
基于粗糙集结合SimRank算法的 数控机床故障诊断研究
2018-03-07 03:02王家海徐旭辉沈佳豪江小林柴李梦
组合机床与自动化加工技术 2018年2期
王家海,徐旭辉,沈佳豪,江小林,柴李梦
(同济大学中德学院,上海 201804)
0 引言
制造业是国民经济的命脉,而数控机床是制造业之母。随着科技的发展,数控机床的精度越来越高,数控机床的复杂度越来越高,数控机床的故障诊断也是越来越复杂,因为在短时间内实现快速诊断、精确定位故障原因和部位显得越来越重要[1]。
对于故障诊断方法,国内外的研究有:故障树诊断法,这种方法直观性好,通用性好,灵活性大,但也存在着建树困难,繁杂,工作量大,并且容易搞错[2]。适合故障空间较小的故障诊断。基于不确定推理的故障诊断,存在的问题是对于故障现象的可信度需要人为的设定,这就导致主观性较强,并且过程相对而言比较复杂[3]。基于案例推理的故障诊断,存在缺乏相应的知识表示和获取的研究的问题[4]。针对上述难题,通过分析实际诊断过程设计了一套故障诊断系统,包含用来定义故障模型的七层故障诊断知识结构,以及具备机器学习能力的诊断系统。
1 七层故障诊断知识结构
经过对数千例西门子数控系统故障案例的分析总结,发现故障案例的有效信息,即存储于专家系统知识库中的数据可归结为7层网络结构:系统、子系统、部位、故障描述、故障原因、故障现象、故障解决方案。
其中系统对子系统,子系统对部位,部位对故障描述是一对多的关系。故障描述和故障原因是一对一的关系。故障原因和故障现象,故障原因和解决方案存在着多对多的关系。7层知识库的设计充分符合三范式原则。
如此设计知识库,首先从层次上展现了知识体系。其次,故障原因,故障现象,故障部位和故障解决方案这四个重要知识结构之间的关系可以清晰表达出来。再次这样的设计可以将后面需要用的算法与知识体系进行完美的结合,可以快速从现象找到原因,从原因找到故障的解决方法和故障部位。
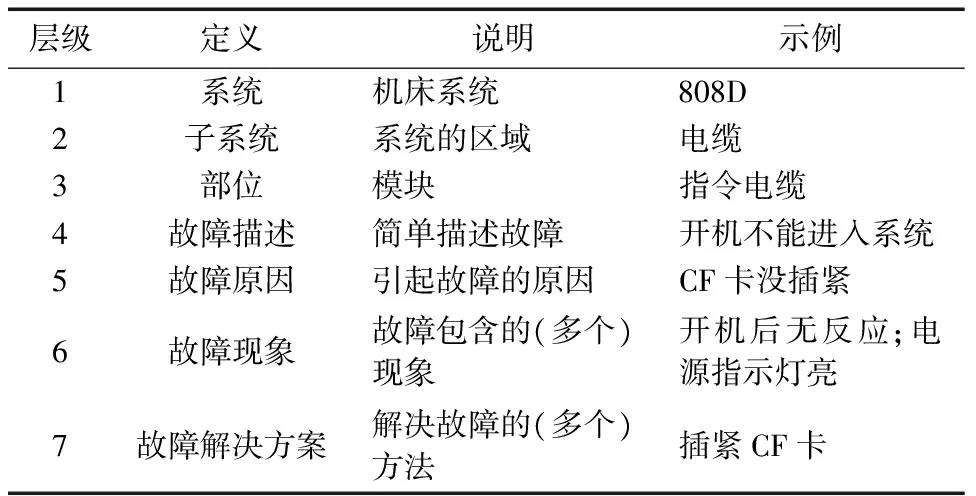
表1 七层故障诊断知识结构
2 粗糙集结合SimRank算法
2.1 粗糙集
故障现象为故障的特征属性,可以直接用粗糙集理论来处理,所以对一个决策表系统,属性的重要度为:
(1)
其中,card(*)表示集合的基,ai表示第i个属性。rc(ai)越大,表明属性ai对决策越重要,当从条件属性中去掉属性a_i后,案例库的分类U/D的正域会受到较大的影响。
对求得的属性重要度rc(ai)进行归一化处理,得到属性ai的权重值ωai:
(2)
2.2 SimRank算法
SimRank算法可以挖掘出故障诊断知识结构图中故障现象与故障原因之间的联系SimRank算法公式如下[5]:
(3)
s(a,b)为对象a和对象b之间的相似度,即图1中两个节点a、b之间的相似度。C是衰减因子,它的取值范围为[0,1],I(a)是节点a在图中的入边集合,I(b)是节点b在图中的入边集合。
S(a,b)=1,if (a=b)
(4)

