
一种用于时空体元编解码存储的低计算量优化方法*
2018-02-26 10:12顾清华卢才武
计算机工程与科学 2018年12期
顾清华,马 龙,卢才武
(西安建筑科技大学管理学院,陕西西安710055)
1 引言
近年来,地理信息系统受大数据环境的深入影响,时间变化的信息存储管理备受关注[1]。时态地理信息系统TGIS(Temporal Geography Information System)组织的重点是时空数据库STDB(Spatio-Temporal Data Base)[2]。时空体元作为 TGIS 中实体对象表达的最小单元,可动态反映地理空间内的事物,这就需要存储海量的时间和空间属性的数据,且这些数据需能在有限的存储空间和传输速率下实现存储转换和表示计算。如何降低这些海量数据的存储计算量则成为了解决这些问题的关键。目前,为了减少时空数据存储空间,降低数据传输计算量,时空数据索引结构、数据编码和存储方法的优劣直接影响着STDB和TGIS的整体性能,它是解决二者之间数据存储转换、编解码过程计算量的关键技术。
十六叉树HDT(HexaDecimal Tree)索引结构最早是由Inamoto[3]在1993年提出的,经过不断的实践应用,该方法成为TGIS数据索引的关键技术[4],实践证明其对海量时空数据索引、查询具有突出的特点,因此利用四维十六叉树索引结构建立时空数据索引在需求上是完全合理的。但是,在十六叉树索引结构中仍是采用十进制对时空对象进行编码,这既无法满足计算机存储管理要求,又增加了时空数据存储、转换和传输过程的计算量。为此,Lacan 等与 Plank[5,6]采用传统的范德蒙码和柯西码,构建了伽罗华有限域上的时空数据存储系统和编码方法。但是,在实际应用中,这两种方法在编解码转换时存储开销大,兼容性差,并需借助查询乘法表来完成域内体元乘法运算。Wardlaw与Plank 等[7,8]采用二进制矩阵表示域内体元,构建了二进制矩阵上的编码方法,从而使存储的体元数据编解码过程具有更低的计算优势。但是,如何进一步降低时空体元对象编解码过程中的计算量,学术界只进行了简单的探索,并未形成完整的解决方案。李德仁等[9]针对地理空间体元计算的复杂性问题,采用一种新的网格分裂方法,实现了空间对象网格编码策略、存储方法以及地球空间坐标的转换方法。郭达志等[10]根据时态GIS的应用需求,构建了四维时空数据模型,解决了时空对象线性编码、存储计算和时空坐标转换问题。但是,这些索引结构、编解码和存储方法均有各自的适用范围,对于时变范围较大或存在多个局部极小点的数据索引、存储表示计算量还大。因此,本文根据地理空间实体动态变化特征,提出了一种用于时空网格体元模型编解码存储的低计算量优化方法,通过对网格体元对象的编码表示和存储转换,构建了时空网格体元编解码优化方法,使得网格体元模型在时空数据库中存储、表示、转换和数据传输过程中的计算量进一步降低,并对时空网格体元编解码的时空复杂度和优化算法进行分析。最后的实验结果表明,本文提出的方法可有效降低编解码存储过程中约30%左右的计算量。
2 时空网格体元编码及转换方法
2.1 时空网格体元编码和解码模型
十六叉树本质上是对目标网格体元的动态存储方式,也是实现体元编解码表示和数据索引的结构。由十六叉树编码图解[10]可知,该索引结构对于空间体元对象标识与地理时空坐标位置上存在着严格的对应关系,可较好地实现地理时空对象编解码的转换与计算。时空网格体元对象的解码数学模型为:

