
分簇架构处理器上卷积并行计算算法的研究
2018-03-27 03:30邓文齐郑启龙杨振浩
小型微型计算机系统 2018年3期
邓文齐,郑启龙,盛 鑫,杨振浩
(中国科学技术大学 计算机科学技术学院,合肥 230027)
1 引 言
在很多的嵌入式系统应用中,都有实现人工智能任务的需求,如[10,11].近年来深度学习在图像识别、语音识别和自然语言处理等领域取得了非常出色的成果[9].深度学习的成功给嵌入式系统中的人工智能应用带来了新的发展机遇.在这些应用中改用深度学习的方法,势必将大幅提升应用的性能.此外,智能硬件的发展火热,无人机、智能机器人、可穿戴设备等,这些应用更加需要深度学习技术的支撑.
嵌入式系统部署深度学习模型的其中一个难点是,深度学习所需的运算量很大,大部分嵌入式处理器无法满足它的性能要求.BWDSP*http://www.cetc38.com.cn/38/335804/335809/377610/index.html系列处理器是基于分簇架构32位DSP处理器,它的指令系统支持VLIW和SIMD类型的操作,最高能达到30GOPS和8GFMAC的运算能力,它的架构和计算能力很适合处理深度学习任务.卷积神经网络[12]是目前性能最好、最流行的深度学习算法之一[4],论文[7]证明了卷积神经网络中,卷积操作占据超过90%的总计算时间.因此本文基于BWDSP处理器,对多簇架构处理器中的卷积并行计算算法进行了研究.结合该系列处理器的架构和深度学习计算的特点设计了一个算法,通过性能测试,表明该算法的在BWDSP的运算速度是目前较常用的GEMM(General Matrix Multiplication)算法的9.5倍和基于常规向量化思路实现的算法的5.7倍.在大规模的输入下,算法的性能为2.27GMACS.
目前,也有很多研究者对采用硬件加速器加速卷积神经网络的计算进行了研究.这些加速器使用FPGA[5]或ASIC[3,4]来实现特殊的卷积计算算法.这些算法在它们的硬件平台运行的性能优于本算法在BWDSP上运行的性能,这主要是因为这些加速度器的主要目标是弥补服务器上通用处理器的不足,采用的计算部件(如乘法器)的数量远多于本文使用的处理器中的数目.通过对比一些基于FPGA实现的系统,本文设计算法的等效计算资源的平均性能是它们设计的硬件算法的1.63倍到10.85倍.
本文的主要贡献有:针对分簇架构处理器的架构特点,设计了适合该架构的卷积并行算法;提出了一种基于双总线的数据内存布局方式,在提高访存带宽的同时,避免内存的浪费.本文的剩下部分的结构如下:第2节主要介绍了多簇处理器BWDSP的结构特征和性能指标;第3节介绍了卷积的计算公式、常规卷积计算方式的不足和本文提出的卷积计算算法及基于双总线的访存优化;第4节是性能测试和结果分析;第5节是对本文的工作总结.
2 BWDSP体系结构
BWDSP系列处理器由中国电子科技集团公司第三十八所研制的分簇架构的 32位DSP处理器,架构如图1.该系列芯片有4个簇,每个簇有4个支持MAC操作的乘法器和8个ALU.该DSP采用了可读性非常强的指令系统,它的指令系统支持最多16发射的VLIW,并且大部分指令都是SIMD指令,可以通过在指令前添加簇的编号的组合,同时让多个簇执行相同的操作,因此通过指令的簇前缀组合的指令和多条指令组成一条指令行,这些乘法器和ALU在没有资源冲突的情况下,可以完全并行的运行.例如指令XYZTMACC0+=R13*R9‖XYZTMACC1+= R13*R10‖XYZTMACC2+=R13*R11‖XYZTMACC3+=R13*R12,X、Y、Z、T是簇的编号,MACC0、MACC1、MACC2、MACC3是标识簇中执行乘累加操作的不同乘法器.该指令可以同时让4个簇中共16个乘法器同时执行累加操作.处理器最大的工作频率为500Mhz,能达到30GOPS和8GFMAC的运算能力,被广泛的应用于雷达、通信保障和图像处理等各种高性能计算领域.

