
一种改进的MapReduce互信息文本特征选择机制
2018-03-27 03:30陶永才赵国桦
小型微型计算机系统 2018年3期
陶永才,赵国桦,石 磊,卫 琳
1(郑州大学 信息工程学院,郑州 450001) 2(郑州大学 软件技术学院,郑州 450002)
1 引 言
大数据时代引发的“数据挖掘风暴”已经进入超速发展时期,文本分类是数据挖掘的重要环节,而特征选择又是文本分类的核心步骤.
特征选择是根据文本中划分好的特征词条的重要程度,过滤掉那些不相关的或者冗余的特征词条,保留那些对文本分类有意义的特征词条[1].互信息(Mutual Information,MI)是信息论中的重要概念,人们把互信息广泛运用于文本分类,互信息成为了文本分类中最常用的特征选择方法,在文本分类的特征选择度量指标中,互信息值表示特征项的值与文本类别的统计相关性以及特征词之间的统计相关性.
MapReduce是Google公司提出的一种基于大规模数据集并行计算的编程模式,主要用于对海量数据的收集和处理,与传统的计算模式相比,极大提升了性能,提高了效率.在当今数据挖掘、新闻推荐、机器学习、互联网服务等领域上广泛使用[2].
针对传统互信息算法,只考虑特征项出现在某类别文档的频数,但是没有考虑特征项总共出现了多少次,也没有考虑特征项在文本中平均出现次数,本文提出一种改进的MapReduce互信息文本特征选择机制,一方面对传统互信息计算公式进行改进,引入特征项的频数和特征项的平均出现次数,并借助熵的概念,对互信息公式进行修正,提高互信息方法特征项选择准确度,从而提高分类精度.另一方面提出基于MapReduce的互信息文本特征选择模型,将文本处理分为可并行的两个阶段:文本训练阶段和文本分类阶段,利用MapReduce模型对大规模数据处理的优势,优化文本集训练以及分类,进而提升系统的工作效率.
2 相关工作
传统互信息算法效率较低,众多研究针对于传统互信息算法进行改进,文献[12]针对算法中负相关现象问题改进了传统互信息算法;文献[13]提出了一种新的基于互信息的特征评价函数TFMIIE,有效避免偏向低频特征词;文献[15]提出了一种基于互信息的无监督的特征选择方法(UFS-MI),在UFS-MI中,使用综合考虑相关度和冗余度的特征选择标准UmRMR(无监督最小冗余最大相关)来评价特征的重要性.
以上研究在一定程度上弥补了传统互信息方法的不足,明显地提升了处理效率.随着MapReduce技术的出现和发展,借助MapReduce技术的优势,各种文本分类技术都有了阶段性的进步,实现了高效处理海量数据的能力.文献[10,14]提出了云计算环境下朴素贝叶斯文本分类算法,将贝叶斯分类和MapReduce技术结合;文献[16]提出一种基于MapReduce的分布式聚类方法,该方法对传统K-means算法进行了改进,采用基于信息损失量的相似性度量,相对于传统的聚类算法,性能上有显著提升.
上述研究中,各种改进传统互信息的策略殊途同归,在一定程度上都能提升互信息方法的性能.虽然有不少基于Mapreduce的文本分类技术,但对于互信息和MapReduce技术的结合,还没有得到过多关注和研究.本文创新性地将互信息理念和Mapreduce技术结合,同时优化传统互信息方法,不但能提升系统的效率,也将从根本上提高文本分类的精度.
3 研究背景
3.1 文本分类与特征选择
文本分类(Text Categorization)以预先给定的分类类别为标准,根据文本的主要内容,将文本划分到某一个或者多个分类类别中.借助于文本分类系统,用户可以更方便快捷地查找需要的信息[3].近年来,文本自动分类技术已经逐渐与搜索引擎、信息推送、信息过滤等信息处理技术相结合,有效地提高了信息服务的质量.一般的文本分类过程如图1所示.文本分类的核心之一就是特征选择.典型的特征选择算法有基于互信息(MI)、基于信息增益(IG)、文档频数(DF)计算等.特征选择的目的是对高维文本进行降维处理,降低文本分类的复杂度.特征选择的优势在于直接从特征项中选择,避免生成新特征而消耗大量时间和空间上的资源.