其中,ci、di、ei、fi(i=n -1,n -2,…,0) 的取值为0或1,分别为 X、Y、Z、T轴上坐标值所对应在网格体元中的解码值权系数,p为网格体元分裂的次数或分辨率。
每个十六叉树节点的编码采取的形式为qn-1,qn-2,…,0。每个位置上的 qi是从(0,1,…,10,A,…,F)十六个数中取其中之一,qi的个数取决于上述分辨率p。时空网格体元对象的编码数学模型为:
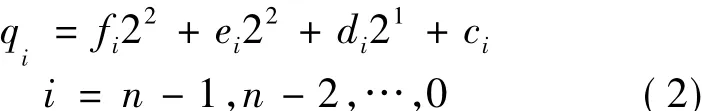
其中,qi为编码值,ci、di、ei、fi分别为 X、Y、Z、T 轴上坐标值所对应网格体元的编码数据权系数。
2.2 时空网格体元编码存储转换
对地理时空网格体元对象编解码后还需满足系统存储要求,即将用十进制表示的空间实体对象转换为二进制形式。因此,本文借助高斯坐标的3DGIS编码方法[11],设计出符合地理网格体元对象编码存储转换方法,其转换步骤如下:
Step 1定义时空区域参照基点O(x0,y0,z0,t0)。
Step 2定义固定时间t周期内沿着X、Y、Z轴的网格体分割尺寸 Dx、Dy、Dz,结合十六叉树原理[10],通常 Dx、Dy、Dz定义为2nm(n=1,…,10),Dt定义为日期型数据。且根据研究区域内空间实体对象的变异频度和复杂度来确定n:当变异频度很高时,可选择低值(n=0,1);当变异频度适中时,可选择中值(n=2,3);当变异频度很低时,可选择高值(n=4,5),t选取为采样数据的时刻。
Step 3按规定尺寸(Dx×Dy×Dz)和给定的时间点,把目标网格体元区域划分为四维空盒集,如图1所示;划分后的目标区域内网格体编码可以采用时空网格体元编码模型(如式(2)所示),如图2所示。
Step 4计算任意地理空间实体对象A的二进制编码:
(1)定义实体对象A的近基点A0:实体对象的最小包围盒的最近角点为近基点A0(x,y,x),其表达式为min[(x-x0)2+(y-y0)2+(z-z0)2];当存在两个以上的近基点时,任选其一。
(2)计算近基点A0空盒集区域的行号I(沿X轴)、列号J(沿Y轴)和层级号(沿Z轴)以及时间点编号,其计算表达式参考文献[12]。
(3)将近基点A0所在空盒的十进制行列层次号(I,J,K)转换为二进制行列层次号(I',J',K')。
(4)获取二进制行列层次号(I',J',K')中每一位二进制数 Pit、Pjt、Pkt,及时间编号:
其中,& 为“与”操作符,t为位的序号,t=1,2,3,…,n。
(5)基于二进制行列层次号(I',J',K')计算时空实体对象A所在空盒的二进制Morton码:
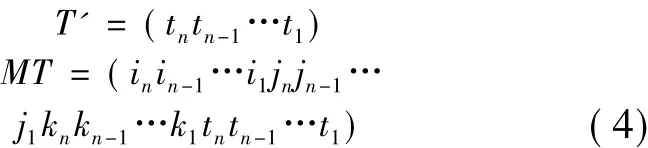
3 时空网格体元编解码计算优化
3.1 二进制解码矩阵构建
根据Wardlaw有限域空间体元方法[6],如果采用B0表示有限域网格体元对应的二进制矩阵,则构建的二进制解码矩阵的形式为:

其中,Bxk∈{B0,B1,B2,…,B2m-1}。
由矩阵的性质可知,对矩阵行列变换后,矩阵的秩不变,将R矩阵转化为如下的形式:

其中,Im为m×m的单位矩阵;I为(m×k)×(m×k)的单位矩阵;Vij为由0、1构成的m×m方阵;V'是(m×r)×(m×k)的0、1矩阵。
因为 Vi1,…,Vik是一个由 0、1构成的 m ×(m ×k)矩阵,[Vi1,…,Vik]是由 1×(m ×k)阶的0、1构成的行向量,由此可将十进制表示的体元对象编解码换算为二进制形式,从而实现网格体元数据块的校验和容错。


在二进制码存储的过程中,检验网格体元数据块将行向量中体元1对应的所有网格体元数据块之间进行异或运算,进而获取校验的网格体元数据块(图2中阴影划分块部分)。具体计算过程如图3所示。