图1 故障原因与故障现象局部图
具体计算过程中,首先由故障现象作为对象,通过式(4)计算故障案例之间的相似度。再以故障案例为对象,通过式(4)更新故障现象之间的相似度。反复迭代直至趋于稳定,即可得到数据库中不同案例与输入的故障案例之间经过修正的相似度。
2.3 粗糙集结合SimRank算法
尽管SimRank算法能够得到两个节点间的相似关系,但在计算时并没有考虑所引用的对象的权重大小,会被不重要但数量多的对象干扰。因而考虑使用粗糙集计算得到的权重改进算法,将现象的重要都和案例的相似度结合,从而使得算法更加接近事实本身。改进后的算法(RSR算法)具体公式如下:

(5)
其中,e-|I(a) ∩I(b)|为衰减因子,目的是使计算结果收敛。|I(a)∩I(b)|表示某两个案例相关的共同的故障现象,或者某两个故障现象相关的共同的案例。eRi·eRj其中e*为自然对数,Ri和Rj为粗糙集算出来的重要度[6]。
(1)得到目标案例和相似案例包含的所有报警号和现象;
(2)根据粗糙计算法确定已有的报警号和现象的重要度;
(3)以案例为元素、报警号和现象为节点,计算案例的相似度;
(4)以报警号和现象为元素、案例为几点,计算报警号和现象的相似度;
(5)反复迭代上述计算过程,使相似度趋近于一恒定值;
(6)得到报警号和现象的相似度。
2.4 算法的系统工作流程
如图2所示,当机器获取故障现象信息后,粗糙集算法开始运行,计算出相关的故障现象的权重。然后SimRank算法再开始运行,根据算出的现象权重以及故障现象和故障原因之间的拓扑关系,算出相似度,进而得出知识库中最相近的案例,然后诊断出这个故障的原因,故障部位。
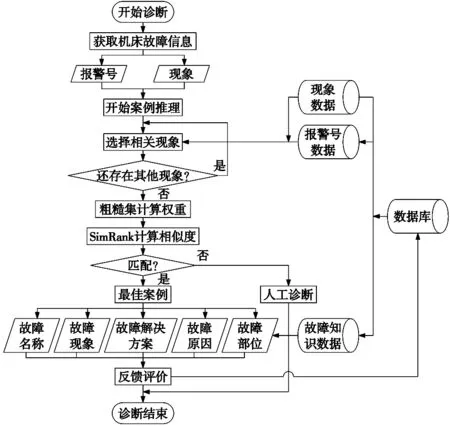
图2 算法系统工作流程图
3 RSR算法的实验验证
3.1 实验说明
为了检查和验证RSR算法在实际使用情况的合理和有效性,实验以真实维修记录为基础设计一组测试数据,分别比对单一现象输入、两个现象输入和多个现象输入情况时的相似度计算结果,相似度排序和实际维修参考价值排序最为符合则为优。
3.2 实验数据
本实验测试数据来源于真实案例测试数据共包含10个现象,测试案例和现象之间的对应关系如表2所示。通过粗糙集可知,现象A、现象B是最为重要的现象,现象D、G、I次重要。

