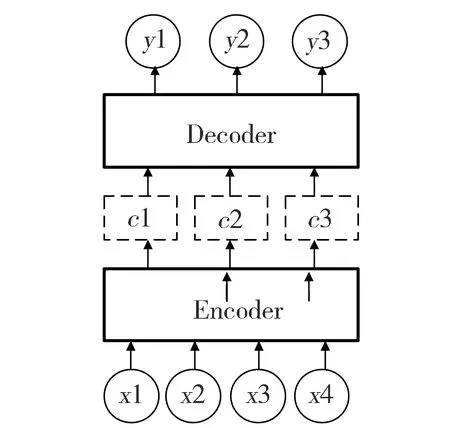
Fig.1 Framework of Encoder-Decoder model图1 Encoder-Decoder模型示意图
在RNN中,当前时间的隐藏状态是由上一时间的状态和当前时间输入决定的,即ht=f(ht-1,xt),在获得了各个时间段的隐藏层以后,将隐藏层的信息汇总,生成最后的语义向量c=q({h1,…,hTx})。同样可以将最后的隐藏层作为语义向量c即c=q({h1,…,hTx})=hTx。
解码阶段可以看作编码的逆过程。这个阶段,我们要根据给定的语义向量c和之前已经生成的输出序列y1,y2,…,yt-1来预测下一个输出的单词yt,如公式(1)所示。
yt=g({y1,y2,…,yt-1},c)
(1)
而在RNN中,上式又可以简化为下式:
yt=g(yt-1,st,c)
(2)
其中,s是RNN中的隐藏层,c是语义向量,yt-1表示上个时间段的输出,反过来作为这个时间段的输入。g则可以是一个非线性的多层的神经网络,可生成每个词语对应词典中yt的概率。
但是,Encoder-Decoder模型存在局限性即编码和解码之间的唯一联系是一个固定长度的语义向量c,编码器要将整个序列的信息压缩进一个固定长度的向量中。这样做有两个弊端,一是语义向量无法完全表示整个序列的信息,且先输入的内容携带的信息会被后输入的信息覆盖掉。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息,那么解码的准确度降低。
1.2 Attention模型
本文将Attention模型(注意力模型)引入Encoder-Decoder模型中。新的模型在产生输出的时候,将产生一个“注意力范围”表示接下来输出的时候要重点关注输入序列中的哪些部分,然后根据关注的区域来产生下一个输出,如此往复。模型架构如图2所示。
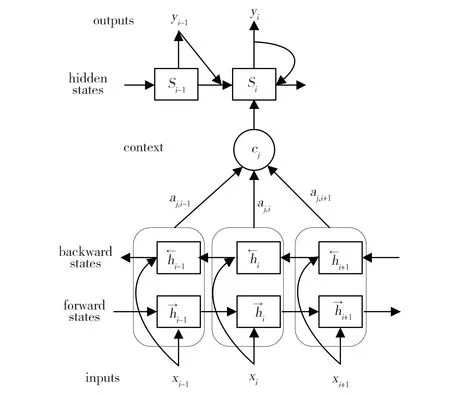
Fig.2 Framework of news headline generation图2 Attention模型的计算框架示意图
相比于经典的Encoder-Decoder模型,Attention模型最大的优点在于它不再要求编码器将所有输入信息都编码进一个固定长度的向量之中。相反,此时编码器需要将输入编码编成一个向量序列,在解码的时候,每一步会选择性的从向量序列中挑选一个子集进行进一步处理。这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。
将输入文档x表示为词语序列{x1,…,xM},其中每个词xi来自固定词汇v,新闻标题生成的流程是将x作为输入,将生成的短标题y={y1,…,yN}作为输出,其中N (3) BiRNN模型对每一个训练序列来说,向前和向后分别是一个循环神经网络,而且每一个都连接着一个输出层。这种结构能够为输出层中的每一个输入序列中的点提供完整的过去和未来的上下文信息。 本文提出的模型中使用了4层LSTM,每层有600个隐藏单位,使用dropout控制过拟合。所有参数的初始值都服从[-0.1,0.1]上的分布。在softmax层中对每个单词的偏差进行初始化,即在训练数据中出现的对数概率。使用的训练方法是RMSProp自适应梯度法,学习速率为0.01。对于RMSProp使用0.9的动量和0.9的衰减。且训练了9个回合,在第5个回合之后,每个回合都将训练速率减半。 此外,使用384组训练数据作为一个batch,修正了序列输入和输出长度的最大值,确保在解码器的第一步有正确的隐藏状态输入,并且保证输出序列在结束之前没有损失。 注意力机制可以用来帮助神经网络更好地理解输入数据,尤其是一些专有名词和数字。该机制在解码阶段起作用,通过将输出与所有输入的词建立一个权重关系,让确码器决定当前输出的词与哪个输入词的关系更大。但权重之和为1,用来计算每个输入单词在最后隐藏层生成过程的加权平均值。 注意力模型中的解码部分定义的条件概率如下: p(yi|y1…yi-1,x)=g(yi-1,si,ci) (4) 其中,yi-1为本次输入的上下文,si表示解码器i时刻的隐藏状态,其中si的计算公式如公式(5)所示, si=f(si-1,yi-1,ci) (5) 这里的条件概率与每个目标输出yi相对应的内容向量ci有关。 在传统的方式中,只有一个内容向量c。内容向量ci是由编码时的隐藏向量序列(h1,…,hTx)按权重相加得到。由于编码使用双向RNN,因此可以认为hi中包含了输入序列中第i个词以及词前后的一些信息。将隐藏层向量序列按权重相加,表示在生成第j个输出的时候的注意力分配是不同的。 ci计算过程就是注意力机制关键步骤,计算方法如下: (6) 其中ci表示解码阶段的第i时间序列,hj为对输入编码后的结果,传统的编码过程只能保留最后一个时刻作为编码的输出,这里对所有编码输出分别加权得到每一个ci。加权系数αij的值越高,表示第i个输出在第j个输入上分配的注意力越多,在生成第i个输出的时候受第j个输入的影响也就越大。加权系数αij是由第i-1个输出隐藏状态si-1和输入中各个隐藏状态共同决定的。其计算方法如下: (7) 其中eij=α(si-1,hj)。 需要注意的是eij的计算仅仅依赖于上一输出状态和输入hj。解码基于这些向量和解码器的隐藏状态,使用单项GRU注意力RNN顺序地生成标题词。 从输入计算到softmax输出的注意力模型如下所示: oyt′=Wcocyt′+Whohyt′+bo (8) 其中,cyt′是解码器当前步骤中计算的上下文,hyt′是最后的隐含层。Wco,Who,bo是模型的参数。可以通过Whohyt′+bo找到最高的值。