图1 标准文本分类过程Fig.1 Standard text categorization process
3.2 MapReduce
MapReduce是一个大数据集的分布式处理平台,具有高可用性、高可扩展性和高容错性能.MapReduce模型集成多个计算机节点对海量数据并行处理[4].
MapReduce主要包括Map阶段(映射)和Reduce阶段(归约)[5,7,8],工作过程如图2所示.用户预先给定一个Map函数和Reduce函数,原始数据经过预处理被分割成多个数据块并以键值对
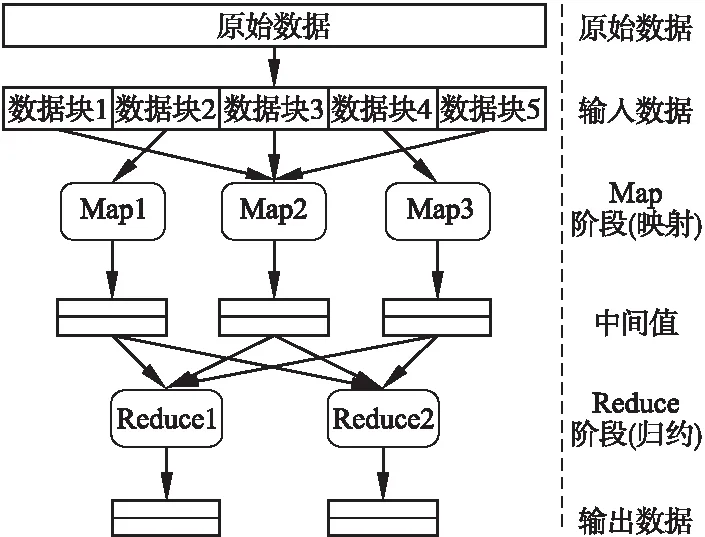
图2 MapReduce工作流程Fig.2 Workflow of MapReduce
3.3 互信息
互信息是信息论的重要概念,用来描述两个事件集合之间的关联性[6].两个事件X和Y的互信息定义为:
I(X,Y)=H(X)+H(Y)-H(X,Y)
(1)
其中,H(X)和H(Y)是边缘熵,H(X,Y)是联合熵,定义为:
H(X,Y)=-∑p(x,y)log(p(x,y))
(2)
在特征选择中运用互信息的思想,即特征项t和类别ci的互信息MI(t,Ci)指本特征项和类别ci的关联程度,如式(3)所示.
(3)
其中,p(t,ci)指特征项t和类别ci同时出现的概率(即特征项出现在类别ci中),p(t)指特征项t在整个训练文本集合中出现的概率,p(ci)指类别Ci的文档占整个训练文本集合的比率.由于分类类别一般会有很多,记分类类别的个数为m,用平均关联程度表示最后计算的互信息值,则特征项t与各个类别的平均关联程度MI(t,Ci)可表示为式(4).
(4)
在文本分类中,传统的互信息特征选择的基本步骤为:
1)对目标文本进行预处理:分词,去停用词;
2)利用传统的互信息计算公式,计算每个特征项与各个类别的平均关联程度;
3)在所有特征项中选择一定量的特征项,选择依据是根据特征项与各个类别的平均关联程度的高低.
3.4 传统互信息方法的不足
传统的互信息特征选择方法中,基于p(t,ci)的存在,只考虑了特征项的文档频度,即只考虑特征项t出现在类别ci的文档数,但是没有考虑特征项出现了多少次,即特征项的频数.在式(3)中没有考虑到特征项的频数这个参数,则会有以下情况出现:
可能存在两个特征项t1、t2,特征项t1的频数远大于特征项t2的频数,由于没有特征项的频数的约束,在用互信息计算公式计算时,导致t1、t2的互信息权值相等,在排序中随机选择权值相等的特征项中的一个,很大可能过滤掉频数高的特征项,将稀有的低频特征项选作最终特征项.