图1 BWDSP1042的结构框图Fig.1 Architecture of BWDSP1042
BWDSP处理器按字存储,内部集成3个地址发生器U、V、W,支持单双字寻址;内部提供了2条读总线和1条写总线,总线的位宽为256位.双字访指令XYZTR14:13=[U1+=4,1]‖XYZTR16:15=[V1+=4,1],的基址U1、V1位于不同的内存Block时,可以同时读取2组,每组4个等间距的双字,总共16字,用于分发给4个簇.BWDSP处理器的32位地址线提供了1.75G的寻址能力,提供了8个高速Link口、1个并行口、和一个DDR2接口.能够满足多DSP高速互连和外接高速存内存的需求.
3 基于BWDSP的卷积算法的实现和优化
3.1 卷积层
卷积层是卷积神经网络的核心,它通过在输入上使用滑动的窗口滤波器,在局部提取更抽象的特征,用于网络的下一层的特征提取或最终的分类.卷积层的输入和输出是三维的张量,这三维分别被称为输入(输出)通道,长和宽.卷积层的参数由一组滤波器组成,每个滤波器的大小为Kx*Ky,这些滤波器分别在每个输入通道中的长和宽方向上滑动,计算滤波器和当前滤波所覆盖的输入的二维区域的点积,所有输入通道上相同位区域计算的点积的累加和作为一个输出元素,每个输出的元素的具体计算公式如下[3]:
in(fi,x+Kx,y+Ky)
(1)
其中Nfi为输入通道数,对应的有输出通道数Nfo.Kx、Ky是滤波器窗口的长和宽.in(fi,x,y)某个输入元素;out(fo,x,y)某个输出元素.f为的滤波器组,称为卷积核.在计算某个输出通道上的输出时,每个输入通道上使用了不同的二维滤波器,而输入通道一般情况有多个,因此卷积核为四维张量,f(fi,fo,Kx,Ky)表示在计算输出通道fo上的输出时,在输入通道fi上,使用的滤波器中的参数值.
3.2 卷积层计算的常规方法
在很多基于CPU或GPU深度学习库中,如cuDNN[8],都是采用基于GEMM的算法来实现卷积的计算.见图2,Fm是卷积核展开形成的矩阵,Dm是根据卷公式(1)和Fm中每行中卷积核元素的位置,在每一列的对应位置放置特定的输入元素.这样Fm的某一行的向量和Dm的某一列的向量的点积对应卷积的某个输出元素.通过矩阵相乘,可以并行计算所有的输出元素.该算法需要额外的数据读写操作把输入和卷积核展开成矩阵.在处理能力有限的处理器中,对性能影响很大.因此需要设计适合BWDSP的卷积计算算法.
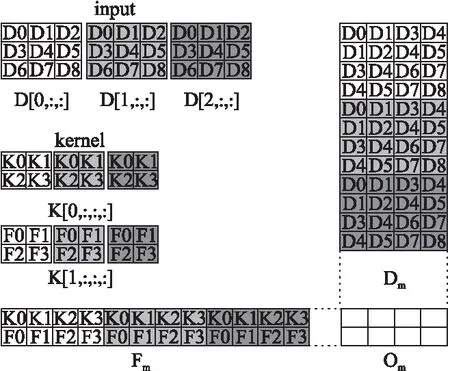
图2 基于GEMM的卷积计算算法Fig.2 GEMM convolution computing algorithm
3.3 基于BWDSP的卷积算法
由公式(1),可以得到卷积的基本代码,见下页图3.在内三层循环中变量out(fo,x,y)存在到自身的流依赖,不能直接进行向量化.但可以注意到,out(fo,x,y)是一个规约变量,这类程序的编译优化会把out(fo,x,y)看成一个向量,向量中的每个元素分别保存部分累加和.这样部分累加和的计算可以并行的进行,在循环的结束后,把向量中的元素进行规约求和得到最终的结果.基于这种思路,在BWDSP上实现卷积层最直观的方法是,把内3层循环展开,采用多个乘法器分别计算部分累加和,最后把部分结果汇集到一起,进行累加.伪代码如图4的算法1,算法1每次分别将输入和卷积核的16的元素分发到4个簇上,然后16个乘法器同时进行乘累加操作,中间结果暂时保存在乘累加寄存器中,用于在下次循环进行乘累加操作.在完成了所有的乘累加操作后,由于部分结果分散在不同簇的不同乘法器的累加寄存器中,为了得到最终的结果,需要额外的规约操作,把每个簇的内部部分和进行累加操作,再把累加和的值传输到X簇,进行累加计算最后的结果.