3.2 时空网格体元编码与解码过程的低计算量优化算法
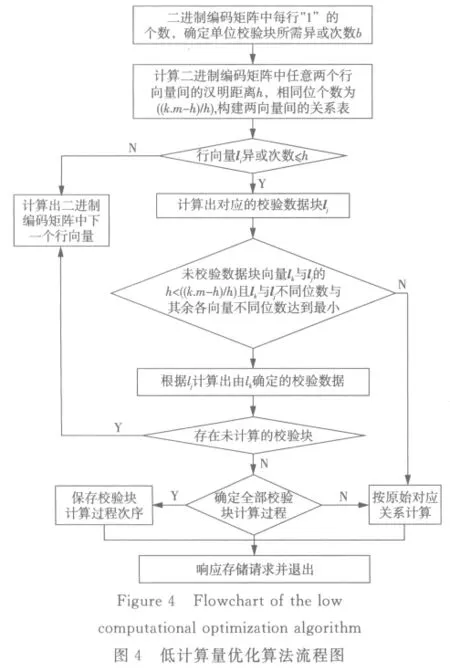
在实际的应用过程中,借助二进制编码矩阵的存储方法,采用异或运算实现编解码的校验和容错,降低整个网格体元编解码存储的计算量。其总体优化思路:首先通过Wardlaw的方法构造有限域体元的二进制编码矩阵;然后根据网格体元校验块最优次序算法,依次计算出二进制编码矩阵中各向量间的关系;最后依据校验块优化计算方法,先计算出由向量本身确定的校验块异或计算次数,再从已知向量的校验块间接搜索计算出其余向量的未知校验块。通过减少向量间的校验块计算的异或次数,从而降低整个网格体元编码存储过程中的计算量。反向计算过程,即是解码过程的优化方法。
设任意网格体元编码矩阵形式如式(7)所示:

则可根据生成的校验块Vrm中的行向量l1,l2,…,lrm为“1”的数量确定出异或计算次数。其优化算法的流程如图4所示。
4 工程应用与结果分析
4.1 数据来源
为了验证本文所提出的时空体元对象编解码、存储过程计算量算法的有效性,使用SURPAC矿业软件对某矿山的经纬度坐标和矿床高程数据进行处理后,获得该矿山某采场的矿体空间块体数据模型,时间属性以采剥与否的实际时间为基准,并对复杂矿体模型数据进行简化处理,选取矿床中部分块体的地理时空坐标数据集(X,Y,Z,T)={(6,3,4,1),(0,2,3,1),(2,1,0,0),(2,0,2,0)}作为典型实验数据,采用SURPAC软件处理的体元数据模型如图5所示。