当然,如果单纯地直接引入特征项的频数,没有考虑特征项在文本中平均出现次数,可能会出现以下情况:在个别文本中出现次数多的特征项的互信息值小于在多数文本中偶尔出现的特征项的互信息值.以至于对于一个类别ci,无法选择特征项t作为它的一个候选特征项,这个特征项t可能仅仅是在这个类别中出现的次数较高.
4 改进的MapReduce互信息文本特征选择机制
4.1 改进的互信息方法
针对互信息的不足,本文通过引入特征项的频数和特征项的平均出现次数,同时,基于信息熵的概念,引入信息熵对互信息的计算公式加以修正,从而提高互信息值的有效性和准确度.
由于在传统的互信息选择方法中,只考虑了特征项的文档频度,即只考虑特征项t出现在类别ci的文档数,但是没有考虑特征项出现了多少次,即特征项的频数.本文引入特征项的频数这个概念,用来表示特征项在某个类别中出现的次数和特征项在整个文本集合中出现的次数的比值,记作Q(qt),若类别ci有文档(d1,…,dk,…,dn),则有:
(5)
其中,qt表示特征项在类别ci的文档dk中出现的次数,n表示类别ci中的文本总数,m表示训练集中类别总数.由式(5)可知,Q(qt)越大,说明特征项在某个类别中出现的次数越多,则这个特征项选为候选特征项的可能性就越大.
再引入特征项的平均出现次数,来弥补引入特征项的频数的不足:没有考虑特征项在文本中平均出现次数,导致可能会出现在个别文本中出现次数多的特征项的互信息值小于在多数文本中偶尔出现的特征项的互信息值.记特征项的平均出现次数为V(qt),若类别ci有文档(d1,…,dk,…,dn),则有:
(6)
其中,qt表示特征项在类别ci的文档dk中出现的次数,n表示类别ci中的文本总数.由式(6)可知,V(qt)越大,表明这个特征项越能当这个类别的候选特征项.
考虑特征项的频数和特征项的平均出现次数,互信息计算公式可表示为:
(7)
考虑分类类别有m个,并用平均关联程度表示最后计算的互信息值,则有:
(8)
熵是统计热力学中表示目标系统的混乱程度的物理量[9],为了让互信息值更有效,准确度更高,借助于信息熵的概念,特征项t在类别ci中的信息熵为:
(9)
其中,P(ci|t)是含有特征项t的类别ci的文本数和含有特征项t的文本数的比值.信息熵IE(C|t)描述了以类别ci为系统,特征项t为事件的一个量,表示文本分类的混乱程度(即不确定性).IE(C|t)越小,系统的混乱程度越小,确定性越大,特征项t对类别ci分类的影响越大.
在式(8)中引入信息熵作为互信息计算的修正,用新的记号MInew(C,t)表示改进过的互信息计算公式,如式(10)所示.
(10)
4.2 基于MapReduce的互信息文本特征选择
基于MapReduce的互信息文本特征选择模型分为两部分:文本训练阶段和文本分类阶段.
4.2.1 文本训练阶段
图3是基于MapReduce的文本训练模型.首先选择合适的训练文本集进行预处理:分词、去停用词.通过VSM模型建立维向量来表示预处理后的特征项.经过预处理和向量处理的训练文本集便可以进入文本训练过程.

图3 基于MapReduce的文本训练模型Fig.3 A text training model based on MapReduce
文本训练模型包含3个MapReduce过程,前两个过程可以在资源节点上同时运作,第1个MapReduce过程用来产生训练文本集的特征项,公式(10)是Map阶段函数的核心;第2个MapReduce过程用来产生训练文本集各个类别的特征项,公式(7)是这过程中Map阶段函数的核心;第3个MapReduce过程用来产生训练文本集各个类别的特征向量,利用过程(1)、(2)的结果,在过程(1)生成的训练文本集的特征项中匹配过程(2)中训练文本集各个类别的特征项,匹配成功(即发现相同特征项)后便可选为最终的训练文本集对应类别的特征项向量,作为训练库供下一步使用.