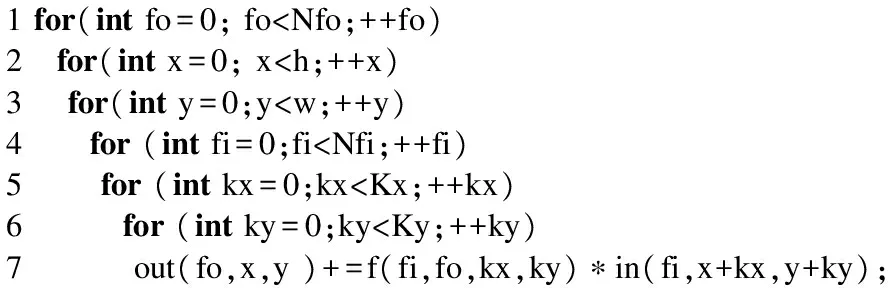
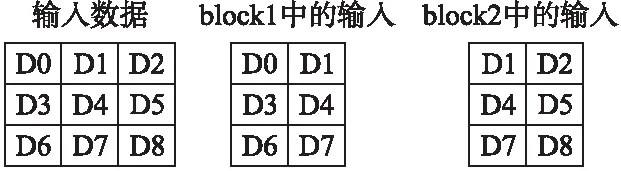
1for(intfo=0;fo 图3 卷积计算的伪代码Fig.3 Pseudo code for convolution computing 图4 算法1 使用向量化的卷积计算算法 在卷积神经网络中,卷积层中输入和输出的规模非常大.算法1在计算每个输出时,除了使用Nfi*Kx*Ky次乘累加操作外,还需要进行额外的规约操作.因此卷积计算中的规约操作的总耗时是相当大的,这会对卷积层的计算性能造成很大的影响.不同于算法1,本文了采用粗粒度的并行方式来卷积层的计算,如图5的算法2.由于在外三层循环上,变量是不存在依赖关系的,因此算法选择在第三层循环进行向量化处理,在数据分发时,扩大读取的间隔,分别读取16个滑动窗口中的输入到寄存器XYZTR0-3,并且每个乘法器单独负责一个输出结果的计算,这样每个乘法器的计算完全独立、进行的操作也完全相同,可以使用VLIW和SIMD指令使乘法器的计算并行,消除了算法的冗余规约操作.算法2只需要Nfi*Kx*Ky次乘累加操来完成每个输出的计算,并且相对算法1,除了读取的操作数的方式不同外,读取和存储数的指令数目没有增加,算法2在数据存取和计算中也没有引入冗余操作. 1for(intfo=0;fo 图5 算法2 BWDSP中的卷积计算算法 本文使用16个乘法器同时计算卷积层输出的同一行的16个结果.在DSP处理器中特别优化了乘累加操作,BWDSP的乘法器可以一个时钟周期内完成乘累加操作,因此使用乘累加操作进行最内层循环中的计算.由于每个乘法器每次计算时需要的核的参数值相同,所以每个簇可以共享读取的参数,减少计算对内存带宽的需求.在常规的计算时,核的窗口大小是不确定的,仍然需要使用6层循环来实现计算.然而,在卷积神经网络中,采用的核的窗口大小不会太大,而且长和宽相等.针对这些常用大小的核,本文设计了特殊版本的卷积程序.在这些版本中,能把最内2层的循环展开,这样不仅能减少的条件跳转指令的使用.而且,在常规版本的程序中,最内层循环中每个乘法器只进行一次计算,这样每次只能读取一个参数,读取指令不能发挥读取总线最大带宽.而通过循环展开后,读取指令可以一次读取多个参数用于展开后循环内的多次计算,提高带宽利用率. 图6 卷积中输入的内存布局Fig.6 Memory layout of convolution′s input 在BWDSP中,有2个最大带宽为8个字的读数据总线和3个内存block,由于相邻滑动窗口的间隔是相等的,本文使用2个指针,利用双读取总线同时读取等间隔的16个字的输入,每条总线负责读取8个字,用于同一行16相邻输出的计算.但当2个读数据总线的读取地址落在同一个block时,2个总线的读取不能并行进行,而数据通常存储在一块连续的内存中,造成读取数据时会发生访存冲突,实际上并不能发挥双读取总线的优势.为了能在计算中发挥最大读取带宽,可以把数据同时存放在2个block中,每个指针从不同的block上读取输入.但是这样会占用非常多的内存,实际上,每个指针为不同的输出区域的计算提供输入时,这2部分的计算分别只读取了一半左右的输入数据,所以存放在每个block中的数据有一半的数据是不会在计算中被利用的.造成了非常大内存的浪费.因此,本系统设计了特殊的数据内存布局方式,在这种布局方式中,数据按一定间隔进行划分,如图6所示,每个block只存储某指针需要读取的那部分输入,这样能发挥最大的读取带宽和避免内存的浪费. 本文分别对了基于GEMM算法、图4中算法1和图5中算法2在BWDSP1042上进行了实现和测试.测试结果表明,算法2的平均计算速度分别是GEMM算法的9.5倍和算法1的5.7倍.接着测试了算法2在大规模输入情况下的性能,随着输入规模不断增大,算法2的性能逐渐保持在 2.27GMACS左右.为了与采用FPGA硬件实现的卷积计算算法性能比较,本文分析了这些系统采用的算法和本文基于BWDSP实现的算法2的等效计算资源的平均性能,结果表明,算法2的等效计算资源的平均性能是它们设计的硬件算法的1.63倍到10.85倍. 图7 BWDSP上卷积计算算法的性能测试Fig.7 Convolution Computing Algorithms′ Benchmark on BWDSP 测试所用的测试硬件平台是BWDSP1042,处理器的工作频率为时钟频率为500M.