因为上下文仅仅是隐藏层解码器的权重之和,且可以使用Wcohxt′+bo计算每个输入单词的位置。 式(8)中,第一项表示注意力向量对解码输出的影响,由于上下文是从输入部分计算得来,可以理解为解码的每个输入对输出的影响;第二项表示解码当前隐藏层最后一层对输出的影响;第三项表示偏置项。 本文使用的是English Gigaword数据集,该数据包含了六大主流媒体的新闻文章。其中包括纽约时报和美联社,在每篇文章都有清晰的内容和标题,并且内容被划分了段落。经过对数据预处理之后,训练集包括5.5 MB新闻文章和236 MB单词。 在预处理的过程中,将标题作为预测目标,每一篇新闻的第一段内容作为数据源。预处理的过程包括:对单词小写,分词,从词中提取标点符号,对标题结尾和文本结尾都会加上一个自定义的结束标记。对于那些没有标题、内容或者标题超过25个标记或者文本内容超过50个标记的文章都滤掉。整理出的数据按照token的出现频次排序,取出前40 000个tokens作为词典。数据集被划分为训练集和保留集。保留集中是最近一个月的文章,倒数第二个月的文章并不在训练集合保留集中。这样就保证了无论是训练集还是保留集都没有类似的文章出现。最后,将数据集中的数据随机打乱。 计算的硬件是GTX 980 Ti GPU,测试集使用384个样本进行计算。测试集中随机抽取的6个案例,结果如表1所示。实验结果表明,模型大体上能够抓住文章的主要观点,有的可以用全新的话对标题进行概括。但是确实也存在一些问题,比如在句子4的标题生成过程中,预测的偏差比较大。 表1 新闻标题生成模型测试结果Table 1 Results of news headline generation 本文提出了一个带有LSTM单元的编码-解码器循环神经网络模型,该模型对新闻内容提取关键点信息组成标题。数据集使用的是Gigaword数据集中的新闻文章。本文中所使用的注意力机制可以定位输入数据中的某些单词,有利于神经网络计算被注意单词的权重。实验结果表明,该模型生成的大多数摘要比较准确且语法正确。 [1] Liddy E.Advances in Automatic Text Summarization[J].InformationRetrievalJournal,2001,4(1):82-83.DOI:10.1023/A:1011476409104. [2] Saranyamol C S,Sindhu L.A Survey on Automatic Text Summarization[J].InternationalJournalofComputerScienceandInformationTechnologies,2014,5(6):7889-7893. [3] Nenkova A,McKeown K.A Survey of Text Summarization Techniques[M].Mining Text Data. Springer US,2012:43-76. [4] Dorr B,Zajic D,Schwartz R.Hedge Trimmer:A Parse-and-Trim Approach to Headline Generation[C]∥Proceedings of the HLT-NAACL 03 on Text Summarization Workshop,2003:1-8. [5] De KoK D.Headline Generation for Dutch Newspaper Articles through Transformation-based Learning[J].MeasurementTechniques,2008,12(5):657-662. [6] Banko M,Mittal V O,Witbrock M J.Headline Generation based on Statistical Translation[C]∥Proceedings of the 38th Annual Meeting on Association for Computational Linguistics 2000,In Proceedings of ACL-2000,2002:318-325. [7] Zajic D,Dorr B,Schwartz R.Automatic Headline Generation for Newspaper Stories[C]∥Workshop on Automatic Summarization,2002. [8] Borko H,Bernier C.Abstracting Concepts and Methods[M].New York:Academic Press.1987. [9] Gattani A K.Automated Natural Language Headline Generation Using Discriminative Machine Learning Models[J].PhysicaCSuperconductivity,2007,441(4):229-232. [10] Sutskever I,Vinyals O,Le Q V.Sequence to Sequence Learning with Neural Networks[C]∥Proceeding NIPS′14 Proceedings of the 27th International Conference on Neural Information Processing Systems,2014:3104-3112. [11] Cheng Y,Shen S,He Z,etal.Agreement-based Joint Training for Bidirectional