算法1.文本训练算法
输入:训练文本集W1;类别C;文档d;特征项t
输出:Textvectorfile
1.Map1:
//计算特征词t对于全部类别(C)的互信息值均值
2.{
3.Foreach du∈W1do
5.MInew(C,t);
6.endfor
7.endfor
8. }
9. Sort( )→Ts={MI1,MI2,…,MIn};
10.Map2:
//计算特征词t对于每个类别(Ci)的互信息值
11.{
12.Foreach du∈Cido
14. MI(t,Ci);
15.endfor
16.endfor
17. }
18.Foreach Cido
19.Sort( )→Tv={MI1,MI2,…,MIn};
20.endfor
21.Map3:
22. Match the same tjin Map1 and Map2;
23.OutputText vector file;
文本训练算法如算法1所示:
1)对于进入文本训练过程的每一个训练文本,通过第1个Mapreduce过程的Map1函数计算其与全部类别的互信息均值,得到<特征项,互信息值>的键值对< termID,Value >(第1行至第8行).
2)将步骤(1)得到的键值对< termID,Value >经过处理后,以Value为分类标准降序排列,得到训练文本集的特征项序列Ts={MI1,MI2,…,MIn}(第9行).
3)通过第2个Mapreduce过程,计算特征词对于每个类别的互信息值,得到以<特征项,互信息值>的键值对< termID,Value >(第10行至第17行).
4)将步骤(3)得到的键值对< termID,Value >经过处理后,同样的,以Value为分类标准降序排列,得到每个类别的特征项序列Tv={MI1,MI2,…,MIn}(第18行至第20行).
5)通过第3个Mapreduce过程,执行Map3函数,在Map1和Map2中匹配相同的特征词,得到训练文本集各个类别特征向量.(第21行至第22行).
6)输出Text vector file(第23行).
4.2.2 文本分类阶段
图4所示为基于MapReduce的文本分类模型.
基于MapReduce的文本训练模型已生成文本的训练库,当给出合适的测试文本集时,使用一个MapReduce过程,以训练库的文本向量为训练样例,对输入过来的测试用例集(测试文本集)进行分类.其中,Map阶段就是分类的阶段,本文使用KNN算法作为Map阶段的核心函数.KNN算法思想如下:对于给定待分类的文本文档,经过预处理,用特征向量(t1…tk…tn)表示,在训练库中找到与它最近的K个近邻,则待分类文本属于这K个近邻中大多数属于的那一类.之后经过Reduce阶段将Map阶段的结果按类别输出.
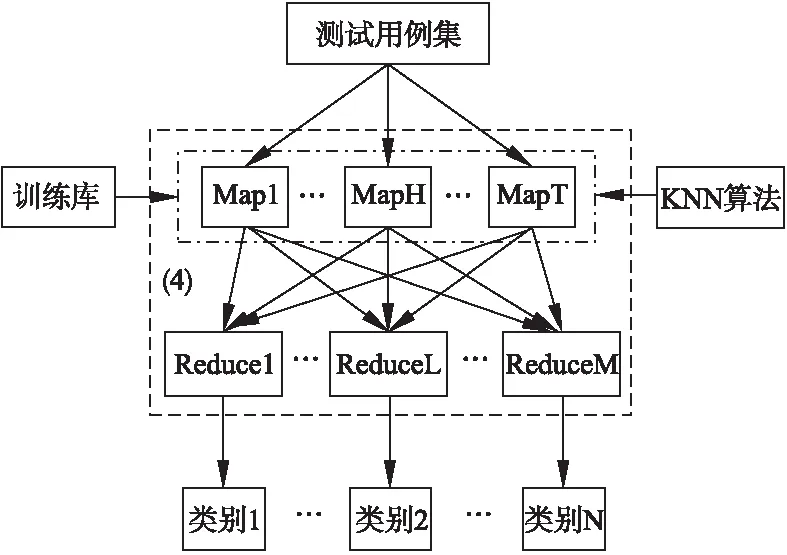
图4 基于MapReduce的文本分类模型Fig.4 Text categorization model based on MapReduce
算法2.文本分类算法
输入:Textvectorfile;测试文本集W2;类别C;
文档d;特征项t
输出:Classifieddocuments
1.Map4:
//分类测试文本集W2
2.{
3.Foreach du∈W2do
4. KNN();
5. Get an initial classification file(ICF);
//通过KNN分类后,得到初始分类文件
6. }
7.Reduce4:
8.{
9.Foreach cj∈Wdo
10. Match the same category in the initial classification file;
11. ICFi→FileCz{LR1,LR2,…,LRn};
12.endfor
13. }
14.OutputClassified documents;
文本分类算法如算法2所示:
1)对于进入文本测试过程的每一个训练文本,通过本阶段的Mapreduce过程中Map4函数以及训练阶段得到的Text vector file,进行文本分类.其中,Map4函数的主体为KNN分类算法,执行后经过处理得到初始分类文件(第1行至第6行).