4.2 时空网格体元数据编解码
由2.1节介绍的时空网格体元对象编解码的数学模型可知,选取空间分辨率n=3,时间点t=0时,表示不开采,其空间坐标(X,Y,Z)分别为(2,1,0)、(2,0,2);时间点 t=1 时,表示开采,其空间坐标(X,Y,Z)分别为(6,3,4)、(0,2,3)。将这两组数据集代入模型(2)中可获得四组不同的编码值(或定位码);反之,根据给定的解码值与网格体元数据权系数,将对应的编码值代入模型(1)中,可计算出对应的解码值。详细计算结果如表1与图2有灰色填充标识的体元所示。
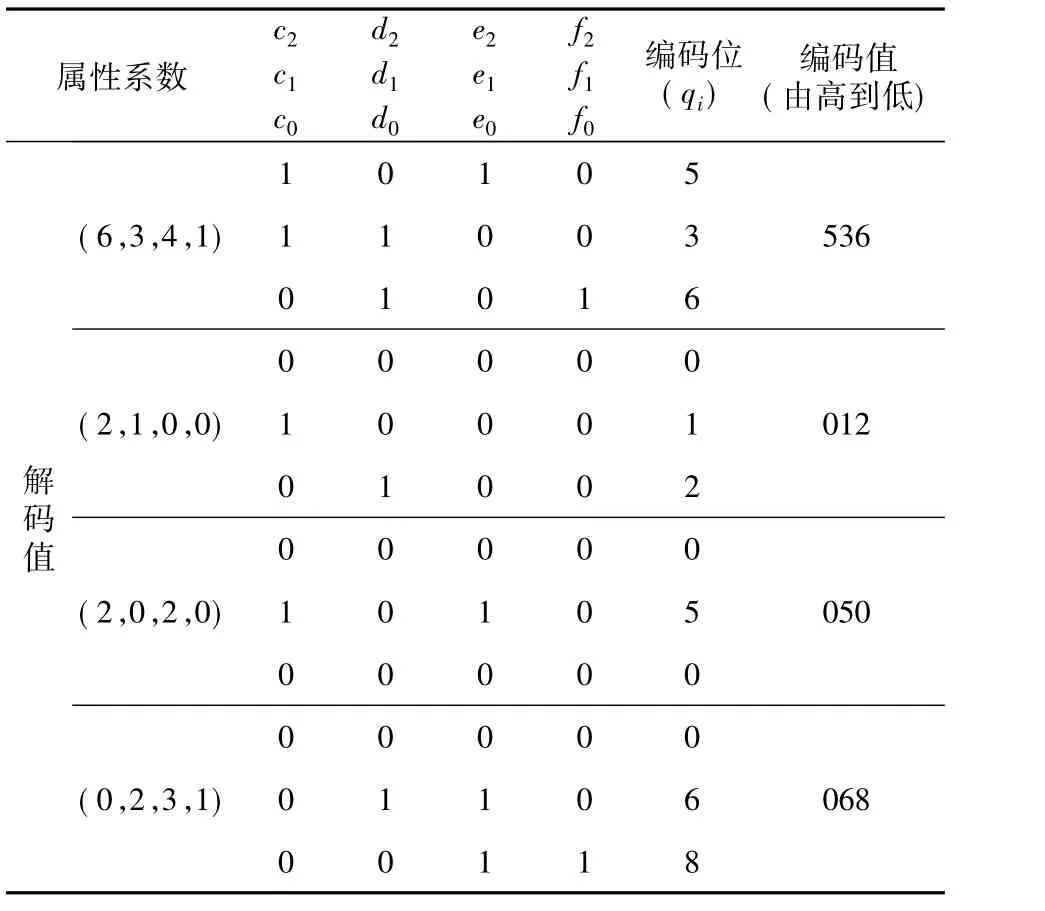
Table 1 Encoding and decoding of spatiotemporal grid voxel data表1 时空网格体元数据编解码表
4.3 数据编码存储转换方法
根据2.2节可知,网格体元编解码是十进制表示形式,需要将其转换为二进制形式,并需确定目标网格体元的高斯坐标的基点和近基点。本文选取时间点 t=1,解码值为(X,Y,Z)=(6,3,4)所在的目标区域为例,其对应的基点值为O(5 433 903.01,2 073 356.22,-200.0),实体对象 A 的近基点为 A0(543 721.73,2 073 464.85,-332.1)。定义Dx=Dy=26m=64 m,Dz=24m=16 m。则其对应的 I、J、K 及 MT 码如下:

其中,函数INT()表示向上取值。
4.4 时空网格体元编解码低计算量优化算法
4.4.1 网格体元解码
由3.2 节可知,依然以时间点 t=1,(X,Y,Z)=(6,3,4)为例,选取构造有限域元素参数m=3,根据 Plank等人[13]提出的二进制矩阵构造方法,随机选取3个二进制矩阵B1、B2、B5,则构造的二进制矩阵如式(8)、式(9)所示:
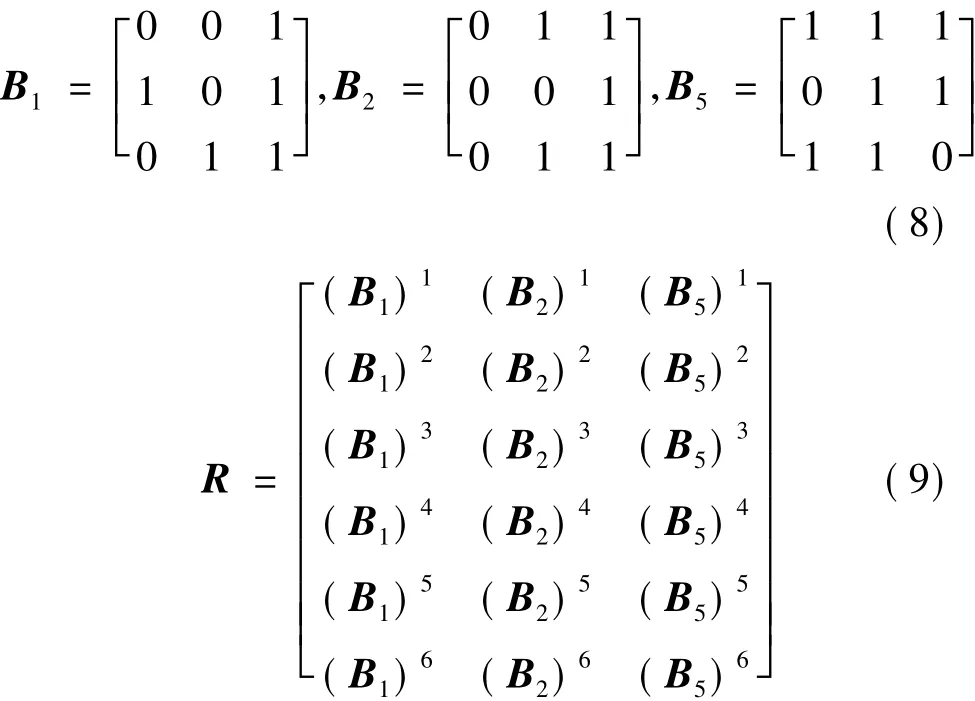
矩阵R优化后:

其中,I为9×9的单位矩阵,V'如式(11)所示;

根据空间坐标(6,3,4)的二进制解码矩阵R中的子矩阵 V',可确定向量 l1,l2,l3,…,l9,依据优化算法需确定出编码矩阵中各向量间的关系,如表2所示。其中,la(b)中a表示矩阵V'的行向量顺序,b表示第a行向量生成校验块时的异或计算次数,((k×m-h)/h)中k×m-h为矩阵V'中任意两个向量间的相同体元位的个数,h为矩阵V'中任意两个向量间的汉明距离;(x/y)表示任意两个行向量li与li+1间相同体元个数x与不同体元个数y。
以上述解码矩阵V'中第1、2行向量l1和l2为例,在表2中标记为l1(3)与l2(4),直接由l1和l2计算网格体元的校验块的异或次数分别为3和4,而向量所需校验块异或次数均小于由其它校验块间接计算的异或次数,即l3生成的校验块为p1,3可直接计算获得;同理l1、l7、l8的校验块由对应的行向量直接经异或运算获得,即直接获得的校验数据块分别为:

通过已计算获得的网格体元校验块l1、l3、l7、l8可计算出其余向量对应的体元校验块数据。从表2可知,从l1至其它行向量的汉明距离知,可由l1的校验块来计算出l9的体校验数据块,可由l8的校验块计算出l4的校验块,由于从l3、l6的校验数据块来确定l9的校验数据块需要更少的异或次数,因此,l1无法作为校验其余行向量的基础校验数据块。同理,l3、l7也无法作为基础校验数据块。依次搜索,由图6可知,分别通过l4的3次校验数据块异或次数计算出l5的校验数据块,l6的校验数据块可分别计算出l2、l9的校验数据块,即间接获得的校验数据块分别为:

Table 2 Relationship of decoding vectors of spatiotemporal grid voxel data表2 时空网格体元数据解码向量关系


至此解码矩阵所生成的所有校验数据块计算结束,其整体计算流程如图7所示。由此可知,将地理空间对象分裂为网格体元时,对其中的有形实体对象解码所产生的存储计算量较少,而对于地形中的“空”位置解码就会造成大量的存储计算。

4.4.2 网格体元编码
对于时空网格体元数据解码过程而言,当存储的体元数据丢失或毁坏时,可通过校验矩阵K来恢复。因为基于矩阵K的解码过程同样需要通过完整的备份数据块间的异或计算来恢复丢失数据,从线性分组码的性质知,解码与编码存在着严格的对应转换关系。因此,可直接将网格体元解码矩阵与编码矩阵进行转换,设编码矩阵如式(12)所示,则校验矩阵如式(13)所示:

矩阵K可用来恢复丢失的体数据块,设存储体数据块B1,B2,…,Br的节点丢失,则随机选择k个节点备份的网格体元编码数据块对丢失数据进行恢复。根据校验矩阵K(k+r)×r恢复丢失掉的r个数据块 B1,B2,…,Br,依据上述提出的校验块优化计算方法将丢失的网格体元数据块B1,B2,…,Br分别表示为X1,X2,…,Xr,并根据上述网格体元数据校验块最优次序算法,将恢复过程中需要完整备份的编码数据块记为 Br+1,Br+2,…,Bk,Bk+1,…,Bk+r+1,Bk+r;令 φ = [X1,X2,…,Xr,Dr+1,…,Dr+k],其中 φ1=[X1,X2,…,Xr];φ2=[Dr+1,…,Dr+k]。则根据关系式 φ.K(k+r)×r=0来恢复丢失的体数据块。同样,根据上述关系式中 φ与K(k+r)×r间的关系可以定位出丢失体数据块在校验矩阵K(k+r)×r中所对应的向量,如果丢失的体数据块所对应的矩阵表示为K1r×r,校验矩阵 K(k+r)×r中与完好备份的数据块对应的矩阵表示为K2r×r,那么有:


因为对于空间坐标系(6,3,4)中网格体元解码的恢复特征可知,系统最多可允许3个数据块丢失,上述提出的算法恢复过程中假设原始网格体元数据全部丢失,只有完整的备份数据块时,才可说明丢失数据块的数据恢复过程。其中,

则通过式(18)确定的校验矩阵行向量间的关系,其中,l'1,…,l'9表示丢失数据块的向量顺序,分别如表3与图8所示。

通过图8可获得丢失数据块的最优计算次序,首先,计算由l1、l6、l7确定的丢失数据块;其次,根据l2的数据块,计算出由向量l8确定的丢失数据块,同时根据l6数据块,计算出l1数据块;然后根据向量l8计算出l3数据块,并根据向量l1计算出l4、l5的数据块;最后根据恢复后的向量l3计算出l9确定的数据块。其整体计算流程如图9所示。
4.5 时空网格体元存储过程的计算量分析
由于地理时空网格体元存储形式可由二进制矩阵表示,因此测试的数据集分别用不同规模的二进制矩阵构成。测试平台所用的硬件为Intel core i5-4590M,3.3 GHz CPU,软件为 Matlab2015R,时空网格体元数据分别为64×64、128×128、256×256的二进制数值矩阵,十六叉树的叶子节点数目分别为2 095、940、4 590、22 628 个,数值矩阵随机生成。网格体元分裂时间和存储效率如表4所示。
由图2可知,假设将地理时空网格体从上至下划分为三个子立方体区域,其中区域I为64×64,叶子节点数目分别为2 095个、940个,区域Ⅱ为128×128,叶子节点数目为4 590个、区域Ⅲ为256×256,叶子节点数目为22 628个。三个实验区的时空网格体元编码是从顶向下分裂方法产生十六叉树,采用式(2)编码,Morton编码采用八叉树的自顶向下分裂方法,可用式(4)编码。


Table 3 Relationship of encoding vectors of spatiotemporal grid voxel data表3 时空网格体数据编码向量关系