输入和卷积核的大小分别为Nif*17*2和Nif*2*2*1,通过不断增大输入通道数Nif,来增大输入规模,测试结果见图7.由图可知,算法2算法最优,算法2的平均计算速度分别是GEMM算法的9.5倍和算法1的5.7倍,算法1的性能较差的原因除了计算中引入为规约操作之外,读取的卷积核也无法被簇中的乘法器共享,另一方面,算法1的计算所需的数据读取方式,很难满足等间隔8个字的读取的模式,无法达到最大带宽.GEMM算法的性能最差,这是因为在计算之前,GEMM需要花费大量的内存读写指令来构造矩阵.随着输入规模的不断增大,构建矩阵的时间消耗越来越多,大大的影响了算法的性能. 接着,测试在大规模输入情况下算法2的性能,结果见图8.由图8可知,随着输入规模的增大,算法的计算性能逐渐保持在2.27GMACS左右. 图8 算法2的性能Fig.8 Performance of Alg.2 目前,也有很多研究者对采用硬件加速器加速卷积神经网络的计算进行了研究,使用FPGA设计了特殊的卷积计算算法.这些加速器使用的硬件平台和本文中存在着很大的差异,并且不同的加速器使用FPGA平台也不同,很难直观地比较这些卷积计算算法的性能差异.本文采用[5]中的方法,比较了各个算法的计算资源的平均性能.硬件加速器通常只测试卷积神经网络的整体计算性能,因为卷积操作占据超过卷积神经网络90%的总计算时间,为了对比算法2和基于FPGA的硬件加速器实现的卷积计算算法的性能,本文用它们计算卷积神经网络的性能表示它们的卷积计算算法的性能,见表1.这些算法在它们的硬件平台运行的性能比本算法在BWDSP上运行的性能好.主要的原因之一是这些系统的主要目标是弥补桌面系统和服务器上通用处理器的不足,采用的计算部件(如乘法器)的数量远多于本系统使用的数目.由于FPGA主要是通过DSP slice单元来实现计算部件,根据[5]可知,实现支持乘累加操作的32位定点乘法器需要4个DSP Slice.为了能和这些系统比较计算器件的平均性能,本文把BWDSP中的乘法器数目换算成等效的DSP Slice数目,用于比较等效DSP Slice的平均性能.对比可以看出,本文设计算法的计算器件的平均性能优于这些系统的,分别是它们的1.63倍、3.23倍和10.85倍. 表1 加速器的等效计算资源的平均性能比较 本文近似FPGA2015[5]ICCD2013[13]PACT2010[14]精度32位定点32位浮点32位定点32位定点硬件平台BWDSP1042VX485TVLX240TSX240T测试性能2.27GMACS61.62GFLOPS8.5GMACS3.5GMACSDSPSlice数64(等效)280028001056DSPSlic3.58E-022.20E-021.11E-020.33E-02平均性能GMACSGFLOPSGMACSGMACS 深度学习的迅速发展对嵌入式系统智能化需求的带来了新等机遇和挑战.本文基于多簇架构的数字信号处理器BWDSP,对卷积神经网络中计算量90%以上卷积计算的并行算法进行了研究和实现.性能测试表明,本文设计的算法的性能是常规的GEMM算法的9.5倍和向量化算法的5.7倍.能达到2.27GMACS.对比基于FPGA实现的卷积计算的硬件算法,该算法的计算器件的平均性能是它们的1.63倍到10.85倍. 在一个典型的卷积神经网络,除了卷积操作,还有其他的操作,未来的主要工作是在BWDSP处理器上实现深度学习算法库,用于在该处理器上构建卷积神经网路加速器. [1] He K,Zhang X,Ren S,et al.Deep residual learning for image recognition[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:770-778. [2] Gu J,Wang Z,Kuen J,et al.Recent advances in convolutional neural networks[J].ArXiv Preprint ArXiv:1512.07108,2015. [3] Chen T,Du Z,Sun N,et al.Diannao:a small-footprint high-throughput accelerator for