2)步骤(1)得到的初始分类文件,是<类别,文档>的键值对< ClassID,DocID >集.在本步骤的Reduce4函数中,将初始分类文件,以ClassID为分类标准进行分类,得到基于不同类别的文本序列FileCz{LR1,LR2,…,LRn}(第7行至第13行).
3)输出Classified documents(第14行).
在算法1和算法2中,第1个Mapreduce过程和第2个Mapreduce过程可在给定的节点上分布式运行,并且对于每一个Mapreduce过程中的Map阶段和Reduce阶段,也可以在给定的多个节点上并行执行,因此可大幅度消减时间上的复杂度,提升系统效率.
1自然语言处理与信息检索共享平台[EB/OL].2017-1-15,http://www.nlpir.org/?action-viewnews-itemid-103.2实验A、B与实验D、E的实验目的相同,实验结果类似,鉴于篇幅问题,本文只列举实验A、B的实验结果.
5 性能评价
5.1 实验数据
实验采用“自然语言处理与信息检索共享平台1”提供的复旦大学收集的文本分类语料库作为训练集和测试集,包含Art、Medical、Education、Computer等20个类别.从中选取部分类别作为实验所需的训练文本集和测试文本集,选取情况如表1所示.
表1 抽取语料库样本分布
Table 1 Corpus drawn sample distribution

ArtMedicalComputerEducationSportsLaw训练集200200200200200200测试集200200200200200200
5.2 实验设置
实验在两个条件下的三种环境里进行性能测试.第一个条件是基于传统的互信息方法,分别在普通的PC单机、Hadoop集群(单节点)、Hadoop集群(多节点)三种环境下进行试验,第二个条件是基于改进的互信息方法,也在相同的三种环境下进行试验.实验设置如图5所示.
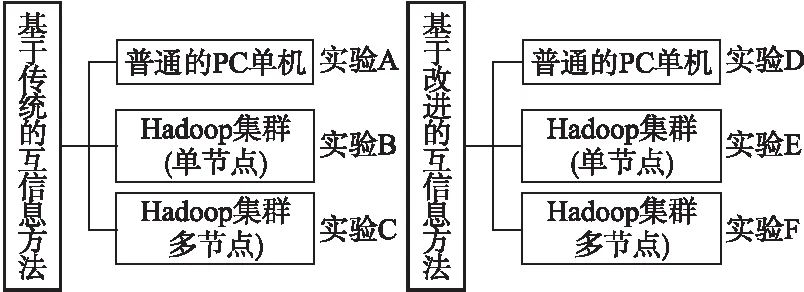
图5 实验设置Fig.5 Experimental arrangement
三种实验环境采用相同的基本配置,配置如下:CPU为3.60Hz,内存为8G,硬盘为1T,操作系统为Ubuntu-15.10,Hadoop版本为2.6.0,所用到代码编译环境为JDK-1.8.使用的KNN算法设置K值为8.针对互信息特征选择方法,选取1000维特征做特征向量.多节点Hadoop集群由配置相同的2、4、8、10台、16台节点组成.
5.3 评价指标
准确率:系统正确分类出某类别的文本数和系统分类的文本总数比值,该指标反映系统正确分类能力的高低.