Table 4 Storage efficiency and splitting time of spatiotemporal grid voxel encoding and Morton encoding表4 时空网格体元编码与Morton编码的存储效率与分裂时间
由表4的结果可知,分别采用以十六叉树索引结构和八叉树索引结构为基础的两种编码方法,采用十六叉树索引结构对地理空间目标块体分裂所消耗的时间几乎是采用八叉树索引结构的一半左右,随着矿床块体数量和叶子节点数量的增加,以八叉树索引结构的Morton编码所消耗的分裂时间明显增加。采用以十六叉树索引结构的网格体元编码所占用的内存空间要比采用八叉树索引结构的Morton编码少25%左右,随着矿床块体数量和叶子节点数量的增加,两种编码方法占用的内存空间成倍数增长。这是因为十六叉树对目标空间块体的索引是以子立方体的形式分裂,而且分裂过程中会随着时间区域的变化而不断地释放已访问节点的内存空间,而八叉树索引结构只是在同一立方体上对目标空间块体进行递归分裂,分裂过程中已访问节点由于根节点的关联性而无法释放,由此导致十六叉树索引方法占用的存储空间较少,分裂速度较快。同理,两种编码方法占用的外存空间也是以倍数在增长,网格体元编码方法所占用的外存空间要明显少于Morton编码方法占用的外存空间。
4.6 低计算量优化方法分析
为验证提出的计算方法的通用性,分别对时间参数 t=1 与空间参数为(6,3,4),(0,2,3)以及时间参数为 t=0,空间参数为(2,1,0),(2,0,2)的时空网格体元的编码与解码过程进行了测试。上述编码与解码系统都由本文提出的方法构建,其低计算量优化性能如表5所示。
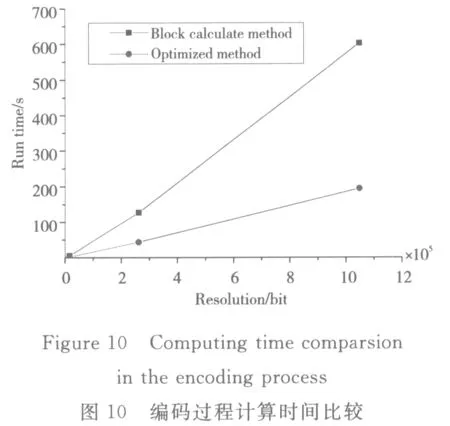
由表5可知,以构建的(6,3,4)编码矩阵为例,如果用传统的分块计算,需计算38次方可获得全部校验块,而使用本文方法只需要计算26次,总的运算次数减少31%左右。对于文中生成的9个校验数据块的编码矩阵,每个校验块需要约2.9次异或运算,因此极大地减少了计算量,从而大幅度地降低了计算时间,节约了存储空间,其优化后的编码计算时间如图10所示。
如果用传统的块计算方法进行解码,需要38次异或运算恢复丢失的全部体数据块,采用本文方法后,只需24次异或运算,即总的运算次数减少大约37%,因此极大地减少了恢复丢失数据的计算量,降低了时空复杂度。图11所示为解码过程计算时间的比较。同时,对表5中的二进制解码过程进行了统计分析,由于缺失网格体编码的数据块不同,解码过程也会有所差别。因此,将测试条件设置为所有原始块体数据缺失,利用校验数据块对其进行恢复,使用本文方法后,解码过程的计算量大约减少30%。
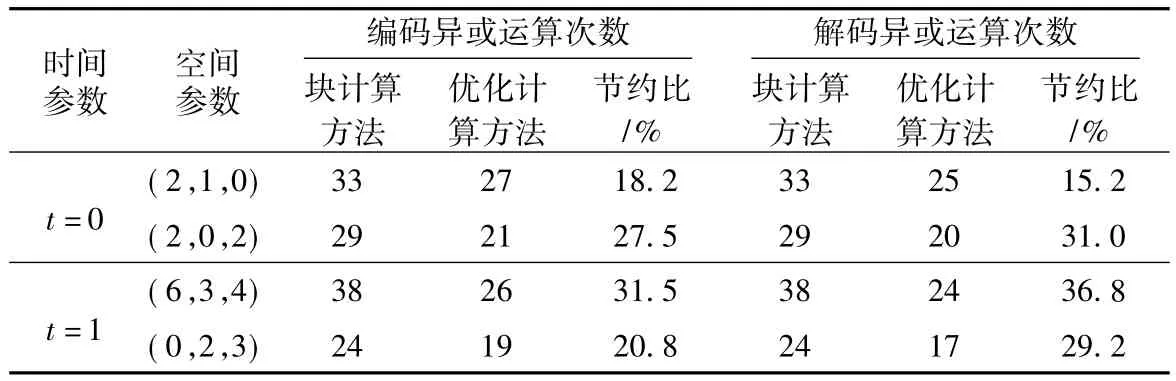
Table 5 Computation comparison between encoding optimization and decoding optimization表5 编码与解码优化计算量比较

5 结束语
在海量时空数据存储和传输计算过程中,需要对动态产生的地理空间对象数据进行存储,本文提出的优化计算方法可减少时空体元存储过程中计算量的30%左右,系统响应时间减少约50%。同时,该方法具有一定的通用性,凡是涉及时空体元编解码存储和二进制矩阵确定的块体异或运算过程,均可采用该方法降低系统存储过程中的计算量。但是,该方法只是针对已经构建的二进制块体矩阵的编解码存储过程进行优化,如何直接构造出最低计算量的编解码矩阵还需进一步深入研究。
猜你喜欢
中国石油石化(2022年12期)2022-07-16
中等数学(2021年8期)2021-11-22
微处理机(2020年5期)2020-10-20
空间科学学报(2020年4期)2020-04-22
中国外汇(2019年19期)2019-11-26
数学大王·低年级(2019年10期)2019-11-25
传播与制作(2019年9期)2019-10-20
中等数学(2019年4期)2019-08-30
民用飞机设计与研究(2019年2期)2019-08-05
家庭影院技术(2018年11期)2019-01-21