ubiquitous machine-learning[C].ACM Sigplan Notices,ACM,2014,49(4):269-284. [4] Chen Y,Luo T,Liu S,et al.Dadiannao:a machine-learning supercomputer[C].Proceedings of the 47th Annual IEEE/ACM International Symposium on Microarchitecture,IEEE Computer Society,2014:609-622. [5] Zhang C,Li P,Sun G,et al.Optimizing fpga-based accelerator design for deep convolutional neural networks[C].Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays,ACM,2015:161-170. [6] Szegedy C,Liu W,Jia Y,et al.Going deeper with convolutions[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015:1-9. [7] Ji S,Xu W,Yang M,et al.3D convolutional neural networks for human action recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(1):221-231. [8] Chetlur S,Woolley C,Vandermersch P,et al.cudnn:Efficient primitives for deep learning[J].ArXiv Preprint Xiv:1410.0759,2014. [9] Bengio Y,Courville A,Vincent P.Representation learning:a review and new perspectives[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(8):1798-1828. [10] Kamijo S,Matsushita Y,Ikeuchi K,et al.Traffic monitoring and accident detection at intersections[J].IEEE Transactions on Intelligent Transportation Systems,2000,1(2):108-118. [11] Roux S,Mamalet F,Garcia C.Embedded convolutional face finder[C].2006 IEEE International Conference on Multimedia and Expo.IEEE,2006:285-288. [12] LeCun Y,Bottou L,Bengio Y,et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278-2324. [13] Peemen M,Setio A A A,Mesman B,et al.Memory-centric accelerator design for convolutional neural networks[C].IEEE 31st International Conference on Computer Design (ICCD),IEEE,2013:13-19. [14] Cadambi S,Majumdar A,Becchi M,et al.A programmable parallel accelerator for learning and classification[C].Proceedings of the 19th International Conference on Parallel Architectures and Compilation Echniques(PACT),ACM,2010:273-284.