召回率:系统正确分类出某类别的文本数和系统分类的某类别文本总数,该指标反映系统分类能力的高低.
F1值:用于综合反映整体的指标,计算公式如式(11)所示.
(11)
其中,P表示准确率,R表示召回率.
加速比:系统在改进前后处理同一任务所用时间的比例,该指标反映系统执行效率的高低.
5.4 实验结果
选取实验A和实验B(或实验D和实验E2)为一组,对比实验结果,如表2所示.
表2 PC单机和Mapreduce下文本的向量维度
Table 2 Vector dimension in PC and Mapreduce

序号类别PC单机下Maprduce下1Art1281302Medical16143Computer14134Educaton91945Sports3363306Law333341
由表2实验数据可以发现,基于MapReduce的互信息文本特征选择和传统互信息特征选择得到的文本向量维数相差无几.由此可见,引入MapReduce技术对互信息特征选择在基本的文本向量选择性能方面未造成不良影响.
选取实验A和实验D为一组,对比实验结果,如表3所示.
表3 传统方法和改进方法的文本向量维度
Table 3 Text vector dimensions of traditional and improved
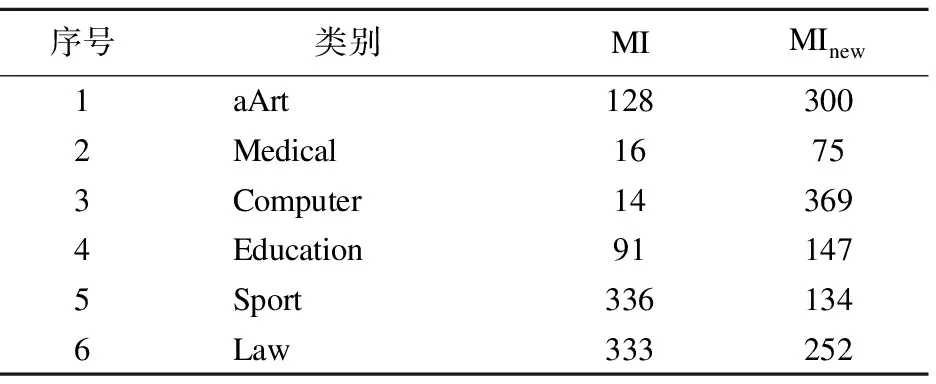
序号类别MIMInew1aArt1283002Medical16753Computer143694Education911475Sport3361346Law333252
由表3实验数据可以明显地看出使用传统互信息方法得到的文本向量维数很不均匀,Medical和Computer类别的训练文本各有200篇,但是选取的特征词只有十几个,这会对后期测试文本的分类有很大影响.Sports和Law类别的特征项相对较多,在后期的文本分类中,准确率可能会相对提高.基于改进互信息方法得到的向量维度相对均衡.结合表4发现Sports类别使用传统互信息方法得到的特征项比使用改进互信息方法得到的特征项多,但是准确率却不如改进互信息方法,特选取Sports类别进行分析.传统互信息方法相对于Sports类别得到的特征项虽然很多,但其中包含了关联度并不是很高的词,如:防守、出击、光速、去年底、整治、辅助、艰苦等等,这类词会对分类结果产生很大影响.反观采用改进互信息方法选到的特征项虽然少,但是到100维,特征项仍明显和Sports相关,如:110米栏、体能、三双等等.使得后期的文本分类能保持较高的准确率.
