
一种融合相关因素和时间因素的信息检索算法研究
2018-01-30 07:15作者余泓贤湖南长沙市第一中学
电子制作 2017年16期
作者/余泓贤,湖南长沙市第一中学
引言
随着信息技术的发展以及互联网的普及,大量的信息充斥在互联网上,“信息过载”现象越来越严重。如何快速找到用户需要的信息,如何充分有效利用互联网上的信息成为目前亟待解决的问题。为此,如百度、Google等信息检索工具以其科学性和实用性受到了人们的高度重视[1–3]。
信息检索的提出在一定程度上缓解了“信息过载”带来的挑战,被认为是克服此问题的重要技术。先前对信息检索的研究主要分为两类,一类是对结构化信息的检索,即针对于存储在例如Oracle、SQL Server和My SQL等关系型数据库中,并按一定组织结构存储的数据进行检索,此类研究已经较为成熟,主要是利用结构化查询语言SQL(Structured Query Language)来对数据库中存储的数据进行检索。另一种是针对于非结构化信息数据的获取,即为某信息需求检索出最为匹配的信息条目,即有一个文档集合D,对于由关键词w[1]、w[2]….w[K]组成的字符串q,返回多个与查询q相匹配的文档。
传统关于信息检索的研究主要集中在计算信息需求与检索条目的相关性上,而忽略了时间对于检索效果的影响。因此,本研究认为人们在信息检索的过程中,更倾向于获取时间较新的文档数据。本研究中,首先计算信息需求与数据条目的相关性,并以此为依据对数据条目进行排序,然后,用数据条目的发布时间去影响基于相关性的排序结果,最后,获取排序位置在前信息作为检索结果。
1.相关研究
目前广泛应用于信息检索的技术有:结构化查询语言SQL、IF–IDF算法、布尔检索模型、向量空间模型和主题模型。
1.1 结构化查询语言SQL
SQL[4]语言是目前广泛应用的,针对于关系型数据库的检索语言,主要有查询、操纵和控制。数据查询语言指对关系型数据库中的数据进行检索以及信息的读取;数据操纵语言主要是对数据库中的数据进行增加、删除和更新;数据控制语言主要是指对访问数据对象的用户权限进行控制。
1.2 IF-IDF算法
TF–IDF[5,6](Term Frequency–Inverse Document Frequency)算法是信息检索中常用词汇加权技术。其主要思想是:如果某个词或者短语在一个文档中频繁出现,而在其它文档中很少出现,那么可以认为这个词在该文档中的权重很高,这个词很具有区分能力,适合用来做为检索的关键词。TF–IDF实际为 TF*IDF,TF(Term Frequency)为词频,指一个词在目标文档中出现的频率;IDF(Inverse Document Frequency)表示逆向文件频率,由语料库总数除以包含该词语的文件数目,再取对数得到该数值。
1.3 布尔检索模型
布尔检索模型[7]是借助于例如与、或和非等运算符找出相关信息条目的一种方法。假设有一文档,标记为 Di(w1,w2,w3,w4,….wm), 其 中 w1,w2,w3,w4,….wm为能够反映文档Di的关键词。设一用户的检索表达式为Q=(w1∧w2)∨( w1∧w2),那么检索出来的文档应该同时含有关键词w1与关键词w2,或者同时含有关键词w3与关键词w4。
1.4 向量空间模型
向量空间模型[8]把文本内容映射到向量空间中,并且利用向量之间的余弦夹角来推断文本之间的相似度,实现信息检索。在向量空间模型中,我们首先依据布尔模型将查询条件Q与检索文档集合D中的每一个文档进行向量化,然后,计算两者的余弦夹角,得分最高的为与查询条件最相关的文档。
1.5 主题模型
主题模型[9](Topic Model)是从一语料库中挖掘出隐含的T主题,即一篇文章中所表达的中心意思。该模型认为一篇文档的生成规则首先是从多个主题中抽取一个主题,然后从选中主题中抽取主题下面的一个词,然后重复此过程,得到整个文档集合。
2.研究方法
2.1 研究思路
本研究主要包括三个步骤:数据预处理、计算用户信息需求与检索项目的匹配度、按时间进行排序、获取检索结果。
(1)数据预处理:本研究首先利用IK Analyzer对用户的信息需求和候选检索条目进行分词,然后利用停用词表去掉常用词和没有实际指代意义的词,最后利用TF-IDF计算每一个词在特定文档中的代表性。
(2)获取被检文档的特征:本研究首先利用向量空间模型计算信息需求和候选检索条目的相关性;然后,获取被检索文档的发文时间。
(3)获取检索结果:本研究线性组合信息需求和被检索文档的相关性和时间来计算用户信息需求与被检索文档的匹配度,并以此为依据获取排序位置在前的信息作为检索结果。
2.2 数据预处理
本研究首先利用IK Analyzer对用户输入的检索需要和候检文档进行分词,然后利用停用词表去掉常用词和没有实际指代意义的词,最后利用TF-IDF计算每一个词在特定文档中的代表性。其中,用户输入的信息需求表示为:Q=(q1,q2,q3….qn)其中,qn表示第n个字符的TF–IDF,同理,第i个侯检文档表示为Di(w1,w2,w3….wn),其中,wi表示第i个单词的TF–IDF值。
2.3 特征整合与检索
本研究以用户输入的信息需求和被检索文档的相关性和时间因素来计算用户信息需求与被检索文档的匹配度,并以此为依据获取排序位置在前的信息作为检索结果。因此,本研究首先引入向量空间模型来计算两者信息需求Q与第i个被检文档的相关性,可标记为:

通常,检索出来的文档应与信息需求相关性尽可能的高,并且检索出来的文档应尽可能的新。因此,本研究提出RTUFIR(Relevance and Time Uniベcation Framework for Information Retrieve) 以融合信息需求和被检文档的相关性和时间两个因素:

其中,λ控制最终遴选结果的偏向。TDi表示文档Di的产生的时间,表示信息需求Q与被检文档D的主题相关性;当λ=1时,该检索系统仅考虑时间因素;而当λ=0时,该检索系统仅考虑两者的相关性。
2.4 主要代码
informationRe = readData(ベlePath);//获取用户输入的信息

3.实验结果分析
本研究从各大新闻网站上搜索到近五年的新闻条目作为候选检索信息集合。同时,请四组被试分别对本研究提出的信息检索算法与传统基于VSM的检索算法进行比较。其中,每组被试为10人,选择前10条信息作为最终检索结果。信息条目的评价分为三个等级,分别为满意,基本满意,不满意,对应的分值为5,2,1。用户对算法的满意程度如图1所示,横坐标表示四组被试,纵左边表示检索结果的平均满意度。从图1中可以看出,除第三组之外,其余各组的检索满意度均高于传统模型。因此,可以看出,融入时间因素后,用户的满意程度有一定的提高。
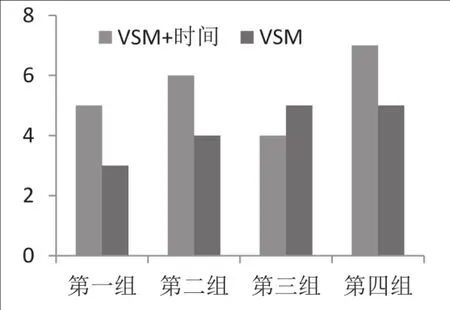
图1 准确率对比图
4.总结与展望
随着信息技术的发展以及互联网的普及,大量的信息充斥在互联网上,“信息过载”现象越来越严重。信息检索的提出在一定程度上缓解了“信息过载”带来的挑战,被认为是克服此问题的重要技术。本研究认为人们在信息检索的过程中,更倾向于获取时间较新的文档数据。本研究中,首先计算信息需求与数据条目的相关性,并以此为依据对数据条目进行排序,然后,用数据条目的发布时间去影响基于相关性的排序结果,最后,获取排序位置在前信息作为检索结果。
但是,仍有一些问题需要进一步探讨。例如,如何使检索结果的重复率达到最低,如何保证检索结果是正确的、质量高的文档。因此,在后续的研究中,笔者将更关注检索结果的质量和满足用户需要的程度。
* [1]顾犇. 信息过载问题及其研究[J]. 中国图书馆学报 ,2000,(05)∶40—43+74.
* [2]邱均平,楼雯. 基于共现分析的语义信息检索研究[J]. 中国图书馆学报 ,2012,(06)∶89—99.
* [3]王灿辉,张敏,马少平. 自然语言处理在信息检索中的应用综述 [J]. 中文信息学报 ,2007,(02)∶35—45.
* [4] Date C J, Darwen H. A Guide to the SQL Standard[M]. New York∶ Addison—Wesley, 1987.
* [5]Ramos J. Using tf—idf to determine word relevance in docu ment queries[C]//Proceedings of the first instructional confere nce on machine learning. 2003.
* [6]Aizawa A. An information—theoretic perspective of tf—idf measures[J]. Information Processing & Management, 2003,39(1)∶ 45—65.
* [7]Salton G, Fox E A, Wu H. Extended Boolean information retri eval[J]. Communications of the ACM, 1983, 26(11)∶ 1022—1036.
* [8]Salton G, Wong A, Yang C S. A vector space model for auto matic indexing[J]. Communications of the ACM, 1975, 18(11)∶613—620.
* [9]Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J].Journal of machine Learning research, 2003, 3(Jan)∶ 993—1022.
猜你喜欢
中文信息(2022年3期)2022-12-07
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
科技与创新(2018年2期)2018-01-09
电脑爱好者(2017年7期)2017-05-06
图书馆界(2013年5期)2013-03-11