Fig.4 Alg.1 vectorized convolution parallel algorithm
Fig.5 Alg.2 convolution parallel algorithm used in BWDSP3.4 基于双总线的读取带宽的优化
4 性能测试与分析
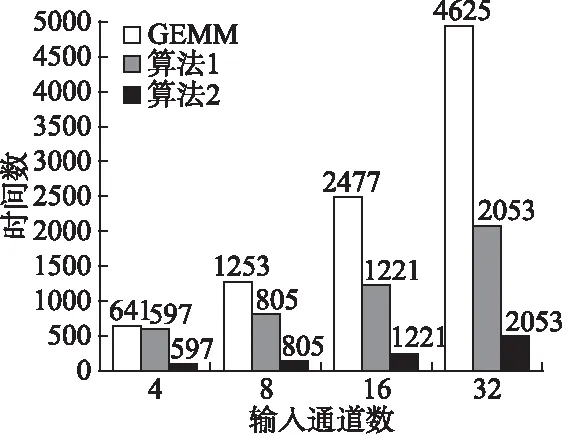
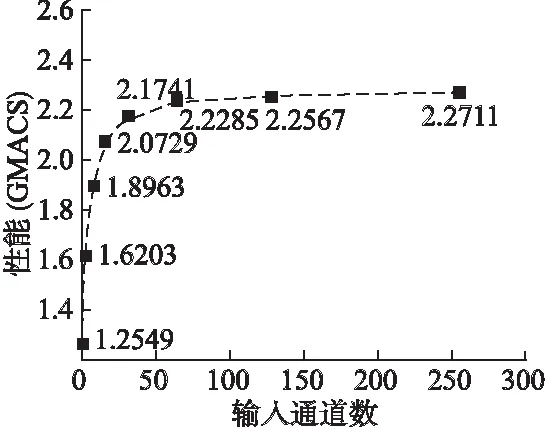
Table 1 Comparison of equivalent computing recourses′ averaging performance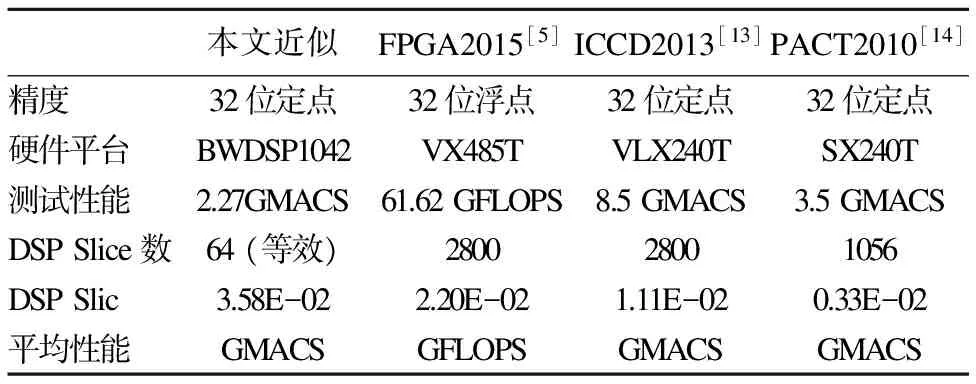
5 总结和未来的工作
猜你喜欢
数码世界(2020年12期)2021-01-20学校教育研究(2020年11期)2020-06-08电脑报(2019年31期)2019-09-10当代陕西(2019年13期)2019-08-20电子制作(2018年8期)2018-06-26电子制作(2018年2期)2018-04-18电子制作(2018年1期)2018-04-04电脑爱好者(2015年21期)2015-09-10科技传播(2015年20期)2015-03-25汽车零部件(2014年2期)2014-03-11