表4 实验结果及对比
Table 4 Experimental results and comparison
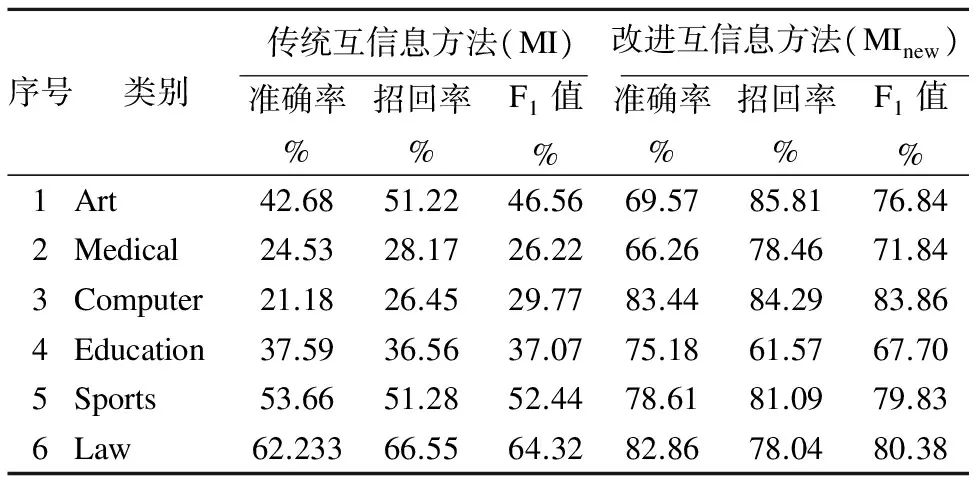
序号类别传统互信息方法(MI)改进互信息方法(MInew)准确率%招回率%F1值%准确率%招回率%F1值%1Art42.6851.2246.5669.5785.8176.842Medical24.5328.1726.2266.2678.4671.843Computer21.1826.4529.7783.4484.2983.864Education37.5936.5637.0775.1861.5767.705Sports53.6651.2852.4478.6181.0979.836Law62.23366.5564.3282.8678.0480.38
表5 实验运行时间
Table 5 Experimental running time

实验号机器数运行时间(ms)实验D126604实验E126376218824413232实验F86080105419163775
为测试基于MapReduce的改进互信息文本特征选择机制的加速比性能,选取实验D和实验E以及实验F为一组,多次实验,对比实验结果,用来验证Hadoop集群中节点数目增加时对模型的性能影响.Hadoop集群多节点分别采用2台、4台、8台、10台、16台同配置的节点.实验D、实验E、实验F执行时间如表5所示,图6所示为由表5运行时间数据计算的系统加速比.
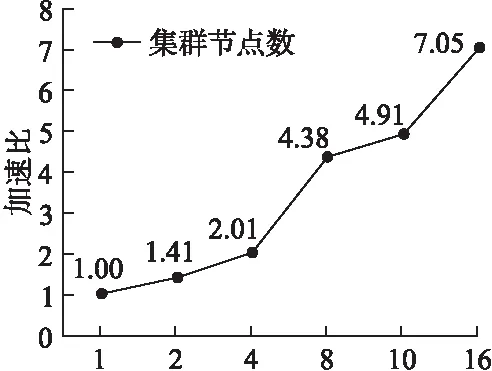
图6 系统加速比Fig.6 System speedup
由表3、表4和表5可知,与传统的互信息特征选择方法相比,基于MapReduce的改进互信息文本特征选择机制不仅提高了分类的准确度,而且明显提高了系统的执行效率.由图6可知,当增加Hadoop节点数,基于MapReduce的改进互信息文本特征选择机可以达到近似线性的加速比.
6 总结与展望
传统的基于互信息的特征文本选择在文本分类中比较常用,但是因理论公式过于简单,实际应用中分类准确率较为偏低.本文在理论上阐述了传统互信息方法的不足,提出一种改进的互信息特征文本选择方法,同时结合MapReduce技术,提出一种基于MapReduce的改进互信息文本特征选择机制.实验表明该机制可以明显提高文本分类的精度,而且显著提升执行效率.
鉴于本文提出的改进的MapReduce互信息文本特征选择机制没有针对特殊文本进行特殊处理,例如,现实中所用到的文本可能包含提纲或者标题.未来研究考虑针对带有提纲或者标题的文本改进算法,提取提纲或标题的关键字,提高关键字在分类时的权重,从而提升此类文本分类的准确率.此外,文本分类方法和Hadoop平台结合是未来本领域发展趋势,所以本文提到的Mapreduce模型能否移植到其他分类方法上、性能是否有所提升,也是下一步研究的重点.