Attention-based Neural Machine Translation[C]∥International Joint Conference on Artificial Intelligence,2016:2761-2767. [12] Weng C,Yu D,Watanabe S,etal.Recurrent Deep Neural Networks for Robust Speech Recognition[C]∥IEEE International Conference on Acoustics,2014,7(3):5532-5536. [13] Peris,Domingo M,Casacuberta F.Interactive Neural Machine Translation[J].ComputerSpeech&Language,2017,45:201-220.DOI:org/10.1016/j.csl.2016.12.003. [14] Mehdad Y,Carenini G,Ng R.Abstractive Summarization of Spoken and Written Conversations based on Phrasal Queries[C]∥Proc. of ACL 2014,Baltimore,MD,USA,2014:220-1230. [15] Takase S,Suzuki J,Okazaki N,etal.Neural Headline Generation on Abstract Meaning Representation[C]∥Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing,2016:1054-1059. [16] Zhang H,Li J,Ji Y,etal.Understanding Subtitles by Character-Level Sequence-to-Sequence Learning[J].IEEETransactionsonIndustrialInformatics,2017,13(2):616-624. ANewsHeadlineGenerationModelBasedonAttentionMechanism LI Hui1,CHEN Hongqian2,MA Liyi1,QI Mei1* (1.CollegeofManagement,BeijingUnionUniversity,Beijing100101,China;2.SchoolofComputerandInformationEngineering,BeijingTechnologyandBusinessUniversity,Beijing100048,China) To improve the coherence and consistency of the automatically generated news headlines, the paper proposes a news headline generation model. The generation model produces the headlines from news articles by combining LSTM and the mechanism of attention. The BiRNN(bidirectional RNN)model is used in the encoding part of the model,and the attention mechanism is selected in the decoding section. The Gigaword data set is used to train the model.The experimental results demonstrate that the proposed method can achieve more concise and to the point than the classical RNN model in the news title generation. news headline generation;attention mechanism;LSTM;Gigaword data set 10.13451/j.cnki.shanxi.univ(nat.sci.).2017.04.002 2017-04-12; 2017-08-09 北京市自然科学基金(9164028);教育部人文社科资助项目(15YJCZH114) 李慧(1983- ),女,山东聊城人,讲师,博士,主要研究方向为机器学习与可视化。E-mail:lihui@buu.edu.cn *通信作者:祁梅(QI Mei),E-mail:qimei@buu.edu.cn TP391.9 A 0253-2395(2017)04-0670-06
1.3 编码过程

1.4 解码过程
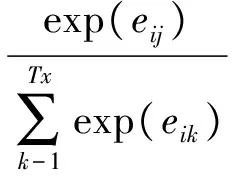
1.5 标题词生成
2 实验结果与分析
2.1 数据集
2.2 预处理过程
2.3 实验结果与分析

3 结语
猜你喜欢
中国石油石化(2022年12期)2022-07-16
小雪花·成长指南(2022年1期)2022-04-09
中国外汇(2019年19期)2019-11-26
活力(2019年22期)2019-03-16
活力(2019年22期)2019-03-16
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
喜剧世界(2016年9期)2016-08-24