表2 测试案例
3.3 实验内容
3.3.1 单一现象作为输入源
依次以现象A和现象B作为输入的故障现象,计算结果如表3和表4所示。

表3 现象A作为输入源时测试结果

表4 现象B作为输入源时测试结果
当输入源仅包含一个现象时,较难通过直观感受判断测试案例和故障案例之间的关系,因此此处仅比较两个算法之间的差异。由图可得,两个算法之间差异并不明显,排序结果基本一致,仅在表3中案例2和案例4出现不同。案例2只包含重要现象A,案例4同时包含重要现象A和B,因此案例4的实验结果位置应高于案例2,RSR算法更为合理。
3.3.2 两个现象作为输入源
现象A和现象B同时作为故障现象,计算结果如表5所示。

表5 现象A、B作为输入源时测试结果
观察测试数据可得,RSR与SimRank++的排序结果一致,符合现实情况,同时包含现象A和现象B的测试案例排列最靠前。
3.3.3 多个现象作为输入源
首先,将较重要的现象全部做为输入源,得到表6所示的测试结果。

表6 重要现象作为输入源时测试结果
当以较重要现象作为故障现象输入算法时,RSR算法将现象的重要程度纳入计算范畴,排名靠前的测试案例均含有更多的输入现象,且包含重要的现象越多,排名越靠前。SimRank++算法则仅考虑测试案例和故障案例的相似程度,测试案例9相比测试案例8含有更多的重要现象,但排名却落后于测试案例8。
第二步选择所有不重要的现象作为输入源,得到表7所示的测试结果。

表7 不重要现象作为输入源时测试结果
这里,两个算法的差异主要体现在排序的末端,即相似度较低的测试案例的选择上。在SimRank++计算过程中,测试案例7的相似度值比测试案例9的相似度值高,然而测试案例9含有更多的重要现象,能够更好地体现案例之间的差异。因此,RSR算法的结果更加合理。
最后,选择现象A~E作为输入源测试算法,以此查看包含重要、次重要和不重要现象的排序情况。测试结果如表8所示。

表8 综合测试结果
在综合输入源测试中,RSR对SimRank++的排序结果同样做出了调整,将包含更少重要现象的测试案例7调整到排序中部。
4 总结
七层故障诊断知识结构、RSR算法和贝叶斯平均算法相结合的故障诊断系统有效地解决了数控机床故障诊断领域的不足,提供了一套能够运用于实际生产的解决方案。七层故障诊断知识结构帮助接触故障指示的表达难题,提供了标准化参考方案。粗糙集和SimRank算法相结合的RSR算法提高了故障诊断时的搜索准确性和案例可用性,使诊断方案更加符合客观事实。RSR算法使故障诊断系统具备了一定程度的学习能力,通过数据积累和使用经验,能够动态调整系统效能。最后,这套系统已经在基于web开发的故障诊断系统中得到验证,能够在实际生产中发挥作用。
[1] 王家海,黄江涛,沈斌,等.数控机床智能故障诊断技术的研究现状与展望[J].机械制造 2014,52(5)30-32.
[2] 盛博, 邓超, 熊尧, 等. 基于图论的数控机床故障诊断方法[J]. 计算机集成制造系统, 2015, 21(6): 1559-1570.
[3] 王家海, 刘晨阳. 基于不确定推理的数控机床故障诊断的研究[J]. 制造技术与机床, 2014 (1):48-52.
[4] 王家海, 张燕青, 周天航. 数控机床故障诊断的三维显示与优化的研究[J]. 机械科学与技术, 2015, 34(12): 1885-1890.
[5] 魏现辉, 张绍武, 杨亮, 等. 基于加权 SimRank 的跨领域文本情感倾向性分析[J]. 模式识别与人工智能, 2013, 26(11): 1004-1009.
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
名家名作(2021年4期)2021-05-12
科教导刊·电子版(2021年6期)2021-05-06
科普童话·学霸日记(2020年1期)2020-05-08
制造技术与机床(2019年12期)2020-01-06
小天使·一年级语数英综合(2019年2期)2019-01-10
制造技术与机床(2018年12期)2018-12-23
电子制作(2018年10期)2018-08-04
电子制作(2017年20期)2017-04-26
现代计算机(2016年17期)2016-02-28