[1] Dash M,Liu H.Feature selection for classification[J].Intelligent Data Analysis,1997,1(1):131-156.
[2] Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[3] Li Yun,Lu Bao-liang.Feature selection based on loss-margin of nearest neighbor classification[J].Pattern Recognition,2009,42(9):1914-1921.
[4] Mashayekhy L,Nejad M,Grosu D,et al.Energy-aware scheduling of MapReduce jobs[J].IEEE International Congress on Big Data,2014,26(10):32-39.
[5] Han Lei,Sun Xu-zhan,Wu Zhi-chuan,et al.Optimization study on sample based partition on MapReduce[J].Journal of Computer Research and Development,2013,50(Sup.):77-84.
[6] Zhao Zheng,Wang Lei,Liu Huan,et al.On similarity preserving feature selection[J].IEEE Transactions on Knowledge & Data Engineer,2013,25(3):619-632.
[7] Neil Gunther,Paul Puglia,Kristofer Tomasette.Hadoop superlinear scalability[J].Communications of the ACM,2015,58(4):46-55.
[8] Fabrizio Marozzo,Domenico Talia,Paolo Trunfio.P2P-MapReduce:parallel data processing in dynamic cloud environments[J].Journal of Computer and System Sciences,2012,78(5):1382-1402.
[9] Howard Barnum,Jonathan Barrett,Lisa Orloff Clark,et al.Entropy and information causality ingeneral probabilistic theories[J].New Journal of Physics,2010,12,033024.
[10] Feng Guo-zhong,Guo Jian-hua,Jing Bing-yi,et al.Feature subset selection using naive Bayes for text classification[J].Pattern Recognition Letters,2015,65:109-115.
[11] Liu Z,Zhang Q,Zhan M F,et al.Dreams:dynamic resource allocation for mapreduce with data skew[J].Integrated Network Management (IM),IFIP/IEEE International Symposium on,2015:18-26.
[12]Xin Zhu,Zhou Ya-jian.Study and improvement of mutual information for feature selection in text categorization[J].Journal of Computer Applications,2013,(S2):116-118+152.
[13]Cheng Wei-qing,Tang Xuan.A text feature selection method using the improved mutual information and information entropy[J].Journal of Nanjing University of Posts and Telecommunications(Natural Science),2013,(5):63-68.
[14]Jiang Xiao-ping,Li Cheng-hua,Xiang Wen,et al.Naive Bayesian text classification algorithm in cloud computing environment[J].Journal of Computer Application,2011,(9):2551-2554+2566.
[15]Xu Jun-ling,Zhou Yu-ming,Chen Lin,et al.An unsupervised feature selection approach based on mutual information[J].Journal of Computer Research and Development,2012,(2):372-382.
[16]Li Zhao,Li Xiao,Wang Chun-mei,et al.Text clustering method study based on mapreduce[J].Computer Science,2016,(1):246-250+269.
附中文参考文献:
[12] 辛 竹,周亚建.文本分类中互信息特征选择方法的研究与算法改进[J].计算机应用,2013,(S2):116-118+152.
[13] 成卫青,唐 旋.一种基于改进互信息和信息熵的文本特征选择方法[J].南京邮电大学学报(自然科学版),2013,(5):63-68.
[14] 江小平,李成华,向 文,等.云计算环境下朴素贝叶斯文本分类算法的实现[J].计算机应用,2011,(9):2551-2554+2566.
[15] 徐峻岭,周毓明,陈 林,等.基于互信息的无监督特征选择[J].控制与决策,2012,(2):372-382.
[16] 李 钊,李 晓,王春梅,等.一种基于MapReduce的文本聚类方法研究[J].计算机科学,2016,(1):246-250+269.
猜你喜欢
陶瓷学报(2021年4期)2021-10-14
南京理工大学学报(2021年4期)2021-09-15
少儿画王(3-6岁)(2020年4期)2020-09-13
小型微型计算机系统(2018年5期)2018-07-04
计算机应用(2016年10期)2017-05-12
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年1期)2016-03-22
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
航空兵器(2014年5期)2015-02-10
